こんにちは。データアナリストの苅部です。
mediba Adventカレンダーの21日目ということで、私からは Rを用いたスクレイピング、前処理、可視化の内容で書いていきます。
やりたいこと
日常的にauのサービスを利用してPontaポイントを貯めているのですが、毎月貯まってゆくポイントを後から振り返りづらいなと感じています。
ポイントの履歴は存在しますが、トランザクションのレコードを眺めても比較する事ができないので全体は掴みづらいのです。またキャンペーンに参加しても1〜2ヶ月後の後付与なので、あとから集約する必要性もありました。
というわけで「付与ポイント数を時系列で整理・可視化してみたい(ついでにRも使いたい)」というのが今回のモチベーションになります。
利用するパッケージ
以下7つのパッケージをスクレイピング・前処理・可視化の流れで利用します。
library(tidyverse) # Tidyなデータラングリング
library(ggthemes) # ggplotにテーマカラーを設定
library(plotly) # ggplotを対話的に操作する
library(lubridate) # 日付型操作
library(stringi) # 文字列型操作
library(RSelenium) # Seleniumサーバへ接続する
library(rvest) # スクレイピング向けの便利関数群
スクレイピング
ポイントサイトをスクレイピングして必要なデータを抽出します。
DockerでSelenium環境の準備
あらかじめSeleniumイメージを取得して、コンテナを立ち上げておきます。
localhost:ポート番号で接続できればOKです。
$ docker pull selenium/standalone-chrome
$ docker run -d -p 4444:4444 selenium/standalone-chrome
表データの取得
ポイントサイトの複数のページに対して5秒毎にHTTP Requestを投げ、毎月のポイント履歴のHTMLテーブルを取得します。
# Seleniumサーバへの接続
remDr <- remoteDriver(remoteServerAddr = "localhost",
port = 4444,
browserName = "chrome")
# ポイントサイトの履歴ページURL。ログイン後にコールバックで戻ってくる。
history_url <- "https://example.com"
remDr$open()
remDr$navigate(history_url)
# DOMの構築を5秒待つ
Sys.sleep(5)
# IDとパスワードを入力してフォーム送信
remDr$executeScript("document.querySelector('#hogehoge').value = ${mailAddress};")
remDr$executeScript("document.querySelector('#fugafuga').value = ${password};")
remDr$executeScript("document.querySelector('form[name=foo]').submit();")
