はじめに
今回は「達人に学ぶDB設計徹底指南書」を読了したのでその感想記事を作成しました。
DB設計はWebシステムの根幹を成す部分で、本書にも「DB設計に合わせてプログラミング言語を記述する」と書かれています。
本記事を読んで、少しでもDB設計の重要性を認識し、学習のキッカケになればと思っております。
良かったところ
実務で通用するノウハウを知ることができる
他の技術書よりも、より実務を意識した内容が記述されており、より現場で使える実践的な知識をインプットすることができます。
例えば、DB設計の基本の「正規化」に関しても、
- なぜ正規化を行う必要があるのか、正規化しないとシステム全体にどのような影響を及ぼすのか
- 正規化は絶対的な方法ではなく、場合によっては非正規化しなければいけない時もある
- 正規化でテーブルを分割しすぎると、逆にパフォーマンスが悪化することがある
といった形で、現場目線かつメリット・デメリット考慮した多角的な視点で正規化の説明が記述されています。
他にもDB設計のアンチパターンや、DB設計の具体的手順など
著者の経験を交えた実務ベースで説明がされており、自身が実務でDB設計を行う際にも都度読み返したいと感じることができました。
学んだところ
1:なぜDB設計が重要なのか
本書の冒頭に 「データベースを制するものはシステムを制す」 と記述されているように、安定して稼働するWebシステムを作るには、正確なDB設計が必要不可欠です。
全てのWebシステムにはDBが必要
Webシステムというのは簡単に説明すると、
DBに作成された箱(テーブル)に対して、
バックエンドの言語(Ruby,PHPなど)でデータの作成、読出、更新、削除(CRUD)を行い、
その結果をフロントエンド(HTML/CSS,JavaScript)で表示する
という形で成り立っています。(他にインフラ等もありますがここでは割愛)
原則、DBがないシステムは存在しません。
そしてDB設計の品質はシステム全体の品質に影響を及ぼします。
DB設計がシステム全体に与える影響
身近な例で説明すると
上司に会議に必要な書類を収納棚から持ってきて欲しいと頼まれたとして、
「どこに何が入っているか分からない収納棚」 と 「整理整頓されていて、どこに何が入っているか一目瞭然の収納棚」
のどちらが 早く、正確に 上司に書類を持っていくことができるでしょうか?
当然後者の 「整理整頓された収納収納棚」 ですよね?
