1. はじめに
仕事でAmazon OpenSearch Serverlessの導入プロジェクトを担当したので、せっかくなら理解したことや気づきをアウトプットしようと思い筆を取りました。
また、ElasticSearchやOpenSearch Serviceについての記事は沢山検索されるが、OpenSearch Serverlessについてはあまり検索できず、検索できたとしてもOpenSearchを理解していることが前提の内容ばかりで筆者を含む初心者にはハードルが高く感じたことも理由の一つです。
実装前の筆者の知識は「名前くらいは聞いたことがある」程度です。
2. システム課題
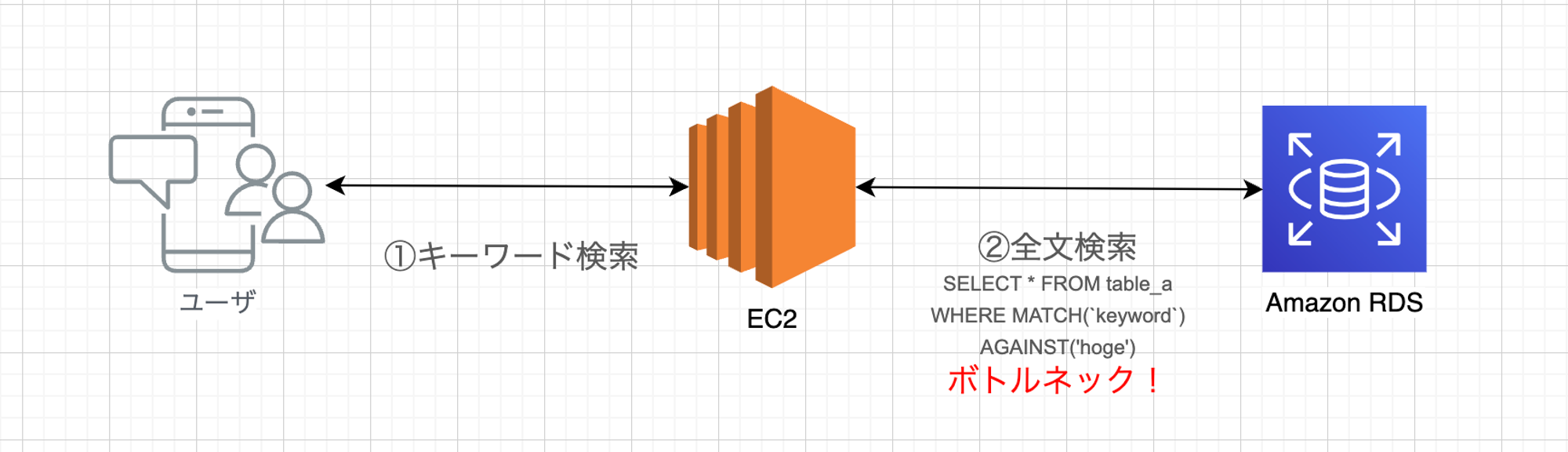
システム内には文字列でのキーワード検索機能があり、旧来MySQLのFULL TEXT INDEXで全文検索処理を行っていました。しかし、レコード数が大量(1億以上)になり結果が返却されないことがしばしば発生していました。
OpenSearchにはその処理を代替し、スムーズに返却されることを期待して導入しました。