# 今月(2)〜11ヶ月前(13)までを取得する
start_num <- 2
end_num <- 13
for(i in start_num:end_num){
if (i < 10){
fixed_num <- paste(0, i, sep="")
} else {
fixed_num <- i
}
remDr$navigate(paste(history_url, fixed_num, sep=""))
# DOMの構築を5秒待つ
Sys.sleep(5)
# 当該TableタグのHTML文字列を取得
res <- remDr$executeScript("return document.querySelector('.hoge_table').outerHTML")
# リスト型になっているため文字列へ変換する
res <- as.character(res[1])
# HTMLテーブルのStringをdataFrameに変換する
res <- as.data.frame(read_html(res) %>%
html_table(fill=TRUE))
if (i == start_num){
merged_df <- res
} else {
merged_df <- bind_rows(merged_df, res)
}
}
すでに読み込んでいるrvestパッケージでもスクレイピングは可能ですが、細かな点で操作が困ることもあるので、スクレイピング自体はSeleniumを利用する方が良さそうです。
executeScript()を利用することによりJavaScriptの実行が可能で、returnすれば値も取得できるため、DOM操作に慣れている人にはSeleniumをオススメします。
今回rvestはHTMLテーブル(文字列)をdata.frameに変換(パース)する目的で利用しています。
html_table()は複雑なHTMLテーブルを整理された表に変換できるとても便利な関数です。
なおページ遷移のデバッグが必要な場合には、remDr$screenshot(display = TRUE) を実行することで、ヘッドレスブラウザで表示されているスクリーンをR側で表示させることも可能です。
前処理
スクレイピングの結果得られたdata.frame(トランザクションログ)は以下のような内容で、数百レコードのボリュームになっていました。このレコードを眺めても傾向を掴むのはなかなか難しいです。
| 日付 | 場所 | ご利用内容 | ポイント |
|---|---|---|---|
| 2020年12月7日 | KDDI加盟店 auPAYコード支払 | お買上げ | 3 |
| 2020年12月5日 | KDDI定期付与 auSTAR長期優待 | お買上げ | 150 |
| 2020年12月5日 | KDDI加盟店 auPAYコード支払 | お買上げ | 4 |
| 2020年12月4日 | KDDI加盟店 ポイントアップ店 | お買上げ | 10 |
| 2020年12月4日 | KDDI加盟店 ポイント貯める | お買上げ | 1 |
| 2020年12月3日 | KDDI加盟店 auPAYコード支払 | お買上げ | 2 |
| 2020年12月2日 | ホットペッパービューティー | 利用期限切れによるポイント失効 | -500 ホットペッパービューティー限定ポイント |
