はじめに
自宅の空いているPCに、使用していない GeForce RTX 3050 を組み込んで、ローカル LLM を構築しました。
参考にしたウェブページ
開発環境
何も問題が起きないので、Windows の WSL2 などを使用せずに、空いているPCに直接 Linux をインストールします。いつも使用している Xubuntu が、llama-cpp-python のビルドでエラーが出て回避方法が難しいので、今回は Debian(Xfce版)を使用しました。Debian は Ubuntu のベースOSなので、操作がほとんど同じです。
デスクトップ自作PC(GIGABYTE B550 マザーボード)
AMD Ryzen 5 5600G 6コア 12スレッド 3.9GHz
メモリ DDR4-3200 16GB x 2
SSD 1TB
GeForce RTX 3050 (他のPCで 4080 SUPER に置き換えたので未使用でした)
Debian インストール
debian-live-12.9.0-amd64-xfce.iso
Rufus を使って起動 USB メモリを作成
PCの電源を入れて DEL キーを押して USB から立ち上げる
デスクトップに表示される Install Debian アイコンをダブルクリックして、PCへのインストールを開始
Language: English
Location: Asia、Tokyo
Keyboard: Japanese
Your name: webmaster
Your computer's name: bookworm01
Your username: webmaster
Password: ******
Confirm password: ******
ネットワークは有線で接続
インストールが終わったら、USB メモリを外して起動
OS アップデート
sudo apt-get update
sudo apt-get upgrade
sudo apt-get dist-upgrade
再起動
SSH インストール
sudo apt update
sudo apt install openssh-server
外部から SSH で接続
ssh -l webmaster 192.168.1.27
password: ******
日本語入力
日本語入力をセットアップしますが、画面は英語のままにしています
Debian でモジュールが1個欠けている模様
参考
https://fridaynight-hilite-club.hatenablog.com/entry/2025/01/11/193821
sudo apt update
sudo apt install mozc-server mozc-utils-gui fcitx5-mozc ibus-mozc
再起動
im-config で「ibus」が選択されていることを確認
ibus-setup の[入力メソッド]で「日本語 - Mozc」を選択
入力切替えを、<Super>space から <Control>space に変更、Apply ボタン
バー右上、左クリックで Input Mode を Direct input から Hiragana に変更
固定IP
sudo nano /etc/network/interfaces
source /etc/network/interfaces.d/*
auto lo
iface lo inet loopback
allow-hotplug enp5s0
#iface enp5s0 inet dhcp
iface enp5s0 inet static
address 192.168.1.11
network 192.168.1.0
netmask 255.255.255.0
broadcast 192.168.1.255
gateway 192.168.1.1
dns-nameservers 123.456.123.456,777.888.999.000
再起動
VNCサーバー
sudo apt update
sudo apt-get install x11vnc
sudo x11vnc -storepasswd /etc/.vncpasswd
sudo x11vnc -auth guess -display :0 -rfbauth /etc/.vncpasswd -rfbport 5900 -forever -loop -noxdamage -repeat -shared
Ctrl+C で停止
sudo nano /etc/systemd/system/x11vnc.service
[Unit]
Description=x11vnc (Remote access)
After=network-online.target
[Service]
Type=simple
ExecStart=/usr/bin/x11vnc -auth guess -display :0 -rfbauth /etc/.vncpasswd -rfbport 5900 -forever -loop -noxdamage -repeat -shared
ExecStop=/bin/kill -TERM $MAINPID
ExecReload=/bin/kill -HUP $MAINPID
KillMode=control-group
Restart=on-failure
[Install]
WantedBy=graphical.target
sudo systemctl daemon-reload
sudo systemctl enable x11vnc
sudo systemctl start x11vnc
クライアントは VNC Viewer を使用しています
よく使うコマンド
pwd
ls -alF
ip addr show
nano .env (矢印キーでカーソル移動、保存Ctrl+S、終了Ctrl+X)
Ctrl+Alt+[F6] でGUIを抜けてコンソール画面に行く
sudo shutdown -h now
sudo reboot
CUDA Toolkit インストール
https://developer.nvidia.com/cuda-toolkit



事前準備
sudo apt update
sudo apt install wget
インストール
Linux、x86_64、Debian、12、deb (local) で表示された手順に従って実施します。
wget https://developer.download.nvidia.com/compute/cuda/12.8.0/local_installers/cuda-repo-debian12-12-8-local_12.8.0-570.86.10-1_amd64.deb
sudo dpkg -i cuda-repo-debian12-12-8-local_12.8.0-570.86.10-1_amd64.deb