3. Amazon OpenSearch Serverlessとは
AWSにはもともと「Amazon OpenSearch Service」とよばれるOpenSearchのマネージドサービスがあります。それをサーバレスとしたものが「Amazon OpenSearch Serverless」です。
3.1. コンセプト
公式にて
OpenSearch クラスターを設定、管理、およびスケーリングすることなく、ペタバイト規模のワークロードを実行できます。
とある通り、敷居が高い領域をAWSに任せられ、開発者はアプリケーションに注力できる点がとても良いと思いました。
今回も例に漏れずOpenSearch Serviceも検討にあがりました。が、やはりシャード数の選択やインスタンスサイズ選定などのドメインのサイジングについて「理解が不足している」「学習時間がない」「運用面での不安」などの課題に対してチーム単体での解決が難しく見送った経緯がありました。
4. 導入手順
ここでは導入までの大まかな流れをご説明します。
今回は以下の手順で導入しました。
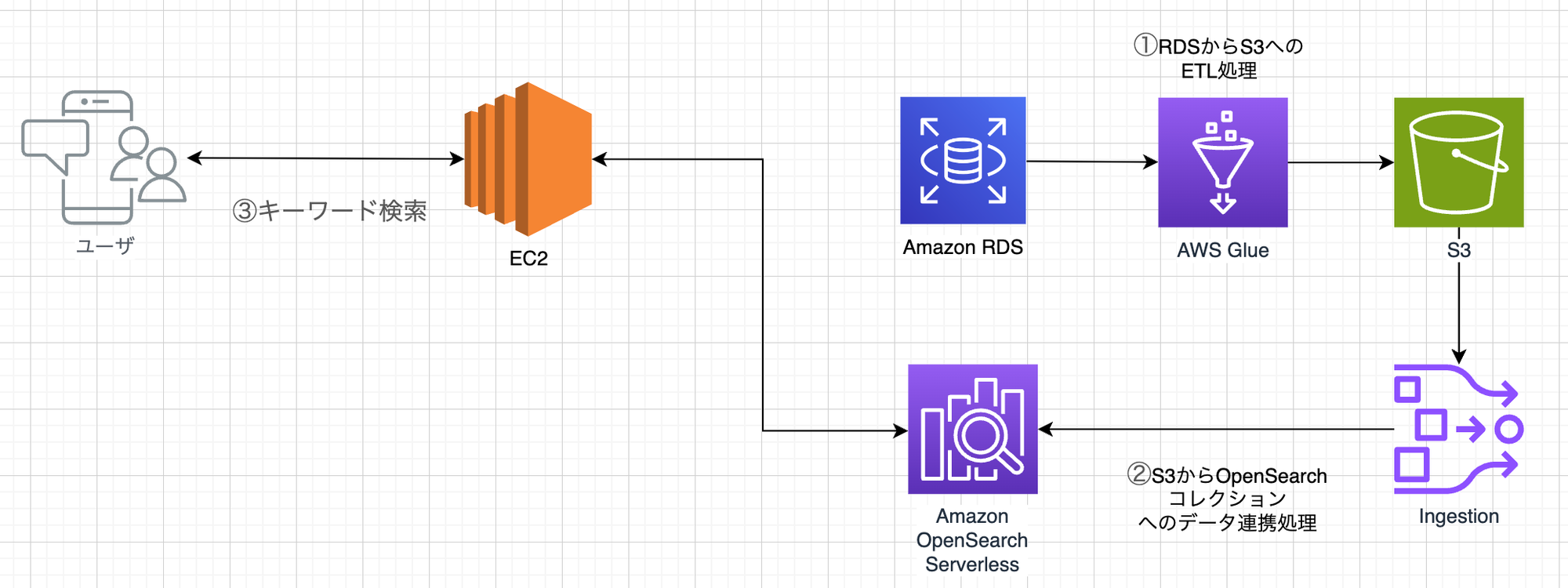
