記事概要
RAG環境を課金を気にしなくていいローカル環境で動かせると嬉しいですね。
この記事ではオープンモデルのLlama3.2を使って完全にローカルに完結するGraphRAGのグラフデータベース構築と質問回答のプログラムを作る流れを説明します。
私自身も生成AIを最近学び始めたばかりなので、正確ではない部分があったらコメントで教えてください。
この記事ではWikipediaでハリーポッター(人物)の記事を元に言語モデルを用いてNeo4jにグラフデータベースを構築し、そのデータからハリーポッターに関する質問に答えさせるコードを作成します。
例えば、以下のような応答ができるプログラムを作ります。
質問:ハリー・ポッターはどのような見た目ですか?
答え:ハリー・ポッターは、額に稲妻形の傷があり、母親譲りの明るい緑の目をしています。父親譲りの黒髪で、膝が「がりがり」しています。丸い眼鏡をかけています。

※Llama3.2は日本語の精度があまり高くないため、全て英語でやっています。
この記事で使用したプログラム
記事で使用したプログラムはこちらに置いています。
satken2/local-llama-graphrag - Github
Graph RAGについて
RAG
いまさら説明するものでもないですが、RAG(検索拡張生成AI)というのは言語モデルに外部データベース(ベクトルデータベース)を連携させることで、言語モデルに疑似的に知識を追加する手法のことです。
GraphRAG
GraphRAGは、RAGの考え方にナレッジグラフを組み合わせた技術で、従来のRAGよりも正確で文脈に適した情報生成を可能にしようとする技術です。
これまでのRAGではベクトルデータベースの中からプロンプトに合致しそうなデータを局所的に取得してきて、それをコンテキストとして言語モデルに与えていました。ですがこの方法は元となるデータ全体の文脈をあまり考慮できておらず、結果としてあまり一致度の高くないデータを取得してしまって回答精度の低下に繋がる場合がありました。
これの対策として、Graph RAGではナレッジグラフを活用することで、データ間の関係性や全体の文脈を考慮したコンテキストの取得をすることを試みる技術です。
本記事の環境
Llamaを触り始めたのが最近ですが、このスペックでもLlamaをローカル起動(しかもけっこうスムーズに)できることが驚きでした。時間はかかりますが11Bモデルを動かすこともできました。すごいですね。
生成AIをローカルで動かす際は特にGPU性能が大事になってきます。
- CPU:
Core i5 12400F - メモリ:
DDR4 32GB - GPU :
RTX 3070 (8GB) - OS:
Windows 11 - Python:
3.11.0
使用するソフトウェア
グラフデータベースとしてNeo4jをDockerで起動しています。
メインとなる言語モデルはオープンの言語モデルであるLlama3.2の3BモデルをOllamaで動作させ、LangChainでグラフデータとの連携とかプロンプトの管理をしています。
Llama 3.2 (3B)OllamaNeo4jlangchain
環境とデータの準備
Neo4j
Neo4jはグラフデータベースを構築するためのオープンソースソフトウェアです。
以下のようなcomposeファイルを書いて起動します。
Neo4jのCypherクエリ言語を拡張するライブラリapoc-coreを使用しますので、./neo4jにはapocのjarファイルを入れています。
version: "3.8"
services:
neo4j:
build: ./neo4j
ports:
- "7474:7474"
- "7687:7687"
environment:
NEO4J_AUTH: "neo4j/your_password"
NEO4J_apoc_export_file_enabled: "true"
NEO4J_apoc_import_file_enabled: "true"
NEO4J_apoc_import_file_use__neo4j__config: "true"
NEO4J_dbms_security_procedures_unrestricted: "apoc.*"
volumes:
- ./data:/data
ファイルを用意したら、docker compose up -dで起動しておきましょう。
http://localhost:7474でNeo4jのWebUIが起動しています。
検索対象データ
今回はWikipediaのハリーポッター(人物)の記事をRAGで検索しますので、この記事からテキストをコピーしてharrypotter.txtという名前で保存しておきます。
Harry James Potter is a fictional character in the Harry Potter series of novels by J. K. Rowling. The plot of the seven-book series chronicles .....
