こんにちは。Kaneyasuです。
最近はいろいろな形式のデータに触れさせていただき、毎日てんやわんやしております。
今日は、タイトルの通りJCAMP-DX形式のテキストをPythonでJSON化してJavaScriptで可視化してみようという話をお送りします。
JCAMP-DXとは
JCAMP-DXは、分光データを保存するために作成されたテキストベースのファイル形式です。
分光データとは光の電磁波スペクトルを測定したデータのことです。
詳しい解説は専門の文献を参照してください。
本記事のソースコード
本記事のソースコードはGitHubに一式をアップしています。
ソース全体と使用方法はこちらをご覧ください。
JCAMP-DXとJavaScript
JavaScriptには可視化用のライブラリが揃っています。
そのどれかを使って、JCAMP-DX形式のテキストを可視化することをゴールとします。
JCAMP-DX形式のテキストを直接扱うライブラリは、なくはないようですが、メジャーと言えるものは見当たりませんでした。
従って、JCAMP-DX形式のテキストをそのままJavaScriptで扱うのではなく、JSONに変換して渡してくれるAPIを作り、変換したJSONをもとにJavaScriptで可視化する方向を考えます。
JCAMP-DX形式のテキストをJSONに変換して返すAPI
今回はJCAMP-DX形式のデータをJSONに変換するために、Pythonのjcampを使わせていただきます。
JCAMP-DX形式のテキストはDynamoDBに格納しておくとします。
S3にJCAMP-DX形式のテキストファイルを置いておいてもいいのですが、S3にあるファイルを都度読み込むようなAPIは作らないかなと思い、DynamoDBを活用する方法にしました。
このように格納しておきます。
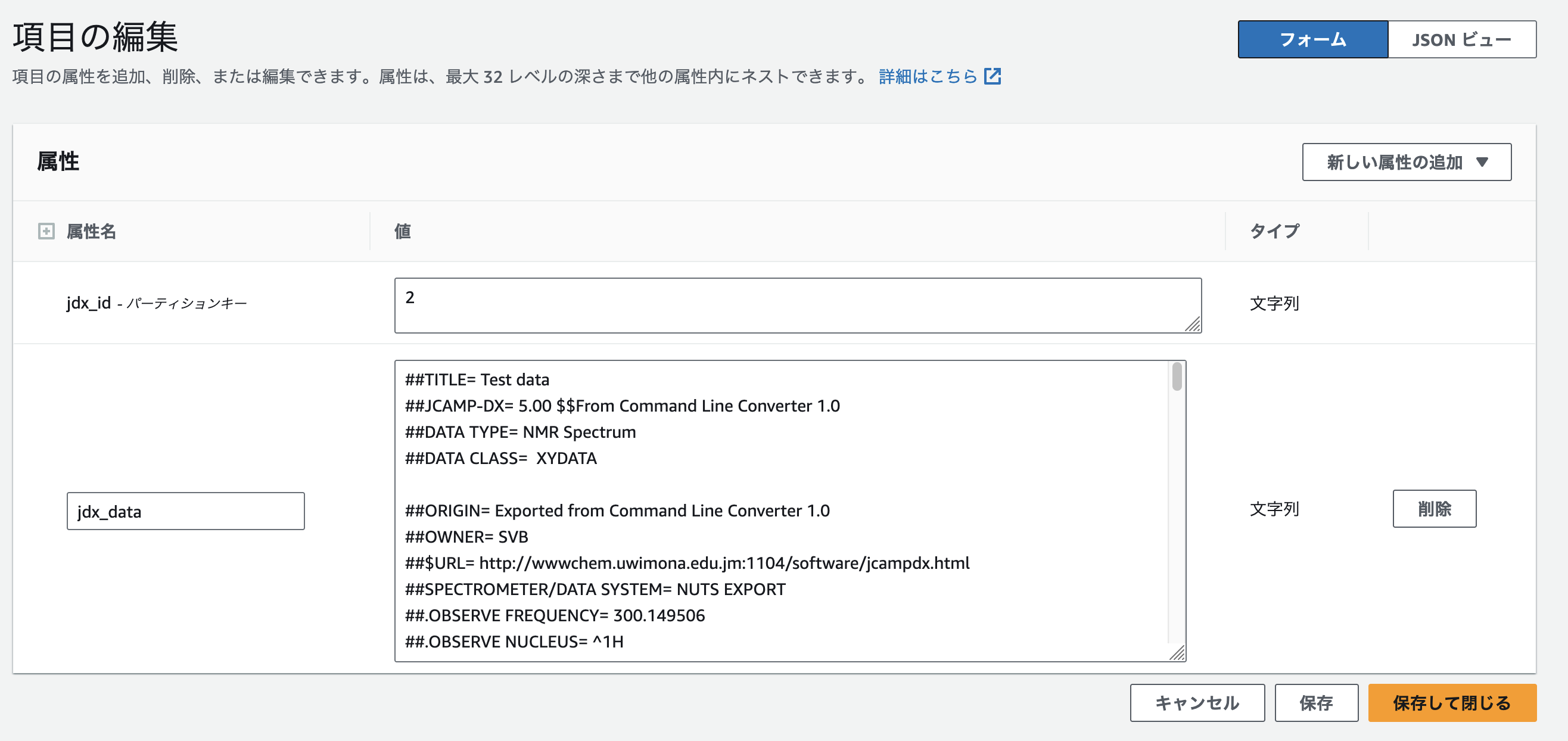
APIの本体のソースはこちらです。
まず、DynamoDBからJCAMP-DX形式のテキストを取得します。
def get_jdx_from_dynamodb(id: str) -> str:
"""
DynamoDBからJDXデータを取得する
Args:
id (str): JDXデータのID
Returns:
str: JDXデータ
"""
dynamodb = boto3.client("dynamodb")
try :
response = dynamodb.get_item(
TableName=os.environ.get("TABLE_NAME"), Key={"jdx_id": {"S": id}}
)
if 'Item' not in response:
raise ValueError(f"No item found with ID: {id}")
jdx_data = response['Item'].get('jdx_data', {}).get('S')
if jdx_data is None:
raise ValueError(f"'jdx_data' is missing for ID: {id}")
return response.get("Item").get("jdx_data").get("S")
except Exception as e:
print(f"Error fetching JDX data from DynamoDB: {str(e)}")
raise e
取得したJCAMP-DX形式のテキストを連想配列に変換します。
def parse_jdx(jdx_data: str) -> dict:
"""