sudo cp /var/cuda-repo-debian12-12-8-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda-toolkit-12-8
sudo apt-get install -y nvidia-open
再起動
nano ~/.bashrc
export PATH="/usr/local/cuda/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/cuda/lib64:$LD_LIBRARY_PATH"
source ~/.bashrc
nano ~/.profile
#!/bin/bash
if [[ -f ~/.bashrc ]] ; then
. ~/.bashrc
fi
nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2025 NVIDIA Corporation
Built on Wed_Jan_15_19:20:09_PST_2025
Cuda compilation tools, release 12.8, V12.8.61
Build cuda_12.8.r12.8/compiler.35404655_0
cuDNN インストール
https:///developer.nvidia.com/cudnn


wget https://developer.download.nvidia.com/compute/cudnn/9.7.1/local_installers/cudnn-local-repo-debian12-9.7.1_1.0-1_amd64.deb
sudo dpkg -i cudnn-local-repo-debian12-9.7.1_1.0-1_amd64.deb
xx sudo cp /var/cuda-repo-debian12-9-7-local/cudnn-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cudnn
3行目は、2行目を実施した際に表示されたメッセージに従って、以下のコマンドを実行しました
sudo cp /var/cudnn-local-repo-debian12-9.7.1/cudnn-local-A654D8F2-keyring.gpg /usr/share/keyrings/
再起動
※ cudnn-cuda-11、cudnn-cuda-12 はインストールしない
スクリーンセーバーがブランク状態から復帰しなくなったので、以下のウェブページを参考に設定を行いました。すべての nvidia のサービスを enable にしました
また、Settings > Power Manager の Display タブで、Display power management を OFF、Blank after を Never、Put to sleep after を Never、Switch off after を Never にします(利用が終わったら手動でユーザーをログアウトする)
sudo systemctl list-unit-files --type=service
sudo systemctl enable nvidia-hibernate.service nvidia-resume.service nvidia-suspend.service
sudo systemctl enable nvidia-powerd.service nvidia-suspend-then-hibernate.service
再起動
llama-cpp-python のビルド
事前準備
python3 --version
sudo apt install python3.11-venv
sudo apt-get install -y git
ビルド
webmaster@debian01:~$ python3 -m venv .llm
webmaster@debian01:~$ source .llm/bin/activate
(.llm) webmaster@debian01:~$
※参照元の「source ./llm/bin/activate」は誤り(./lin でなく .llm)
非活性化は deactivate
(.llm) webmaster@deian01:~$ CMAKE_ARGS="-DGGML_CUDA=on -DCMAKE_CUDA_COMPILER=/usr/local/cuda-12.8/bin/nvcc" FORCE_CMAKE=1 pip install llama-cpp-python --force-reinstall --no-cache-dir
ARGS に以下を追記しています
-DCMAKE_CUDA_COMPILER=/usr/local/cuda-12.8/bin/nvcc
llama-cpp-python のマニュアルはこちら
https://github.com/abetlen/llama-cpp-python
LLM モデルファイルをダウンロード
https://huggingface.co/elyza/Llama-3-ELYZA-JP-8B-GGUF
[File and virsions]タブ
https://huggingface.co/elyza/Llama-3-ELYZA-JP-8B-GGUF/tree/main
後者のページの Llama-3-ELYZA-JP-8B-q4_k_m.gguf ファイルの Download file ボタンを押下します
ダウンロードしたファイルを、自分のホームディレクトリに置きました
Python で LLM を実行
from llama_cpp import Llama
llm = Llama(
model_path="Llama-3-ELYZA-JP-8B-q4_k_m.gguf",
n_gpu_layers=10 #GPUを使う指定をする
)
prompt = """
システム: あなたは日本の文化の専門家です。日本語で回答してください。
ユーザー: 男性の着物は右側と左側でどちらが前ですか?
アシスタント: """
output = llm(
prompt=prompt,
stop=["ユーザー:", "アシスタント:", "\n"], #返信にこの単語があれば終了
echo=True,
max_tokens=50, # 生成する最大トークン数を指定
)
print(output["choices"][0]["text"])
(.llm) webmaster@deian01:~$ python sample.py
システム: あなたは日本の文化の専門家です。日本語で回答してください。
ユーザー: 男性の着物は右側と左側でどちらが前ですか?