OpenSearchの作成の他にも、データを連携するための処理も作成します。
以下では作成方法は紹介せず大きく理解しておくべき点、注意するべき点のみご紹介します。
- OpenSearchコレクションの作成
- RDSからS3へのETL処理の作成
- S3からOpenSearchコレクションへのデータ連携処理の作成
4.1. 全体図
4. 2. OpenSearchコレクションの作成
OpenSearch Serverlessの管理の最上単位を「コレクション」と呼び、まずはこのコレクションを作成する必要があります。
作成時に考慮する点としては以下があります。
- コレクションタイプ
- デプロイタイプ
- セキュリティ
4.2.1. コレクションタイプ
執筆時点では「時系列」「検索」「ベクトル検索」の3つがあります。
今回のシステム課題のように、全文検索を行いたい場合は「検索」を選択します。

4.2.2. デプロイタイプ
アクティブレプリカの有効化を選択できます。
有効化すると他の作成時に他アベイラビリティゾーンでスタンバイノードも起動し、高可用な状態が実現できます。一方でコストにダイレクトアタックされるので注意が必要です。(詳細は注意点セクションで後述)

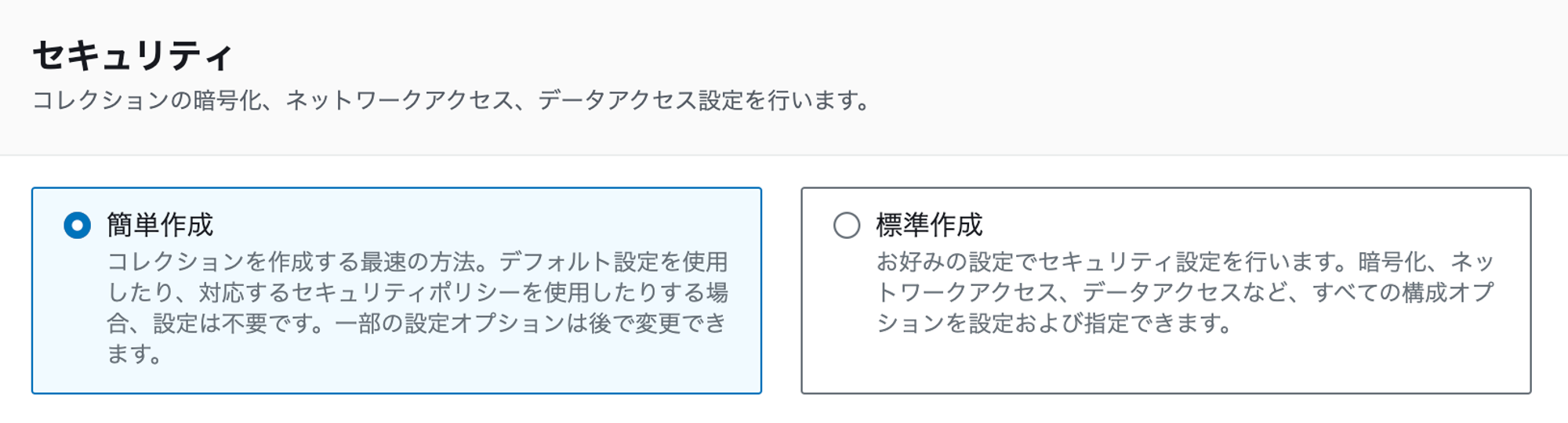
4.2.3. セキュリティ
動作確認やベータ版として作成したい場合は「簡単作成」で選択します。その場合はアクセスが「パブリック」となり、エンドポイントが漏洩すると誰でもアクセス可能となります。
VPC内で通信させるなどのよりセキュアな環境を構築したい場合は「標準作成」を選択します。
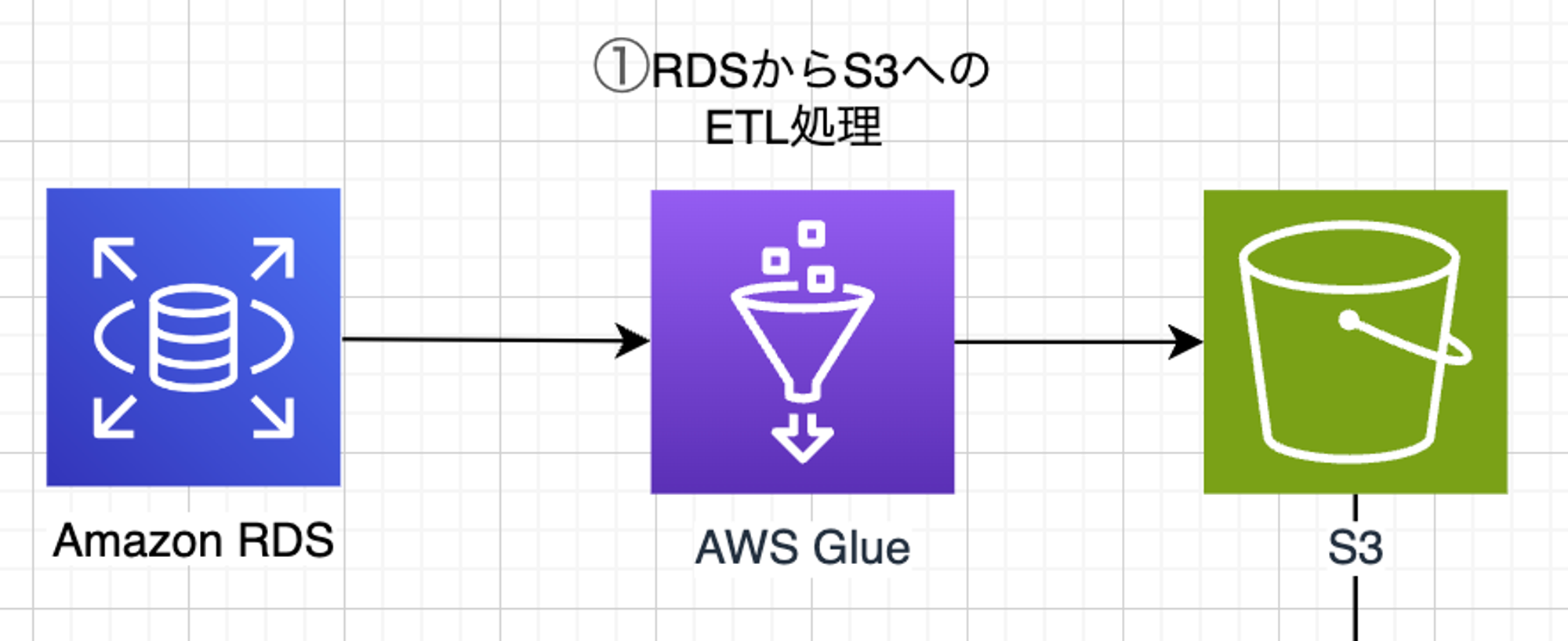
4.3. RDSからS3へのETL処理の作成
AWS Glueというサービスを利用してRDSのデータをS3に出力します。
本来はRDSからOpenSearch Serverlessに対して直接出力したかったのですが、AWS Glueのデータソースに指定できなかったため、一度S3に出力しています。
※OpenSearch Serviceはデータソースに指定できます。
4.3.1. AWS Glueとは
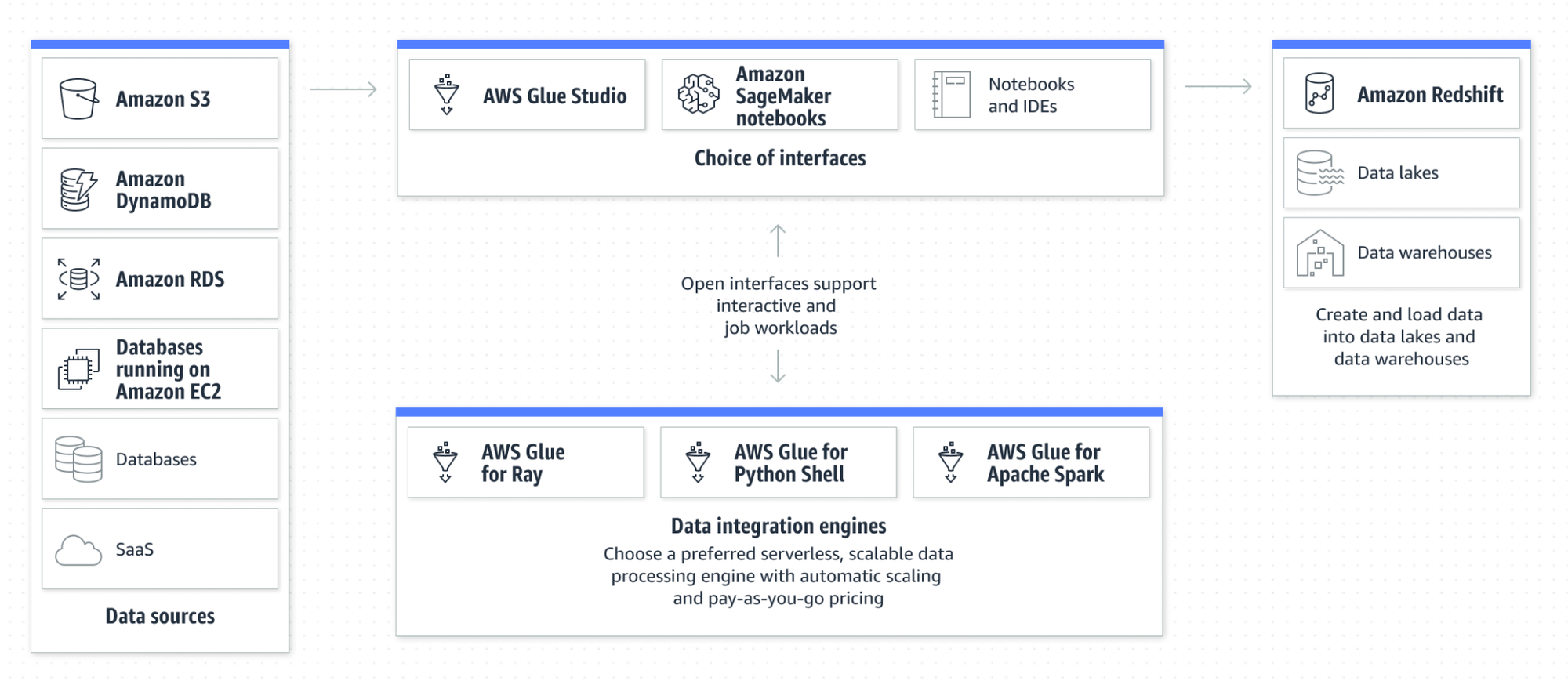
