はじめに
機械学習を用いて分類タスクを行う場合、誤った予測によって生じる損害が異なるケースがある。
例えば、レントゲン画像から癌かどうかを分類する場合、誤分類した時の対応は下記の通り。

癌予測のケースでは、死亡リスクが増大するので明らかに実際には癌であったが、予測が癌でない時(偽陰性)のリスクが高い。
このように誤分類した時のリスクが非対称な場合は、非対称性を考慮して機械学習モデルを学習する必要がある。
この場合、 機械学習モデルの学習方法として、コスト考慮型学習(Cost Sensitive Learning) が活用される。
今回はコスト考慮型学習について解説していく。
コスト考慮型学習とは
コスト考慮型学習は、機械学習において誤分類のコスト(損害や重大さ)を考慮した学習方法である。
誤分類コストを考慮した学習手法はいくつか存在する。手法の1つとして、 モデルの出力に対する検出閾値を誤分類コストに応じて調整する手法がある。
今回は検出閾値を調整する方法について紹介する。
誤分類コストに応じた検出閾値の調整
今回は説明をシンプルにするために2値分類のケースを考える。
検出閾値設定の方針は以下の通り
- 誤分類した時のコストを定義(コスト行列)
-
確率*誤分類コストで誤分類コストの期待値を算出 - 誤分類コストの期待値から検出閾値を算出
それぞれ説明していきます。
誤分類コストの定義(コスト行列)
まずは誤分類した時のコストを定義する。
ここで、機械学習モデルが$C_i$と予測したデータの真のクラスが$C_j$だった時の誤分類コストを$c_{ij}$とする。
この時、誤分類コストは下表のとおり。
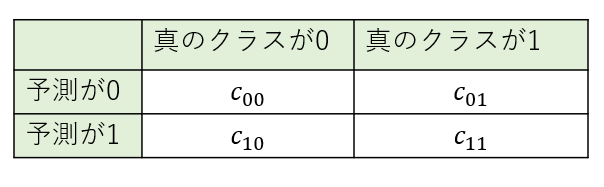
誤分類コストの値をどう定義するかは、事例ごとに考える必要がある。
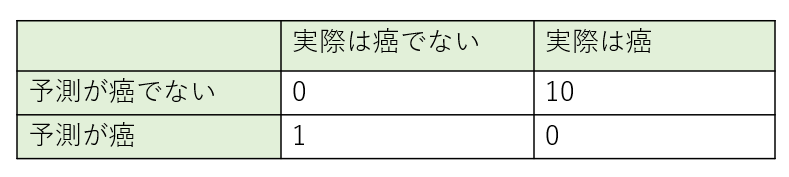
例えば、癌予測の事例で、擬陽性の時の患者の死亡リスクを1とした時、偽陰性では10倍リスクがあると仮定すると誤分類コストは下表のとおり定義できるかもしれない。
誤分類コストの期待値を算出
コスト行列が定義できたら、データ$x$のクラスを予測した時の誤分類コストの期待値を計算する。
方針としては、あるデータ$x$の予測は 誤分類コストの期待値が小さい方のクラスに属する ように分類することを考える。
データ$x$がクラス$C_j$に属する真の確率を$P(C_j|x)$とする。
データ$x$が$C_1$に属すると予測した場合の誤分類コストの期待値は (実際はC_0だがC_1と誤分類した時のコスト期待値) + (C_1と正しく分類できた時のコスト期待値)となる。
数式だと下式の通り。
$$
P(C_0|x)c_{10}+P(C_1|x)c_{11}
$$
$C_0$と予測した場合の誤分類コストの期待値は下記の通り。
$$
P(C_1|x)c_{01}+P(C_0|x)c_{00}
$$
誤分類コストの期待値から検出閾値を算出
ここから、誤分類コストの期待値が最小となる検出閾値を算出していく。
数式での説明が続くが、頑張ってついてきてほしい。
誤分類コストの期待値が小さい方のクラスに分類する という考えの基で分類するとする。この時、クラス$C_1$に分類する場合は下記が成り立つ。
$$
P(C_0|x)c_{10}+P(C_1|x)c_{11} \le P(C_1|x)c_{01}+P(C_0|x)c_{00}
$$
ここで、$P(C_1|x)=p$とおくと、$P(C_0|x)=1-p$となる。
先ほどの式を$p$を用いて表現すると下式になる。
\begin{align}
(1-p)c_{10}+pc_{11} \le pc_{01}+(1-p)c_{00}
\end{align}
ここで、最適な検出閾値を$p^*$とする。
$C_1$と予測した時の誤分類コストと$C_0$と予測した時の誤分類コストが等しくなる時を閾値とすると考えると、$p^*$は、
\begin{align}
(1-p^*)c_{10}+p^*c_{11} &= p^*c_{01}+(1-p^*)c_{00} \\
p^* &= \frac{c_{10}-c_{00}}{c_{10}-c_{00}+c_{01}-c_{11}}
\end{align}
上述の癌の分類のコスト行列を使うと、検出閾値は$\frac{1-0}{1-0+10-0} \fallingdotseq 0.09$となる。よって、機械学習モデルの出力する予測確率が、0.09以上であれば癌と予測するという運用になる。(検出閾値が低すぎる気がするので、コスト行列は要調整。。)
コスト考慮型学習の実装
決定木で2値分類する場合のコスト考慮型学習の実装は下記の通り。
cost_matrix = np.array([0, 10, 1, 0]).reshape((2,2))
threshold = (cost_matrix[1,0] - cost_matrix[0,0]) / (cost_matrix[1,0] - cost_matrix[0,0] + cost_matrix[0,1] - cost_matrix[1,1])
x_train, x_test, y_train, y_test = train_test_split(df, df["class"], test_size=0.2, random_state=99)
cls = DecisionTreeClassifier(max_depth=5, random_state=99)
model = cls.fit(x_train, y_train)
y_prob = model.predict_proba(x_test)[:, 1]
y_pred = (y_prob >= threshold).astype(int) # コスト行列から算出した閾値で分類
さいごに
誤分類コストが非対称である場合に活用できるコスト考慮型学習について紹介した。
検出閾値を調整する方法はコスト考慮型学習の1つにすぎない。
他には誤差関数などのモデルの学習手法そのものに誤分類コストを組み込む手法もあるらしい。
気になる方は他の手法も調べてみてほしい。
参考文献
関連記事