はじめに
今回は強化学習,その中でもQ学習を使って迷路を探索したいと思います.
Q学習
概要
簡単に言うと,「状態」と「行動」のペア毎にQ値という値を保持しておき,「報酬」などを使ってQ値を更新していきます.正の報酬を得られる可能性が高い行動ほど高いQ値に収束していきます.迷路で言えば,通路のマスが状態に相当し,上下左右に移動することが行動に相当します.つまり,Q値は通路のマスの数*行動パターン数(上下左右なら4)分だけメモリに保持しておく必要があります.そのため「状態」と「行動」のペアがたくさんある,つまり状態行動空間(state and action space)が爆発してしまうような場合には簡単に適応できません.
今回は通路のマス数が60,行動可能な行動数が上下左右の4つの240ほどのQ値を保持しておけばよい問題を取り扱います.
アルゴリズム
Q値の更新
はじめQ値は全て0で初期化します.
状態$s_t$で行動$a$を取る毎にQ値を更新します.
$$Q(s_t, a) \leftarrow Q(s_t, a) + \alpha(r_{t+1} + \gamma \max_{p}{Q(s_{t+1}, p)} -Q(s_t, a))$$
行動選択
今回はε-greedyを使います.小さい確率εでランダムな行動を,1-εの確率でQ値が最大の行動を選択します.
ソースコード
コードはGithubに上げました.python map.pyとしてやってくだい.2年位まえに書いたのですが,なかなかひどい.
実験
環境
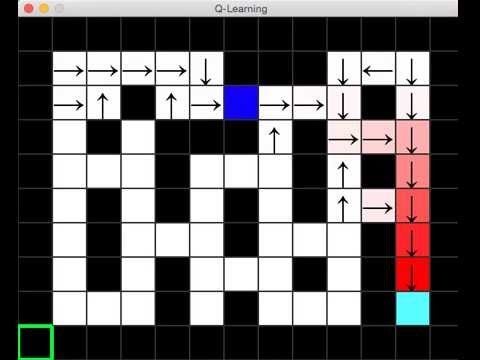
実験環境は以下の写真のようになっていて,右下の水色のマスがゴール,一番左上のマスがスタート,青い4角が学習エージェントとなっています.ゴールに到達すると,正の報酬がもらえます.また,黒い部分が壁でエージェントが入り込むことができません.なのでエージェントは白い通路の部分を通るしかありません.各マスのQ値は0で初期化されていますが,Q値が0より大きくなったとき,そのマスにおける4つのQ値の一番大きいQ値が色の濃淡で,行動が矢印で表示される仕組みになっています.

結果
実験結果はyoutubeに上げました.エージェントがゴールに到達するにつれてQ値が伝搬されていくのがわかるかと思います.
おわりに
Q学習+ニューラルネットやってみたい