Llama3.2 3Bモデルの取得
今回はMeta社が開発してオープンに公開されているLlamaという言語モデルを使用します。
Llamaは1B, 3B, 11B, 90Bの4つのモデルがありますが、今回は軽量な3Bを使用します。より上位のモデルを使えば当然検索精度は上がります。
LlamaはOllamaというオープンの言語モデルをローカルで実行するためのランタイムを使って実行します。事前にインストールが必要ですが方法はここでは省略します。
Ollamaコマンドを使用して、Llama3.2 3Bモデルを事前にローカルに落としておきましょう。
ollama pull llama3.2
RAGの構築
それでは、グラフデータベースを構築するためのプログラムを書いていきます。
Neo4jの初期化とLlama3.2の読み込み
No4jとOllamaはどちらもlangchainを使って以下のように使用することができます。
from langchain_ollama import ChatOllama
from langchain_community.graphs import Neo4jGraph
# Initialize LLM model
llm = ChatOllama(model="llama3.2:1b", temperature=0, format="json")
# Initialize the Neo4j graph
graph = Neo4jGraph()
プログラムの作成
RAGの構築用プログラムgraph_generator.pyを作成していきましょう。
テキストデータの読み込みと分割
最初に準備したWikipediaの記事を読み込んで、RecursiveCharacterTextSplitterを使ってチャンクに分割します。
このテキスト分割は文脈などを考慮せず機械的に切っているだけなので、重要な情報が途中でぶった切られることがあります。
そのようなことを防ぐため、chunk_overlapを設定してチャンクと次のチャンクの範囲をある程度重複させて分割します。
# Load documents from a text file
loader = TextLoader(file_path="harrypotter.txt", encoding = 'UTF-8')
docs = loader.load()
# Split documents into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=250, chunk_overlap=24)
documents = text_splitter.split_documents(documents=docs)
チャンクからグラフデータを作成
まずはLLMGraphTransformerを使ってチャンクに分割したテキストをグラフドキュメントに変換します。ここでは、LLMがテキストからエンティティやその間の関係性を抽出し、構造化されたグラフデータを生成します。
その後、それをNeo4jに保存します。
# Convert documents to graph format
llm_transformer = LLMGraphTransformer(llm=llm, ignore_tool_usage=False)
graph_documents = llm_transformer.convert_to_graph_documents(documents)
# Add documents to the graph
graph.add_graph_documents(
graph_documents,
baseEntityLabel=True,
include_source=True
)
ベクトルインデックスの作成
また、グラフデータだけでなくテキストから作成した埋め込み行列(ベクトルインデックス)も計算し、これもNeo4jに格納します。
ベクトルインデックスの計算にはmxbai-embed-largeという別のモデルを使用しています。
Neo4jVector.from_existing_graphを使用することで、embeddingsに指定したモデルを使用してテキストの埋め込み行列が作成され、グラフデータベースに保存されます。
# Initialize embeddings
embeddings = OllamaEmbeddings(
model="mxbai-embed-large",
)
# Create a vector index from the existing graph
Neo4jVector.from_existing_graph(
embeddings,
search_type="hybrid",
node_label="Document",
text_node_properties=["text"],
embedding_node_property="embedding"
)
フルテキストインデックスの作成
最後に通常の全文検索に使用するインデックス(ベクトルインデックスとは異なります)を作成します。
これは単にNeo4jに接続してCREATE FULLTEXT INDEXを使えばOKです。
# Connect to the Neo4j database and create a full-text index
driver = GraphDatabase.driver(
uri=os.environ["NEO4J_URI"],
auth=(os.environ["NEO4J_USERNAME"], os.environ["NEO4J_PASSWORD"])
)
def create_fulltext_index(tx):
query = '''
CREATE FULLTEXT INDEX `fulltext_entity_id`
FOR (n:__Entity__)
ON EACH [n.id];
'''
tx.run(query)
try:
with driver.session() as session:
session.execute_write(create_fulltext_index)
print("Fulltext index created successfully.")
