概要
皆様,こんにちは.
漸く緊急事態宣言が解除されましたが,まだまだ予断を許さない状況が続いていますね..
まだまだ私も,家にこもりっぱなしの生活が続きそうです.
さて,今回は,シンプルなAutoencoderを用いてMNISTに対する異常検知プログラムを実装し,検証していきたいと思います.具体的には,以下のようなモデルとなります.

(当記事でご理解いただけるのは,Autoencoderと異常検知の基本的な流れ,PyTorchを用いたMNISTの異常検知の流れとその検証結果です.)
QiitaにはすでにMNISTを使った異常検知の記事が何件か掲載されております.
なので,じゃあこの記事の需要はどこに?って話になるのですが,実はPyTorchで実装している点が他と違う点と考えています.
ググると良くでてくるのはKerasを使った実装例なんですが,僕は最近PyTorchに乗り換えた身なので,PyTorchの実装ないかなーとあさっていたんですが,見つからなかったので自分で実装した次第です.それでは解説に参ります.
なお,今回の実装したコードはすべてこちらで公開しております.
Autoencoderと異常検知
Autoencoderがどのように異常検知タスクに応用されるのか,簡単に振り返ります.(ご存じの方は実装以降の章をご覧ください)
Autoencoderについて
モデルの構造を以下に示します.
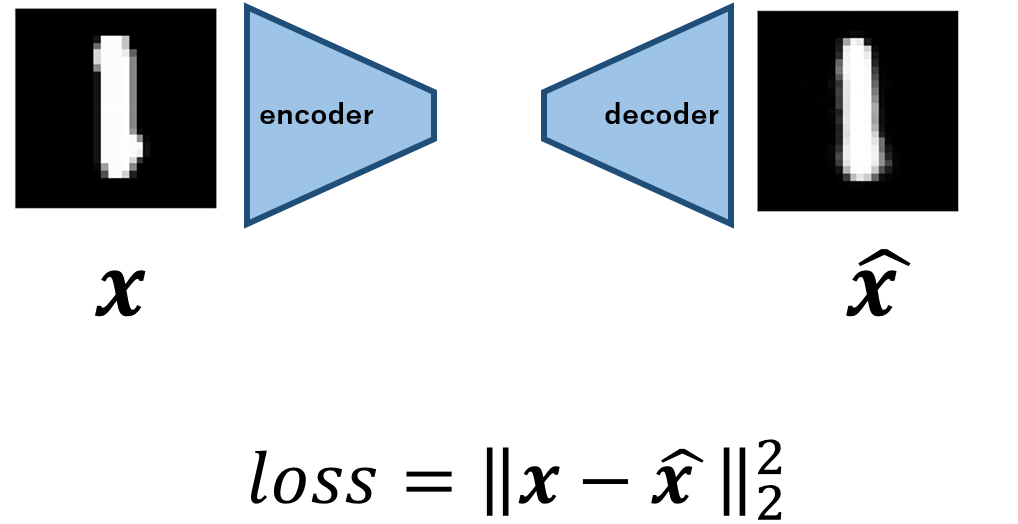
Autoencoderの発想はいたってシンプルで,画像などが存在する高次元データをencoderを用いて潜在変数へと符号し,decoderを用いて画像を復号するモデルです.
潜在空間へと写像するメリットは何?となってくるわけですが,これは多様体仮説に基づいています.以下の分布をご覧ください.
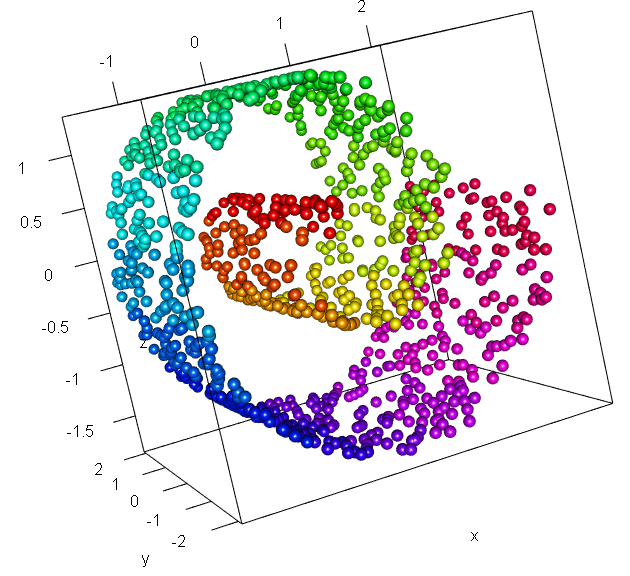
引用元:こちら
上記はスイスロール分布と呼ばれるものです.画像では三次元ですが,高次元データの例だとお考え下さい.よく見ると,かなりデータが疎な部分が存在しているのがわかるかと思います.これを二次元に写像する(平面に引き延ばすようなイメージ)ことができれば,元の分布を低次元空間で表現可能と推測できます.より一般的に言えば,高次元空間に存在するデータは低次元多様体としてとらえられる,これを多様体仮説と呼びます.
