最小二乗推定
通常の最小二乗推定(OLSE)は、線形回帰において、残差の二乗和を最小化する回帰線のパラメータを推定するための方法です。
従属変数Yと独立変数Xを持つ単純な線形回帰モデルを考えてみましょう。YとXの関係を見つけたいとします。ノイズがない完全な世界では、YはXの3倍かもしれません。しかし、現実には常にノイズや誤差項が存在します。したがって、観測されるYは3Xにランダムなノイズを加えたものです。
この関係を推定するためにOLSEを使用することができます。Pythonでは、ランダムなX値を生成し、真のY値(3X)を計算し、ランダムなノイズを加えて観測されるY値を得ることができます。そして、numpy.polyfit関数を使用して回帰を行います。以下に例を示します。
import numpy as np
import matplotlib.pyplot as plt
# ランダムなX値を生成
X = np.random.uniform(-1, 1, 100)
# 真のY値を計算
Y_true = 3 * X
# ランダムなノイズを加えて観測されるY値を得る
Y_obs = Y_true + np.random.uniform(-1, 1, 100)
# numpy.polyfitを使用して回帰を行う
coeffs = np.polyfit(X, Y_obs, 1)
# 推定された係数を表示
print(f"Estimated coefficients: {coeffs}")
# 観測データと推定された回帰線をプロット
plt.scatter(X, Y_obs, label='Observed data')
plt.plot(X, coeffs[0]*X + coeffs[1], 'r-', label='Estimated regression line')
plt.legend()
plt.show()
この例では、推定された係数は真の係数である[3, 0]に近いはずです。プロットは観測データ点と推定された回帰線を表示します。線は真の関係Y = 3Xに近いはずで、これはOLSEがノイズの存在下で真の関係を効果的に推定できることを示しています。

推定量における満たすべき性質
最小二乗推定量(OLS)の性質について説明します。
一定の条件のもとで OLS推定量は 「不偏性」「一致性」「漸近正規性」 と いわれる統計的に望ましい性質を持つことを証明することができます。
具体的には、下記の性質を満たします。
-
不偏性: OLS推定量は不偏であると言われます。これは、OLSが真のパラメータを推定するための期待値であることを意味します。つまり、多数のサンプルを取り、それぞれのサンプルに対してOLSを適用し、その結果を平均すると、真のパラメータに非常に近い値が得られることを意味します。
-
一致性: OLS推定量は一致すると言われます。これは、サンプルサイズが増えるにつれて、OLS推定量が真のパラメータに収束することを意味します。つまり、無限に多くのデータがある場合、OLS推定量は真のパラメータに等しくなります。
-
漸近正規性: OLS推定量は漸近的に正規分布に従うと言われます。これは、サンプルサイズが大きくなるにつれて、OLS推定量の分布が正規分布に近づくことを意味します。これは、大数の法則と中心極限定理によるものです。
以下に、これらの性質を示すPythonコードを示します。このコードでは、単純な線形回帰モデルを考え、OLSを用いてパラメータを推定します。そして、不偏性、一致性、漸近正規性を視覚的に確認します。
まず不偏性と一致性についてです。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# 真のパラメータ
true_beta = 3
# サンプルサイズ
sample_sizes = np.arange(10, 1001, 10)
# OLS推定量を格納するリスト
ols_estimates = []
for n in sample_sizes:
# 独立変数
X = np.random.normal(size=n)
# 誤差項
epsilon = np.random.normal(size=n)
# 従属変数
Y = true_beta * X + epsilon
# OLS推定量
beta_hat = np.sum(X * Y) / np.sum(X**2)
ols_estimates.append(beta_hat)
# 不偏性と一致性を確認
plt.figure(figsize=(10, 5))
plt.plot(sample_sizes, ols_estimates, label='OLS estimates')
plt.axhline(y=true_beta, color='r', linestyle='--', label='True parameter')
plt.xlabel('Sample size')
plt.ylabel('Parameter estimate')
plt.title('Unbiasedness and Consistency of OLS')
plt.legend
以下のグラフは、サンプルサイズが増えるにつれて、OLS推定量が真のパラメータに収束することを示しています。これはOLS推定量の一致性を示しています。

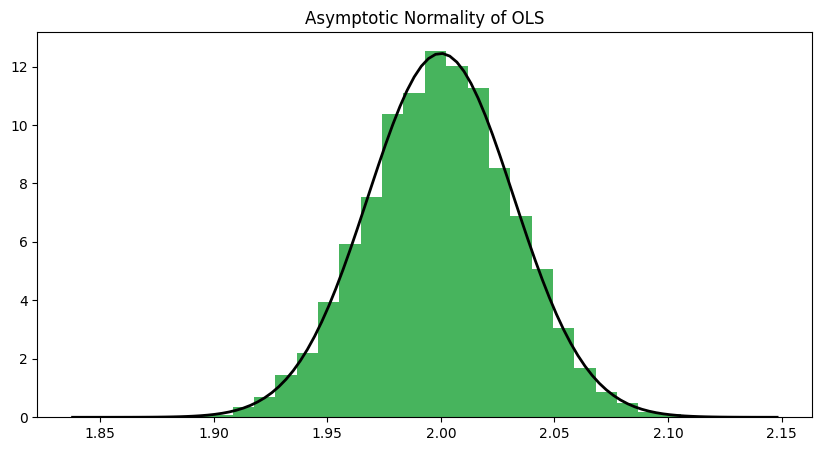
次に、OLS推定量の分布が正規分布に近づくことを示すために、大きなサンプルサイズ(例えば、n=1000)で多数のOLS推定量を生成し、そのヒストグラムをプロットします。これはOLS推定量の漸近正規性を示しています。
# 大きなサンプルサイズ
n = 1000
# OLS推定量を格納するリスト
ols_estimates_large_sample = []
# 多数のOLS推定量を生成
for _ in range(10000):
# 独立変数
X = np.random.normal(size=n)
# 誤差項
epsilon = np.random.normal(size=n)
# 従属変数
Y = true_beta * X + epsilon
# OLS推定量
beta_hat = np.sum(X * Y) / np.sum(X**2)
ols_estimates_large_sample.append(beta_hat)
# ヒストグラムをプロット
plt.figure(figsize=(10, 5))
plt.hist(ols_estimates_large_sample, bins=30, density=True, alpha=0.6, color='g')
# 正規分布の確率密度関数をプロット
xmin, xmax = plt.xlim()
x = np.linspace(xmin, xmax, 100)
p = norm.pdf(x, true_beta, np.std(ols_estimates_large_sample))
plt.plot(x, p, 'k', linewidth=2)
plt.title('Asymptotic Normality of OLS')
plt.show()
このコードは、大きなサンプルサイズで多数のOLS推定量を生成し、そのヒストグラムをプロットします。また、OLS推定量の標準偏差を用いて正規分布の確率密度関数をプロットします。ヒストグラムが確率密度関数に従って形成されることから、OLS推定量が漸近的に正規分布に従うことが確認できます。