はじめに
前回、oneWEXのランカーの概略と操作方法に関する記事(oneWEXの操作メモ_ランカー⑴)を書きました。
今回は、ランカー操作時の考慮点をお伝えします。
ランカー操作時の考慮点
機械学習において有効なデータとは
・トレーニングデータは「矛盾のない」正解データでないといけません
極端な例では、もしトレーニングデータ中のすべての文書で、内容が同じにも関わらず、正解データが異なる場合、エラーになりトレーニングできません
・クエリー文書は教師データと類似したデータ構造を持たなければなりません
ランカーモデルにおける上位K位とは
以下は、Admin Consoleのランカー管理画面です。
ランカーモデルに現れる上位K位の意味を説明します。
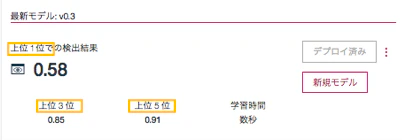
・上位K位とは、ランカーが正解類似文書を検索する精度を評価する数字であり、ランキング結果の中で、テストクエリーに対する正解類似文書が上位K位以内に少なくとも1つ以上含まれる確率です
・医療カルテデータを例に、上位K位の求め方をご説明します
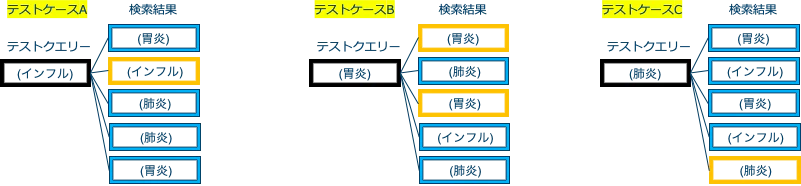
上位1位の値は、1/3=0.33
(3つのテストケースのうち、上位1位以内に正解類似文書が含まれるのは、テストケースBの1つのため)
上位3位の値は、2/3=0.66
(3つのテストケースのうち、上位3位以内に正解類似文書が含まれるのは、テストケースAとBの2つのため)
上位5位の値は、3/3=1.0
(3つのテストケースのうち、上位5位以内に正解類似文書が含まれるのは、テストケースAとBとCの3つのため)
上位10位の値は、3/3=1.0
(3つのテストケースのうち、上位10位以内に正解類似文書が含まれるのは、テストケースAとBとCの3つのため)
ランカー作成における注意点⑴
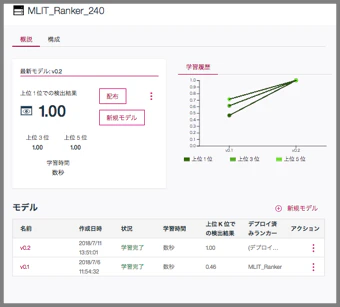
・ランカー精度向上時、新旧の教師データ間で重複を含むデータを入れてはいけません
テスト・データセットは変更されない(1度目にインポートした教師データからテストクエリーが作られ、以後固定される)ため、重複するデータ値を持つ教師データを追加した場合、必ず上位に正解文書がランキングされ、正しく上位K位が算出されません
下の例は、誤って新旧の教師データ間で重複を含むデータをインポートした場合です。
(1度目に240件、2度目に2400件(一度目の240件と重複するデータを含む)の教師データを追加)
ランカー作成における注意点⑵
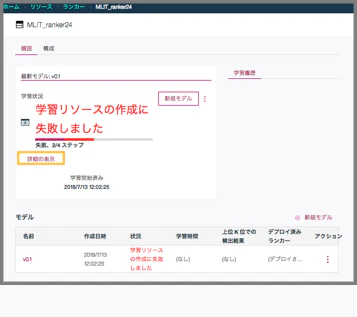
学習リソースの作成に失敗する場合、「詳細の表示」から学習エラーの詳細を確認します


ランカー作成における注意点⑶
コレクション作成完了後に、適用するコレクション・テンプレートやランカーの変更はできません
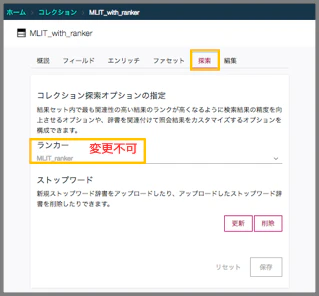
分類器とランカー両方を適用したコレクションを作成する場合、まずランカーをコレクションに適用し、その後コレクション管理画面で分類器を追加します。追加後はコレクションで索引の再作成を行います
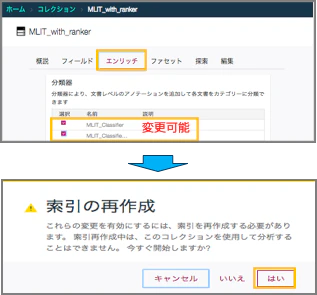
ランカー作成における注意点⑷
ランカーを適用していないコレクションでも類似文書検索は可能です。
ただしランカーがない場合は、すべてのフィールドが等しく扱われてランキングのスコアが決まります。
ランカーがある場合は、機械学習結果によって得られたフィールドの重み付けを加味してスコアが決まります。