はじめに
当記事はある目的を持って必要な技術を調べながら手を動かした記録を要素別にまとめたものの1つです。データ解析全体の流れはリンク先の記事を参照ください。('21/4/29時点未完成)
やりたいこと
前回Webから引っ張ってきた情報をとりあえずDataFrameに格納するとことまでやりました。このままでは、一つのindexに本来複数のレコードであるべき情報が含まれていたり、不要な文字列を含んでいたり、カラムが必要な粒度で分解できていなかったり、定量的に解析できるはずなのにテキスト情報になっていたりするので、1つ1つ解決していきます。
使用するライブラリ
pandasにつきます。この当たりのメソッドを駆使します。
- pd.DataFrame.str.split()
- pd.DataFrame.str.extract()
- pd.DataFrame.str.replace()
- pd.DataFrame.astype()
- あとは、strメソッドでの正規表現の活用
元データ
こんな状態からスタートです。
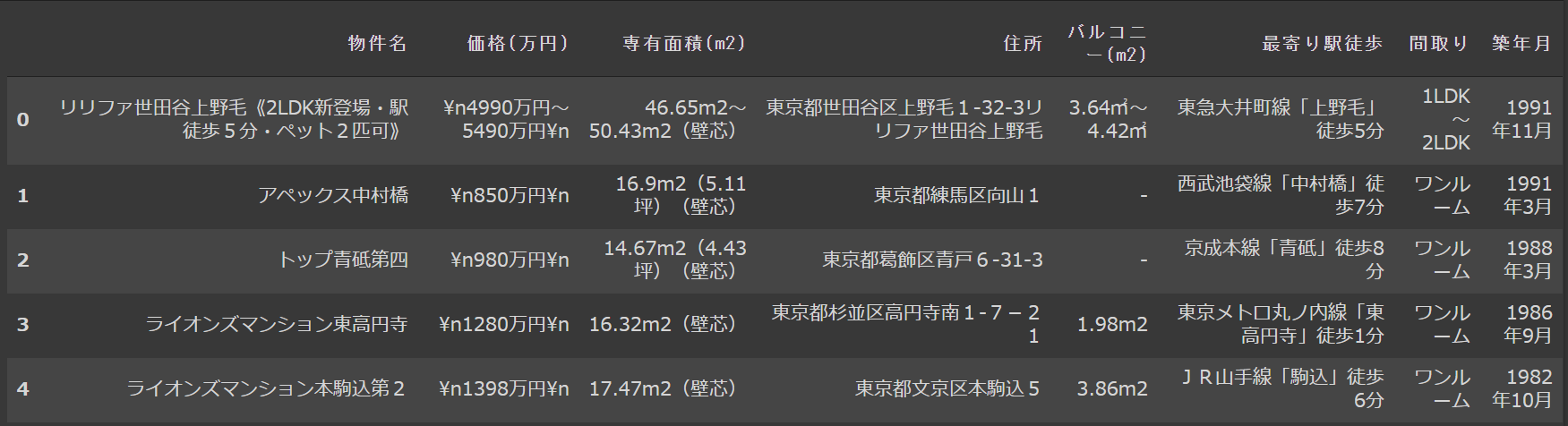
戦略
- まず1つのindexに「○○万円~○○万円」とレンジで記載されているレコードを2つに分割する。
- 不要な文字列を落とす。
- 分析しやすい粒度にカラムを分ける(例:住所→区名、町名)
- 数字の整理(例:バス○分徒歩○分→○○m)
- 重複しているレコードの削除
実践
範囲で記載された1つのレコードを最大、最小の2つのレコードに分割する。
2つに分割してレコードを増やしたいのが本来やりたいことですが、まずはカラムを分割します。df.str.splir()で分割した後の要素をそれぞれ新しく作った別のカラムに入れてもとのカラムは削除します。
# GoogleColab環境にGoogleDriveをマウント
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
# 前作ったcsvをGoogleDirveから読み込んでおきます。
df=pd.read_csv('/content/drive/MyDrive/suumo.csv', sep = '\t',encoding='utf-16')
# ここからがデータの前処理
df['価格(万円)1']=df['価格(万円)'].str.split('~', expand=True)[[0]]
df['価格(万円)2']=df['価格(万円)'].str.split('~', expand=True)[[1]]
df=df.drop('価格(万円)', axis=1)
そもそも何故こういうことが起きるかというと、元のサイト内の検索結果がマンション名単位のレコードだった為。同じマンション内で違う間取りの別の部屋が売りに出ていたらこうるようです。したがって、価格だけでなく他の関連するカラムも同様に操作します。
df['専有面積(m2)1']=df['専有面積(m2)'].str.split('~', expand=True)[[0]]
df['専有面積(m2)2']=df['専有面積(m2)'].str.split('~', expand=True)[[1]]
df=df.drop('専有面積(m2)', axis=1)
df['バルコニー(m2)1']=df['バルコニー(m2)'].str.split('~', expand=True)[[0]]
df['バルコニー(m2)2']=df['バルコニー(m2)'].str.split('~', expand=True)[[1]]
df=df.drop('バルコニー(m2)', axis=1)
df['間取り1']=df['間取り'].str.split('~', expand=True)[[0]]
