概要
GA4の普及によって、アクセス解析に携わる多くの方がBigQueryを利用する機会が増えていますが、SQLの品質管理まで気が回らないかもしれません。
作業速度が優先され、コストパフォーマンスが考慮されていないクエリが作成されることも少なくありません。その結果、後になって費用の問題が顕在化することになります。
しかし、増え続けるクエリをすべてチェックするのは現実的ではありません。そこで、複数の生成AIを比較して、クエリのレビュー自動化の可能性を考えてみます。
今回のプロンプト
生成AIに指摘してもらうため、改善余地のあるクエリを用意しました。
以下のような簡単なプロンプトで投げてみます。
- 以下のクエリをリファクタリングしてください。
- リファクタリング後にも何か注意点があれば教えてください。
-------
WITH
data1 AS (
SELECT
event_date,
event_name,
COUNT(DISTINCT user_pseudo_id) AS uu
FROM
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_*`
WHERE
event_name = "page_view"
GROUP BY
1,
2 ),
data2 AS (
SELECT
event_date,
COUNT(user_pseudo_id) AS pv
FROM
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_*`
WHERE
event_name = "page_view"
GROUP BY
1)
SELECT
event_date,
pv,
uu,
pv / uu rate
FROM
data1
JOIN
data2
USING
(event_date)
このクエリで指摘できそうなポイント
- 同一のGA4テーブルから複数回読み込んでいる
- _table_suffixでの期間指定がなくフルスキャンしている
- group byでのカラム名ではなくカラム番号が指定されている
- 不要なselectがある(event_name)
- CTEの名前が直感的に分かりづらい(data1、data2)
- CTEの利用自体が冗長かも
- 明示的にASが記述されていない(pv / uu rate)
現場でも見かけるような記述を散りばめてみました。生成AIはどこまで細かく指摘してくれるのでしょうか。
※生成AIの結果は再現性がないため(同じ質問でも毎回結果が異なるため)、今回の比較を一般化することは難しいと思います。あくまでざっくりとした参考程度にしてください。
Gemini 1.5 Flash
まずは無償でも利用できるGoogleのGemini 1.5 Flashから試してみましょう。
返却結果
WITH data AS (
SELECT
event_date,
COUNT(DISTINCT user_pseudo_id) AS uu,
COUNT(user_pseudo_id) AS pv
FROM
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_*`
WHERE event_name = 'page_view'
GROUP BY 1
)
SELECT
event_date,
pv,
uu,
SAFE_DIVIDE(pv, uu) AS rate
FROM data;
リファクタリング内容
- CTEの統合: data1とdata2の2つのCTEを1つのCTE dataに統合しました。これは、両方のCTEが同じテーブルから同じイベント名でデータを取得し、1つのクエリで必要な情報を取得できるためです。
- 集計関数の最適化: data CTEでは、 COUNT(DISTINCT user_pseudo_id) を uu と > COUNT(user_pseudo_id) を pv の2つの別々の集計関数で計算しました。これにより、両方の集計関数を1つの COUNT で取得できます。
- JOINの削除: 元のクエリでは、 data1 と data2 を event_date で結合していましたが、CTEを統合したため、JOINは不要になりました。