データ統合サービスで、データソースのデータをデータターゲットにETL処理(抽出、変換、読み込み・出力)が簡単にできます。
サーバレスのため、単一障害点になるリスクがありません。
内部ではApache Sparkが動作していますがAWS Glue Studioの「ビジュアルジョブエディター」というノーコードツールを利用することによりコードを書かずとも目的が達成できます。
4.3.2. データソース、データターゲット
RDSのような抽出元をデータソース、S3のような出力先をデータターゲットと呼びます。
データソースはRDS以外にも各種AWSサービス、JDBC接続接可能なデータベースなどと接続可能です。
データターゲットもOpenSearch以外にもRedshiftや各種データウェアハウスなどに出力可能です。
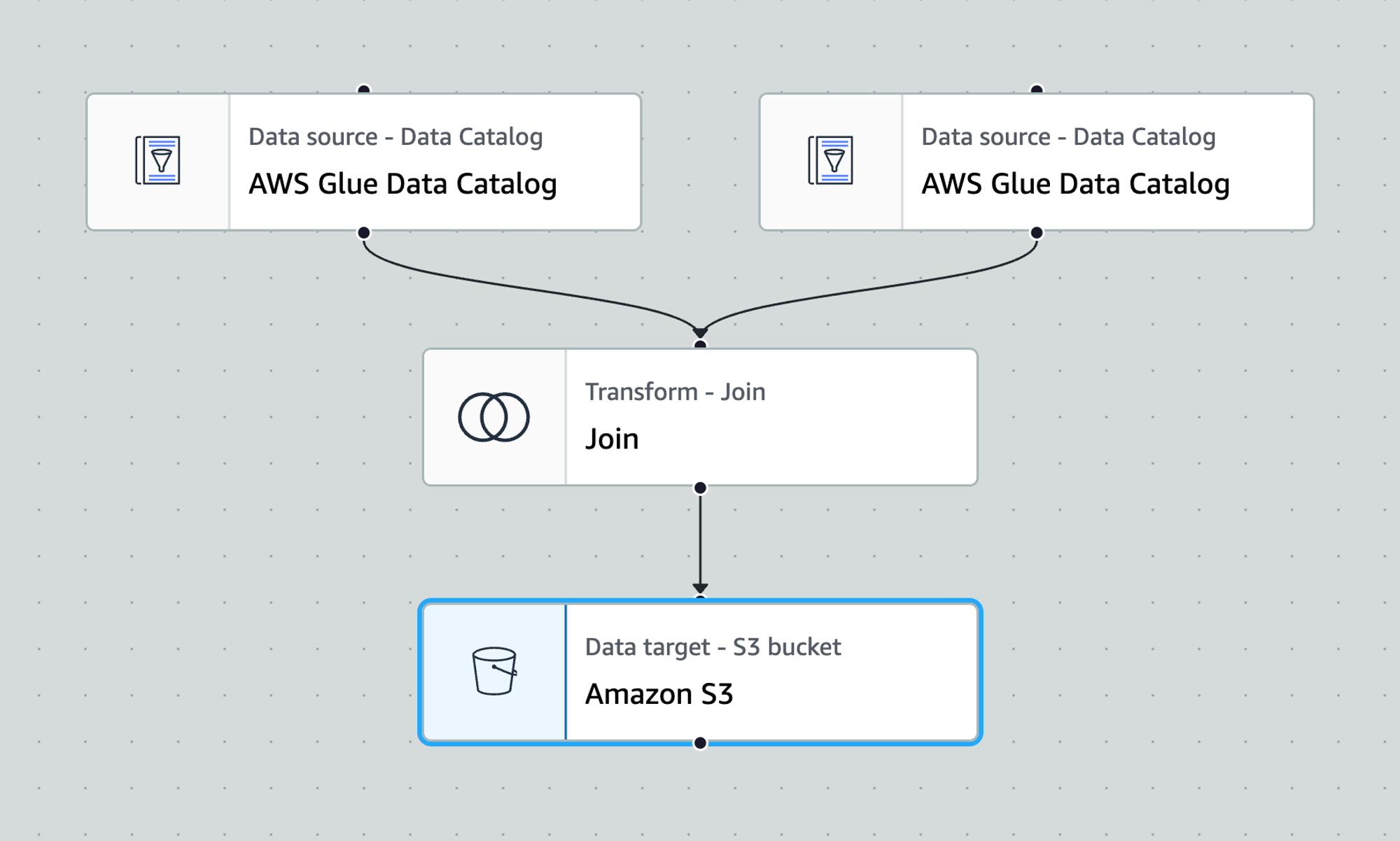
4.3.3. ビジュアルジョブエディター
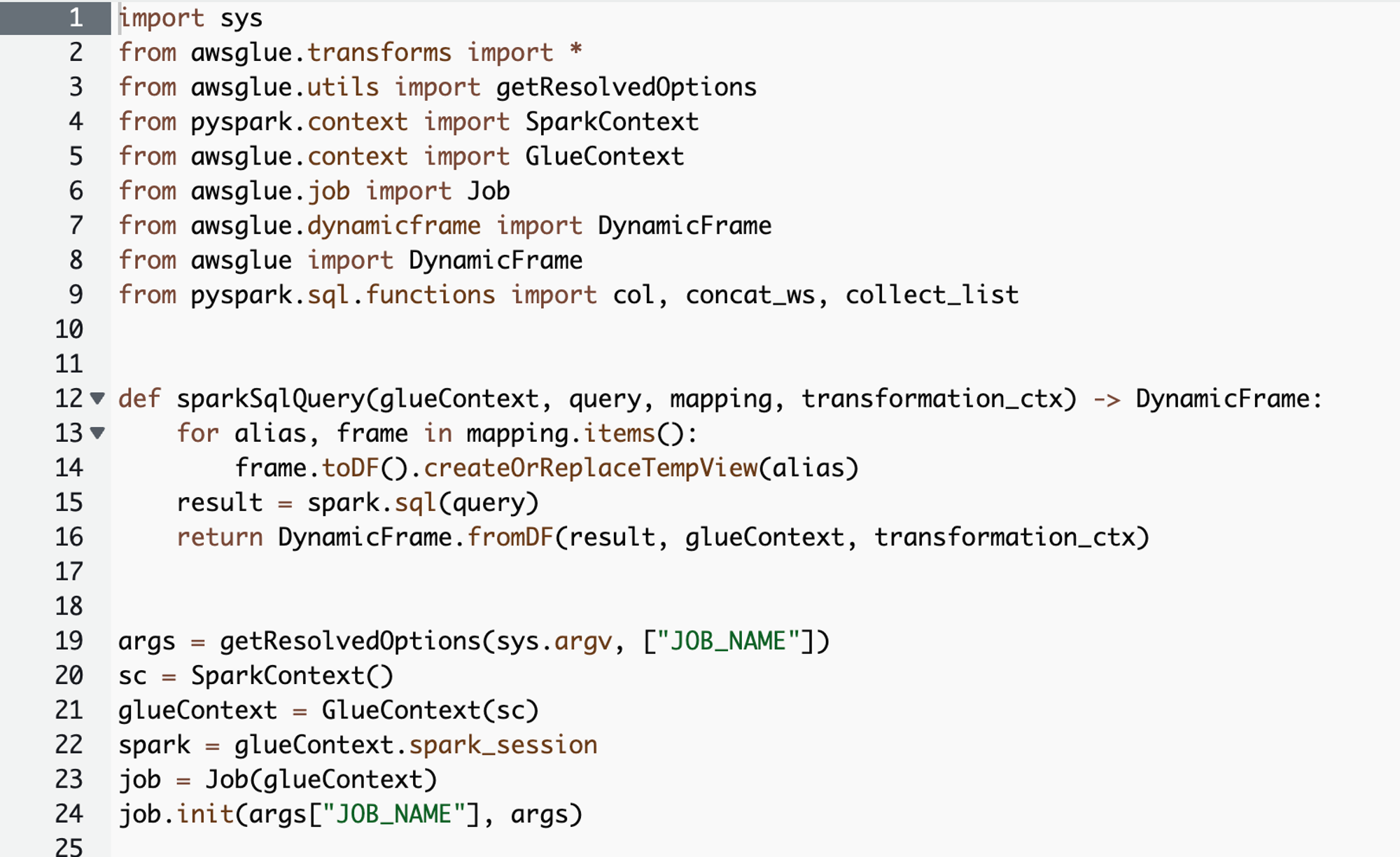
データソースからデータターゲットまでのELT処理をビジュアルで組み立てることができます。
