Haskell で SQLite3 を操作したくなったので、ライブラリをいくつか調べてみました。
TL;DR
- persistent-sqlite は SQL を書かなくてもいいけど、代わりにきめ細かいことができないよ
- direct-sqlite ははっきり言って使いにくいのでオススメしないよ
- sqlite-simple は簡単につかえて細かいこともできるよ
- サンプルは GitHub にあるよ
- もし時間があればコメントまで読んでね
はじめに
Hackage を sqlite で検索して、SQLite3 に対応していて、メンテナンスがされていて、2017 年 12 月 21 日時点でダウンロード数1の多いものからとりあえず 3 つ、使い方を調べてみました。
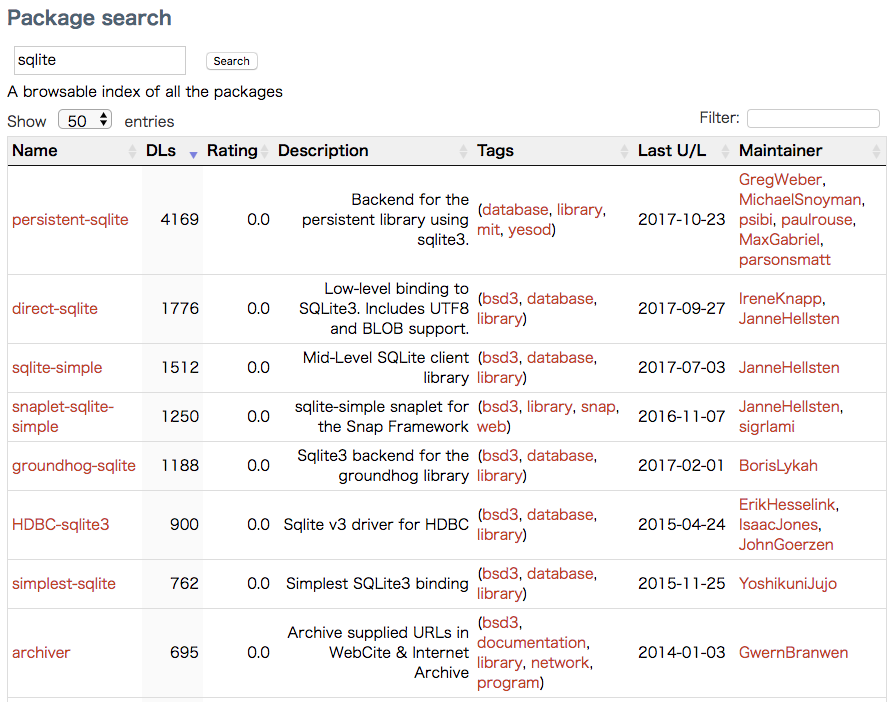
他にオススメがあれば是非教えてください。
調査指針
以下ができることを確認します。
- データベースの作成(ファイル生成)
- テーブルの作成
- レコードの追加
- レコードの検索
- レコードの更新
- レコードの削除
作成するテーブルは以下の構造とします。
CREATE TABLE file
( path TEXT PRIMARY KEY
, size INTEGER
, digest TEXT
);
プログラムは以下を行うものとします。
- なければデータベースとテーブルを作成
- レコードをいくつか追加
- 条件をつけてレコードを検索
- 検索結果のレコードを更新
- 再び条件をつけてレコードを検索
- レコードを全件削除
persistent-sqlite
persistent-sqlite は Yesod で使われているライブラリで、今回調べた中ではダントツのダウンロード数でした。
使い方は以下のとおりです。
{-# LANGUAGE GADTs #-}
{-# LANGUAGE GeneralizedNewtypeDeriving #-}
{-# LANGUAGE MultiParamTypeClasses #-}
{-# LANGUAGE OverloadedStrings #-}
{-# LANGUAGE QuasiQuotes #-}
{-# LANGUAGE TemplateHaskell #-}
{-# LANGUAGE TypeFamilies #-}
import Control.Monad.IO.Class (liftIO)
import Database.Persist.Sqlite ( (=.)
, (==.)
, Entity(..)
