概要
NPS計測用のアンケートを作成し、NPSのスコアと自由回答を集計・分析します。
今回は以下の手順で進めていきます。サイト側の修正作業なしにGTM/Optimizeを利用してアンケートへの導線が設置できることがポイントです。
- Googleフォームでアンケートを作成
- GTMから非同期でOptimizeを配信
- Optimizeでカスタマイズを作成・実行
- Rで集計・可視化
NPSとは
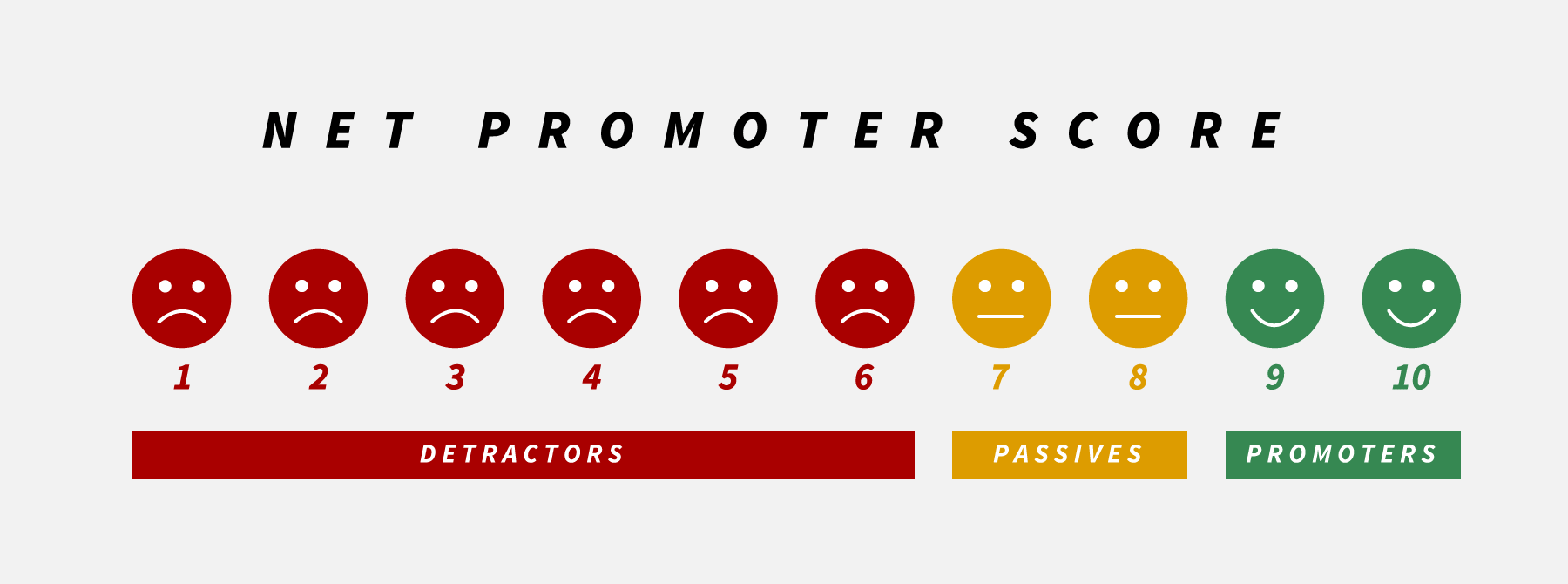
NPSとは顧客ロイヤルティを測るための指標で「あなたはこの商品・サービスをどの程度、友人や同僚に勧めますか?」といった質問に0~10の11段階で回答してもらった結果を数値化したものです。
ここでは細かい説明を省きますが、NPSについて詳しく知りたい方にはネットプロモーター経営をおすすめします。
1) Googleフォームでアンケートを作成
まずGoogleフォームにてNPSを集計するためのアンケートを作成します。
ネット・プロモーター経営に書かれているように質問数に応じて回答率が下がってしまうため、回答バイアスを減らすためにも少ない質問数で設計したほうが良さそうです。
究極の質問を尋ね、それ以外の質問は極力減らす
注意してほしいのは、質問の数はあくまでも少なく抑えることである。ありきたりな原因追求のための追加質問は、たいてい逆効果となる。そうした質問から改善策につながる洞察が得られることはほとんどなく、いたずらに顧客の時間を浪費し、回答率を押し下げてしまう。
ベインの顧客は一般的には大規模な多国籍企業の経営層だが、そうした顧客に対してもネットプロモーターの調査を行なっている。そこで明らかになったのが、調査票からわずか二つ、三つ質問を減らすだけで、回答率は2倍になり、60%を超えるということだった。
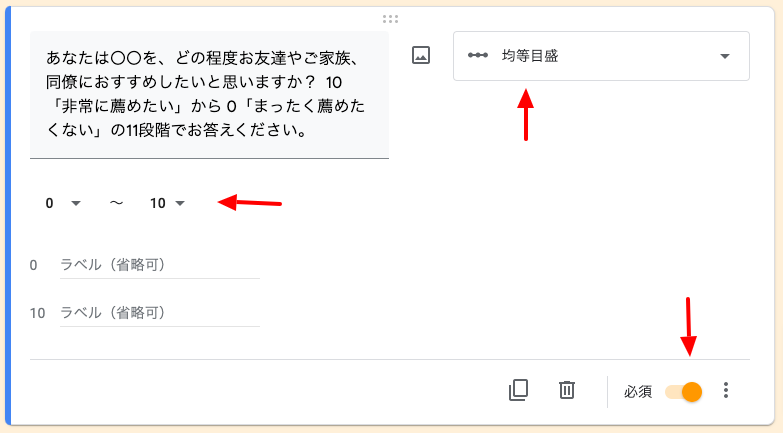
スコアを均等目盛で設定
点数の項目は「均等目盛」にて0〜10と設定すると横並びのラジオボタンが作成できます。
NPSスコアは必ず取得しておきたいので、この項目は必須として設定しておきます。
自由回答を段落で設定
NPSのスコアに対する理由の回答は 自由項目として「段落」で設定します。

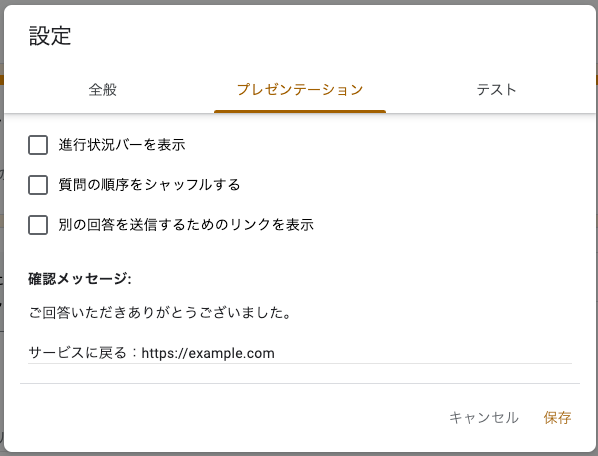
回答後画面の設定
