Microsoft Fabric の 2023/10 のアップデート情報を和訳・まとめてみました。
Core
アイテムタイプのアイコン
プラットフォーム全体のアイテムタイプのアイコンの改善をした。
Admin
テナント設定のキーワードベースのフィルタリング
管理者ポータルのテナント設定ページにキーワードベースのフィルタリングを導入した。これにより、必要なテナント設定を迅速かつ簡単に見つけることができる。
テナント設定ページの上部にある検索バーにキーワードを入力するだけで、タイトルまたは説明にキーワードを含む設定のみをフィルタリングして表示する。
Power BI
レポート
Power BI Desktop の OneDrive および SharePoint との統合
5月にプレビューリリースされた機能が改善され、デフォルトでオンとなり、以下のことが可能となった。
- OneDrive と SharePoint に保存されたレポートをファイルメニューから開く。
- OneDrive と SharePoint に直接ファイルを保存する。
- OneDrive や SharePoint に保存されたレポートを Power BI Desktop から直接共有する。
Power BI Service に公開する前に、OneDrive と SharePoint を使用してレポートを共同作成するワークフローを合理化することができる。
また、OneDrive や SharePoint に保存された Power BI レポートをブラウザで直接表示できるようになったため、Power BI ファイルと Power BI Desktop のダウンロードをする必要がなくなった。
Fabric の管理ポータルでオフにすることができる。
オンオブジェクトインタラクションの更新(プレビュー)
データポップアップ上の日付階層
日付階層から生の日付フィールドに切り替える際は、日付フィールドを直接右クリック、もしくはデータポップアップ上でも可能となった。
1.右クリックで切り替える。

2.データフライアウトで切り替える。

直接テキストを編集するためのプレースホルダ
「自動」値を持たないテキスト要素をオンにすると、ユーザがビジュアル上で直接入力できるプレースホルダが表示されるようになった。
誤ってすべての文字を削除してしまっても、テキスト要素がオンのままであればプレースホルダは表示されたままとなる。プレースホルダは編集中にビジュアルが選択されている場合にのみ表示され、ビジュアルの選択を解除すると表示されなくなる。

リボンチャートとファネルチャートがオンオブジェクトフォーマットをサポート


Power BI データセットおよび Analysis Services での複合モデルの重複排除ルール
これまでは、テーブル名やメジャー名が一意でない場合、いずれかがリネームされていた。例えば、2 つのソースから複合モデルを作成し、両方のソースで 'Customers' というテーブルを定義した場合、テーブルの 1 つは 'Customer 2' という名前に変更され、その結果、'Customer 2' のテーブルがどちらのソースから作成されたものであるかがわからなくなる状況に陥ることがあった。
これを改善するために、名前の競合が予想される場合、名前に接頭辞または接尾辞として追加するテキストを設定できるようになった。さらに、重複が発生した場合にのみそのテキストを追加するか、あるいは常に追加するかを選択できる。
これらのオプションは、Power BI データセットまたは Analysis Services への複合モデル接続をセットアップするときに表示されるダイアログの [設定] の下にある。
重複排除ルールを指定しない場合、または指定した重複排除ルールで名前の競合が解決されない場合でも、標準の重複排除アクションが適用される。
モデリング
Power BI Service でのデータモデル編集機能の更新
リレーションシップの管理ダイアログ
データモデルのリレーションシップを簡単に表示・編集できるようになった。

刷新された「リレーションシップの管理」ダイアログでは、すべてのリレーションシップとその主要なプロパティが、1つの場所で表示される。ここから新しいリレーションシップを作成したり、既存のリレーションシップを編集したりすることができる。