話をDB設計に戻すと
書類が収納されている棚がテーブルで、それを取り出す人がバックエンド言語(Ruby,PHP) で
DB設計の段階で「列、テーブル」を正しく整理、分割した上で作成されたDBでは、バックエンド言語の記述もシンプルになり、仕様変更にも強い、安定したシステムを作り上げることができます。
DBは後から修正できない
またプログラムは後から修正することが可能ですが、DBに関しては作り直すということは、システムそのものを0から作り直すということになってしまいます。
家で例えると、外壁や内装は後から改装することは可能ですが、基礎部分や、骨組み、柱は後から部分的に変えることができないのと同じです。
つまり、それだけDB設計の段階で後戻りがないように、設計しなければならないということです。
2:論理設計
DB設計では大きく分けると 論理設計 と物理設計に分かれていますが、
本書では論理設計を中心に記述されていたので、そちらについて説明していければと思います。
論理設計とは
データベースの要素やデータ同士の関連性を定義することを「論理設計」と呼びます。
ユーザー側の現実世界と開発者側のDBの世界を繋ぐ翻訳書のようなもので、
ユーザーの要望をシステムのDBに落とし込んで実装していくのに必要不可欠なプロセスということができます。
論理設計の手順
- エンティティの抽出
↓ - エンティティの定義
↓ - 正規化
↓ - ER図の作成
エンティティの抽出
要件定義の段階で、どのようなエンティティ(実体)が必要になるか決めていくことになります。
例えばとある会社の勤怠管理システムを作るとなった時に、
「社員名」「所属部署」「出勤時間・退勤時間」「時給」「雇用形態」などが必要になってきそうですね。
このように、システムのDBに必要な要素を洗い出していく作業を行っていきます。
エンティティの定義
上記にて抽出した属性ごとにデータを整理して、テーブルの形で列と行に分けていきます。
例)田中太郎 → 「社員名」属性
経理部 →「部署」属性
正社員 →「雇用形態」属性、、、など
そして行・列に分けたテーブルの中で、行を一意に特定するためのキーもここで決めていきます。
正規化
上記にて属性ごとに分けて、行列に分けデータを詰め込んだ1つのテーブルを
分類ごとに分割していく作業のことを正規化と呼び、
正規化を行うことで、データの登録、変更、削除が整合的に行えるようになるというメリットがあります。