「設定」の「プレゼンテーション」の項目で回答後画面も設定できます。
デフォルトではもう一度回答するためのリンクが掲出されてしまうので「別の回答を送信するためのリンクを表示」をオフにしておきます。
また回答後のメッセージも「回答を記録しました。」と若干無機質な文言になっているので適宜変更し、サービスに戻すURLも添えておきます。
アンケートの完成
以下のようなNPSアンケートが作成できました。

回答の集計
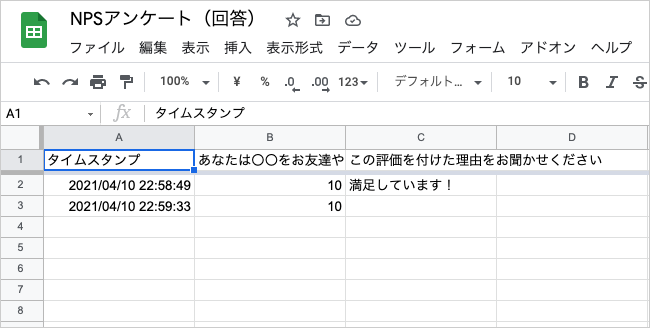
アンケートの集計結果は回答タブでリアルタイムに集計結果が確認できます。

Googleスプレッドシートと連携することもできますので、データポータルやBIツール、分析ツール(R/Python)などから集計結果を呼び出すこともできます。
2) GTMから非同期でOptimizeを配信
サイト側にGoogleフォームへのリンクを設置するためGTM経由でOptimizeのタグを配信します。トリガーはGoogleフォームの導線を設置するURL限定で着火させる形にします。

一般的にタグマネージャー経由したA/Bテストツールの配信はレイテンシの問題で推奨されません。今回の事例ではOptimizeタグの設置が困難だったのでGTMを経由していますが、サイト側に直接Optimizeタグを設置することが容易であれば、この限りではありません。
今回のような導線設置に限定して言えば、必要に応じてA/Bテストタグを遠隔で除去できるのでGTMを使うことのメリットもあります。
3) Optimizeでカスタマイズを作成・実行
Optimizeの管理画面を操作してNPSアンケートへの導線を設置します。
カスタマイズの作成
何かを実験するA/Bテストではないため、カスタマイズを選択します。
ビジュアルエディタでHTMLの編集
アンケート導線の設置をするためにOptimizeのエディタでコードを編集します。
エディタでの作業の難易度は高くはありませんが既存のコードを書き換えるリスクはありますので、この作業はフロントエンド・バックエンドの理解があるエンジニアに依頼した方がよいでしょう。
参考:Google Optimize導入とA/Bテスト実施のポイント | mediba Creator × Engineer Blog
今回の場合以下のようなHTMLを任意の箇所に追加して導線を設置しました。
<p>