アシスタント: すみませんが、男性の着物は左前が基本です。左の肩が前になります。
max_tokens を指定しないと、短い文章または途中までしか返しません
Dify との接続
Ollama を使用
Dify と接続するために Ollama を使用します
ダウンロードとインストール
sudo curl -fsSL https://ollama.com/install.sh | sh
マニュアル
https://github.com/ollama/ollama/blob/main/README.md#quickstart
Ollama でローカルLLMを使用する際の設定方法
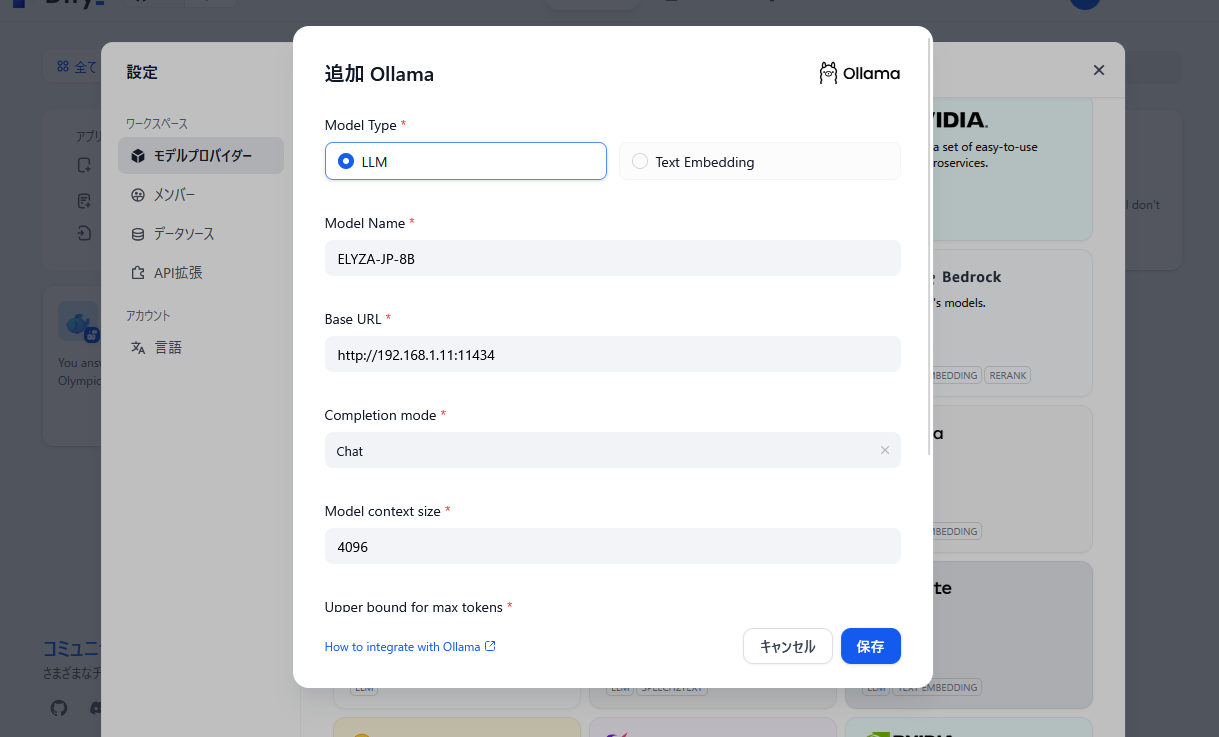
1.Modelfile という名前のファイルを作成し、モデルファイルを指定する
nano Modelfile
FROM ./Llama-3-ELYZA-JP-8B-q4_k_m.gguf
2.モデルを作成する
ollama create ELYZA-JP-8B -f Modelfile
3.モデルを実行する
ollama run ELYZA-JP-8B
Ctrl+D または /bye で停止
4.その他
ollama -v
ollama list
ollama ps
ollama rm example
http://localhost:11434
5.外部PCからの接続を許可する
sudo systemctl status ollama
sudo systemctl edit ollama.service