Autoencoderの話に戻ると,encoderによって,高次元空間から低次元の潜在空間へと写像されるのでした.つまり,画像のような高次元のデータの「特徴」なるものを抽出し,潜在変数として扱っていることになります.
この低次元の「特徴」から,元のデータを復号するのです.
異常検知への応用
このAutoencoderの枠組みは,異常検知でしばしば応用されます[1].
異常検知の目的は,入力データに対してモデルが「正常」か「異常」かどうかを認識することにあります.この問題設定は,よく用いられる教師あり学習でのパターン認識の枠組みですが,残念ながら異常検知が実際に応用される工場など(外観検査)の多くは,異常データが集まらないのが普通です.
そのため,パターン認識のような教師ありのアプローチは適用できません.
しかし,一般に工場などの現場では,大量に「正常」なデータが取得できます.これを活用して,「異常検知」に落とし込むために,Autoencoderが登場します.
上記までで説明した通り,Autoencoderでは高次元のデータの分布から,特徴を抽出して低次元の潜在空間へと写像することができます.
つまり,***大量の正常データを用いてモデルを学習することで,正常なデータの特徴を獲得できます.***このことから,「正常」なデータをモデルに入力すれば,もちろんdecoderは元の入力を復号できるでしょう.しかし「異常」なデータが入力されたとき,これは異常なデータを表現できる特徴を獲得していないので,うまく復号することができません.
このトリックを用いて異常検知が行われます.具体的には,入出力間で差分をとり,それを異常度として計算することで異常が検知できます.
なお,実際の異常検知への応用事例は,大半が「教師なし」もしくはわずかな異常データを活用する「半教師あり」の二つが用いられます.
次に,実際にMNISTの実装と実験を確認することで,より理解を深めていただければと思います.
実装・MNISTのロード部分
MNIST(手書き数字のデータセット)を用いて異常検知をさせます.今回は,MNISTの有する0~9のうち,「1」のラベルがついたものを正常データとして学習します.
そして,「9」のラベルがついたものを異常データとして,これを検知できるかどうかを検証していきます.
まず,PyTorchのdatasetクラスのMNISTモジュールを用いることで,簡単にMNISTデータをロードできます.
しかしこのままでは,0~9すべてのデータが存在していますので,これを任意のラベルのものにのみ絞る作業が必要です.以下のようなクラスを定義しました.
class Mnisttox(Dataset):
def __init__(self, datasets ,labels:list):
self.dataset = [datasets[i][0] for i in range(len(datasets))
if datasets[i][1] in labels ]
self.labels = labels
self.len_oneclass = int(len(self.dataset)/10)
def __len__(self):
return int(len(self.dataset))
def __getitem__(self, index):
img = self.dataset[index]
return img,[]
初期化メソッドでは,引数として与えた任意のラベルのlistに該当するデータのみを,クラス内の変数として渡しています.後は通常のDatasetクラスと同じ挙動ですね.
肝心のAutoencoderは,以下のように定義しています.
class Autoencoder(nn.Module):
def __init__(self,z_dim):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(28 * 28, 256),
nn.ReLU(True),
nn.Linear(256, 128),
nn.ReLU(True),
nn.Linear(128, z_dim))
self.decoder = nn.Sequential(
nn.Linear(z_dim, 128),
nn.ReLU(True),
nn.Linear(128, 256),
nn.ReLU(True),
nn.Linear(256, 28 * 28),
nn.Tanh()
)
def forward(self, x):
z = self.encoder(x)
xhat = self.decoder(z)
return xhat
それぞれ三層のシンプルなものです.
学習は入出力間のMSEをとり,これを最小化することで入力を再構成するように学習されます.
では,実験に入ります.
実験・考察
上記のように,学習データは「1」の画像のみで,約6,000枚の画像データを学習します.
テストデータは「1」と「9」のデータを混ぜ,「9」を正しく異常と判別できるかを確認します.
なお,異常度の定義は入出力間の差の絶対値を用います.