<a onclick="$.cookie('nps_click', 'YYYYMMDD', {expires: 7});gtag('event', 'クリック', {'event_category': 'NPS導線','transport_type': 'beacon'});" href="${GoogleFormsのURL}">アンケート:満足度について</a>
</p>
この導線は1度クリックされたら次回以降表示させたくないので、任意のCookieをセットする形にしています。そして、ここで生成したCookieはこの後のターゲティング条件で利用します。さらにアンケートの回答率を把握するためGAのクリックイベントも設定しておきます。(beaconAPIを利用して送信することをお勧めします)
ターゲティングの設定
アンケート導線を1度でもクリックした人はターゲティング対象外とするため「任意のCookieが存在しないこと」をターゲティング条件として設定します。

スケジュール設定
iOSではITPの影響でJSで生成したCookieの有効期限が7日間となるため、テスト開始から7日以内に終了させるようスケジュール設定しておきます。
4) Rで集計・可視化
Googleスプレッドシートから集計データを読み込みdplyrでデータ整形、RMeCabで形態素解析、ggplot等のライブラリで可視化します。
自由回答とNPSスコアはセットになっているので、批判者・中立者・批判者で分けて分析することが可能です。
コードは省略しますが以下のライブラリを利用しました。
library(googlesheets4)
library(tidyverse)
library(RMeCab)
library(wordcloud)
googlesheets4を利用すると スプレッドシートの表から簡単にデータフレームを作成することができます。便利ですね。
### SpreadSheetの認証 (ブラウザが立ち上がる)
gs4_auth()
## SpreadSheetからデータを取得。rangeでシートの範囲を指定
df_raw <- read_sheet(
ss = "${SheetId}",
range = "${SheetName}!A1:C"
)
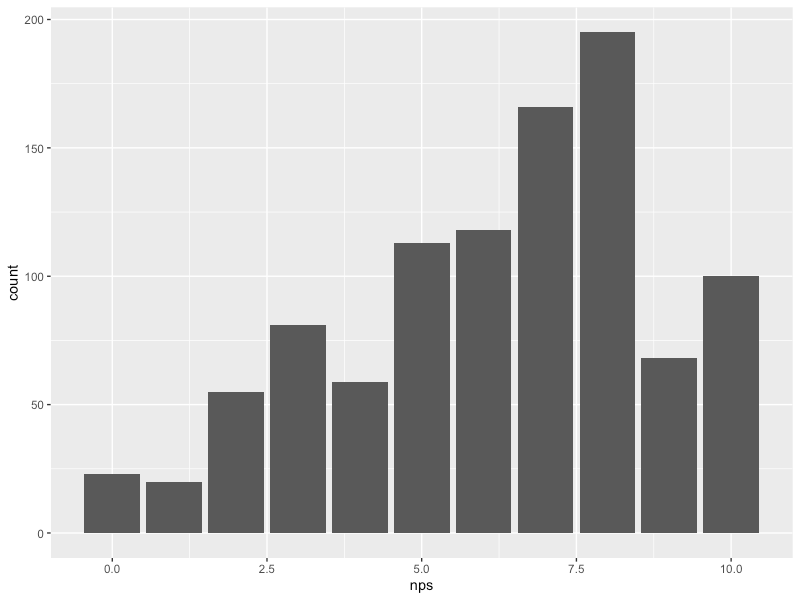
ggplotでNPSスコアの分布を可視化