JDXファイルの文字列をデータに変換する
Args:
jdx_data (str): JDXデータ
Returns:
dict: JDXデータを解析したデータ
"""
try:
return jcamp.jcamp_read(jdx_data.splitlines())
except Exception as e:
print(f"Error parsing JDX data: {str(e)}")
raise e
以下の部分は、テキストファイルから読む場合は必要ですが、今回はDynamoDBからJCAMP-DXのテキストをロードしたので、この記述は不要でした。
付いていると逆に動きませんでした。
content = [line.decode("utf-8") for line in content]
変換した連想配列は、中にndarrayというデータが含まれており、そのままではJSONにできません。
json.dumpsにndarrayを変換するコードを渡して対応するようにしました。
jdx_data: str = get_jdx_from_dynamodb(params.get("jcampdx_id", ""))
jdx_parsed: dict = parse_jdx(jdx_data)
jdx_json: str = json.dumps(jdx_parsed, default=serialize_ndarray)
def serialize_ndarray(obj: any) -> list:
"""
ndarrayをシリアライズ可能な形式に変換する
Args:
obj (Any): シリアライズするオブジェクト
Returns:
list: シリアライズ可能なオブジェクト
"""
if isinstance(obj, numpy.ndarray):
return obj.tolist()
raise TypeError(f"{obj.__class__.__name__} is not JSON serializable")
JavaScriptで可視化
JCAMP-DX形式のテキストをJSONで返すAPIができたので、これをJavaScriptで可視化します。
テスト用のHTMLを作って可視化しました。
テスト用のHTMLは、下記部分の{APIのURL}を、API GatewayのURLに置換して使用しました。
const url = "{APIのURL}/jcampdx/";

JavaScriptによる可視化はPlotlyを使用しました。
APIレスポンスから、X軸とY軸の値リストを取得し、これを用いて描画します。
function fetchAndVisualize() {
const jdxId = document.getElementById("jdxIdInput").value;
const url = "{APIのURL}/jcampdx/";
fetch(url + jdxId)
.then((response) => response.json())
.then((data) => {
const xValues = data.x || [];
const yValues = data.y || [];
HTMLを開いて動作させるとこのようなイメージになります。
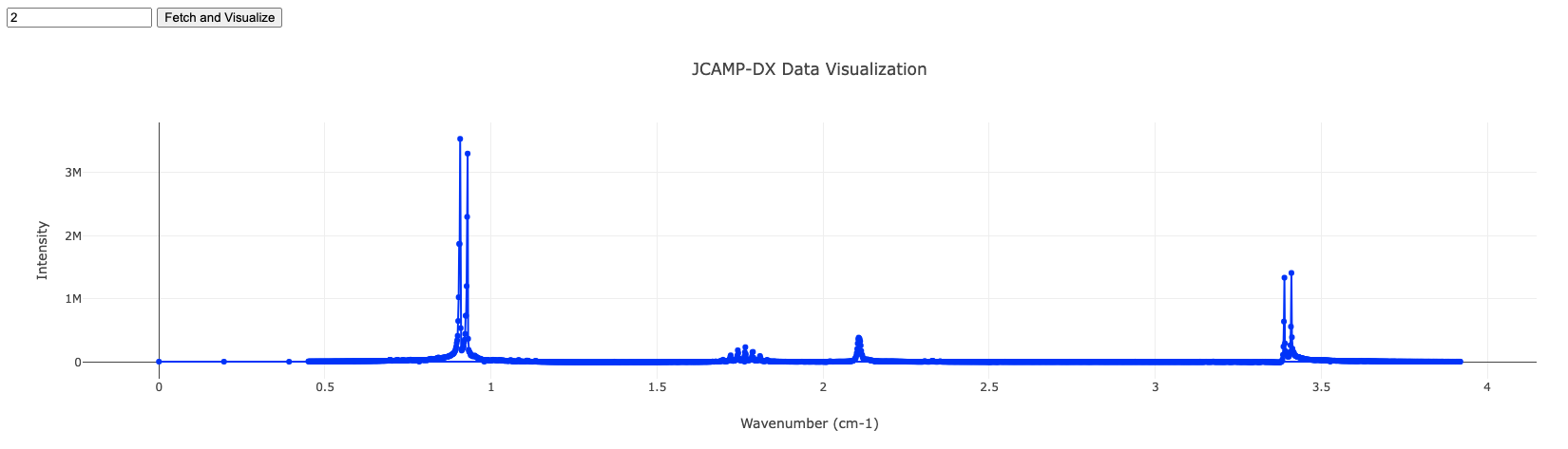
最後に
今回珍しい形式のデータを取り扱う機会があったので、サンプルコードを書いてみた次第です。
データを扱うのはPythonが充実してるので、Pythonで加工してから他の言語で扱うのはアリだなと感じました。
本記事がどなたかの役に立つことを願います。