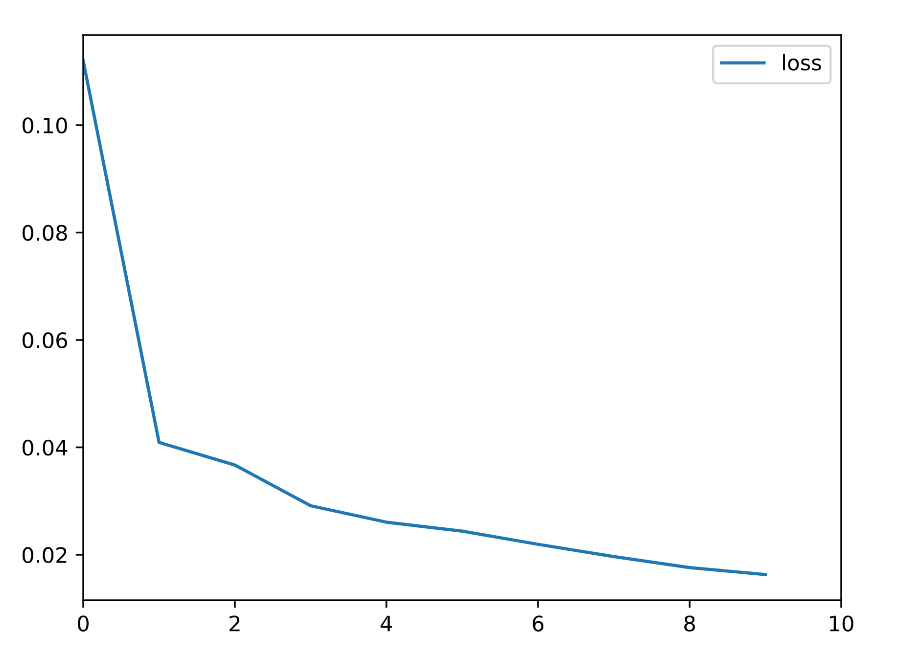
lossの推移をを以下に示します.
モデルの入力(上段)と,その出力(中段),さらにその差分画像(下段)を以下に示します.
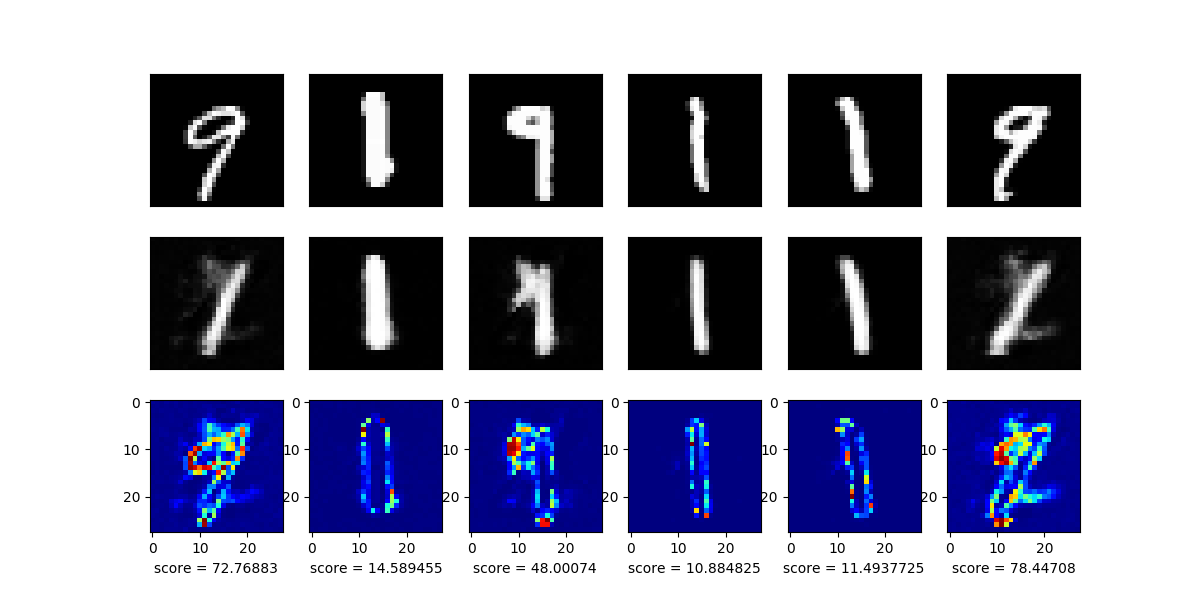
目論見通り,学習した「1」の画像はうまく再構成できているのがわかりますが,異常データとして混ぜた「9」のデータはうまく再構成できていないのがわかりますね.
今回はシンプルな全結合層のみのモデルでしたが,うまくいった印象です.
また,下段のscoreに着目すると,異常データが入力された際には値が大きくなっていることがわかります.
実際には異常度に閾値を設けることで,異常検知を行います.閾値の設け方は,専門家による設計だよりであることがほとんどです.
まとめ
今回は,PyTorchを用いてMNISTによる教師なし異常検知を実装し,検証しました.
また,Autoencoderを用いた異常検知の基本的な流れについても解説しました.
今回の記事は,技術的な新規性という観点では微妙になってしまいましたが,PyTorchによるMNISTの異常検知という意味では需要があるかと思ってます(そう思っているのは僕だけかもしれませんが(笑))
記事が冗長になるのを恐れて,異常検知性能の定量的評価(AUROCなど)までは手をつけませんでしたが,近いうちにまとめたいと思います.
同時に,GANによる異常検知のframeworkの検証も行いたいところです.
最近では,Autoencoderからさらに発展して,AnoGAN,EfficientGAN,AnoVAEGANなど,多様なGANを活用した異常検知のframeworkが登場し,次々にSOTAを獲得しています.
今後の動向にさらに期待できますね.
参考文献