- SAFE_DIVIDEの使用: ゼロ除算を避けるために、 SAFE_DIVIDE 関数を使用しました。
注意点
- パフォーマンス: このリファクタリングにより、クエリの実行速度が向上する可能性があります。これは、クエリの複雑さが軽減され、データのスキャン量が削減されたためです。
- 正確性: リファクタリングされたクエリは元のクエリと同じ結果を生成します。ただし、集計関数を使用しているため、データの量によってはパフォーマンスに影響を与える可能性があります。
- データ型: SAFE_DIVIDE 関数は、ゼロ除算を避けるために使用されます。除算の結果がゼロになる場合、結果は NULL になります。必要に応じて、 NULL を別の値に置き換えることができます。
印象
CTEを1つにまとめてくれたようですが、ここまでくるとCTE自体が不要に思えます。解説も多少冗長です。生成AIらしい、内容は多いけど何が言いたいかよくわからない文章になっているようにも思えます。
Gemini 1.5 Pro
次にGoogleの Gemini 1.5 Proを試します。
このモデルは24年8月時点では有償利用に限定されています。
返却結果
リファクタリング後のクエリは以下のとおりです。
SELECT
event_date,
COUNT(DISTINCT user_pseudo_id) AS uu,
COUNT(user_pseudo_id) AS pv,
COUNT(user_pseudo_id) / COUNT(DISTINCT user_pseudo_id) AS rate
FROM
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_*`
WHERE event_name = "page_view"
GROUP BY 1
変更点
- data1 と data2 のCTEを削除し、1つのSELECT文に統合しました。
- COUNT(DISTINCT user_pseudo_id) と COUNT(user_pseudo_id) を1つのSELECT句で計算するようにしました。
- rate を計算するための除算をSELECT句内で行っています。
- JOIN を削除し、1つのテーブルから全てのデータを取得するようにしました。
注意点
- リファクタリング後のクエリは、元のクエリと全く同じ結果を返します。
- リファクタリング後のクエリは、元のクエリよりもシンプルで効率的です。
その他
- このクエリは、特定の日付におけるページビュー数とユニークユーザー数を計算し、それらの比率を算出します。
- このような指標は、ウェブサイトのトラフィックを分析する際に役立ちます。
印象
CTEが無くなりなりシンプルなSQLとなりました。解説も最低限の内容になっています。悪くないですね。
Gemini Pro Experimental
次に試験運用版モデルのGemini Pro Experimentalを試してみます。
返却結果
リファクタリング後のクエリ
SELECT
event_date,
COUNT(user_pseudo_id) AS pv,
COUNT(DISTINCT user_pseudo_id) AS uu,
COUNT(user_pseudo_id) / COUNT(DISTINCT user_pseudo_id) AS rate
FROM
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_*`
WHERE event_name = "page_view"
GROUP BY 1
リファクタリング後の注意点
- 元のクエリでは、page_view イベントのユニークユーザー数 (UU) とページビュー数 (PV) を別々に計算し、結合していました。リファクタリング後のクエリでは、1つの SELECT 句で両方を計算することで、クエリを簡略化しています。
- rate の計算は、pv / uu から COUNT(user_pseudo_id) / COUNT(DISTINCT user_pseudo_id) に変更されました。これは、結合後のカラム名ではなく、集計関数を使用することで、クエリがより明確になるためです。
その他
- リファクタリング後のクエリは、元のクエリと全く同じ結果を返します。