df['間取り2']=df['間取り'].str.split('~', expand=True)[[1]]
df=df.drop('間取り', axis=1)
これらを同じカラムの新しいレコードとして置きなおす必要があります。
まずは、該当するレコードだけ抜き出して別のDataFrameで作業をするため、以下の操作。
dfdpl=df[df['価格(万円)2'].notnull()]
あとで元のDataFrameにくっつけて'価格(万円)1'のカラムだけ残すことを考えているので、抜き出したレコードの'価格(万円)2'などの情報を'価格(万円)1'などへ貼り付けます。
dfdpl.reset_index(inplace=True, drop=True)
dfdpl['価格(万円)1']=dfdpl['価格(万円)2']
dfdpl['専有面積(m2)1'][dfdpl['専有面積(m2)2'].notnull()]=dfdpl['専有面積(m2)2']
dfdpl['バルコニー(m2)1'][dfdpl['バルコニー(m2)2'].notnull()]=dfdpl['バルコニー(m2)2']
dfdpl['間取り1'][dfdpl['間取り2'].notnull()]=dfdpl['間取り2']
本当はこんな左辺を.notnull()で絞り込んで右辺の値を打代入するという操作は良くないようです。エラーにはならないけど、なんかメッセージが出ます。
.notnull()としている理由は、価格にはレンジがあるが、間取りは一定で広さだけ違う場合などもあるためです。
元のDataFrameにくっつけて、indexを振り直し、操作用に一時的に作ったカラムを削除します。
df=pd.concat([df, dfdpl])#axisを指定しない場合は縦に積む。
df.reset_index(inplace=True, drop=True)
df=df.drop(['価格(万円)2','専有面積(m2)2','バルコニー(m2)2', '間取り2'],axis=1)
金額、広さ、距離、年数など数値データとして参照したいものをテキストデータから取り出す。集計する際のキーにしたいテキスト(住所、駅名)などを取り出す。
価格のうち、億円以上の数字を抜き出しています。余分な\nを消して、「※~」のような但し書きを消し、正規表現を使って○億△千万円の○だけ抜き出し(str.extract("(.*)億.*"))、最後に、億円未満のため抜き出し条件に該当しないレコードに対してfillna(0)で埋めています。
df['億']=df["価格(万円)1"].str.replace("\n", "").str.replace("※.*","").str.extract("(.*)億.*").fillna(0)
次の処理も同様なのですが、少しハマったのがstr.replace("円","0")の処理。○億円ポッキリ、みたいなレコードはこの前までの処理で"円"という文字列だけが残るので0に置き換えています。
df['万']=df["価格(万円)1"].str.replace("\n", "").str.replace("※.*","").str.replace(".*億","").str.replace("万円","").str.replace("円","0").fillna(0)
あとは結論から。
df['専有面積(m2)']=df['専有面積(m2)1'].str.replace("m2.*","")
df['バルコニー(m2)']=df['バルコニー(m2)1'].str.replace("m2.*","").str.replace("㎡.*","").str.replace("-","0")
df['築年']=df['築年月'].str.split('年', expand=True)[[0]]