| 2020年11月30日 | HOT PEPPER Beauty | 次回のネット予約でご利用いただけるポイントプレゼント★ ※利用期限2020/12/31まで | 500 ホットペッパービューティー限定ポイント |
「場所」でグルーピングしてみます。
count_store <- merged_df %>%
group_by(場所) %>%
summarise(count=n())
count_store
| 場所 | count |
|---|---|
| KDDI加盟店 ポイント貯める | 266 |
| KDDI加盟店 auPAYコード支払 | 80 |
| KDDI加盟店 au PAYカード | 24 |
| KDDI加盟店 auPAYコード支払 増量ポイント | 22 |
| KDDI加盟店 au Webポータル 毎日ポイント | 16 |
| PontaWeb | 14 |
| リクルートカード(JCB) | 11 |
| KDDI加盟店 auPAYポイント運用 | 10 |
| HOT PEPPER Beauty | 7 |
| KDDI加盟店 auでんき ガチャポイント | 7 |
| KDDI加盟店 ニュースパス | 7 |
| KDDI定期付与 トリプルセットポイントで割引 | 7 |
| じゃらんゴルフ | 7 |
| ホットペッパービューティー | 7 |
| ポンパレモール | 7 |
| KDDI加盟店 ポイントアップ店 | 6 |
| KDDI定期付与 auSTAR長期優待 | 6 |
| KDDI定期付与 auでんきポイントで割引 | 6 |
| JAL | 4 |
| ホットペッパーグルメ | 4 |
| KDDI加盟店 auPAYマーケット | 3 |
| じゃらん | 3 |
| ローソン 渋谷ヒカリエ | 3 |
| ローソン 六本木三丁目 | 3 |
| KDDI加盟店 au PAY カードチャージでポイント還元 | 2 |
| KDDI加盟店 au PAY マーケット | 2 |
| KDDI加盟店 au PAY(スーパーマーケットCP) | 2 |
| ローソン 西麻布三丁目 | 2 |
| [Ponta] ロイヤリティ マーケティング | 1 |
| KDDI auID連携 | 1 |
| KDDI加盟店 au PAY(ドラッグストアCP) | 1 |
| KDDI加盟店 au PAY(生活応援キャンペーン8月) | 1 |
| KDDI加盟店 au PAY(生活応援キャンペーン9月) | 1 |
| KDDI加盟店 au PAYアプリ | 1 |
| KDDI加盟店 au PAYカード キャンペーン即時付与 | 1 |
| Ponta PLAY ポンタのゲームボックス2 | 1 |
| ケンタッキーフライドチキン 広尾店 | 1 |
| すき家 目黒駅東口 | 1 |
命名規則がバラバラで、ディメンションもこのままでは無限に増えてしまうため、名寄せをして分類する必要がありそうです。
また「じゃらん」や「ホットペッパー」といったサービスは自動付与され自動消滅する期間限定ポイントのため、除外する必要がありそうです。
他にも処理が必要な項目はいろいろありますが、以下のような流れでデータを整えていきます。
最低限必要なデータの整理
