はじめに
今回はICWSM-14で提案されたVADERという感情分析手法を用いて,約1年間分の英語のツイートデータを解析してみました.VADERについてはNLTKにSentiment Analysisがやってきたという記事を参照しました.ありがとうございます.
VADER
VADERはPythonの自然言語処理パッケージのnltkに実装されています.
使ってみると.
In [1]: from nltk.sentiment.vader import SentimentIntensityAnalyzer
In [2]: analyzer = SentimentIntensityAnalyzer()
In [3]: analyzer.polarity_scores("I am happy!!!")
Out[3]: {'compound': 0.6784, 'neg': 0.0, 'neu': 0.179, 'pos': 0.821}
と"compound","neg"(nagative),"neu"(neutral),"pos"(positive)の4種類が0~1で出力されます.
データセットと実験
2014/10/31から2015/10/28までのTwitter Streaming APIで取得した英語のツイート(を先輩から頂きました!).1日あたり1089358件ツイートがあった.各ツイートについて感情分析し,"pos"の値を日毎に平均をとった.さらに,最終的なデータについて平均0,標準偏差1となるように基準化を行いました.
関連研究(?)
Twitter mood predicts the stock marketという論文で,極性分析ツールであるOpinionFinderと6種類の感情因子を分析するGPOMSをつかって以下の様な結果が得られていました.
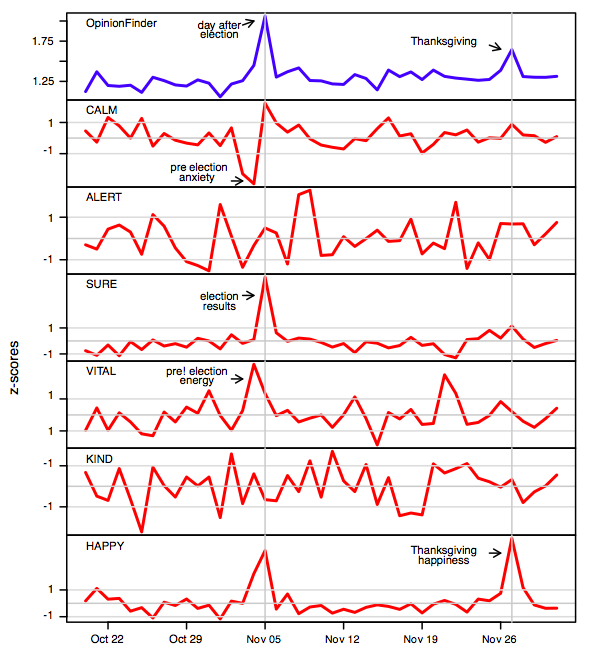
今回の"pos"の値がOpinionFinderやGPOMSのHappyの結果に近づくことが予想されます.
結果
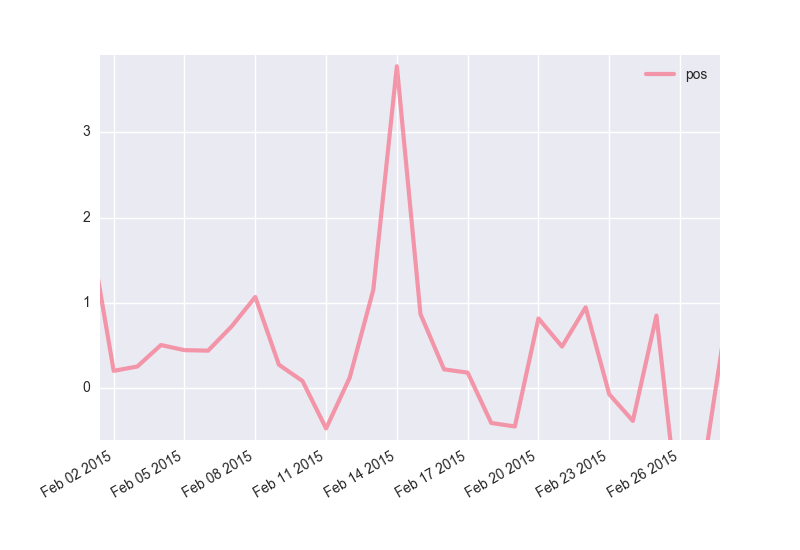
得られた結果を時系列のグラフとして描画する.
