こんにちは,@hogefugabarです.
この記事はDeepLearning Advent Calendar 2016の21日目の記事です.
専門では無いですが,声質変換について書きます.
本記事執筆に当たって,@asteer23に助言を頂きました.感謝します.
指摘等歓迎です.
(随時コードも上げていきたいが修論があるので確約はできないです)
はじめに
声質変換とは,「ある話者の音声」(入力)を「ターゲットとなる話者(出力話者)が同じ内容を話したかのような音声」(出力)に変換することである.イメージはコナンくんの蝶ネクタイなのである.
声質変換システムの概要
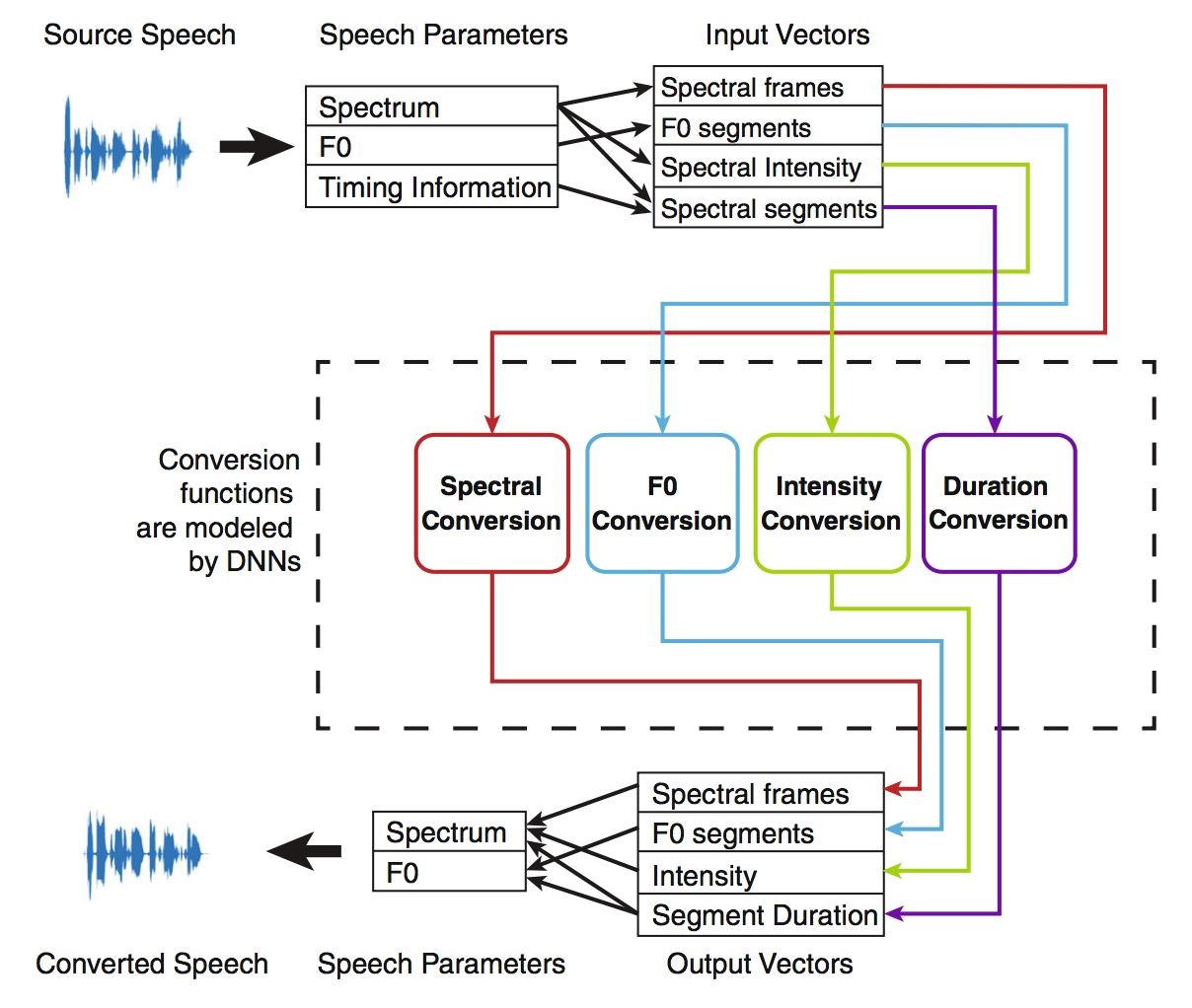
一般的な声質変換システムの概要を示したのが以下の図である.