except Exception as e:
print(f"Failed to create index: {e}")
driver.close()
完成したグラフの確認
上記のコードが実行できたら、http://localhost:7474にアクセスしてグラフの状況を確認してみましょう。
例えば、Harry Potterのノードを確認すると、彼に言及するテキストとして以下のような構造が作られていることが分かります。
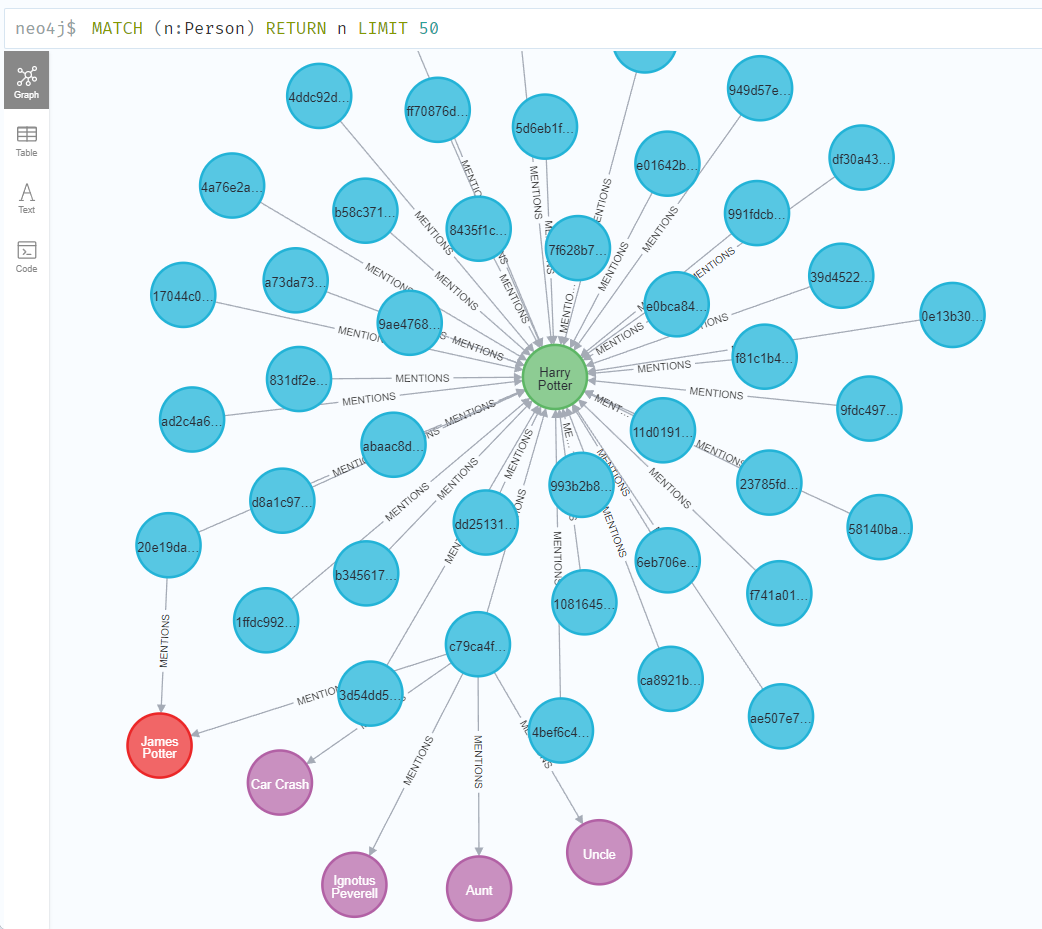
下の方にはハリーの父親であるJames Potterのノードとかも出てきていますね。
RAGを使った質問の回答
検索の流れ
このグラフRAGでは質問に回答するときに以下の3段階でデータを取ってます。
- 質問文に含まれる人名や組織名を抽出し、それに関連するグラフノードを取得する
- 取得したグラフノードでベクトル検索を行い、コンテキストを作る
- 元の質問文に作成したコンテキストを添えて言語モデルに投げ、最終的な回答を得る
例えば、"What does Harry Potter looks like?"という質問をした場合で考えてみると、以下のような流れになります。
1.質問に関連するグラフデータの抽出
質問文から"Harry Potter"という人名が抽出され、"Harry Potter"に言及するグラフノードが取得されます。(上の画像で言う青いノードです。)
2.ベクトル検索による関連情報の抽出
さらに、これはハリーの見た目に関する質問だということを言語モデルが解釈して、1で取得したグラフノードに含まれる文章に対してベクトル検索を行い、見た目に関する言及を抽出してコンテキストとします。
3.最終的な回答の生成
最後に、context_builderが作ったコンテキストと元の質問である"What does Harry Potter looks like?"をつなげてLlamaに投げています。
検索用プログラムの作成
質問文からの人名抽出
まず、ユーザーの質問文からエンティティを抽出するための処理を書きます。
Entitiesクラスを定義し、descriptionに「テキストに出てくる全ての人名・組織名」と定義することで言語モデルに人名と組織名を抽出させるように指定します。
そして、そのEntitiesクラスをllm.with_structured_outputで言語モデルに渡してinvokeすることで質問から人名・組織名を抽出できます。
class Entities(BaseModel):
"""Identifying information about entities."""
names: list[str] = Field(
...,
description="All the person, organization, or business entities that "
"appear in the text",
)
# Create a prompt for extracting entities
prompt = ChatPromptTemplate.from_messages(
[
("system", "You are extracting organization and person entities from the text."),
("human", "Use the given format to extract information from the following input: {question}"),
]
)
dict_schema = convert_to_openai_function(Entities)
entity_chain = prompt | llm.with_structured_output(dict_schema)
entities = entity_chain.invoke({"question": question})
entity_names = eval(entities['names'])
グラフデータ取得
ここは単なるNeo4jの操作となりますが、先ほどリスト形式で取得したエンティティをループさせてNeo4jのクエリを複数回投げます。
# Retrival of related nodes
related_nodes = []
for entity in entity_names:
response = graph.query(
"""
MATCH (n)-[:MENTIONS]->(m)
WHERE m.id = $entity
RETURN n.text AS text, n.embedding AS embedding
""",
{"entity": entity},
)
for record in response:
text = record["text"]