df['築月']=df['築年月'].str.split('年', expand=True)[[1]]
df['築月']=df['築月'].str.replace("月", "")
df['住所1']=df['住所'].str.split('都', expand=True)[[0]]
df['住所2']=df['住所'].str.extract(r'都(.*区)')
df['住所3']=df['住所'].str.extract(r'区(.*)')
df['住所4']=df['住所3'].str.replace("[1-9].*","").str.replace("[1-9].*","")#全角半角混じっているので両方置き換え。
df['沿線']=df['最寄り駅徒歩'].str.extract(r'(.*)「')
df['最寄り駅']=df['最寄り駅徒歩'].str.extract(r'「(.*)」')
df['歩(分)']=df['最寄り駅徒歩'].str.extract(r'歩(.*)分')
df['バス(分)']=df['最寄り駅徒歩'].str.replace("歩.*分","").str.extract(r'バス(.*)分').fillna(0)
まあまあきれいに抜き出せています。

不要なカラムを削除。
df=df.drop(['価格(万円)1','専有面積(m2)1','バルコニー(m2)1', '築年月','住所','最寄り駅徒歩'],axis=1)
数字は定量的に解析できるように整理したい。
まずは型変換。
df['億']=df['億'].astype(int)
df['万']=df['万'].astype(int)
df['専有面積(m2)']=df['専有面積(m2)'].astype(float)
df['バルコニー(m2)']=df['バルコニー(m2)'].astype(float)
df['築年']=df['築年'].astype(int)
df['築月']=df['築月'].astype(int)
df['バス(分)']=df['バス(分)'].astype(int)
df['歩(分)']=df['歩(分)'].astype(int)
そして次の計算。
# 価格は1カラムにまとめる。
df['価格(万円)']=df['億']*10000 + df['万']
df=df.drop(['億','万'],axis=1)
# 総面積のカラムも作っておく。(元の情報は残す)
df['総面積(m2)']= df['専有面積(m2)'] + df['バルコニー(m2)']
# 築年月は2021年4月基準、築年数に換算(月も年単位に変換)
df['築年数']= 2021 - df['築年'] + (4 - df['築月'])/12
# バス1分400m, 徒歩1分80mとして距離に換算
df['駅距離km']= df['バス(分)'] * 0.4 + df['歩(分)'] * 0.08
# 単価を計算しておく。
df['平米単価']= df['価格(万円)'] / df['総面積(m2)']
こんな感じの仕上がりに。
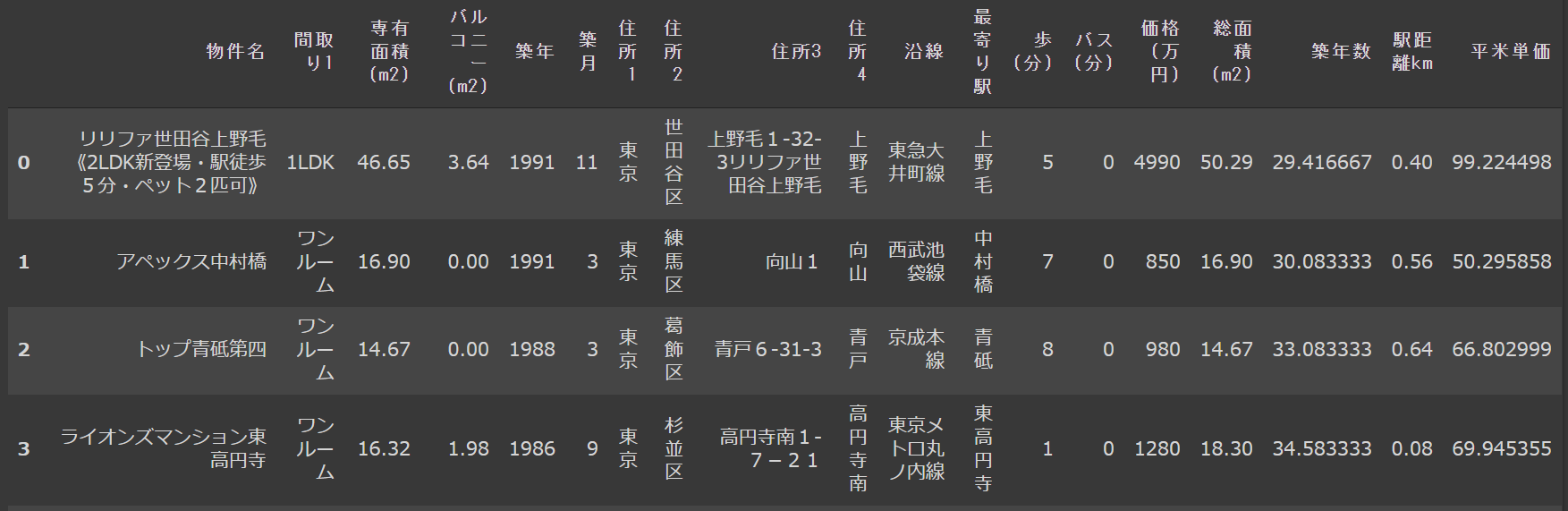
重複データの削除
最後に、複数の不動産会社が登録した同じ部屋のデータがあるので省こうと思います。
まったく同じ間取り、同じ金額の部屋が2つ以上、同じ物件から売りに出ていたら、それは複数の不動産会社による重複登録と区別が付かず、省いてしまったら住所で集計した平均値などずれてしまいますが、確率的に殆ど無かろうと判断。データの重複を省くことにします。
df = df.drop_duplicates(subset=['物件名','価格(万円)','専有面積(m2)','築年数'], keep='first')
df.reset_index(inplace=True, drop=True)
参考情報