geom_bar()でスコアの分布を可視化することができます。
ggplot(df,aes(x=nps)) +
geom_bar()
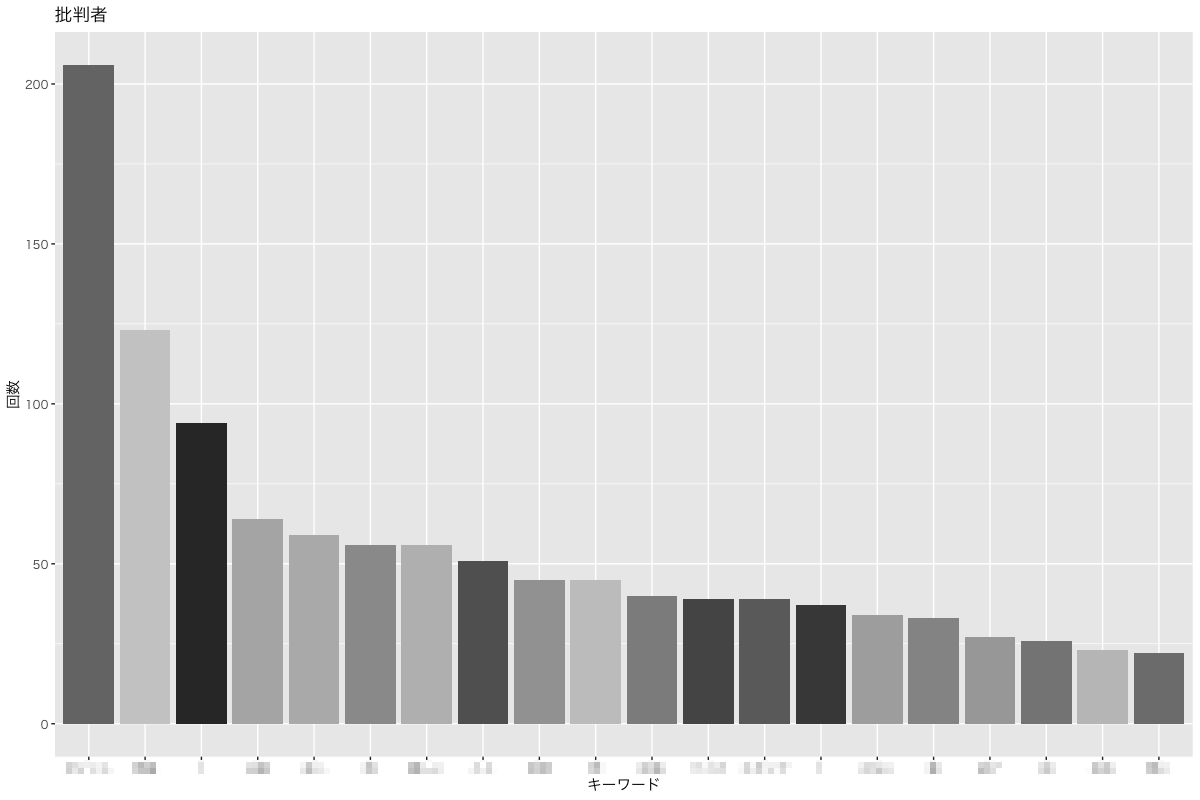
単語の頻度を可視化
RMeCabのdocDF()にて任意のテキストを分かち書きします。
NPSスコア(0〜6、7〜8、9〜10)ごとに単語の頻出度を可視化することで推奨者・中立者・批判者ごとの自由回答の傾向を掴むことができます。
word_detractors <- df %>%
as.data.frame() %>% #RMeCabはtibble形式を受け付けないのでdataframeへキャスト
filter(nps <= 6) %>%
docDF(col="text",type=1,N=1) %>%
mutate(freq = rowSums(.[4:ncol(.)])) %>%
select(TERM,POS1,POS2,freq) %>%
group_by(TERM) %>%
mutate(freq = sum(freq)) %>%
distinct(TERM,.keep_all=TRUE)%>%
filter(POS1 == "名詞"|POS1 == "形容詞" ) %>%
arrange(desc(freq)) %>%
select(TERM,freq) %>%
head(20)
plot_detractors <-
ggplot(word_detractors, aes(x=reorder(x = TERM, X = -freq, FUN = mean),y = freq,fill=TERM)) +
geom_bar(stat = "identity", show.legend = FALSE) +
ggtitle("批判者")+
labs(x="キーワード",y="回数")+
theme_gray (base_family = "HiraKakuPro-W3") +
scale_fill_grey()
plot_detractors


任意の単語と共起する単語の集計
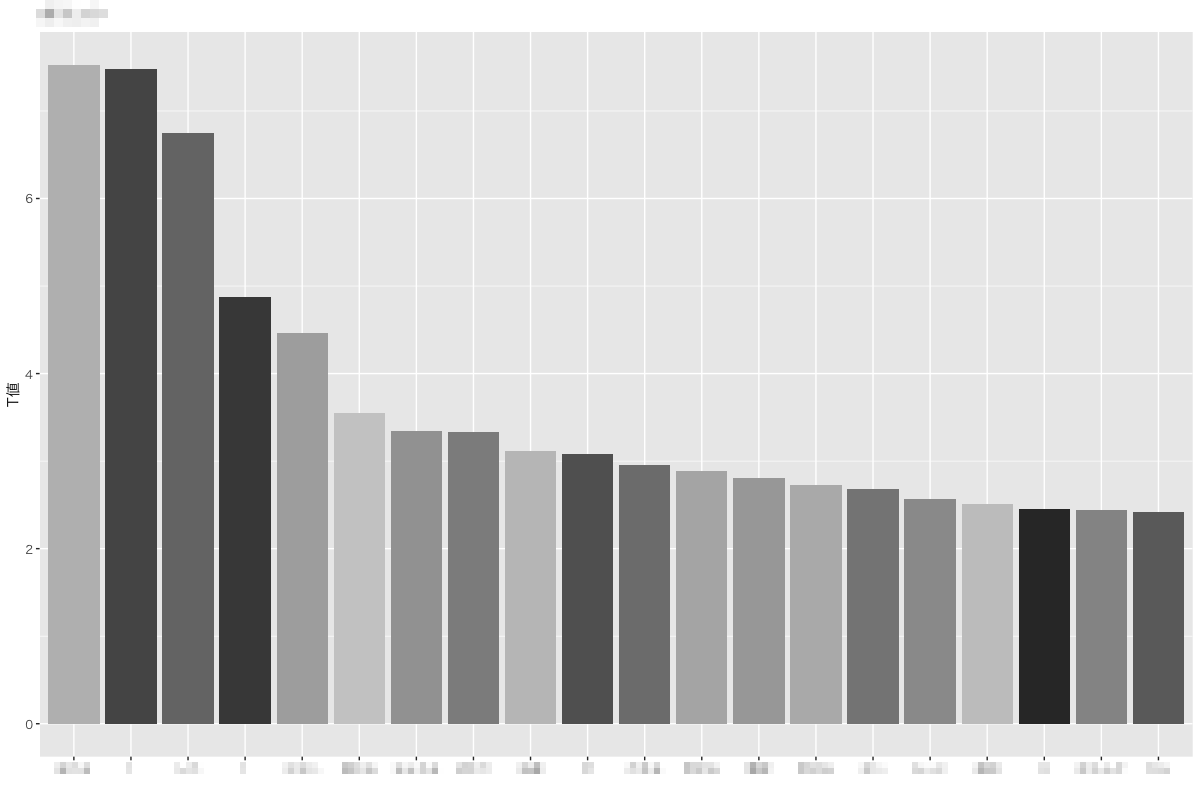
目立った頻度の単語があればRMeCabのcollScores()を用いてその単語と共起する単語も抽出することができます。
col_point <- collocate("./nps.csv","任意の単語",5)