泥臭く前処理を進めてゆきます。
merged_df2 <- merged_df %>%
rename(store = "場所",content = "ご利用内容",point = "ポイント",date = "日付") %>%
# 自動付与、自動消滅系の限定ポイントを除外
filter(str_detect(point,"^(?!.*限定ポイント).*$")) %>%
# ポイント運用はポイント付与ではないので除外
filter(store != "KDDI加盟店 auPAYポイント運用") %>%
# 冗長な文字列なので除去
mutate(store = str_remove(store, pattern="KDDI加盟店 ")) %>%
# storeが空の場合にcontentを代入する
mutate(store = ifelse(str_detect(store,"^$"),content,store)) %>%
# 全角英数を半角英数に変換
mutate_all(~stri_trans_nfkc(.)) %>%
# 数値のカンマ表記を除去
mutate(point = str_remove(point,",")) %>%
mutate(grant_point = ifelse(str_detect(point,"^-"),0,point)) %>%
mutate(grant_point = as.numeric(grant_point)) %>%
mutate(use_point = ifelse(str_detect(point,"^-"),point,0)) %>%
mutate(use_point = str_remove(use_point,"-")) %>%
mutate(use_point = as.numeric(use_point)) %>%
mutate(year = str_extract(date,"([0-9]{4})(?=年)")) %>%
mutate(month = str_extract(date,"([0-9]+)(?=月)")) %>%
mutate(day = str_extract(date,"([0-9]+)(?=日)")) %>%
mutate(date = as.Date(paste(year,month,day),format = "%Y%m%d")) %>%
select(date,store,content,grant_point,use_point)
以下のような形で整理できました。
日本語の日付をdate型に変換し、取得ポイント(grant_point)と消化ポイント(use_point)で列を分けています。
| date | store | content | grant_point | use_point |
|---|---|---|---|---|
| 2020-12-07 | auPAYコード支払 | お買上げ | 3 | 0 |
| 2020-12-06 | ポイント貯める | お買上げ | 1 | 0 |
| 2020-12-06 | ポイント貯める | お買上げ | 1 | 0 |
| 2020-12-05 | auPAYコード支払 | お買上げ | 4 | 0 |
| 2020-12-04 | auPAYコード支払 | お買上げ | 10 | 0 |