ここで組み立てた処理はPythonコードとしても出力され、編集することもできます。
4.4. S3からOpenSearchコレクションへのデータ連携処理の作成
Amazon OpenSearch Ingestionというサービスを利用してS3のデータをOpenSearchに出力します。
OpenSearchへの取り込みは他にもLogstash、Jaegerなどのサードパーティのクライアントを利用することもできます。

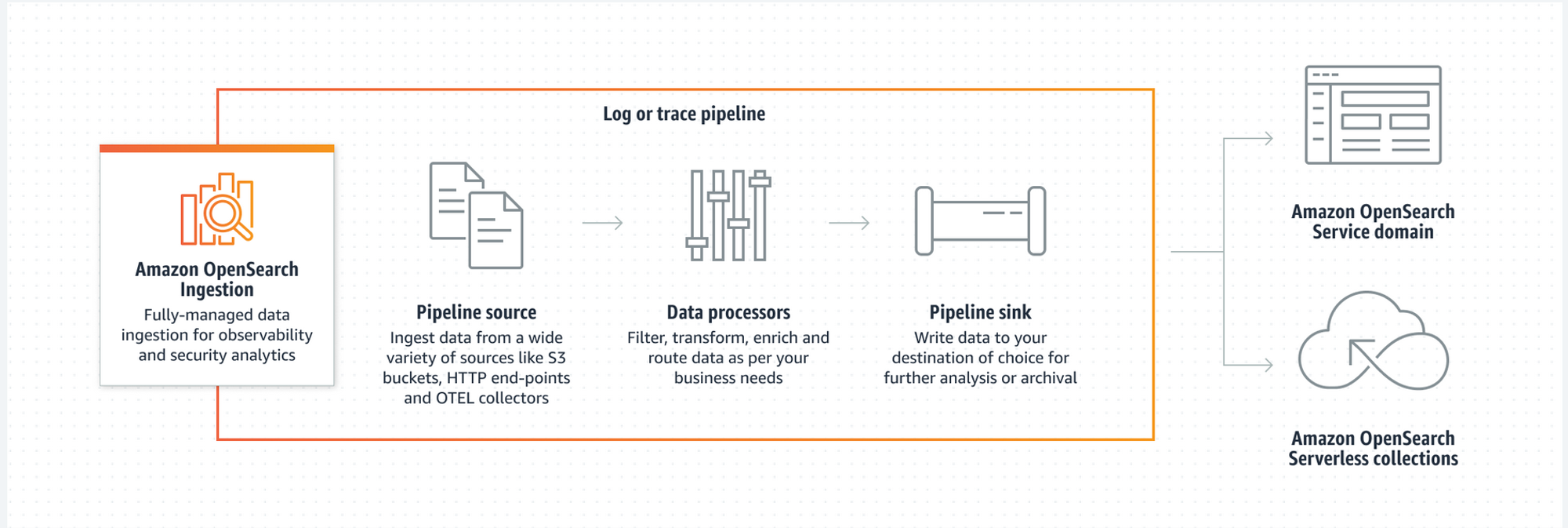
4.4.1. Amazon OpenSearch Ingestionとは
OpenSearch Serverlessにデータを出力するためのサービスです。
他サードパーティと違いサーバレスのため、単一障害点になるリスクがありません。
内部ではデータコレクターであるData Prepperを使用しており、「ソース」コンポーネントがデータを読み込み、「プロセッサ」コンポーネントが変換を行い「シンク」コンポーネントがOpenSearchに出力します。
管理はYAMLファイルで行います。
4.4.2. ソース、プロセッサ、シンクコンポーネント