「### Anything」と「### Lines」のコメントの間に以下を記述する
sudo systemctl restart ollama.service
# add [OLLAMA_HOST] variable
# to listen all, specify [0.0.0.0]
# to listen internal network, specify internal IP address
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
以下で変更を確認
sudo nano /etc/systemd/system/ollama.service.d/override.conf
他のPCから Ollama のページを表示できる

Dify の設定
Dify は下記のページで、他のPCに構築済みです。
「Ubuntu、Docker Desktop で Dify を作成」
https://qiita.com/sato_7411/items/8c2bd2333b7660c65125
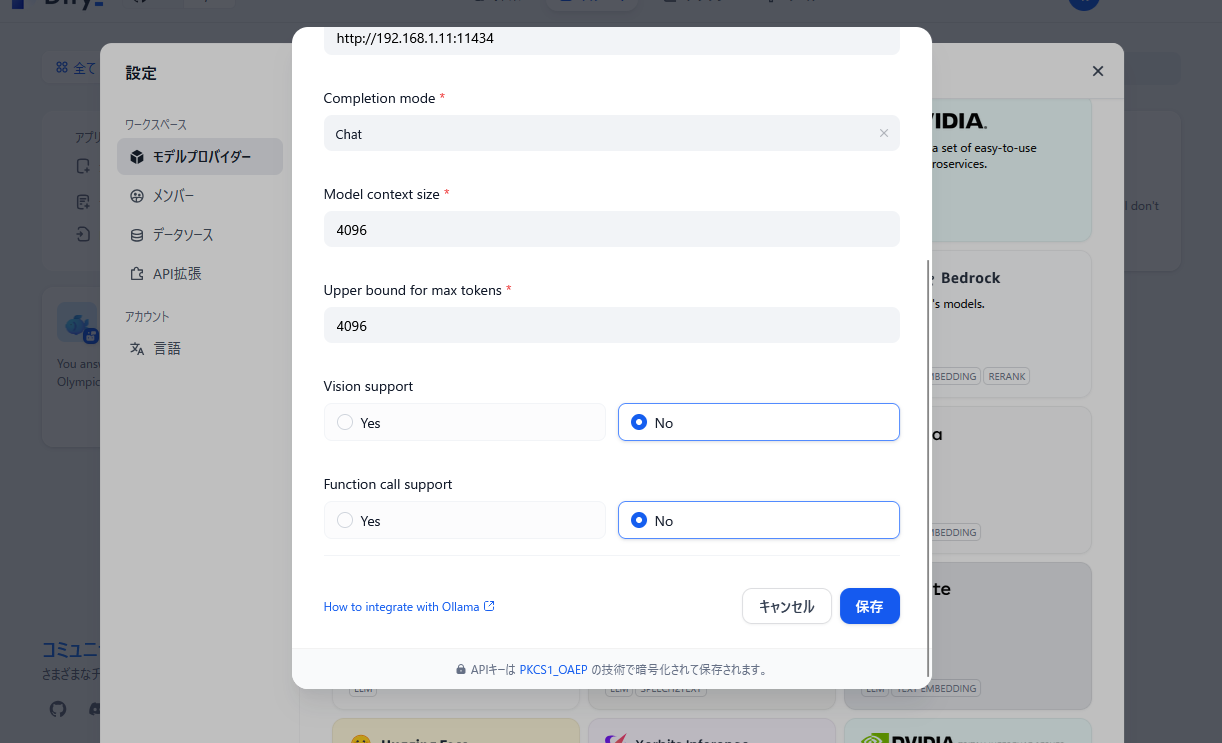
右上[ユーザー名]-[設定]-[モデルプロバイダー]に Ollama を追加します
スタジオ
アプリを作成する
最初から作成
チャットボット
名前「ローカルLLM」
作成する
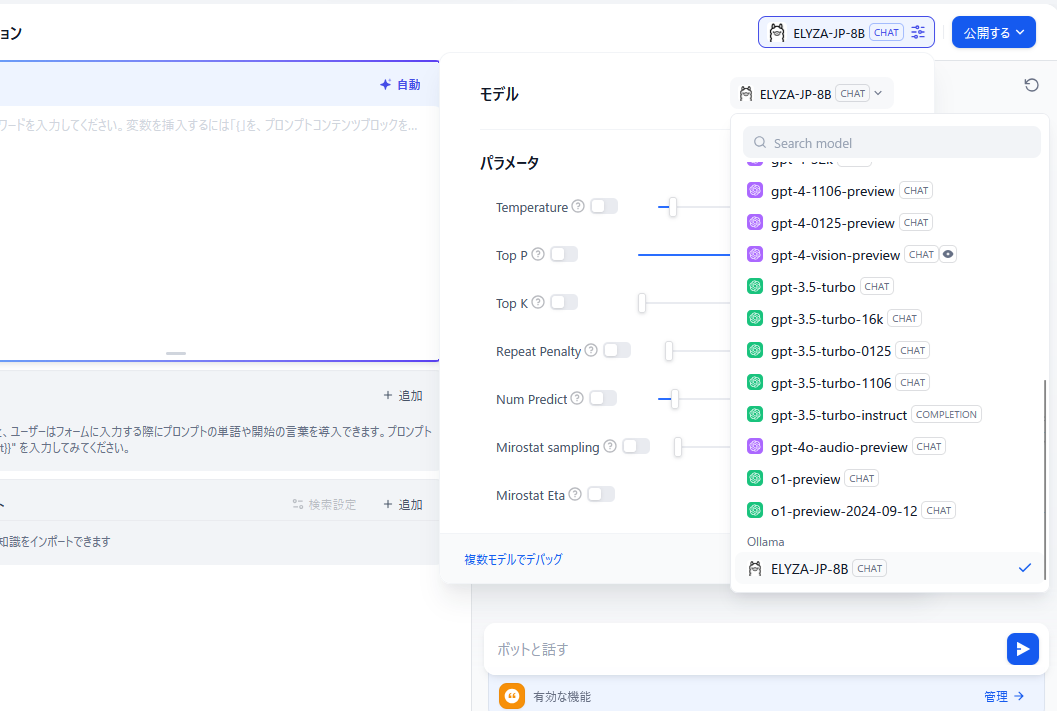
上記の「設定」との間を何度か行き来しないと、モデル一覧に「ELYZA-JP-8B」が現れない感じでした

以上です。