概要
日本語NLPライブラリGiNZAでリリースされたja-ginza-electraモデルでは従来のja-ginzaに比べて精度が向上したようです。
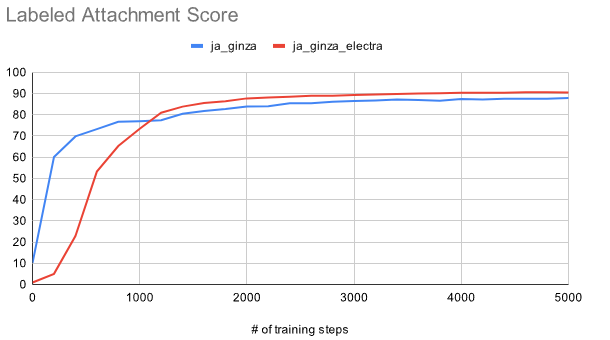
(出典:https://megagonlabs.github.io/ginza/)
ただ、速度面でどの程度差があるのか気になったので、本記事では両者速度を比較してみました。
準備
python = "^3.9"
pip install ja-ginza = "^5.0.0"
pip install ja-ginza-electra = "^5.0.0"
コード
検証のために下記コードを用意
それぞれのモデルごとにトークン化を実施し、その際にかかった秒数をそれぞれ計測します。
main.py
import time
import spacy
def use_ja_ginza(text, cache=None):
nlp = spacy.load('ja_ginza') if cache is None else cache
[token for token in nlp(text)]
return nlp
def use_ja_ginza_electra(text, cache=None):
nlp = spacy.load('ja_ginza_electra') if cache is None else cache
[token for token in nlp(text)]
return nlp
def stopwatch(func, times=100):
# 桃太郎 芥川龍之介 https://www.aozora.gr.jp/cards/000879/card100.html
s = 'むかし、むかし、大むかし、ある深い山の奥に大きい桃《もも》の木が一本あった。大きいとだけではいい足りないかも知れない。この桃の枝は雲の上にひろがり、この桃の根は大地《だいち》の底の黄泉《よみ》の国にさえ及んでいた。何でも天地|開闢《かいびゃく》の頃《ころ》おい、伊弉諾《いざなぎ》の尊《みこと》は黄最津平阪《よもつひらさか》に八《やっ》つの雷《いかずち》を却《しりぞ》けるため、桃の実《み》を礫《つぶて》に打ったという、――その神代《かみよ》の桃の実はこの木の枝になっていたのである。'
time_s = time.perf_counter()
cache = None
for i in range(times):
cache = func(s, cache)
time_e = time.perf_counter()
return time_e - time_s
def main():
d = {
'ja-ginza': stopwatch(use_ja_ginza),
'ja-ginza-electra': stopwatch(use_ja_ginza_electra)
}
d = sorted(d.items(), key=lambda x: x[1])
print('\n'.join(map(str, d)))
if __name__ == '__main__':
main()
結果
結果は以下の通り、ja-ginza-electra は ja-ginzaと比べて4倍弱遅いことがわかりました。
$ python main.py
('ja-ginza', 6.013060999999652)
('ja-ginza-electra', 22.437576700000136)
まとめ
精度面で向上した反面、速度はかなり遅いようです。
ja-ginza-electraを選択する際の参考になればと思います。