embedding = np.array(record["embedding"])
related_nodes.append((entity, text, embedding))
取得したグラフデータに対するベクトル類似度計算
上の質問で質問に関連する人物に関するグラフノードを取得しましたが、元のデータの量によっては膨大な量のデータが取れるかもしれません。そのため、取得したグラフデータに対して質問文との類似度を計算し、上位いくつかのデータだけをコンテキストとして採用することとします。
まずは質問文の埋め込みベクトルを計算し、cosine_similarityで各グラフデータとの類似度を計算しています。
上位いくつかのデータを並べて、#Documentというタグをつけておきます。
# Create embeddings from question
question_embedding = embeddings.embed_query(question)
# Calculation and sorting of cosine similarity
def cosine_similarity(vec1, vec2):
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
related_nodes.sort(
key=lambda x: cosine_similarity(question_embedding, x[2]),
reverse=True
)
top_related_texts = [node[0] for node in related_nodes[:top_n]]
graph_context = ""
for node in related_nodes[:top_n]:
graph_context += f"#Document\nExplanation about '{node[0]}' - '{node[1]}'\n\n"
通常のベクトル検索も行う
グラフデータの検索だけでなく通常のRAG検索であるベクトル検索も行います。
Neo4jVector.from_existing_indexを使用してグラフデータを取得するためのリトリーバーを取得してから、それを使って検索を実行します。
これも#Documentというタグをつけてテキストに整形します。
# Retrieve the vector retriever
vector_index = Neo4jVector.from_existing_index(
embeddings,
search_type="hybrid",
index_name="Document_embedding",
keyword_index_name="Document_keyword",
node_label="Document",
text_node_property="text",
embedding_node_property="embedding"
)
vector_retriever = vector_index.as_retriever()
# Execute vector search
vector_data = [el.page_content for el in vector_retriever.invoke(question)]
vector_context = ""
for text in vector_data[:top_n]:
vector_context += f"#Document\nAdditional information - '{text}'\n\n"
コンテキストの作成と言語モデルの実行
コンテキストができたので、あとはこれをLlamaに渡すだけです。
このコード例ではgraph_retrieverとvector_retriverが上記のコンテキスト作成プログラムになっています。
プロンプトやchainの作成などはLangChainの基本的な使い方の話なのでここでは割愛します。
def context_builder(question: str) -> str:
graph_data = graph_retriever(question)
vector_data = vector_retriver(question)
return f"""
Context from graph data:
{graph_data}
Context from vector data:
{vector_data}
"""
# Create a prompt template for the final answer
template = """Answer the question based only on the following context:
{context}
Question: {question}
Use natural language and be concise.
