1.パイプとリダイレクト
パイプ(パイプライン)とは「|」の記号
使い方
ls | wc -l入力→結果:カレントディレクトリ内のファイル、ディレクトリ数が出力される(今回は11)

リダイレクトとは
使い方
ls > redirect.txt入力→結果:viエディタ内にls情報が出力されている

2.ファイル内容を出力(catコマンド)
コマンド cat ファイル名 [オプション]
[オプション一覧]
-n 各行の先頭に行番号をつけて出力する
使い方
cat vitext.txt -n入力→結果:vitext.txt内の情報がコマンド上に表示される

3.行番号をつけてファイルを出力(nlコマンド)
コマンド nl [オプション] [形式] ファイル名
[オプション一覧]
-b 形式 指定した形式で行頭に行番号をつける
[形式一覧]
a 全ての行に表示する
t 空白行以外に表示する
n 行番号を付けるのを中止する
使い方
nl -b a vitext.txt入力→結果:先頭行に行番号がついた状態で、vitext.txtの内容が出力される

4.ファイルを1ページずつ出力する(lessコマンド)
コマンド less ファイル名
[キー操作一覧]
k、矢印上(↑) 上方向に一行スクロール
j、矢印下(↓) 下方向に一行スクロール
f、スペース 下方向に1画面分スクロール
b 上方向に1画面分スクロール
q 終了
/検索文字列 下方向に指定文字列を検索
?検索文字列 上方向に指定文字列を検索
h ヘルプ表示
使い方
less /var/log/boot.log入力→結果:ログ内容が大量に表示されるので上記キー操作で操作する
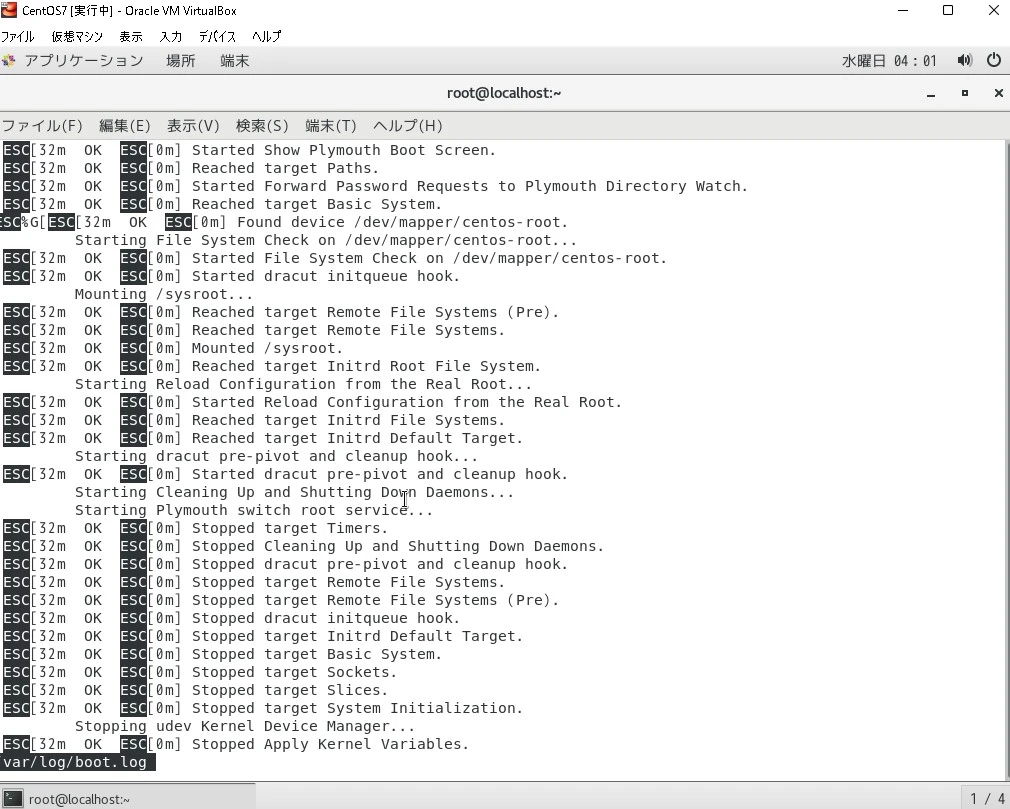
5.ファイルの先頭部分を出力する(headコマンド)
コマンド head [オプション] ファイル名
[オプション一覧]
-n 行数 ファイルの先頭から指定した行数分出力する
-c バイト数 ファイルの先頭から指定したバイト数分出力する
使い方