, Filter
, SelectOpt(Asc)
, deleteWhere
, insert
, runMigration
, runSqlite
, selectList
, update
)
import Database.Persist.TH ( mkMigrate
, mkPersist
, persistLowerCase
, share
, sqlSettings
)
share [mkPersist sqlSettings, mkMigrate "migrateAll"] [persistLowerCase|
File
path String
size Int Maybe
digest String Maybe
Path path
deriving Show
|]
main :: IO ()
main = runSqlite "persistent-sqlite.sqlite3" $ do
let dummySize = Just 100
runMigration migrateAll
_ <- insert $ File "/foo.txt" dummySize Nothing
_ <- insert $ File "/bar.txt" Nothing Nothing
_ <- insert $ File "/baz.txt" dummySize Nothing
fileList <- selectList [FileSize ==. dummySize] [Asc FileId]
mapM_ updateDigest fileList
fileListWithDigest <- selectList [FileDigest ==. dummyDigest] [Asc FilePath]
liftIO $ mapM_ printFilePath fileListWithDigest
deleteWhere ([] :: [Filter File])
where
updateDigest (Entity key (File path _ _)) = do
digest <- liftIO $ getDigest path
update key [FileDigest =. digest]
dummyDigest = Just "349a0426747b3b8c3583664a0ca66b6f"
getDigest _ = return dummyDigest
printFilePath (Entity _ (File path _ _)) = putStrLn path
今回調べた中では SQL レスでコードが書けるので、いい感じではあるのですが、細かいことが苦手です。例えば、作りたかったテーブルは以下なのですが:
CREATE TABLE file
( path TEXT PRIMARY KEY
, size INTEGER
, digest TEXT
);
runMigration で生成するテーブルは:
CREATE TABLE "file"
( "id" INTEGER PRIMARY KEY
, "path" VARCHAR NOT NULL
, "size" INTEGER NULL
, "digest" VARCHAR NULL
, CONSTRAINT "path" UNIQUE ("path")
);
相当になります。データの管理方法が、レコードのキーとレコードのデータ、という具合に分離されているため、レコードの特定のフィールドがレコードのキー、というようなデータ構造は扱えないのかもしれません。
レコードが Haskell の型として定義できる、runSqlite というモナドコンテキストがある、というところは良い感じです。細かいですが、マイグレーション時に以下のように標準出力されるのはイケてません。
Migrating: CREATE TABLE "file"("id" INTEGER PRIMARY KEY,"path" VARCHAR NOT NULL,"size" INTEGER NULL,"digest" VARCHAR NULL,CONSTRAINT "path" UNIQUE ("path"))
direct-sqlite
direct-sqlite は、その名の通りかなりローレベルなライブラリです。
{-# LANGUAGE OverloadedStrings #-}
import qualified Data.ByteString as BI
import Database.SQLite3.Direct ( Utf8(Utf8)
, close
, exec
, execWithCallback
, open
)
import Codec.Binary.UTF8.String ( encode
, decode
)
main :: IO ()
main = do
edb <- open "direct-sqlite.sqlite3"
case edb of
Left (_, Utf8 msg) -> putStrLn $ decode (BI.unpack msg)
Right db -> do
_ <- exec db $ Utf8 "create table file (path text primary key, size integer, digest text)"
_ <- exec db $ Utf8 "insert into file values ('/foo.txt', 100, null)"
_ <- exec db $ Utf8 "insert into file values ('/bar.txt', null, null)"
_ <- exec db $ Utf8 "insert into file values ('/baz.txt', 100, null)"
_ <- execWithCallback db (Utf8 "select path from file where size = 100") (\_ _ [value] -> updateDigest db value)
_ <- execWithCallback db (Utf8 "select path from file where digest = '349a0426747b3b8c3583664a0ca66b6f'") (\_ _ [value] -> print value)
_ <- exec db $ Utf8 "delete from file"
close db
return ()
where
updateDigest _ Nothing = return ()
updateDigest db (Just (Utf8 path)) = do
_ <- exec db $ Utf8 (BI.pack $ encode ("update file set digest = '349a0426747b3b8c3583664a0ca66b6f' where path = '" ++ (decode $ BI.unpack path) ++ "'"))
return ()
これは、かなり使いづらいです。使いづらい点をいくつか列挙します。
- SQL を書くのは良いが、その文字列が Data.ByteString であること
- アプリ内では String や Data.Text も使うので文字列変換が煩わしいこと
- いちいちエラーチェックをしなければならないこと、あるいは無視しなければならないこと
- プレースホルダが使えないこと
ライブラリの文字列インターフェイスが Data.ByteString なのはかなりのマイナスポイントです。Data.ByteString は名前こそ String ですが、実際はバイナリなので、文字列を受け取るインターフェイスにはふさわしくありません。そのくせ所々、文字列の指定が Data.Text だったりもします。全部 Data.Text になっていれば良かったのですが。
生 SQL を渡す関係で、exec や execWithCallback はエラーを返す可能性があります。渡した SQL が絶対に間違っていない、データの不整合がないのであればエラーは無視できますが、それをアプリ側で保証するのはかなり大変です。かと言ってすべての実行結果の成否をハンドリングするのもまた大変です。
あと、プレースホルダがどうしても使えませんでした。以下のようないくつかの方法が提供されていますが、どれも実行自体は成功していますが、レコードが更新されませんでした。
updateDigest db (Just (Utf8 path)) = do
stmt <- DB.prepare db "update file set digest = ? where path = ?"
DB.bind stmt [DB.SQLBlob "349a0426747b3b8c3583664a0ca66b6f", DB.SQLBlob path]
_ <- DB.step stmt
DB.finalize stmt
return ()
updateDigest db (Just (Utf8 path)) = do
stmt <- DB.prepare db "update file set digest = ? where path = ?"