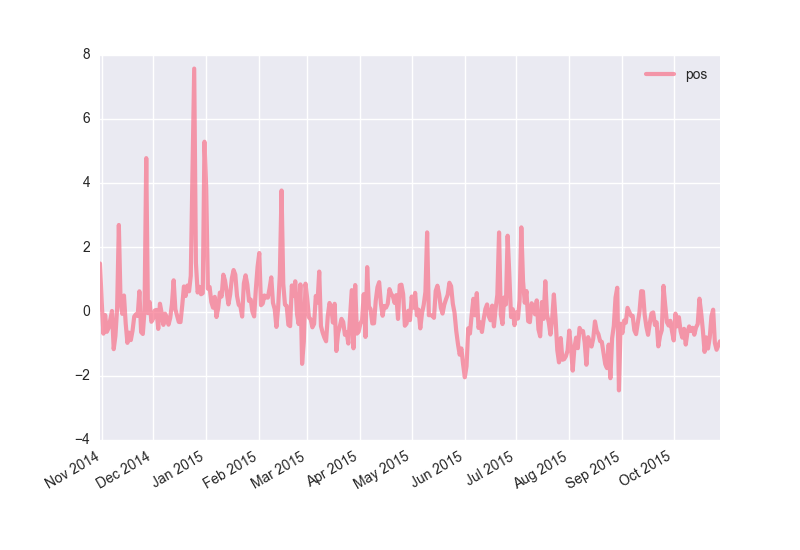
何本か上に飛び出ている箇所があるので注目する.
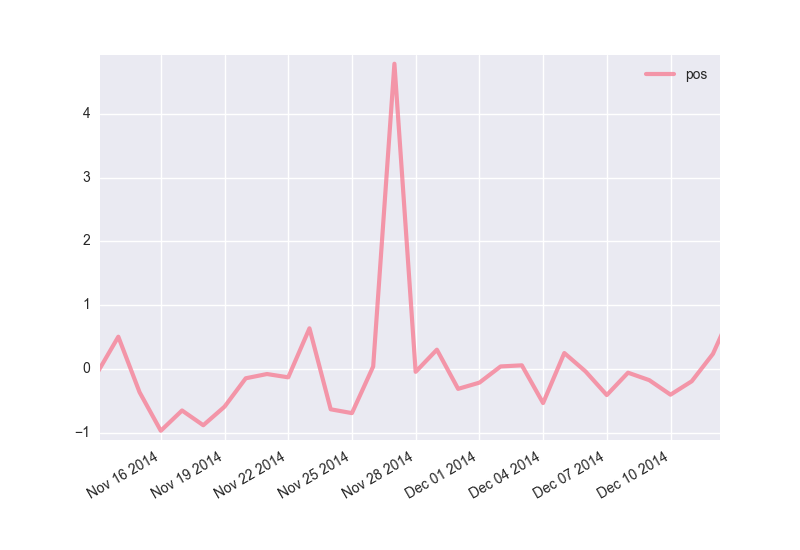
感謝祭(2014/11/27)
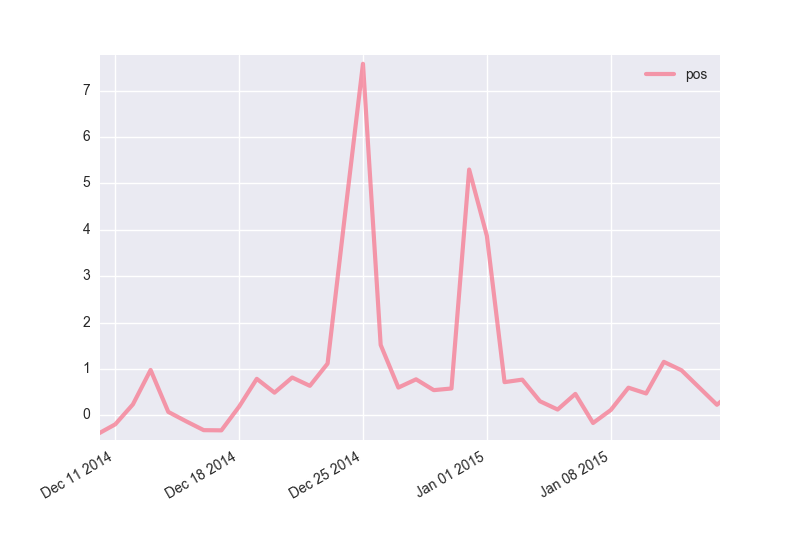
クリスマスと年末年始
バレンタインデー
おわりに
楽しくなるようイベントがあるときにはみんなポジティブになってますね!!
"neg"の値が大きい部分も分析してみたかったんですが,結局原因が分からなかったです.