TL;DR
- PythonとFastAPIを使用してRESTfulAPIを開発
- 株価を予測するための基本的な機械学習モデルを構築
- FastAPIアプリをHerokuにデプロイし,ホスティングを確認
FastAPIとは
2018年12月にリリースされたPython製APIフレームワークです
https://fastapi.tiangolo.com/
特徴としては,Node.jsやGoと同等のパフォーマンス性能でかつFlaskライクな書き方で簡単にAPI構築することができます.
ハッカソンなど時間が限られた開発で有効なフレームワークだと思います
詳細については公式ドキュメントの機能ガイドを確認してください.また,FastAPIが他のWebフレームワークや技術とどのように異なるのかを詳しく説明している,Alternatives, Inspiration and Comparisonsを確認することをお勧めします.
準備
「fastapi-heroku」というプロジェクトフォルダを作成します.
$ mkdir fastapi-heroku
$ cd fastapi-heroku
次に,新しいPythonの仮想環境を作成して有効化します.
$ python3.8 -m venv env
$ source env/bin/activate
依存関係をインストールするためにrequirements.txtを作成します.
fastapi==0.58.1
uvicorn==0.11.5
作成した依存関係ファイルに基づきパッケージのインストールを行います.
$ pip install -r requirements.txt
次に,動作確認を行うために簡単なAPI処理を書いたmain.pyを作成します.
from fastapi import FastAPI
app = FastAPI()
@app.get("/ping")
def pong():
return {"ping": "pong!"}
アプリを起動します.
$ uvicorn main:app --reload --workers 1 --host 0.0.0.0 --port 8080
上記uvicornコマンドでは次のような設定を行いました.
-
--reload自動リロードを有効にして,コードに変更が加えられたときサーバが再起動する -
--workers 1シングルワーカープロセスを提供する -
--host 0.0.0.0サーバをホストするアドレスを定義する -
--port 8080サーバをホストするポートを定義する
正常に動作していれば,下記URLにアクセス出来るはずです.
http://localhost:8080/ping
このような結果が出力されていればOKです
{
"ping": "pong!"
}
MLモデル
展開するモデルは,Prophetを使用して株式市場の価格を予測します.
次の関数を追加して,モデルを学習し,model.pyという新しいファイルに予測を生成します.
import datetime
from pathlib import Path
import joblib
import pandas as pd
import yfinance as yf
from fbprophet import Prophet
BASE_DIR = Path(__file__).resolve(strict=True).parent
TODAY = datetime.date.today()
def train(ticker="MSFT"):
# data = yf.download("^GSPC", "2008-01-01", TODAY.strftime("%Y-%m-%d"))
data = yf.download(ticker, "2020-01-01", TODAY.strftime("%Y-%m-%d"))
data.head()
data["Adj Close"].plot(title=f"{ticker} Stock Adjusted Closing Price")
df_forecast = data.copy()
df_forecast.reset_index(inplace=True)
df_forecast["ds"] = df_forecast["Date"]
df_forecast["y"] = df_forecast["Adj Close"]
df_forecast = df_forecast[["ds", "y"]]
df_forecast
model = Prophet()
model.fit(df_forecast)
joblib.dump(model, Path(BASE_DIR).joinpath(f"{ticker}.joblib"))
def predict(ticker="MSFT", days=7):
model_file = Path(BASE_DIR).joinpath(f"{ticker}.joblib")
if not model_file.exists():
return False
model = joblib.load(model_file)
future = TODAY + datetime.timedelta(days=days)
dates = pd.date_range(start="2020-01-01", end=future.strftime("%m/%d/%Y"),)
df = pd.DataFrame({"ds": dates})
forecast = model.predict(df)
model.plot(forecast).savefig(f"{ticker}_plot.png")
model.plot_components(forecast).savefig(f"{ticker}_plot_components.png")
return forecast.tail(days).to_dict("records")
def convert(prediction_list):
output = {}
for data in prediction_list:
date = data["ds"].strftime("%m/%d/%Y")
output[date] = data["trend"]
return output
ここでは,次の3つの関数を定義しました.
train
yfinanceを使用して過去の株式データをダウンロードし,新しいProphetモデルを作成します.
作成したモデルを株式データに適用させてから,モデルをシリアル化させ,Joblibファイルとして保存します.
predict
保存したモデルを読み込み逆シリアル化します.
新しい予測を生成し,予測プロットと予測コンポーネントの画像を作成し、予測に含まれる日数をdictリストとして返します.
convert
predictからdictリストを取得し,日付と予測値のdictを出力します.
例えば,{"12/09/2020": 200}
依存関係の更新
requirements.txtに依存関係を新しく追加します.
fastapi==0.58.1
uvicorn==0.11.5
fbprophet==0.6
joblib==0.16.0
pandas==1.0.5
plotly==4.8.2
yfinance==0.1.54
仮想環境に追加したパッケージをインストールします.