Answer:"""
prompt = ChatPromptTemplate.from_template(template)
# Set up the final chain
chain = (
{
"context": context_builder,
"question": lambda x: x,
}
| prompt
| llm
| StrOutputParser()
)
input_question = input("Question: ")
result = chain.invoke(question)
print("Answer:", result)
質問を投げる
完成したら、以下のようなプロンプトを投げてみます。
Where did Dumbledore and Harry entered in search of a Horcrux?
取得されているグラフデータの確認
graph_dataをログに出力してみると、HarryとDumbledoreが人名として解釈され、2人に言及するグラフデータが取得されてコンテキストとして整形されています。
Context from graph data:
#Document
Explanation about 'Dumbledore' - 'Near the end of the book, Dumbledore and Harry enter a cave in search of a Horcrux. Dumbledore drinks a potion inside the Horcrux's container and begins to scream in agony. When Harry attempts to retrieve some lake water for Dumbledore to drink, he'
#Document
Explanation about 'Harry' - 'Near the end of the book, Dumbledore and Harry enter a cave in search of a Horcrux. Dumbledore drinks a potion inside the Horcrux's container and begins to scream in agony. When Harry attempts to retrieve some lake water for Dumbledore to drink, he'
#Document
Explanation about 'Dumbledore' - 'Harry awakens in the Hogwarts infirmary, where Dumbledore explains that Harry was protected by his mother's love, which also killed Quirrell. Voldemort survived, and the Philosopher's Stone was destroyed. During the school's end-of-year feast,'
#Document
Explanation about 'Harry' - 'Hagrid takes Harry to Diagon Alley to shop for school supplies. Harry buys a wand, and the proprietor tells him that his wand and Voldemort's wand contain feathers from the same phoenix. At the end of the summer, Harry boards the Hogwarts Express,'
#Document
Explanation about 'Dumbledore' - 'that both wands contain as their cores both comes from Fawkes, the phoenix that Dumbledore keeps as a pet in his office until his death in Half-Blood Prince.[26] Harry's wand is broken in Deathly Hallows. For a time, he borrows Hermione's wand, and'
ベクトル検索データの確認
ベクトル検索から得られたコンテキストも確認します。
だいたい同じようなデータが取得されていますね。
Context from vector data:
#Document
Additional information - 'Near the end of the book, Dumbledore and Harry enter a cave in search of a Horcrux. Dumbledore drinks a potion inside the Horcrux's container and begins to scream in agony. When Harry attempts to retrieve some lake water for Dumbledore to drink, he'
#Document
Additional information - 'Dumbledore to drink, he is attacked by Inferi. They try to drown Harry, but Dumbledore rescues him. Dumbledore and Harry then return to the Hogwarts Astronomy Tower with the Horcrux. Dumbledore asks Harry not to interfere in the events that are'
#Document
Additional information - 'Harry, Ron, and Hermione leave Hogwarts in Harry Potter and the Deathly Hallows (2007) to search for and demolish Voldemort's four remaining Horcruxes. They must be destroyed with basilisk venom, the Sword of Gryffindor, or some other powerful'
#Document
Additional information - 'or some other powerful means. Ron, Hermione, Vincent Crabbe and Neville Longbottom each destroy one of these Horcruxes. After a battle at Hogwarts, Harry goes into the Forbidden Forest to meet Voldemort, who uses the Elder Wand to cast the Killing'