col_point <- collScores(col_point,node="任意の単語",span=5) %>%
arrange(desc(T)) %>%
head(20)
plot_col_point <-
ggplot(col_point, aes(x=reorder(x = Term, X = -T, FUN = mean),y = T,fill=Term)) +
geom_bar(stat = "identity", show.legend = FALSE) +
ggtitle("任意の単語")+
labs(x="",y="T値")+
theme_gray (base_family = "HiraKakuPro-W3") +
scale_fill_grey()
plot_col_point
共起ネットワークによる可視化
igraphパッケージを利用することで、単語の組み合わせを網羅的に可視化することができます。ここでは単語2-gramでの集計結果を利用しています。
df <- docDF("./nps.csv",type=1,nDF=1,N=2,pos = c("名詞","形容詞","動詞")) %>%
select(N1,N2,nps.csv) %>%
filter(nps.csv >7)
g <- graph.data.frame(df)
plot(g, vertex.label = V(g)$name,vertex.color = "grey",vertex.label.family = "HiraKakuProN-W3")

用例検索 (KWICコンコーダンス)
任意の単語の前後に注目して どのようなコンテキストでその単語が利用されているかを把握します。
kwic.conc <- function(vector,word,span){
word.vector <- vector
word.positions <- which(word.vector == word)
context <- span
for (i in seq(word.positions)) {
if(word.positions[i]==1){
before <- NULL
}else{
start <- word.positions[i] - context
start <- max(start,1)