さらに、カーディナリティとクロスフィルタの方向に基づいて、特定のリレーションシップをフィルタリングしてフォーカスするオプションもある。

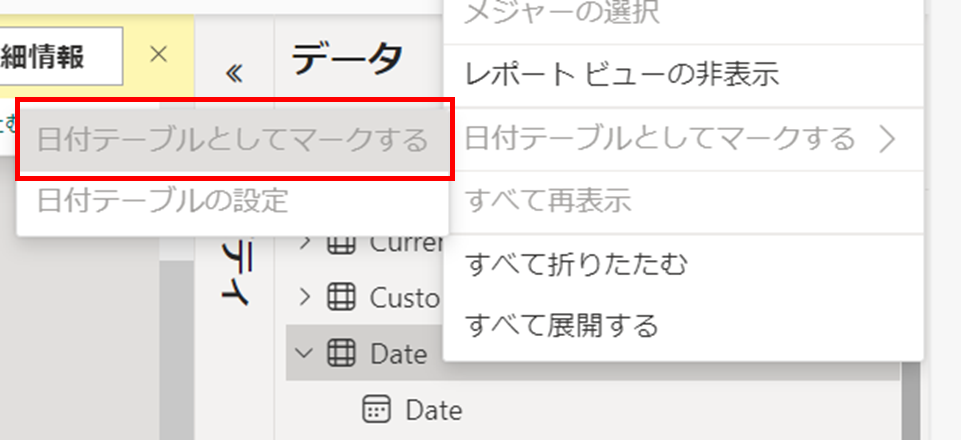
日付テーブルとしてマークする
データモデル内のテーブルを日付テーブルとしてマークできるようになった。モデルに日付テーブルをマークすると、ビジュアル、テーブル、クイックメジャーなど、日付に関連するさまざまな要素にこのテーブルを使用できるようになり、タイムインテリジェンス関数もサポートされる。日付テーブルを設定するには、目的のテーブルを右クリックし、表示されるメニューから "日付テーブルとしてマーク" -> "日付テーブルとしてマーク" を選択する。
計算グループの編集とプロパティペインでのリレーションシップの作成が可能なモデルエクスプローラーがパブリックプレビュー
データセットすべてのセマンティックモデリングオブジェクトを一箇所で見ることができるようになった。
セマンティックモデルに対するプロパティペインも表示されるようになった。

また、新しいアイコンもデータペインに表示されるようになった。

モデルエクスプローラでは、計算グループの作成および編集することもできる。計算グループは、既存のメジャーに動的な計算を適用できる強力な機能で、モデル内の任意のメジャーに、年間累計、四半期累計、月間累計などのタイムインテリジェンス計算を適用する計算グループを作成することができる。これらを作成するには、モデルビューに移動し、データペインのモデルタブをクリック後、3つのオプションがある。(①リボンボタン、②コンテキストメニュー、③プロパティペイン)

"新しい計算グループ" をクリックした後、"暗黙的なメジャー"をオフにする必要があることが告げられる。

モデルエクスプローラからプロパティペインでリレーションシップを作成することもできる。プロパティペインでリレーションシップを編集することで、"変更の適用" をクリックするまで、データのプレビューや検証を行うことなく、テーブルやカラムを変更することができるようになった。

まだ Desktop に表示されていない編集機能として、パースペクティブとカルチャーがある。これらの機能は、XMLA write の外部ツールまたは XMLA を直接使用して編集する必要がある。
これらの機能を使用するには、モデルエクスプローラーのパブリックプレビューをオンにする必要がある。

データ接続
Snowflake(コネクタの更新)
Snowflake コネクタが更新され、"LIMIT 1" クエリの実装が改善され、パフォーマンスが向上した。
Planview OKR(新規コネクタ)
以下は Planview チームからのリリースノート:
Planview の Objectives and Key Results (OKR) は、組織の主要な目標を定義し、達成に向けた進捗状況を追跡するための成果主導型のフレームワークです。OKR を定義することで、組織は "どこに行きたいのか?"(目的)と "そこに到達するための努力をどのように測定するのか?"(主要な成果)という問いに答えられるようになり、組織の明確性が生まれます。OKRは、企業、ポートフォリオ、プログラム、チームなど、組織構造のさまざまなレベルで作成することができ、親子関係を使って結び付けられます。組織とチームの目標を階層的にリンクさせることで、仕事の成果を企業戦略に整合させ、組織が提供する価値を一本線で把握できるようになります。カスタムコネクタ Planview OKR を使用して OKR データに接続します。
BitSight Security Ratings (コネクタの更新)
BitSight Security Ratings コネクタが更新され、マイナーなバグが修正された。
Starburst Enterprise(コネクタの更新)
以下は Starburst チームからのリリースノート:
- 他の ODBC 接続パラメータを使用できるように、詳細セクションにオプションの接続文字列(非クレデンシャルプロパティ)を追加しました。
- データソースの表示を Starburst Enterprise から接続詳細 ({"Host": "sep.example.com", "Port": "443"}) に基づく値に変更し、複数の Starburst Galaxy またはクラスタを別々のデータソースとして接続した場合に区別できるようにしました。
- OAuth 2.0 認証のポート 8443 に関する問題を修正しました。
- タイムスタンプ列でのクエリのフォールディングを修正しました。
Service
OneLake データハブ-データへのクイックアクセス
エクスプローラー ペイン-クイックアクセス
エクスプローラー ペインでは、ワークスペースの階層をナビゲートし、特定のワークスペースのデータ項目をスコープすることができる。新機能として上部にクイックアクセス セクションが追加された。クイックアクセス セクションには、アクティブなワークスペース、ピン留めされたワークスペース、最近使用したワークスペースが表示される。