DB.bindSQLData stmt 1 $ DB.SQLBlob "349a0426747b3b8c3583664a0ca66b6f"
DB.bindSQLData stmt 2 $ DB.SQLBlob path
_ <- DB.step stmt
DB.finalize stmt
return ()
updateDigest db (Just (Utf8 path)) = do
stmt <- DB.prepare db "update file set digest = :digest where path = :path"
DB.bindNamed stmt [(":digest", DB.SQLBlob "349a0426747b3b8c3583664a0ca66b6f"), (":path", DB.SQLBlob path)]
_ <- DB.step stmt
DB.finalize stmt
return ()
※ ここで DB とは Database.SQLite3 のエイリアスです。
なので、今回のサンプルはプレースホルダは使わずに、文字列連結で SQL を構築しています。これはかなり危ないので絶対にやってはいけません。
sqlite-simple
sqlite-simple は Haskell のデータベースバインディングのシンプルシリーズ(と勝手に呼んでいるもの)のひとつです。sqlite-simple の他には、mysql-simple、postgresql-simple があり、それぞれ作者は違うのですが、かなり似たインターフェイスを提供しています。
{-# LANGUAGE OverloadedStrings #-}
import Control.Exception.Safe (catch)
import Database.SQLite.Simple ( FromRow(..)
, Only(..)
, ToRow(..)
, close
, execute
, execute_
, open
, query
, SQLError(..)
)
import Database.SQLite.Simple.FromRow (field)
data File = File String (Maybe Int) (Maybe String) deriving Show
instance FromRow File where
fromRow = File <$> field <*> field <*> field
instance ToRow File where
toRow (File path size digest) = toRow (path, size, digest)
main :: IO ()
main = do
conn <- open "sqlite-simple.sqlite3"
(execute_ conn "create table file (path text primary key, size integer, digest text)") `catch` (const $ return () :: SQLError -> IO ())
execute conn "insert into file values (?, ?, ?)" (File "/foo.txt" (Just 100) Nothing)
execute conn "insert into file values (?, ?, ?)" (File "/bar.txt" Nothing Nothing)
execute conn "insert into file values (?, ?, ?)" (File "/baz.txt" (Just 100) Nothing)
rs1 <- query conn "select * from file where size = ?" (Only (100 :: Integer)) :: IO [File]
mapM_ (\(File path _ _) -> updateDigest conn path) rs1
rs2 <- query conn "select * from file where digest = ?" (Only ("349a0426747b3b8c3583664a0ca66b6f" :: String)) :: IO [File]
mapM_ (\(File path _ _) -> putStrLn path) rs2
execute_ conn "drop table file"
close conn
where
updateDigest conn path = execute conn "update file set digest = ? where path = ?" ("349a0426747b3b8c3583664a0ca66b6f" :: String, path)
コードの作りは direct-sqlite に似ていますが、以下のような優位性があります。
- レコードの型が Haskell のデータとして表せる
- レコードの追加で Haskell のデータを渡して、コンパイル時に型チェックが行える
- レコードの検索を Haskell のデータとして受け取れるので、すぐに値が使える
- プレースホルダが使える、使いやすい
このように全体的に使いやすい設計になっているのですが、それ故のトレードオフがあります。例えば、open でパーミッションの無いパスを渡した場合、エラーが発生します。SQL が間違っていた場合やプレースホルダの数が間違っていた場合にもエラーになります。このサンプルでは処理の冒頭で毎回テーブルを生成していますが、既にテーブルが存在する場合はエラーになるため、例外をキャッチしてなかったことにしています。
戻り値の Either をチェックするのか、必要に応じて例外をキャッチするのか、というポリシーの違いですが、エラーをハンドリングする場合でもしない場合でも、後者のほうが圧倒的に簡潔に書けます。
まとめ
persistent-sqlite は使いやすいのですが Yesod のコンテキストを引きずっているので、設計をライブラリ側に合わせなければならないと感じました。具体的にはテーブル設計が自由にできないので、これは結構痛いです。ただ、メンテナが多いので、めちゃくちゃ安心感はあります。
direct-sqlite はとにかく使いづらいです。本当にオススメしません。
sqlite-simple は私が mysql-simple を使ったことがあるというバイアスがあるものの、それを除いても使いやすいライブラリだと思います。ただし「今時 SQL 書くのダサい」と思われる方もいるかもしれません。今回の用途なら NoSQL でも良かったのですが、SQLite のデータベースが単一ファイルになる、という特性も今回必要だったのです。
なお、今回の完全なサンプルコードは以下の GitHub に置いてあります。
参考資料
以下に参考にした資料の URL を貼っておきます。
persistent-sqlite
-
http://hackage.haskell.org/package/persistent-sqlite
- Hackage
- API 仕様を調べるのに参照した
-
https://www.yesodweb.com/book/persistent
- Yesod の Persistent のページ
- ここにほぼすべての情報がある
direct-sqlite
-
http://hackage.haskell.org/package/direct-sqlite
- Hackage
- API 仕様を調べるのに参照した
- Sqlite のドキュメントに説明を丸投げしてて辛かった
sqlite-simple
-
http://hackage.haskell.org/package/sqlite-simple
- Hackage
- API 仕様を調べるのに参照した
- ここだけで十分理解できる
-
ところでダウンロード数ってなんだろう? ↩