大量のテキストを記憶したテキストファイルを先頭から指定した分量の出力を行う場合にはheadコマンドを使用する
head -n 15 /var/log/boot.log入力→結果:boot.logの先頭から15行出力される
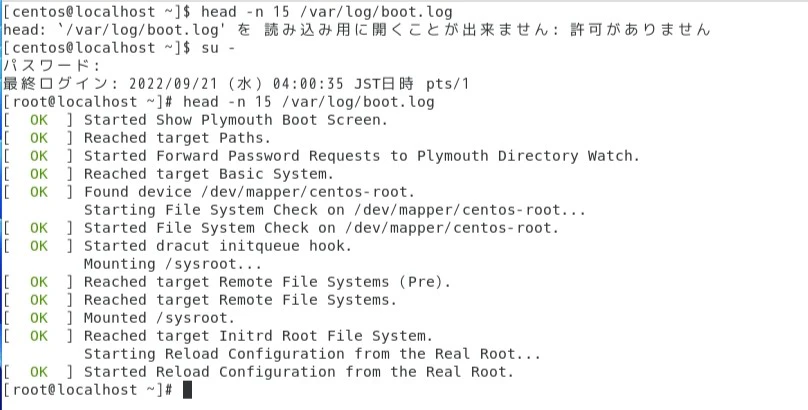
※同様に末尾から指定した分量を出力する場合はtaillコマンドを使用する
6.ファイルの指定箇所を出力する(cutコマンド)
コマンド cut [オプション] ファイル名
[オプション一覧]
-c 文字数 取り出す文字位置を指定する
-d 区切り文字 区切り文字(デリミタ)を指定する(デフォルトはtab)
-f フィールド 取り出すフィールドを指定する
使い方
テキストファイルの指定した箇所の出力を行う場合にはcutコマンドを使用する
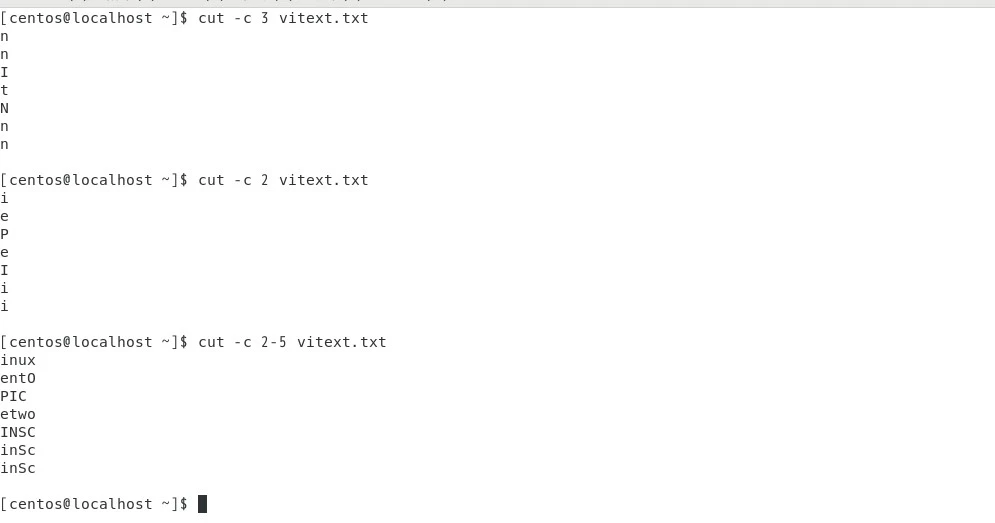
cut -c 3 vitext.txt入力→結果:3文字目だけ出力される
cut -c 2-5 vitext.txt入力→結果:2文字目から5文字目までの範囲出力される
7.二つのファイルを連結する(pasteコマンド)
コマンド paste [オプション] ファイル名1 ファイル名2
[オプション一覧]
-d 区切り文字 連結する際の区切り記号(デリミタ)を指定する(デフォルトはタブ)
使い方
二つのファイルを読み込み、連結を行う場合にはpasteコマンドを使用する
paste -d":" sample1.txt sample2.txt入力→結果:二つのファイル内容が「:」を挟んで連結される
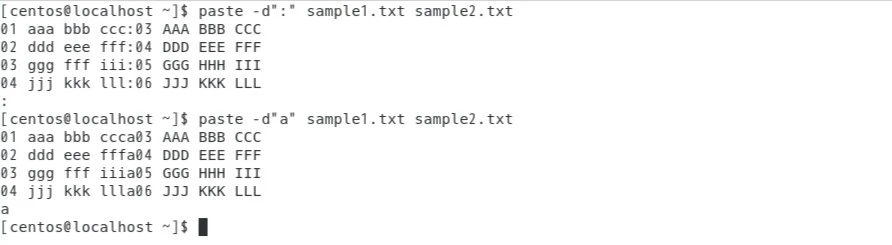
7.指定の文字を変換・削除する(trコマンド)
コマンド tr [オプション] 文字列1 [文字列2]
[オプション一覧]
-d 文字列1でマッチした文字列を削除する
-s 連続するパターン文字列を1文字として処理する
cat vitext.txt | tr 'a-z' 'A-Z'入力→結果:vitext.txt内のアルファベットがすべて大文字に変換された