この正規化は論理設計において、重要な土台をなしており、論理設計を理解する鍵とも言うことができ
本書でも説明に多くのページが割かれています。
ER図の作成
ER図は上記の正規化作業にて分割したテーブルの関連性を分かりやすく表した図のことを言います。
大規模なシステムになると、正規化によって何百にもテーブルが分割されていることもあり、テーブル同士の関係性をなんの助けも無しに理解することは困難でしょう。
ER図の作成は上記問題を解決するのに必要不可欠なプロセスと言うことができます。
3:正規化
先ほど説明した論理設計の中で特に理解を深めておきたい概念が正規化で、
本書でも折に触れてその重要性が記述されています。
正規化とは
正規化とは一言で言うと
「データの冗長性を排除して、一貫性と効率性を保持すること」を言います。
例えば1つのデータが複数のテーブルに重複して存在(冗長性)していると、
無駄なデータ領域と面倒な更新を発生させてしまい、データの不整合が発生したり、
データを登録できないようなテーブルを作ってしますことがあります。(非一貫性)
上記のような問題を解決するために作られた方法論が「正規化」です。
正規化には何段階かレベルがあり、第1〜5正規化までがよく知られていますが、
実務では第3まで理解できていれば十分なため、ここでは第1〜3正規化までを説明していきます。
第1正規化
第1正規化の定義は
1つのセルには1つしか含まないというものです。
下記に実際に表になります。
-
非正規形(正規化が行われていないテーブル)
下記の表では、1人の社員は複数の子供を養っている場合があるので、1人の社員につき複数の子供が対応することはあり、エクセルシートなどで表を作る時は、一つのセルに複数の値を入れ込むことは何ら問題ありません。
しかし、この場合だと、RDBの行は一意に識別できなければならないという原則に反することになります。
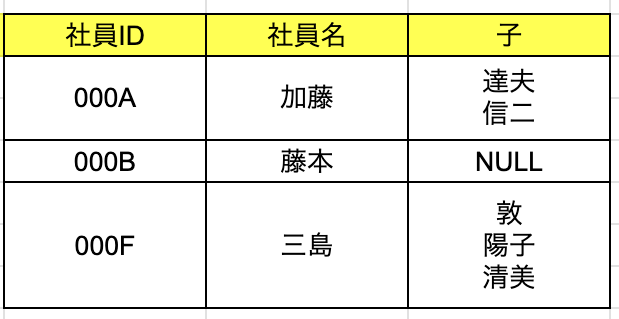
↓↓↓
- 第1正規形
RDBの規則を守るために、この数だけ、行を増やせばこの問題は解決できます。
こうすることで
{000A(1行目)} - {達夫}
{000A(2行目)} - {信二}
といった形で関数従属が成立し、値を一意に決めることができます。
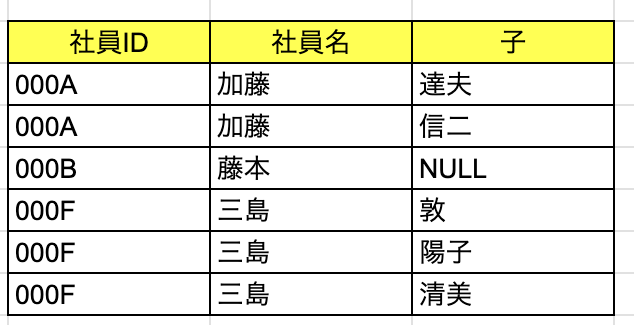