before <- word.vector[start:(word.positions[i]-1)]
}
end <- word.positions[i] + context
after <- word.vector[(word.positions[i] + 1) : end]
after[is.na(after)] <- ""
keyword <- word.vector[word.positions[i]]
cat("-------------",i,"-------------","\n")
cat(before,"[",keyword, "]",after,"\n")
}
}
※Rによるやさしいテキストマイニング [活用事例編]のコードをそのままお借りしています。
関数の利用イメージ
「もっと」や「ほしい(欲しい)」という単語の前後に注目することで、お客様の要望事項を把握することができます。
kwic_detractors <- df %>%
filter(nps <= 6) %>%
select(text) %>%
as.data.frame() %>%
RMeCabDF() %>%
unlist()
kwic.conc(kwic_detractors,"もっと",4)
------------- 1 -------------
とても 使いやすい です が [もっと] 不具合 を 減らして ほしい
------------- 2 -------------
いうと 不満 です ね [もっと] キャンペーン を 実施 して もらえると
------------- 3 -------------
は いいの だけ ど [もっと] 広告 を 減らして 欲しい
NPSを運用してみた感想
スコアとしてのNPSは「統計的な信頼区間」や「事業指標(顧客行動)との相関の有無」の考慮も必要であったり他のサービスと単純比較もできず取り扱い方は難しいですが、システムとしてのNPSはシンプルに「お客様の意見を定量的に把握し、その声に向き合いながらサービスを改善していく」という性質のものでサービス運営として有用だと感じています。
そして定量データだけでは「何が起きているか」は分かっても「なぜ起きているか」は分からないので、定性としての自由回答の重要性も実感できました。
この記事で書いた方法であれば導入のコストは低いので、細かいことを考えずにまずは始めてみるといいかもしれません。