- パフォーマンスは、BigQuery のクエリプランナーによって最適化されるため、どちらのクエリでも大きな差はない可能性があります。しかし、一般的に、結合を減らすことでクエリのパフォーマンスが向上する可能性があります。
ご不明な点等ございましたら、お気軽にご質問ください。
印象
クエリ自体も悪くなく、解説もスッキリまとまり文章が理解し易くなっています。
Claude 3.5 Sonnet
無償版で利用できるClaudeでも試してみます。
返却結果
リファクタリングしたクエリは以下の通りです:
SELECT
event_date,
COUNT(user_pseudo_id) AS pv,
COUNT(DISTINCT user_pseudo_id) AS uu,
COUNT(user_pseudo_id) / COUNT(DISTINCT user_pseudo_id) AS rate
FROM
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_*`
WHERE
event_name = "page_view"
GROUP BY
event_date
このリファクタリングでは、以下の改善を行いました:
2つのCTE(Common Table Expression)を1つのクエリにまとめました。これにより、コードの重複を削減し、読みやすさが向上しました。
JOINを削除し、1回のテーブルスキャンで全ての計算を行うようにしました。これにより、クエリのパフォーマンスが向上する可能性があります。
event_nameの条件を1か所にまとめ、重複を避けました。
グループ化と集計を1つのSELECT文で行い、コードをよりシンプルにしました。
注意点:
パフォーマンス:このクエリは単一のテーブルスキャンで済むため、多くの場合元のクエリより効率的です。ただし、データ量が非常に多い場合は、元のクエリのようにデータを分割して処理する方が効率的な場合もあります。
rateの計算:0除算を避けるため、uuが0の場合の処理を追加することを検討してください。例えば:
SAFE_DIVIDE(COUNT(user_pseudo_id), COUNT(DISTINCT user_pseudo_id)) AS rate
日付範囲:元のクエリでは日付範囲が指定されていませんでした。必要に応じてWHERE句に日付条件を追加することを検討してください。
インデックス:event_nameとevent_dateにインデックスがあることを確認し、クエリのパフォーマンスを最適化してください。
このリファクタリングにより、コードの可読性と保守性が向上し、多くの場合パフォーマンスも改善されると考えられます。
印象
Claudeはレスポンスの速さ、そして日本語の文章の読みやすさが特徴だと感じました。
そしてWHERE句での日付指定や検索インデックスなどコストパフォーマンスの提案も含まれており、筋が良さそうな回答結果となりました。
ChatGPT 4o mini
続いては、ChatGPT 4よりもコストパフォーマンスに優れると言われている、ChatGPT 4o miniを試してみます。
返却結果
以下にリファクタリングしたクエリを示します。主な変更点は、サブクエリを共通テーブル式(CTE)に統合し、計算をシンプルにすることです。これにより、クエリの可読性が向上し、パフォーマンスも改善される可能性があります。
WITH
aggregated_data AS (
SELECT
event_date,
COUNT(DISTINCT CASE WHEN event_name = "page_view" THEN user_pseudo_id END) AS uu,
COUNT(CASE WHEN event_name = "page_view" THEN user_pseudo_id END) AS pv
FROM
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_*`
GROUP BY
event_date
)
SELECT
event_date,
pv,
uu,
SAFE_DIVIDE(pv, uu) AS rate
FROM
aggregated_data
注意点
