事の発端
ある用途でPCの画面を長時間キャプチャしていたのですが、保存先をFAT32のドライブにしてしまったために動画がファイルサイズ上限の4GBに達してしまいました。
メタ情報が壊れてしまったため、動画ファイルは一切再生できない3.99GBのゴミファイルと化しました。
再生しようとしてもプレイヤーを開いた瞬間にエラーが出てしまいます。
結論から言うと、尻切れトンボになった動画を復活させることはできなかったのですが、なぜ復活できないのかをMP4ファイルの構造とともに解説します。
MP4ファイルの中身
動画ファイルに含まれるデータの種類
ひとくちに動画ファイルといっても、動画ファイルの中には色んなデータが含まれています。
主なものだと以下のような情報でしょうか。
- 画像データ
- 音声データ
- 字幕データ
音声データの中にも主音声と副音声があったり、字幕も複数言語が含まれていたりしますね。
市販のDVDでメニューが表示できるものだとそれ用のTOC情報が含まれているでしょうし、最近流行りのVR動画とかだとまた何か別の情報が含まれているんですかね。よく知らないですけど。
形式の違う色んなデータを一つのファイルに含め、各情報へのランダムアクセスを可能にるために考案されたのがMP4ファイルというわけです。
MP4のBOX構造
実際にはMP4ファイルはBOXと呼ばれるひとかたまりのデータの木構造の形式でデータを記録しています。
BOXは直接データを含むこともできますし、別のBOXを子要素として含むこともできます。
BOXのことをatomと呼ぶ場合があるのはQuick Time時代の名残です。
最初の4バイトが子要素も含めたBOX全体の長さ、次の4バイトはBOXの種類を示す4文字のアルファベット、それ以降はBOXの中身です。
子要素を持たない場合(leaf box)
子要素を持たないBOXはleafと呼びます。
実際のデータを持てるのはleaf boxのみです。
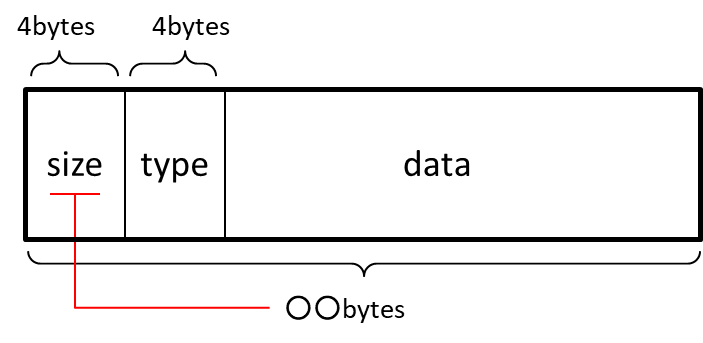
子要素を持つ場合
このように子要素を含むこともできます。
子要素を持つ場合、親要素はデータを持てません。
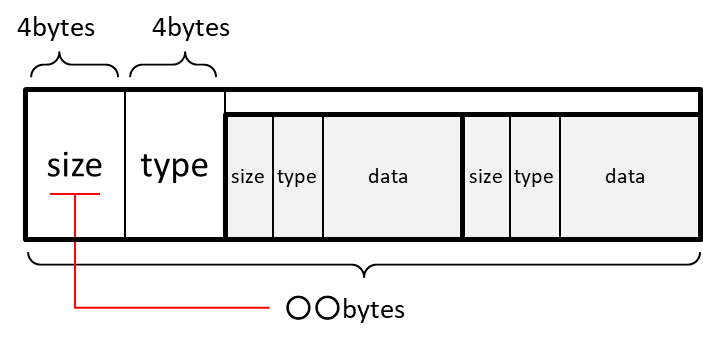
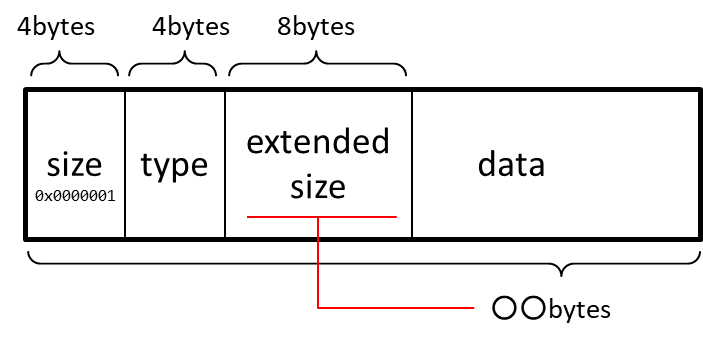
BOXの長さが4294967296バイト超の場合
BOXの長さの情報が2^32バイト(=4294967296)を超える場合、最初の4バイトには0x00000001が格納され1、その変わりに9バイト~16バイトに実際のBOXの長さが書かれます。
解析結果サンプル
まず、メタ情報が壊れていない普通のMP4ファイルの構造を調べてみました。
キャプチャソフト: GeForce Experience(Windows)
キャプチャ時間: 0.5秒ぐらい
インデントは親子関係を示しています。
一番左はBOXのインデックス、その右はBOXの種類、その右は内容のバイト数です。
バイト数が書かれていないのは内容を持たない親要素です。
index: name - bytes
01: ftyp - 24
02: mdat - 239668
03: moov
04: mvhd - 108
05: trak
06: tkhd - 92
07: mdia
08: mdhd - 32
09: hdlr - 44
10: minf
11: vmhd - 20
12: dinf - 36
13: stbl
14: stsd - 168
15: stts - 32
16: stss - 20
17: stsz - 48
18: stsc - 28
19: co64 - 24
20: trak
21: tkhd - 92
22: mdia
23: mdhd - 32
24: hdlr - 44
25: minf
26: smhd - 16
27: dinf - 36
28: stbl
29: stsd - 91
30: stts - 32
31: stsz - 28
32: stsc - 28
33: co64 - 24
34: udta - 30
35: udta - 295
まず、最初にファイルタイプを示すftypが来ます。これは必ず最初です。
その後に続く各コンテナの意味は後で解説しますが、重要なのは最初の方にmdatがあり、その後にmoovが続いているということです。
mdatが動画と音声の本体で、moovはメタ情報です。moov内の1つめのtrakが動画のメタ情報、2つめのtrakは音声のメタ情報です。
このキャプチャソフトは動画データ本体の後にメタ情報を書き込んでいるようです。
主なBOXの種類
全部解説しているときりがないですが、主なBOXの種類を解説します。
全量はQuickTime File Format Specification - Movie Atomsにあるので、もっと知りたい人は読んでみてください。
ftyp
File typeのことで、その名の通りどのような形式のファイルなのかやバージョンの情報が書かれています。
かなり古いページですが、Complete List of all known MP4 / QuickTime 'ftyp' designationsに形式のリストがあります。公式情報かはわかりません。
mdat
肝心の動画や音声データ本体。
中身の構造はコーデックによって変わります。
moov