trコマンドにはクラスがあり、クラスを使うと指定が簡単になる
[クラス一覧]
[:alpha:] アルファベット
[:lower:] アルファベット小文字
[:upper:] アルファベット大文字
[:digit:] 数字
[:alnum:] 英数字
[:space:] スペース
[:digit:]を使用して先ほどのvitext.txtから数字だけ消してみる
tr -d [:digit:] < vitext.txt入力→結果:CENTOS7.7から7だけが削除された

8.ファイル内を並び替える(sortコマンド)
コマンド sort [オプション] [+開始位置 [-終了位置]] ファイル名
[オプション一覧]
-b 先頭の空白は無視する
-f 大文字小文字の区別を無視する
-r 降順に並び替える
-n 数字を文字ではなく数値として判断する
使い方
ファイル内を行単位で並び替えるにはsortコマンドを使用する
sort vitext.txt入力→結果:vitext.txt内の昇順に並び替えられて出力された

9.ファイルを分割して複数のファイルに分ける(splitコマンド)
コマンド split [オプション] 分割元ファイル名 [出力ファイル名]
[オプション一覧]
-b バイト数 指定されたバイト数で分割します。数値の後に「k」をつけるとキロバイト単位、「m」をつけるとメガバイト単位になる
-l(小文字のエル)行数 指定した行数で分割する(lは省略することもできる)
使い方
ファイルを指定した行数やバイト数で分割するにはsplitコマンドを使用するs
split -l 3 vitext.txt vitextsplit入力→結果:vitext.txt内のテキストが3行単位で分割されて出力されている
ここから分割されたファイルを結合してみる
cat vitextsplit* > vitext2.txt入力→結果:分割されたファイルの中身が結合されてvitext2.txtに出力された
(分割されたファイルは残ったまま)

10.並び替え後のファイルから重複する行を削除する(uniqコマンド)
コマンド uniq [オプション] 入力ファイル名 出力ファイル名
[オプション一覧]
-d 重複している行のみ出力する
-u 重複していない行のみ出力する
使い方
sortコマンドを使って並び替えた後に、重複する行があるかどうかを調べて重複する行があればそれを削除するためにはuniqコマンドを使用する
sort uniq.txt | uniq入力→結果:重複のある部分が削除された状態で出力される
11.ファイルの大きさを調べる(wcコマンド)
コマンド wc [オプション] ファイル名
[オプション一覧]
-c 文字数(バイト数)を出力する
-l(小文字のエル) 行数を表示する
-w 単語数を表示する
使い方
ファイルの各種サイズを出力するにはwc(Word Count)コマンドを使用する
wc -c vitext.txt入力→結果:60バイトと表示される