SAFE_DIVIDE関数の使用:
- pv / uu の計算に SAFE_DIVIDE 関数を使用しています。これにより、uu がゼロの場合にエラーを回避できます。SAFE_DIVIDE 関数は、ゼロ除算を防ぐために使用される関数です。
COUNT と DISTINCT の組み合わせ:
- COUNT(DISTINCT CASE WHEN ...) と COUNT(CASE WHEN ...) を使用することで、各イベントのカウントを一つのクエリで計算しています。これにより、複数回のスキャンを避けることができます。
データ量とパフォーマンス:
- クエリのパフォーマンスは、データ量やクエリ実行環境に依存します。大規模なデータセットの場合、適切なインデックスやパーティション分けも考慮する必要があります。
クエリの目的確認:
- 目的が「ページビューのユーザー数」と「ページビューの総数」の比率を求めることである場合、リファクタリングしたクエリで問題ないか確認してください。意図と結果が一致するかを確認することが重要です。
印象
共通テーブル名が「aggregated_data」となっており、名前に意味を持たせてくれたようです。
COUNTの中でのCASE文利用は新しい発見でしたが、冗長な気もします。
ChatGPT 4o
次に24年8月時点でOpenAIの最新のモデルである ChatGPT 4oを試してみます。
返却結果
以下はクエリのリファクタリング後のバージョンです。構造を簡潔にし、パフォーマンスの観点からも最適化されています。特に、COUNT(DISTINCT user_pseudo_id)の計算を統合し、必要な集計を一度に行うようにしています。
リファクタリング後のクエリ:
WITH aggregated_data AS (
SELECT
event_date,
COUNT(user_pseudo_id) AS pv,
COUNT(DISTINCT user_pseudo_id) AS uu
FROM
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_*`
WHERE
event_name = "page_view"
GROUP BY
event_date
)
SELECT
event_date,
pv,
uu,
SAFE_DIVIDE(pv, uu) AS rate
FROM
aggregated_data
変更点と理由:
集計処理の統合:
- data1とdata2のサブクエリを統合して、1つのクエリでpv(ページビュー)とuu(ユニークユーザー)を同時に集計するようにしました。これにより、冗長なJOIN操作を避け、クエリの効率を高めました。
SAFE_DIVIDEの使用:
- pv / uuの計算において、SAFE_DIVIDE(pv, uu)を使用しました。これにより、uuがゼロの時に除算エラーを防ぎ、安全に計算を行うことができます。
注意点:
データのスキャン量:サブクエリを1つにまとめたことでクエリが効率的になりましたが、大量のデータに対して実行する場合、BigQueryのコストやパフォーマンスに影響が出ることがあります。データのフィルタリングや範囲指定が必要であれば、それを最初に適用することをお勧めします。
時間の範囲:このクエリはすべてのpage_viewイベントに対して集計を行うため、必要に応じてevent_dateや他の条件で期間を絞ると良いでしょう。
印象
ChatGPT 4o miniと近しいクエリが出力されました。簡単なタスクにおいては4oと4o miniでは大きな性能差がないのかもしれません。
ChatGPT4(カスタムGPTs)
生成AIの結果は再現性がない上に、そもそも期待しているフォーマットがあるのであればそれを細かく指示した方が返却結果が安定するかもしれません。
というわけでカスタムGPTsを試してみます。
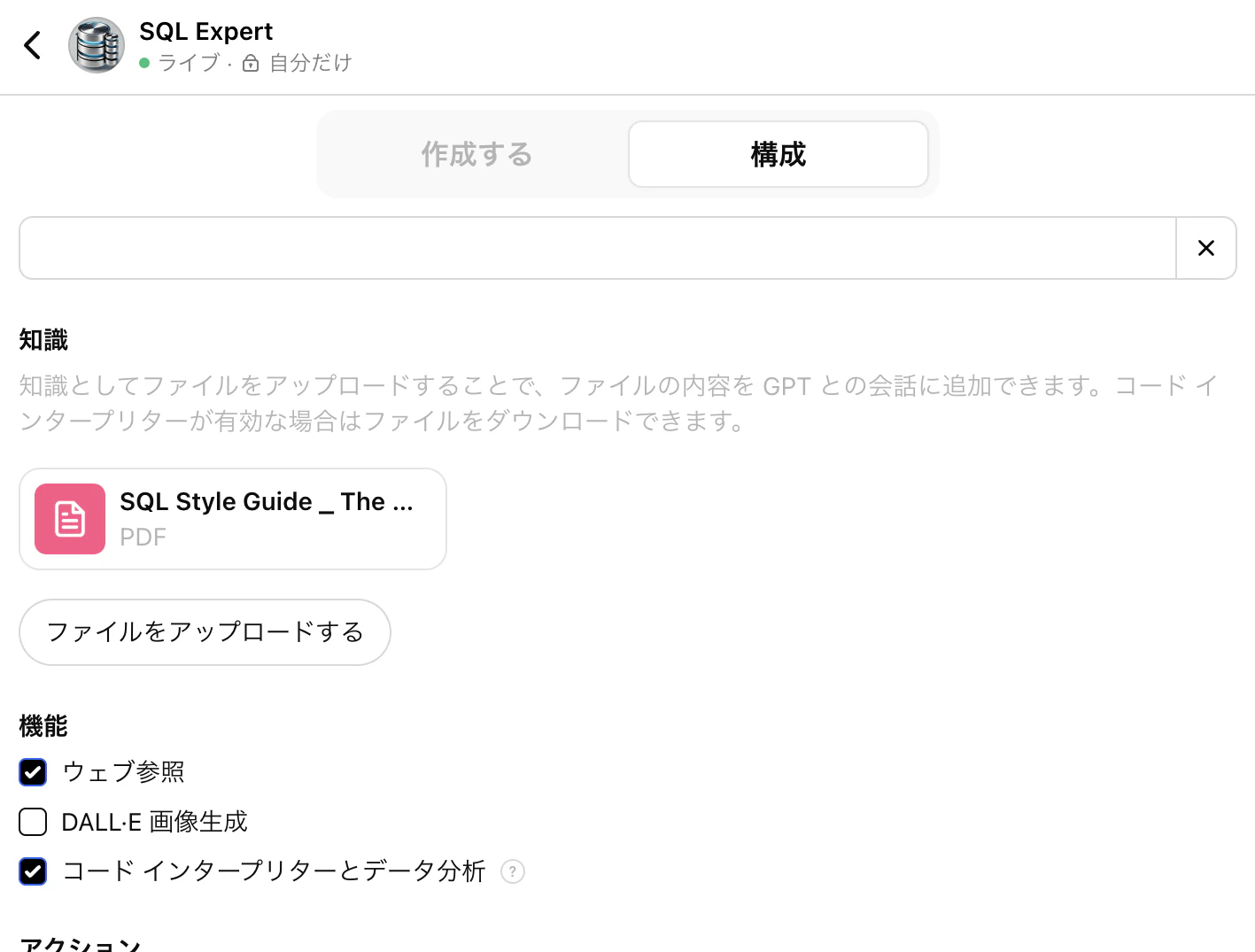
GitLabがSQL Style GuideをCC BY-SA 4.0として公開しているので、このページをPDF出力してカスタムGPTsの学習素材に利用します。
設定内容
SQL Style GuideのWebページををPDFファイルとして保存してカスタムGPTsの知識として与えます。サムネイル画像はDALL-Eが自動生成してくれました。