名寄せ
今回の分析に適した形に整理します。ここでは名寄せをしてディメンションの数を減らします。
pattern_aupay_code <- "^auPAYコード支払|^auPAY\\(|^ローソン|^ケンタッキー|^すき家|^トモズ|^ゲオグループ|^ポイントアップ店"
pattern_aupay_card <- "^auPAYカード|^auPAY カード"
pattern_kddi <- "^KDDI"
pattern_ponta <- "Ponta+|ポンタ+"
merged_df2 <- merged_df2 %>%
# クレジットカードポイントでの付与ポイントを除外
filter(store != "PontaWeb") %>%
mutate(store = str_replace(store,"au PAY","auPAY")) %>%
mutate(store = str_replace(store,"auPAY マーケット","auPAYマーケット")) %>%
mutate(store = ifelse(str_detect(store,pattern_aupay_code),"auPAYコード支払",store)) %>%
mutate(store = ifelse(str_detect(store,pattern_aupay_card),"auPAYカード",store)) %>%
mutate(store = ifelse(str_detect(store,pattern_kddi),"KDDI定期付与",store)) %>%
mutate(store = ifelse(str_detect(store,pattern_ponta),"PontaWeb",store))
名寄せすることでディメンションを12個に絞ることができました。すっきりしましたね。
count_store <- merged_df2 %>%
group_by(store) %>%
summarise(count=n())
count_store
| store | count |
|---|---|
| au Webポータル 毎日ポイント | 16 |
| auPAYアプリ | 1 |
| auPAYカード | 27 |
| auPAYコード支払 | 129 |
| auPAYマーケット | 5 |
| auでんき ガチャポイント | 7 |
| JAL | 4 |
| KDDI定期付与 | 20 |
| PontaWeb | 3 |
| じゃらん | 1 |
| ニュースパス | 7 |
| ポイント貯める | 266 |
分析用途に応じた整理
今回の可視化では月・サービスカテゴリごとのポイント加算状況を可視化したいので、month,storeごとでグルーピングしてgrant_pointの合計数を抽出します。
merged_df3 <- merged_df2 %>%
filter(grant_point > 0) %>%
mutate(month = as.factor(month(date))) %>%
mutate(store = as.factor(store)) %>%
select(month,store,grant_point) %>%
group_by(month,store) %>%