第2正規化
部分関数従属
第2正規形は部分関数従属を解消することで得ることができます。
部分関数従属とはどういったものなのか、下記の表を確認しながら説明していきます。
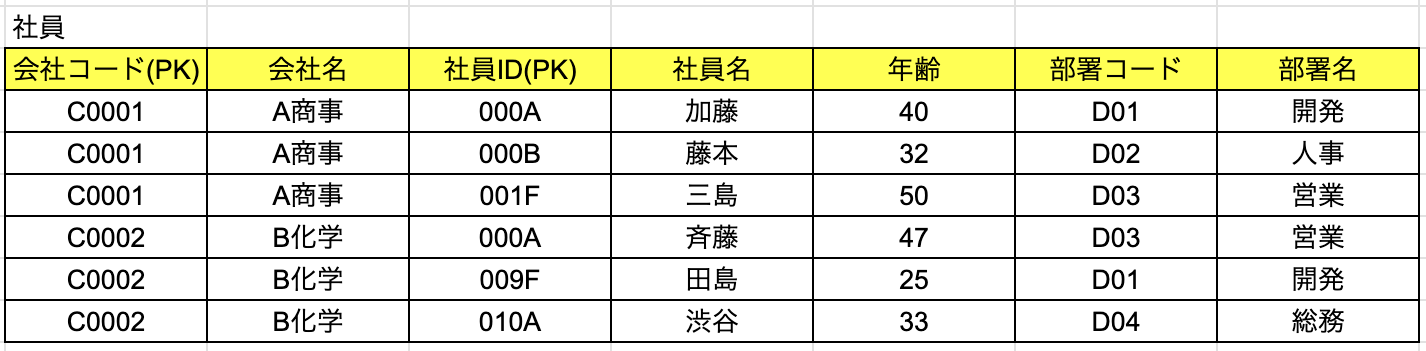
こちらのテーブルは1つの列に1つの値が入っているので、第1正規形は満たされています。
一方で、テーブルにおける関数従属が完全ではないため、第2正規形ではありません。
このテーブルの主キー(PK)は{会社コード,社員ID}で、複合主キーの形をとっており、他のすべての列は、
このキーに従属(主キーが決まると値が一意に決まる)しているはずですが、
よく見ると、{会社名}だけは{会社コード}にのみ従属しています。
(※{C0001,000A} - {A商事},{C0001,000B} - {A商事}といった形で,
社員IDが異なっても、同じ会社名なので、社員IDに従属しておらず、
{会社コード}-{会社名}といった形で会社名のみに従属している。)
このように、主キーの一部の列に対して従属する列がある場合、これを部分関数従属と言います。
部分関数従属を取り除いて第2正規化する手順
部分関数従属を解消する手段は、部分関数従属の関係にあるキー列と従属列を独立のテーブルにすれば解消されます。
- 第2正規化されたテーブル
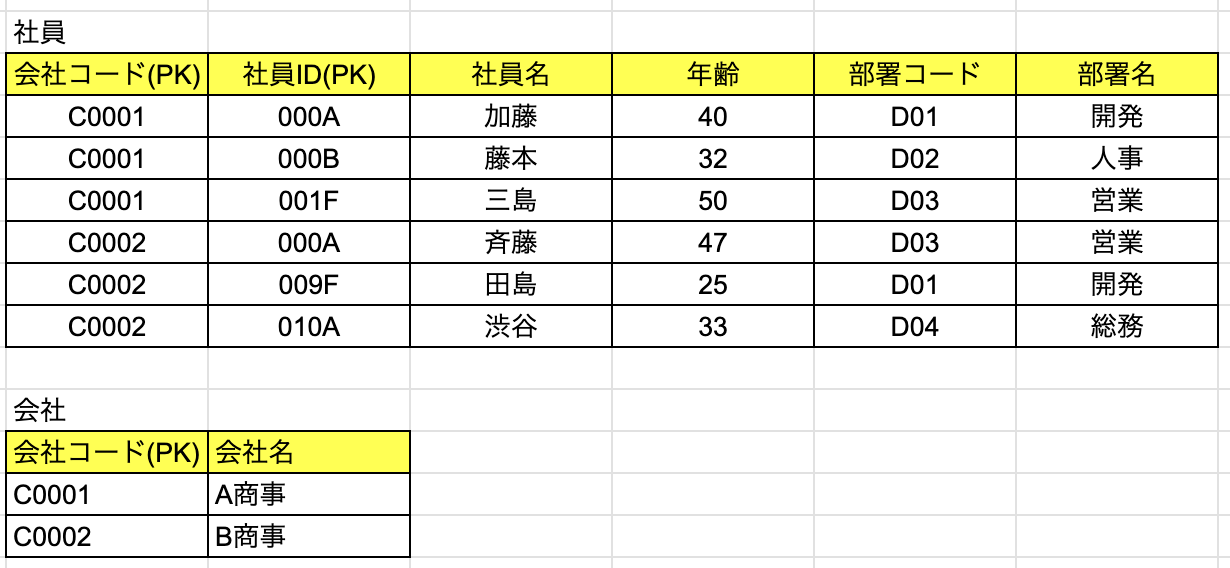
これによって、「社員」テーブルも、新しく作った「会社」テーブルも、全ての列が主キーに完全関数従属することになりました。
第3正規化
推移的関数従属
先ほど第2正規化した社員テーブルの「部署コード」と「部署名」に注目します。
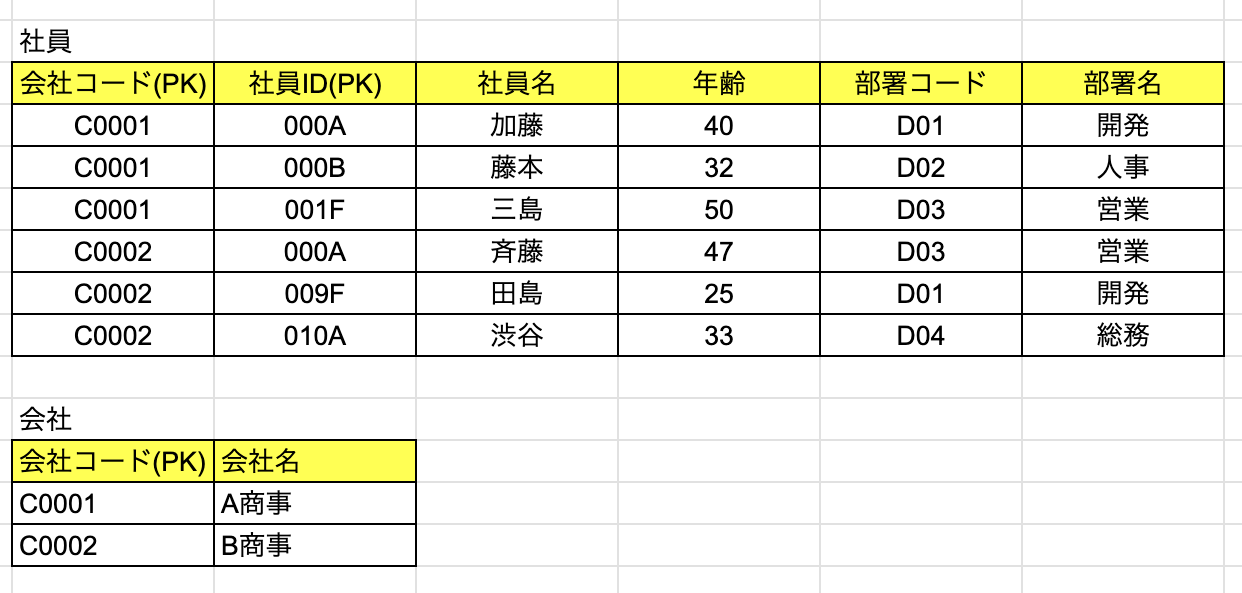
例えば、現在欠員が出て、 その部署には一人もいない場合もあり得るので、登録できるようにしなくてはいけません。
しかし、今の状態だと、主キーである「社員ID」をNULLの状態で、「部署」を登録することはできません。
このような問題が生じる理由は、
この社員テーブルに「推移関数従属」という従属性が残っているからです。
「部署コード」と「部署」に関しては、
{部署コード} → {部署名}
といった形で、関数従属が成立しています。
一方で、「社員ID」と「部署コード」の間にも
{会社コード,社員ID} → {部署コード}