最終的な質問文
ChatPromptTemplateに渡しているテンプレートの内容と合わさって、最終的にLlamaには以下のような質問が投げられます。
Answer the question based only on the following context:
Context from graph data:
#Document
Explanation about 'Dumbledore' - 'Near the end of the book, Dumbledore and Harry enter a cave in search of a Horcrux. Dumbledore drinks a potion inside the Horcrux's container and begins to scream in agony. When Harry attempts to retrieve some lake water for Dumbledore to drink, he'
#Document
Explanation about 'Harry' - 'Near the end of the book, Dumbledore and Harry enter a cave in search of a Horcrux. Dumbledore drinks a potion inside the Horcrux's container and begins to scream in agony. When Harry attempts to retrieve some lake water for Dumbledore to drink, he'
#Document
Explanation about 'Dumbledore' - 'Harry awakens in the Hogwarts infirmary, where Dumbledore explains that Harry was protected by his mother's love, which also killed Quirrell. Voldemort survived, and the Philosopher's Stone was destroyed. During the school's end-of-year feast,'
#Document
Explanation about 'Harry' - 'Hagrid takes Harry to Diagon Alley to shop for school supplies. Harry buys a wand, and the proprietor tells him that his wand and Voldemort's wand contain feathers from the same phoenix. At the end of the summer, Harry boards the Hogwarts Express,'
#Document
Explanation about 'Dumbledore' - 'that both wands contain as their cores both comes from Fawkes, the phoenix that Dumbledore keeps as a pet in his office until his death in Half-Blood Prince.[26] Harry's wand is broken in Deathly Hallows. For a time, he borrows Hermione's wand, and'
Context from vector data:
#Document
Additional information - 'Near the end of the book, Dumbledore and Harry enter a cave in search of a Horcrux. Dumbledore drinks a potion inside the Horcrux's container and begins to scream in agony. When Harry attempts to retrieve some lake water for Dumbledore to drink, he'
#Document
Additional information - 'Dumbledore to drink, he is attacked by Inferi. They try to drown Harry, but Dumbledore rescues him. Dumbledore and Harry then return to the Hogwarts Astronomy Tower with the Horcrux. Dumbledore asks Harry not to interfere in the events that are'
#Document
Additional information - 'Harry, Ron, and Hermione leave Hogwarts in Harry Potter and the Deathly Hallows (2007) to search for and demolish Voldemort's four remaining Horcruxes. They must be destroyed with basilisk venom, the Sword of Gryffindor, or some other powerful'
#Document
Additional information - 'or some other powerful means. Ron, Hermione, Vincent Crabbe and Neville Longbottom each destroy one of these Horcruxes. After a battle at Hogwarts, Harry goes into the Forbidden Forest to meet Voldemort, who uses the Elder Wand to cast the Killing'
Question: Where did Dumbledore and Harry entered in search of a Horcrux?
Use natural language and be concise.
Answer:
これだけ事前情報が与えられれば、パラメータ数の少ないLlama3.2 3Bでも正確な回答ができます。回答は以下のようになりました。
A cave.
今後の改善点など
- グラフデータを取得する時に表記ゆれに弱い気がする。質問文に
Harry Potterと書くかHarryと書くかで精度が変わってしまう。 - グラフデータをベクトル類似度でソートしたが、うまく類似度でソートできているのか若干怪しい。
- ベクトルインデックスやグラフの作成に使う言語モデルと質問に使う言語モデルのパラメータ数を変えて精度がどうなるのかを見てみたい