YAMLファイルでメインとなる記述は以下の3つとなります。
ソースコンポーネントは入力を担当します。HTTPS経由、Amazon S3 などの外部エンドポイントから読み取る。
プロセッサーコンポーネントはソースコンポーネントが読み出したデータにフィルタリング、エンリッチ化、変換、正規化、集約などを担当します。
処理をする必要がない場合、このコンポーネントは省略が可能です。
シンクコンポーネントは出力を担当します。ソースまたはプロセッサーコンポーネントで処理したデータを宛先に出力します。
5. 注意点
便利な反面、注意が必要な点もあります。
-
ドキュメントがまだ少ない
EC2などの主要サービスと比較するとまだ新しいサービスのため、公式ドキュメントから理解する必要があります。筆者は公式ドキュメントを得意としていないので実装時はストレスフルでした。 -
デバッグが大変
処理内でブラックボックスな箇所が多く、実装初期はエラーメッセージの推測にある程度時間がかかります。 -
割高な料金
フルマネージドなため、自前でのサーバ運用よりコストは高くなります。
特にリアルタイムでの運用を実現する場合は、予想以上のコストとならないよう事前に料金計算を行った方が良いです。
OpenSearch Serverlessだけに関すると、アクティブレプリカを有効化すると無効化時の「4倍」料金が高くなります。(筆者はこれで有効化から無効化に切り替えましたが、その場合はもう1からの作成する必要があります…) -
待機時間は動かさない
Amazon OpenSearch Ingestionは、処理の有無に関係なく起動時間中は課金されてしまいます。
EventBridgeやcron等を利用して別途、起動・停止処理を作成する必要があるかもしれません。
まとめ
いかがでしたでしょうか。
今までOpenSearchを使うにはある程度の知識や体制が整っていないと難しいところが、Serverlessの登場によって、導入のハードルもグッと下がり、また移行に伴う周辺サービスも全てAWS内で完結できてしまうところに大変魅力を感じました。
また全てフルマネージド構成が実現でき、運用負担も格段に軽減できると思います。
ただし価格は若干割高なため、継続的学習によりOpenSearch Serviceへの切り替えを行い、コスト削減も視野に入れる必要がありそう。