$ pip install -r requirements.txt
モデルのテスト
新しいPythonシェルを開き,次のコマンドを実行します
$ python
>>> from model import train, predict, convert
>>> train()
>>> prediction_list = predict()
>>> convert(prediction_list)
次のようなものが表示されます.
{
'12/11/2020': 212.64344057979804,
'12/12/2020': 212.67327416296965,
'12/13/2020': 212.70310774614126,
'12/14/2020': 212.73294132931287,
'12/15/2020': 212.76277491248447,
'12/16/2020': 212.79260849565608,
'12/17/2020': 212.8224420788277
}
以下の画像は,Microsoft Corporation(MSFT)の今後7日間の予測価格です.MSFT.joblibモデルと2つの画像が保存されます.
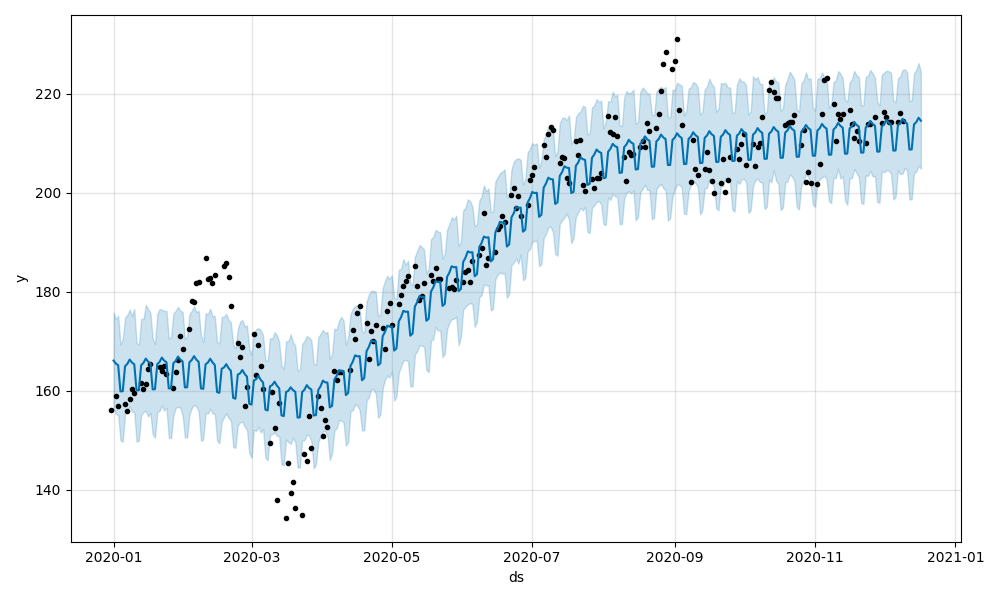
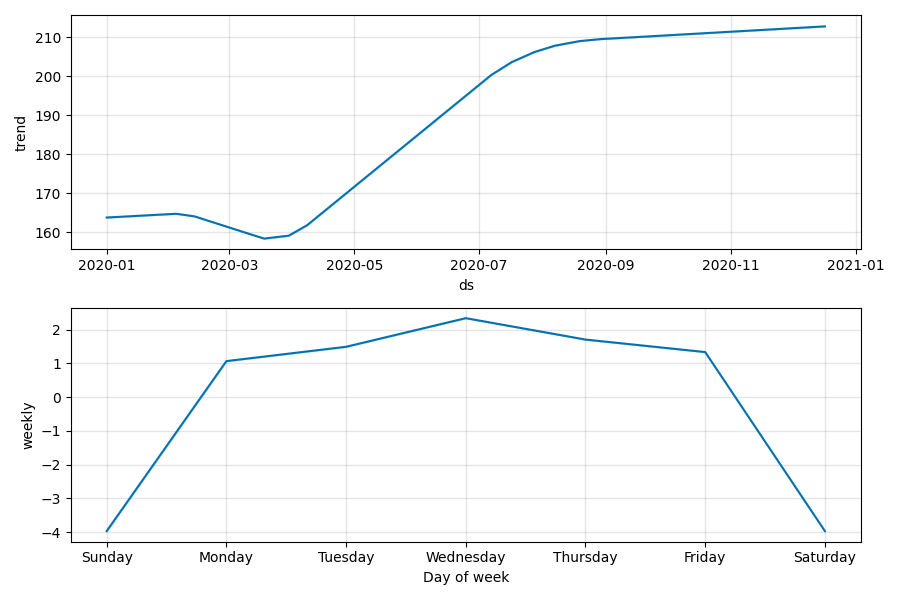
モデルに対してさらにトレーニングを実行
>>> train("GOOG")
>>> train("AAPL")
>>> train("^GSPC")
上記コマンド実行後,シェルを終了します.