返却結果
このSQLクエリはBigQueryに対するクエリで、ページビューに関する集計を行っていますが、いくつかのリファクタリングおよび改善の余地があります。GitLabのSQL Style Guideに基づいて、以下のように改善できます。
改善点
- Casing(大文字・小文字の統一): SQLキーワードはすべて大文字に統一するのが一般的です。列名やテーブル名は小文字に保つことで、可読性を向上させます。
- Alias(別名の明示): テーブルの別名をつける際、 data1 や data2 のような一般的な名前は避け、より意味のある名前を使用します。例: page_views_uu, page_views_total など。
- JOINの方法明示: 明示的に INNER JOIN を使用することで、意図を明確にします。
- 数式にエイリアスを付ける: pv / uu に rate というエイリアスを明示的に付けることで、結果の列名がわかりやすくなります。
リファクタリング後のSQL
WITH
page_views_uu AS (
SELECT
event_date,
event_name,
COUNT(DISTINCT user_pseudo_id) AS uu
FROM
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_*`
WHERE
event_name = "page_view"
GROUP BY
event_date,
event_name
),
page_views_total AS (
SELECT
event_date,
COUNT(user_pseudo_id) AS pv
FROM
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_*`
WHERE
event_name = "page_view"
GROUP BY
event_date
)
SELECT
pvt.event_date,
pvt.pv,
pvu.uu,
pvt.pv / pvu.uu AS rate
FROM
page_views_total pvt
INNER JOIN
page_views_uu pvu
USING
(event_date);
注意点
- event_name のGROUP BYの必要性: page_views_uu のCTEでは、 event_name をGROUP BYしていますが、実際には event_name = "page_view" に固定しているため、不要かもしれません。これを削除することでクエリがシンプルになります。
- rate 計算の検証: pv / uu がゼロ除算を引き起こさないことを確認するために、NULLチェックやフィルタリングが必要な場合があります。
これでコードがより読みやすく、メンテナンスしやすくなり、GitLabのSQL Style Guideに沿ったものになります。
印象
SQL Style Guideに沿った形での回答となりました。
ただ、共通テーブルを省略できるシンプルなクエリでしたが元の形を保っているようです。
これはSQLスタイルガイドに引っ張られてしまい、リファクタリングではなく「フォーマット」することを意識してしまったのかもしれません。
単純に学習素材を増やせばいいだけではないようです。難しいですね。
プロンプトをわずかに変えただけでも返却内容が変化してしまうため、期待した結果になるよう、細かいプロンプトの調整が必要になりそうです。
まとめ
最近の生成AIモデルは賢く、簡単なプロンプトでもSQLクエリを効果的にリファクタリングしてくれました。ただし、モデルによって特徴があり、Geminiは回答がやや冗長になる傾向が見られました。一方、Claudeは文章が読みやすくレスポンスも速く、カスタムGPTsは詳細な設定が必要で少し手間がかかる印象です。
リファクタリングされたクエリを得るだけでなく、その過程で生成AIの意見を聞くことで、新たな視点や発見が得られそうです。
生成AIによるクエリチェックは有用であり、本番環境に投入する前に活用することで、コードの品質向上だけでなく、自身のスキルアップにもつながると思いました。