summarise(grant_point = sum(grant_point))
| month | store | grant_point |
|---|---|---|
| 1 | auPAYコード支払 | 14 |
| 4 | auPAYコード支払 | 34 |
| 4 | じゃらん | 155 |
| 5 | auPAYコード支払 | 3 |
| 5 | KDDI定期付与 | 156 |
| 5 | ポイント貯める | 1 |
可視化
ggplotオブジェクトを作成
必要なデータが抽出できたので、ここからggplotオブジェクトを作成していきます。
plt <- ggplot(merged_df3, aes(x = month, y = grant_point, fill = store, label = grant_point)) +
geom_bar(stat = "identity")+
theme_gray(base_family = "HiraKakuPro-W3")+
ggtitle("Pontaポイント 加算状況")+
labs(title = "Pontaポイント 加算状況", x = "月", y = "ポイント数")+
guides(fill=guide_legend(title="利用サービス"))
プロットしてみる
plotlyを通してggplotオブジェクトを描画します。
ggplotly(plt)

意図していた積み上げ棒グラフにはなりましたが、デフォルトのカラーパレットは彩度・明度が高く見づらい印象です。
テーマを変更する
ggthemesを用いてggplotオブジェクトに対してTableauのカラーパレットでテーマ設定しておきます。
scale_fill_tableau("Tableau 20") +
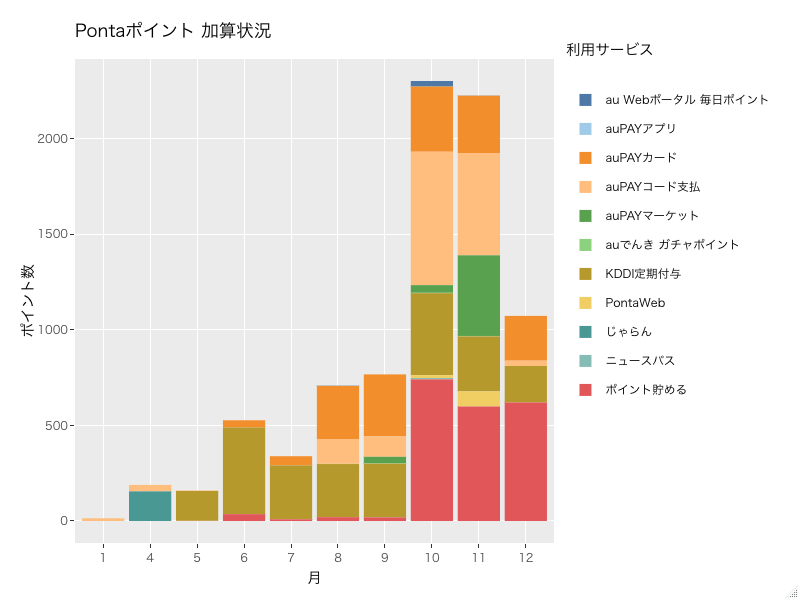
Tableau風の落ち着いた色合いになりました。
今回はplotly通して描画しているため、マウスオーバーで詳細を表示することもできます。
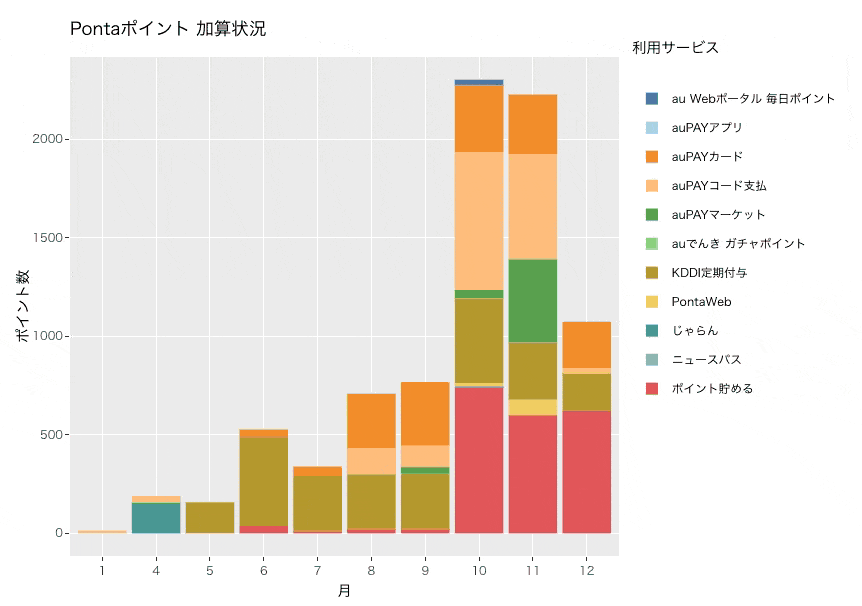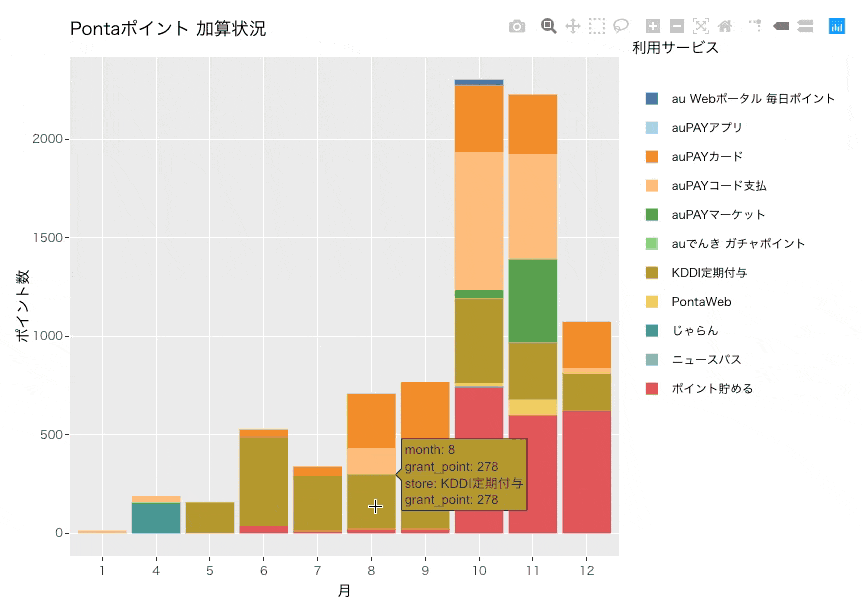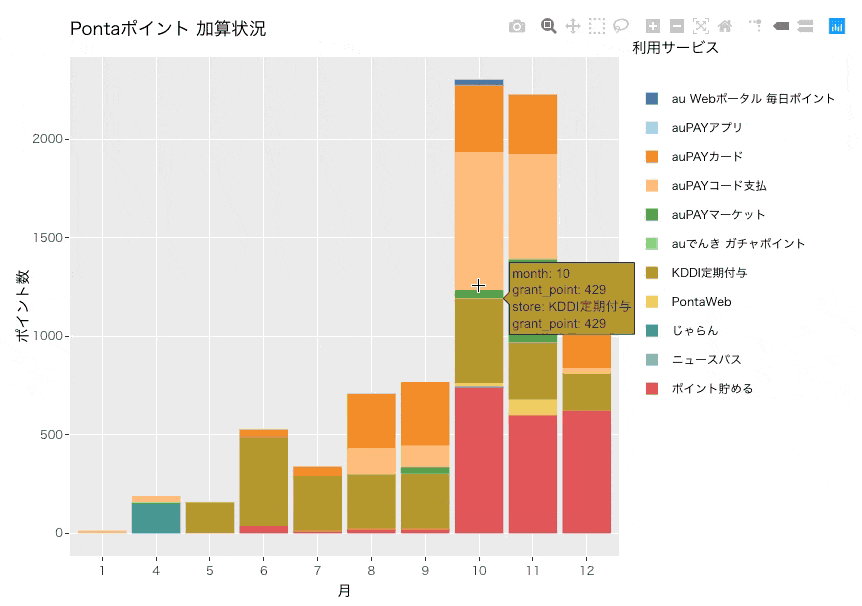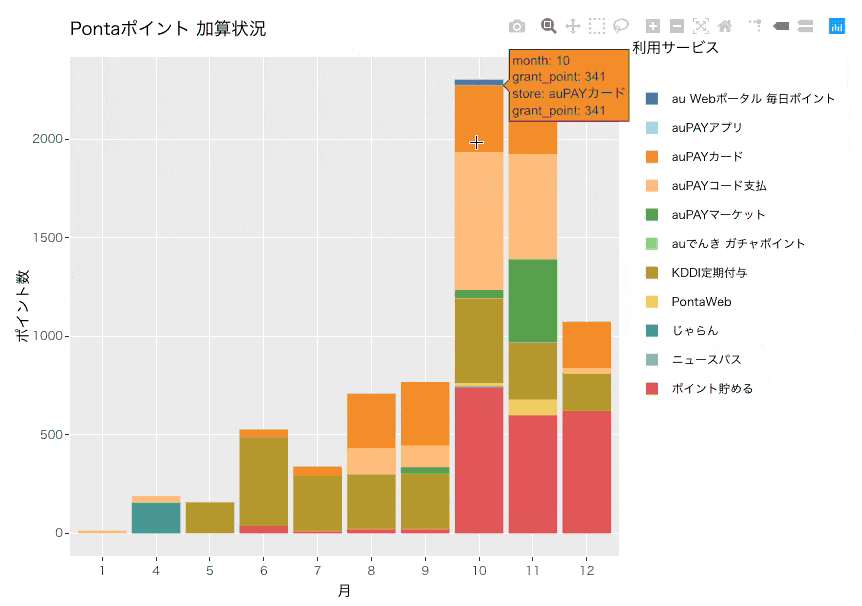
グラフから分かること
10月から付与ポイント数が大幅に増えていて、毎月2,000ポイント以上が付与されていることがわかります。主にauPAYマーケットやauPAYコード支払い、KDDI定期付与、ポイント貯める(enjoy.point.auone.jp)が付与数としては多いようです。
おわりに
もともと数百行あったポイント履歴を前処理を通すことで要約し月毎の比較ができるようになりました。
時系列で整理することで傾向を掴むことができ、付与ポイント数も想定よりも多いことが分かりました。シンプルな棒グラフの可視化だけでも付与傾向がちゃんと掴める印象です。
今回の内容はSpreadsheetとTableauPrep/Tableauでも実現できそうですが、前処理や分析の再現性を保つためにもRとしてコードでバージョン管理できると便利かと思います。