といった形で、関数従属が成立しています。
全体として見ると、
{会社コード,社員ID} → {部署コード} → {部署名}
といった形で二段階の関数従属があり、
このような段階的な従属関係のことを、推移関数従属と呼びます。
推移関数従属を取り除いて第3正規化する
表題の方法は、第2正規化の時と同じ手順で、テーブルを分割することで、
推移関数従属関係にある項目を別テーブルに独立させることで達成できます。
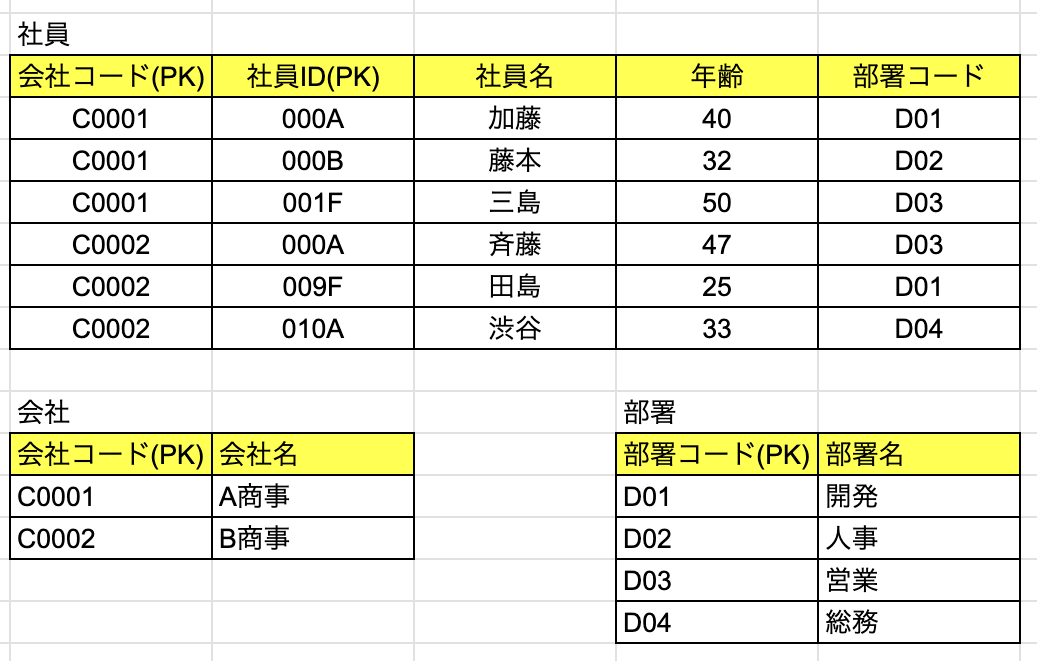
このように「部署」テーブルを独立させることで、全ての非キー列がキー列に対して完全関数従属になり、推移関数従属を除外することができました。
正規化のデメリット
ここまで、説明してきた正規化についてですが、思考停止でとりあえず正規化しておけばいいという訳ではありません。
DBの生合成維持という点において恩恵の多い正規化ですが、デメリットもあるのでその点も考慮しなくてはいけません。
結合によるコスト
正規化によってテーブルが分割されると、それを結合(join) するためのSQL文が必要になります。
結合はSQL文の中でも高コストのため、多用するとシステムのパフォーマンスの速度に悪影響を与えることがあります。
なので、場合によってはあえて正規化を行わず、非正規形のテーブルを作ることも頭に入れておかなければなりません。
原則は正規化
ここまで、正規化のメリットデメリットについて述べてきましたが、非正規系のテーブルを作成するのは切羽詰まった時の最終手段と本書で述べられています。
正規化はデメリットもありますが、データの整合受けられる恩恵の方が多いので、
よっぽどのことがない限りは正規化を用いたDB設計を行う方が良さそうです。
難しかったところ
基本用語の説明は割愛されている
表紙にも 「初級者で終わりたくないあなたへ」 と書かれているように、
こちらはすでにある程度基礎を学び終えた初級者から中・上級者を目指す人向けに書かれている書籍だということができます。
そのため、基本用語の解説が割愛されているので、初学の方は一度入門書で基礎を一通り学習することをお勧めします。
終わりに
いかがだったでしょうか。
DB設計はWeb開発学習の中でも学習が疎かになりがちな部分ですが、システムの基礎をなす不可欠な部分です。
これを記事が学習のきっかけになれば幸いです。
最後まで閲覧いただきありがとうございました!
参考文献