動画のメタデータを格納しているBOX達の親コンテナです。
この下にmvhdやtrakが格納されます。
stbl
Sample Tableです。
MP4はメディアデータをサンプルという形式で記録します。(画質を表す時にサンプリングレートとか言いますよね)
また、複数のサンプルを集めたものをチャンクと呼びます。
QuickTime File Format Specification - Sample Atomsから引用

それぞれのチャンクやサンプルがどれだけの長さを持つか2を示しているのがSample Tableです。
実際のデータはこのBOXの子要素に複数に分けられて記録されています。
実際に中身を読み解きたい場合はQuickTime File Format Specification - Sample Atomsを参照してください。
ファイルの末端が破損した場合
今回再生できなくなった動画のコンテナ構成を見てみると、以下のようになっていました。
index: name - bytes
01: ftyp - 24
02: mdat - 5206156371
mdatがファイルのほとんどを占めていて、メタ情報が全くありません。
各コンテナの順は特に決められていないのでmdatの前にメタ情報がある場合もありますが、今回の形式の場合はメタ情報がファイル末尾に来る形式だったようで、録画中に上限の4GBに達したためにメタ情報の書き込みに失敗したと思われます。
おそらく、動画キャプチャの場合はユーザーが録画停止ボタンを押すまで動画の長さが確定しないので、メタ情報を末尾に書いた方が効率がいいのでしょう。
逆に、ストリーミング配信なんかする場合はメタ情報を最初に書いておくことで、ファイルを全て読み込まずとも動画の長さなどの情報が得られますね。
Youtubeを見るときを思い出してもらうとわかると思いますが、動画を最後まで読み込まなくても再生を始めることができます。
修復を試みる
今回再生できなくなった動画の修復を試みました。
乱暴なやり方ですが、バイナリエディタを使って以下のように他の動画のメタ情報をくっつけることで修復を試みました。
-
mdatの末尾を数MB削る - 新しい
mdatの長さをコンテナの先頭に書く - ファイル末尾に正常に録画できた動画のメタ情報をくっつける
再生したところ、こうなりました。
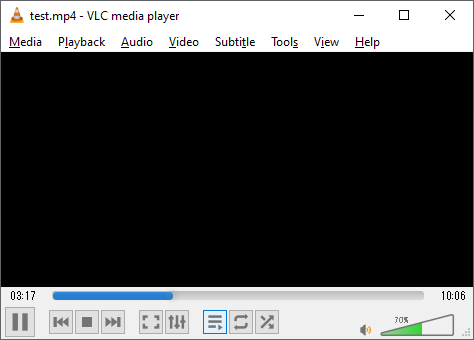
くっつけた動画の長さが表示されて再生時間も順調に進んでいます。
最初は再生時間すら表示されなかったので少し改善しましたが、相変わらず画面は真っ黒のままです。
先ほど説明したように、stbl配下の情報を元にmdatのチャンクやサンプルを取得するので、stblがなければ長いmdatはどこで区切って読めばいいのか全くわかりません。
このように他の動画のstblを無理やりくっつけた場合、stblに書かれている情報と実際のmdatのチャンクが一致しなかったため、デコードに失敗したと思われます。
なので、stblが失われた動画ファイルは復活させることができないわけです。
(参考)コンテナ構造を解析するスクリプト
上記サンプルでは、以下のような簡易スクリプトでファイル構造を調べています。
WindowsだとMP4 Readerというソフトがあるらしいことを後から発見しました。車輪の再発明というやつですね。
まあでもせっかく書いたので、一応載せておきます。
# 使用方法
# $ python mp4_descripter.py [引数1] [引数2]
#
# 引数1: ファイル名
# 引数2: 内容を表示したいコンテナのインデックス
import sys
import binascii
leaf_list = ['fiel', 'mdat', 'rdrf', 'rmcd', 'rmcs', 'rmdr', 'rmqu', 'rmvc', 'wfex', 'cmvd', 'co64', 'dcom', 'elst', 'gmhd', 'hdlr', 'mdhd', 'smhd', 'stco', 'stsc', 'stsd', 'stss', 'stsz', 'stts', 'tkhd', 'vmhd']
parent_list = ['cmov', 'ctts', 'edts', 'esds', 'free', 'ftyp', 'iods', 'junk', 'mdia', 'minf', 'moov', 'mvhd', 'pict', 'pnot', 'rmda', 'rmra', 'skip', 'stbl', 'trak', 'uuid', 'wide']
def read_container(file, indent, index, end_offset, content_index):
# read container size
data = file.read(4)
size = int.from_bytes(data, byteorder='big')
if size == 0: return 0
# read container type
data = file.read(4)
type = data.decode("utf-8")
is_leaf = (type in leaf_list)
end = file.tell() + size - 8
# when container size exceeds 2147483647
if size == 1:
file_pos = file.tell()
data = file.read(8)
size = int.from_bytes(data, byteorder='big')
file.seek(file_pos, 0)
if not is_leaf:
file_pos = file.tell()
file.seek(4, 1)
next_type = ''
try:
next_type = file.read(4).decode("utf-8")
except Exception:
next_type = 'unknown box name'
file.seek(file_pos, 0)
# unknown box is assumed as leaf
if next_type not in leaf_list and next_type not in parent_list:
is_leaf = True
# make index string
if index < 10:
out_text = '0' + str(index) + ': '
else:
out_text = str(index) + ': '
for i in range(indent): out_text += ' '
if is_leaf:
out_text += type
out_text += ' - '
out_text += str(size)
print(out_text)
if index == int(content_index):
# print binary data
print('')
print('offset:' + str(hex(file.tell() - 8)))
data = file.read(size - 8)
strarray = str(binascii.hexlify(data))[2:-1]
outstr = ''
for i in range(int(len(strarray) / 2)):
if i % 8 == 0:
outstr = outstr + ' '
if i % 16 == 0:
print(outstr)
outstr = ''
temp = strarray[i*2:i*2+2]
outstr = outstr + temp + ' '
print(outstr)
print('')
else:
# move to next container
file.seek(size - 8, 1)
return index + 1
else:
out_text += type
print(out_text)
if index == int(content_index):
print('')
print('offset:' + str(hex(file.tell() - 8)))
print('no data')
print('')
index += 1
while True:
# move to children
index = read_container(file, indent + 1, index, end, content_index)
if file.tell() == end: break
return index
if __name__ == '__main__':
file = open(sys.argv[1],'r+b')
try:
content_index = sys.argv[2]
except Exception:
content_index = 0
index = 1
while True:
index = read_container(file, 1, index, -1, content_index)
# read_container returns zero when EOF
if index == 0: break
file.close()
# move to next container
file.seek(size - 8, 1)
return index + 1
else:
out_text += type
print(out_text)
if index == int(sys.argv[2]):
print('')
print('offset:' + str(hex(file.tell() - 8)))
print('no data')
print('')
index += 1
while True:
# move to children
index = read_container(file, indent + 1, index, end)
if file.tell() == end: break
return index
if __name__ == '__main__':
file = open(sys.argv[1],'r+b')
index = 1
index = read_container(file, 1, index, -1)
index = read_container(file, 1, index, -1)
file.close()
参考URL
QuickTime File Format Specification - Movie Atoms
ごちうさMADで学びたいmp4のデータ構造
Complete List of all known MP4
MP4コンテナの中身を調べる