FastAPIにMLモデルを組み込む
次のようにmain.pyに/predictエンドポイントを追加してみましょう.
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from model import convert, predict
app = FastAPI()
# pydantic models
class StockIn(BaseModel):
ticker: str
class StockOut(StockIn):
forecast: dict
# routes
@app.get("/ping")
async def pong():
return {"ping": "pong!"}
@app.post("/predict", response_model=StockOut, status_code=200)
def get_prediction(payload: StockIn):
ticker = payload.ticker
prediction_list = predict(ticker)
if not prediction_list:
raise HTTPException(status_code=400, detail="Model not found.")
response_object = {"ticker": ticker, "forecast": convert(prediction_list)}
return response_object
新しく作成したget_prediction関数では,モデルのpredict関数にティッカー(銘柄コード)を渡し,convert関数を使用して応答オブジェクトを作成します.
また,Pydanticスキーマを利用して,JSONペイロードをStockInオブジェクトスキーマに変換しました.これにより,型検証が自動で行われます.
応答オブジェクトはStockOutスキーマオブジェクトを使用してPythondict---{"ticker": ticker, "forecast": convert(prediction_list)}をJSONに変換します.これも,同様に型検証されます.
アプリの実行
下記コマンドを実行し,APIサーバを起動します.
$ uvicorn main:app --reload --workers 1 --host 0.0.0.0 --port 8080
特にエラーが発生しなければ大丈夫です.
動作チェック
次の,curlコマンドを実行してみましょう.
$ curl \
--header "Content-Type:application/json" \
--request POST \
--data '{"ticker": "MSFT"}' \
http://localhost:8080/predict
次のようなものが表示されるはずです.
{
"forecast": {
'12/11/2020': 212.64344057979804,
'12/12/2020': 212.67327416296965,
'12/13/2020': 212.70310774614126,
'12/14/2020': 212.73294132931287,
'12/15/2020': 212.76277491248447,
'12/16/2020': 212.79260849565608,
'12/17/2020': 212.8224420788277
},
"ticker": "MSFT"
}
ティッカーモデルが存在しない場合は次のように表示されます.
$ curl \
--header "Content-Type: application/json" \
--request POST \
--data '{"ticker":"NONE"}' \
http://localhost:8080/predict
{
"detail": "Model not found."
}
Herokuへデプロイ
Herokuは,Webアプリケーションのホスティングを提供するPlatform as a Service(PaaS)です.
これらは,基盤となるインフラストラクチャを管理する必要がない抽象化された環境を提供し,Webアプリケーションの管理,デプロイ,およびスケーリングを容易にします.数回クリックするだけで,アプリを起動して実行,トラフィックを受信する準備を整えることができます.
ログイン
Herokuアカウントにサインアップし(まだアカウントを持っていない場合),Heroku CLIをインストールします(まだインストールしていない場合).
次に,CLIを介してHerokuアカウントにログインします.
$ heroku login
ログインを完了するには,任意のキーを押してWebブラウザを開くように求められます.
デプロイ準備
gitがインストールされていると仮定して,新しいgitリポジトリを初期化します.
$ git init
次に,.gitignoreファイルを追加します.
__pycache__
env
ファイルをステージングし,新しいコミットを作成します.
$ git add -A
$ git commit -m "init"
Heroku上にアプリを作成する
$ heroku create
成功すると,次のように表示されます.
Creating app... done, ⬢ salty-escarpment-xxxxx
https://salty-escarpment-xxxxx.herokuapp.com/ | https://git.heroku.com/salty-escarpment-xxxxx.git
git remoteにherokuへのリモートが反映されていることを確認
$ git remote -v
Herokuのhttps://git.heroku.com/salty-escarpment-xxxxx.git (fetch)
Herokuのhttps://git.heroku.com/salty-escarpment-xxxxx.git (push)
最後に,Procfile(拡張子なし)を作成して,起動時にHerokuで実行するコマンドを指定します.
web: gunicorn -w 3 -k uvicorn.workers.UvicornWorker main:app
ここでは,本番環境用途のWSGIアプリケーションサーバであるGunicornを使用して,3つのワーカープロセスでUvicornを起動します.
この構成は,並行性(Uvicorn経由)と並列処理(Gunicornワーカー経由)の両方を利用します.
次に,requirements.txtを更新します
fastapi==0.58.1
gunicorn==20.0.4
uvicorn==0.11.5
fbprophet==0.6
joblib==0.16.0
pandas==1.0.5
plotly==4.8.2
yfinance==0.1.54
これまでの変更をコミットします.
$ git add -A
$ git commit -m "add procfile"
デプロイ
コードをpushしてHerokuへデプロイします.