お気に入りアイテム
以前にお気に入りとしてマークされた項目をフィルタリングして表示できるようになった。お気に入りアイテムは、ホームやなどでも表示されます。

Synapse
Data Warehouse
V-Order 書き込み最適化
V-Order は Parquet ファイルを最適化し、Power BI、SQL、Spark などの Fabric コンピュートエンジンで高速な読み取りを可能する。この最適化により、ウェアハウスのクエリ全般の読み込み時間が短縮され、Parquet ファイルがオープンソースの仕様に100%準拠していることが保証される。今月から、ウェアハウスに取り込まれるすべてのデータで V-Order 最適化が使用される。
バースト可能なコンピューティングのための SKU ガードレール
Fabric の Synapse Data Warehouse は、バースト可能なコンピュートによりピーク時のパフォーマンスを向上させる柔軟性を備えている。SKU ガードレールは、ピーク時のワークロードが短時間ですべてのキャパシティユニットを消費することを防ぎ、キャパシティに対する適切な範囲内で運用されることを保証する。
Data Science
セマンティックリンク(パブリックプレビュー)
セマンティックリンクにより Power BI データセットと Fabric の Synapse Data Science をシームレスに接続することができる。メダリオンアーキテクチャのゴールドレイヤーとして組織内で最も洗練されたデータが含まれているPower BIデータセットに、Fabric のノートブックや Python からアクセスできるようになる。
Real-time Analytics
KQL データベース容量レポート
KQLデータベースは、Microsoft Fabric Capacity Metrics を使用して監視できるオペレーションを介して容量を利用する。
KQL Database Consumption - これはデータベースが使用する仮想コア数に対する KQL データベースがアクティブな秒数を示す。たとえば、データベースが4つの仮想コアを使用して10分間アクティブな場合、Capacity Unit を2,400 秒使用することになる。オートスケールメカニズムは KQL データベースのサイズを決定するために利用される。これにより使用パターンに基づき、コスト最適化されたパフォーマンスが保証される。
KQL データベースのオートスケールアルゴリズムの改良
KQL データベースは自動スケーリングアルゴリズムを内蔵していて、このアルゴリズムは最小限のコストでワークロードをサポートするために最適な数のリソースが割り当てられることを保証する。自動スケーリングアルゴリズムは、以下の次元に基づく:
- ホットキャッシュ-即時応答のためにどれだけのデータをホットキャッシュに保存するか。この指標は、顧客によって定義されたキャッシュ・ポリシーの影響を受ける。
- メモリ-クエリのパフォーマンスを最適化するために、メタデータとデータにどれだけのメモリが必要か。
- CPU使用率-クエリの処理、ポリシーの更新、具体化されたビューなどにどれだけの計算リソースが必要か。
- インジェスト-インジェスト率とロード時間に基づいて、データインジェストにどれだけの計算リソースが必要か。
PowerBIの特別な最適化によるローカル時間でのKustoデータのフィルタリングと可視化
Kusto(Fabric の ADX/KQL データベース)の datetime 値は UTC であると仮定されているが、多くの場合、特定のタイムゾーンで datetime 値を視覚化し、ローカルタイムで表現された値を使用してデータをフィルタリングする。このようなシナリオをより効率的にする最適化を実装した。さらに、KQL データベースで PowerBI を使用して時系列分析を行うユーザは、時間範囲をパラメータとして受け取り、それをUTCにシフトし、テーブルをフィルタリングし、フィルタリングされた行を UTC から同じタイムゾーンにシフトする関数を作成することを推奨する。
イベントプロセッサにおけるイベントストリームの UX 改善
イベントストリームのイベントプロセッサは、コード不要なエディタで、リアルタイムデータストリームを効率的に処理および管理できる。データストリームがレイクハウスまたは Kusto データベースに到達する前に、関数を使用してデータストリームを簡単に集約およびフィルタリングできる。最近の UX の改善により、フルスクリーンモードが導入され、データ処理ワークフローを設計するためのより広いワークスペースが提供される。データストリーム操作の挿入と削除がより直感的になり、データ変換の接続がより簡単になった。