- 入力話者の音声データ(WAVファイル)から音響特徴量(後述)を抽出
- 出力話者を目標として学習したモデルを用い,音響特徴量を変換
- 音響特徴量から音声データ(WAVファイル)を復元
という手順を踏むが,特徴量を変換するモデルを学習する際には,パラレルデータ(後述)が必要になる.
まずは音響特徴量について簡単に説明する.
音響特徴量
メル周波数ケプストラム係数(MFCC)
MFCCとは,人の声の周波数帯域を表現した比較的次元の小さい特徴量であり,高周波数帯域はうまく表現できていない.
詳しくはメル周波数ケプストラム係数(MFCC)| 人工知能に関する断創録を参照.
スペクトル包絡
スペクトル包絡は,MFCCと違い,高周波数帯域も表現している特徴量である.
この特徴量はTANDEM-STRAIGHTというツールを用いると抽出することができる.
TANDEM-STRAIGHTを用いると,音声データ(WAVファイル)から各フレーム毎に以下の3つの特徴を抽出できる.
- 基本周波数(スカラー)
- スペクトル包絡(ベクトル)
- 非周期性指標(ベクトル)
1つのフレームは,$x$ミリ秒の情報をフレームシフト$y$ミリ秒で持つ.
$x$と$y$はそれぞれ自分で設定でき,例えば$x = 40, y = 5$等とする.
もちろん, TANDEM-STRAIGHTにより3つの特徴から音声データ(WAVファイル)を復元することもできる.
最近の声質変換の研究では,基本周波数は線形変換,スペクトル包絡はDNN等による非線形変換1が行われる.非周期性指標は入力話者のものをそのままつかうことが多い.
前処理
概要で,変換モデルの学習にはパラレルデータが必要になると述べたが,パラレルデータが一体何なのかを説明する.
パラレルデータとは,入力話者と出力話者について同時に同じ内容を発話した音声データのことをいう.
例えば,両話者が同時に同じタイミングで「こんにちは」と発話したデータ等のことである.
しかし,実際には話すスピードや,呼吸を置く間,全体の長さが異なっており,両話者間で対応が取れていないのが実態である.
http://hil.t.u-tokyo.ac.jp/~kameoka/aa/AA14_05.pdf
そこで,動的時間伸縮(Dynamic Time Warping:DTW)という手法により,パラレルデータの作成を行う.アルゴリズム詳細は下記参照.
http://hil.t.u-tokyo.ac.jp/~kameoka/aa/AA14_05.pdf
深層学習による音響特徴量変換
声質変換系の研究ではINTERSPEECHやIEEE ICASSPがトップカンファレンスとなっているので,このあたりを見れば最新の動向がわかるかも.
DNN
Voice Conversion using Artificial Neural Networks [Desai+ '09]
ICASSP2009の論文.当時state-of-the-artだったGMMにDNNがoutperformしたよという論文.
特徴量はMFCCを使用.誤差関数にはMCD(Mel Cepstral Distortion)を使用.3~5層で実験.
https://www.cs.cmu.edu/~awb/papers/icassp2009/2008_28.pdf
DBNを用いたモデル
Voice Conversion in High-order Eigen Space using Deep Belief Nets [Nakashika+ '13]
INTERSPEECH2013の論文.DBNを用いて高次特徴量を抽出し,NNで変換するモデル.
https://pdfs.semanticscholar.org/0a45/9255c11543894735b7950a2292651c809b6c.pdf
Autoencoderを用いたモデル
Autoencoderを用いて事前学習を行うモデル.
こちらにデモがある.
High Quality Voice Conversion using Prosodic and High-Resolution Spectral Features [Nguyen+ '15]
http://link.springer.com/article/10.1007/s11042-015-3039-x
LSTMを用いたモデル
Voice Conversion using Deep Bidirectional Long Short-Term Memory based Recurrent Neural Networks [Sun+ '15]
ICASSP2015の論文.通常のLSTMは過去の入力から未来の出力を予測するモデルだったが,Bidirectional LSTMは未来の入力から過去の出力を予測するモデルも同時に組み込んでいる.音声認識の分野で精度向上したこのモデルを使うことにより,変換精度向上を目指した.
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.699.5280&rep=rep1&type=pdf
終わりに
残念ながら現状のデモを聴く限りではコナン君の蝶ネクタイにはまだまだほど遠いレベルである.
WaveNetのようにWAVファイルの情報を畳み込んだりなんかして超高精度に変換するのが出てきそうな気もするが,その場合データが大量に必要になりそう...
-
線形変換モデルである混合ガウスモデル(GMM)を使う研究もなされている. ↩