$ git push heroku master
これで,アプリを表示できるようになります.
動作チェック
curlコマンドで/predictエンドポイントを叩いてテストしてみましょう.
$ curl \
--header "Content-Type: application/json" \
--request POST \
--data '{"ticker":"MSFT"}' \
https://<YOUR_HEROKU_APP_NAME>.herokuapp.com/predict
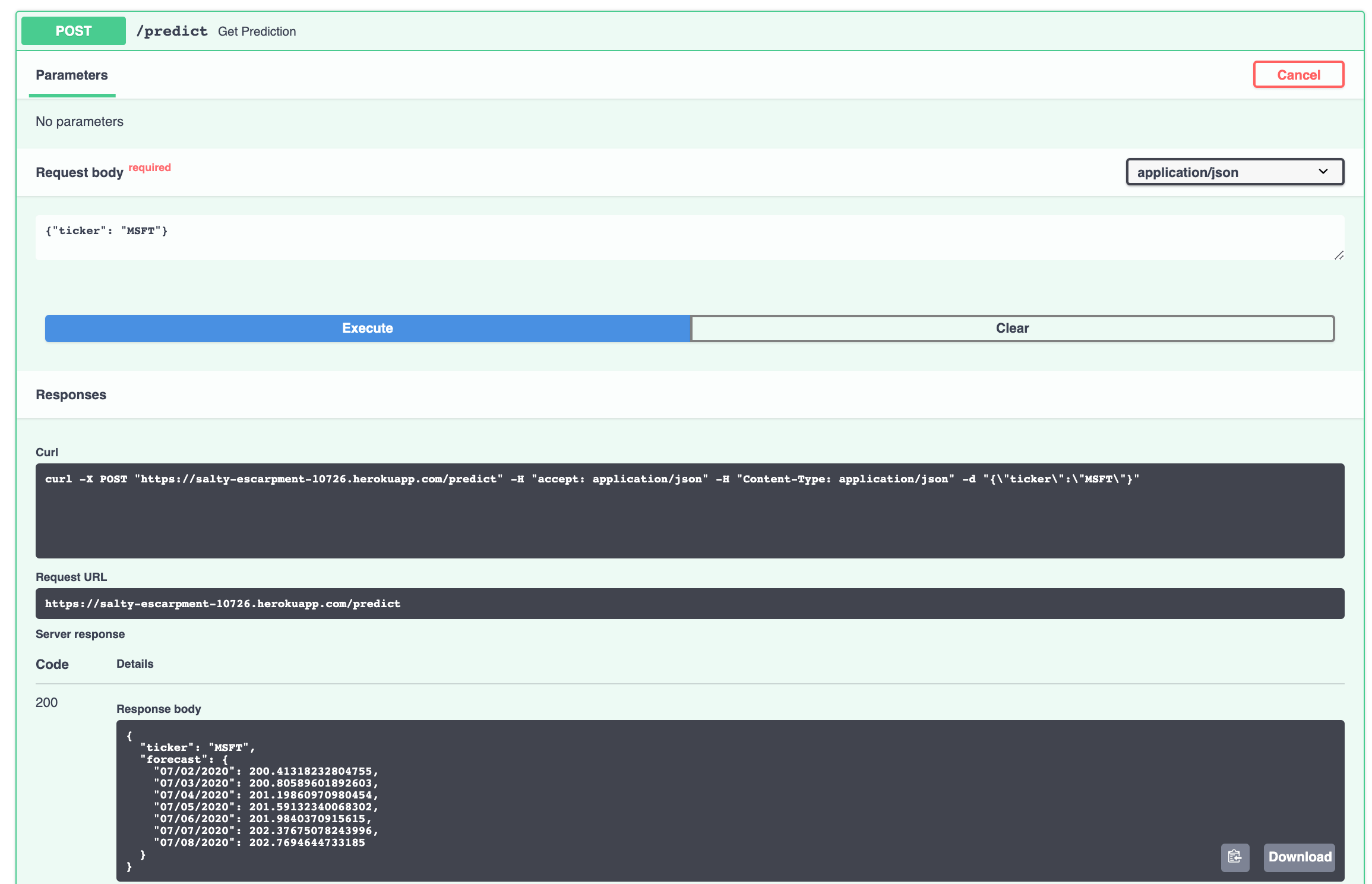
FastAPIでは自動でAPIドキュメントが生成されます.
ここからも実行して確認することができます.
まとめ
本記事では,株価を予測するための機械学習モデルを,FastAPIを利用してHerokuの本番環境へデプロイする方法を説明しました.
機械学習はPythonで書かれることが多いため,Python性フレームワークであるFastAPIと親和性が高いです.また,今回記述したコードを見ていただければ分かる通り,シンプルに書くことができデプロイも非常に簡単なため全人類に強くおすすめします.