Eventstream Kafka エンドポイントとサンプルコード
ソースと宛先にさまざまな新しいエンドポイントを追加して、カスタム App 機能を拡張した。これにより、EventHub、AMQP、Kafka などのプロトコルを使用して、アプリケーションをイベントストリームにシームレスに接続できるようになった。セットアップを簡素化するために、サンプル Java コードが含まれている。これをアプリケーションに追加するだけで、リアルタイムイベントをイベントストリームにストリーミングする準備が整う。
Data Factory
Dataflow Gen2
データ接続
SAP HANA (コネクタの更新)
SAP Datasphere の追加セキュリティコンセプトを考慮することで、SAP Datasphere にデプロイされた HANA Calculation Views を消費する機能が強化された。これにより、_SYS_BIスキーマに追加の権限を付与することなく、HANA Cloud ビューに接続できるようになる。
Emplifi Metrics(新規コネクタ)
以下、Emplifiチームからのリリースノート:
マーケティングやビジネスインテリジェンスの他のデータと一緒にソーシャルメディアインサイトを統合することで、デジタル戦略全体を一箇所で総合的に理解することができます。Emplifi Power BI コネクタを使用すると、チャートやグラフに Emplifi プラットフォームからのソーシャルメディアデータを含めることができ、所有する他のデータと組み合わせることができます。
Power BI コネクタは、Emplifi Public API と Power BI 間のレイヤーです。Power BI ツールで直接データを扱うことができます。Emplifi Public API で利用可能なほとんどのデータやメトリクスは、コネクタでも利用可能です。
Emplifi Public API の詳細と利用可能なメトリクスのリストについては、公式ドキュメントをご覧ください。
バグ修正と信頼性の向上
Dataflow Gen2 のオーサリングとリフレッシュの全体的なエクスペリエンスが向上した。
パイプライン
アクティビティ
AML アクティビティ
Azure Machine Learning アクティビティがパイプラインで使用できるようになった。Azure Machine Learning アクティビティを使用して、Machine Learning パイプラインに接続したり、バッチ予測シナリオを有効にしたりできる。
アクティビティの非アクティブ化 / 再アクティブ化(プレビュー)
パイプラインから1つまたは複数のアクティビティを非アクティブにできるようになった。これにより、パイプラインの検証中やパイプラインの実行中にアクティビティをスキップできるようになる。無効にしたアクティビティはいつでも再開できる。
生産性
アクティビティカテゴリの再設計
Control flow、Notificationsなどの新しいカテゴリーにより、アクティビティを見つけやすくなった。

コピー実行時のパフォーマンス改善
コピー実行時のパフォーマンスを改善した。テスト結果によると、parquet / csvファイルから Lakehouse テーブルへのコピー時間が 25%~35% 改善された。
変数のデータ型が整数に
新しい変数を作成する際に、変数のデータ型を Integer に設定できるようになり、変数で算術関数を簡単に使用できるようになった。
システム変数でパイプライン名がサポート
パイプラインの式エディタ内でパイプライン名を検査したり渡したりできるように、パイプライン名という新しいシステム変数を追加した。

コピーアクティビティのマッピングでの型編集のサポート
Lakehouse テーブルにデータをランディングする際に、カラムタイプを編集できるようになった。マッピングが表示されていない場合は、マッピングタブに移動してスキーマをインポートし、ドロップダウンリストを使用して変更する。

Data Activator
Data Activator がパブリック・プレビューに
Data Activator を使えば、Fabric データからアラートやアクションを起こすことができる。
イベントストリームのリアルタイム・ストリーミング・データでも動作する。イベントストリームアイテムで Data Activator アラートを作成するには、“reflex” を作成する。