はじめに
こんにちは、@sasshi_iです。
本日はXAIの手法の1つであるLIME(Local Interpretable Model-agnostic Explanations)について説明したいと思います。
LIMEは局所説明の手法です。
LIMEはある入力に対して機械学習モデルの出力に寄与した特徴量を算出します。
局所説明って何?という方はこちらの記事をご覧ください。
それでは、LIMEがどのように機械学習モデルを説明するのかを説明していきます。
LIMEとは?
LIMEは、複雑な機械学習モデルを説明するための解釈可能な機械学習モデルを作ります。
LIMEがどのように機械学習モデルを説明しているかみていきましょう。
どのようにして解釈可能な機械学習モデルを得るのか
LIMEは、複雑な識別境界や内部ロジックを持つ機械学習モデルであっても、説明対象の近傍に限れば、単純な(解釈可能な)機械学習モデルで近似できると仮定しています。
LIMEを用いて解釈可能な機械学習モデルを得るステップは以下の通りです。
- 説明対象のデータに摂動(小さな変更)を加え、近傍データを作成する
- 訓練済の機械学習モデルを用いて近傍データの予測結果を取得する
- 近傍データと予測結果を用いて解釈可能な機械学習モデル(ex. 線形回帰など)を構築する
近傍データの重みづけ
説明対象から距離が近い近傍データほど解釈可能な機械学習モデルの訓練において大きな影響を持つように重みづけされます
データ種別ごとの近傍データの作成方法
説明対象のデータが表データ、画像データ、テキストデータのいずれかによって近傍データの作成方法が変わります。
それぞれについて説明していきます。
表データ
各特徴量が取り得る値や統計的な計算情報を基に近傍データが作成されます。
説明対象データの近傍に限らず、各特徴量が取り得る空間全体でランダムにデータが生成されます。
ただし、説明対象と距離が近いデータは解釈可能なモデルの学習の際に重視するように重みづけされます。
画像データ
画像データでは下記のようにセグメントに分け、セグメント単位で白や黒、RGBの平均などで塗りつぶすことで近傍データを作成します。
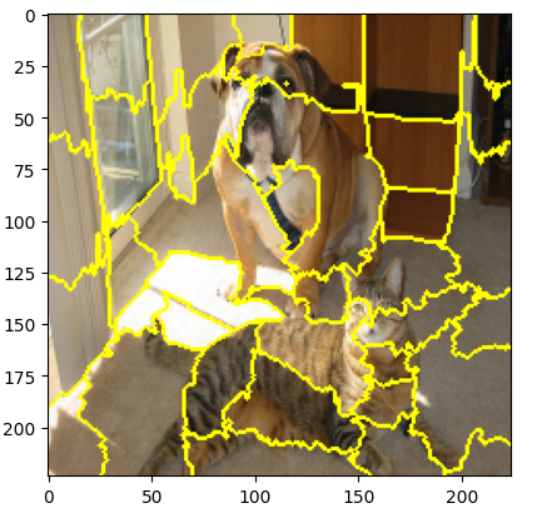
テキストデータ
テキストデータにおける近傍データは、説明対象の文の中にある単語を隠すようにして作成されます。テキストデータ版LIMEでは出現している単語のみが摂動の対象となるため、ある単語が書かれていないことを説明として出力することはできません。
LIMEの強み/注意点
強み
- モデルに依存しないため、任意の機械学習モデルに適用可能
注意点
- 近傍データがランダムに生成されるため、説明結果が一定にならない
- ハイパーパラメータの調整が必要(近傍データのデータ数など)
- 局所的な説明に限定されるため、モデル全体の動作を説明することはできない
LIMEを用いた局所説明実装
それでは、実際にLIMEで実際に機械学習モデルの説明をしてみましょう。
今回はkaggleのタイタニックのデータを使いたいと思います。
また、機械学習モデルにはLightGBMを使います。
最初はLightGBMのモデルを訓練します。
from lime.wrappers.scikit_image import SegmentationAlgorithm
import numpy as np
import pandas as pd
from skimage.segmentation import mark_boundaries
from sklearn.preprocessing import OneHotEncoder
from PIL import Image
import matplotlib.pyplot as plt
from lightgbm import LGBMClassifier
from sklearn.model_selection import train_test_split
df = pd.read_csv("train.csv")
# 前処理
drop_columns = ["PassengerId", "Ticket", "Cabin", "Name"]
cotegory_coulms = ["Embarked", "Sex"]
df = df.dropna(subset=["Embarked"])
df = df.drop(columns=drop_columns)
df["Age"] = df["Age"].fillna(df["Age"].median())
df = pd.get_dummies(df, columns=cotegory_coulms)
df_train, df_test = train_test_split(df, test_size=0.2, stratify=df["Survived"], random_state=99)
X_train = df_train.drop("Survived", axis=1)
y_train = df_train["Survived"]
X_test = df_test.drop("Survived", axis=1)
y_test = df_test["Survived"]
# モデル定義
model = LGBMClassifier(
max_depth=4,
colsample_bytree=0.5,
reg_lambda=0.5,
reg_alpha=0.5,
importance_type="gain",
random_state=100
)
# 訓練
model.fit(
X_train,
y_train,
eval_sample_weight=0.2,
)
print(f"Accuracy: {model.score(df_test.drop('Survived', axis=1), df_test['Survived'])}")
> Accuracy: 0.8426966292134831
モデルの訓練が完了したらLIMEを用いて機械学習モデルの局所説明を行います。
from lime.lime_tabular import LimeTabularExplainer
explainer = LimeTabularExplainer(
X_train.values,
feature_names = X_train.columns,
)
exp = explainer.explain_instance(
X_test.values[1],
predict_fn,
num_features=5
)
exp.show_in_notebook()
こんな感じの出力がでます。

今回は予測に寄与した特徴量のうち、5つを表示しました。
exp.show_in_notebook()で結果を表示することができますが、自身でグラフを描画したいのであれば、exp.as_list()で必要な値を取得することが可能です。
exp.as_list()で下記のような値を取得することができます。
[('Sex_female <= 0.00', -0.3703521038941386),
('Pclass <= 2.00', 0.1400599028326455),
('Fare > 30.50', 0.13944809602049085),
('Age > 35.00', -0.12828630423116846),
('0.00 < Sex_male <= 1.00', -0.1255471131696602)]
おわりに
今回は局所説明の手法であるLIMEについて解説しました。局所説明の手法としては他にもSHAPがあるので、SHAPについての解説記事も今後書いていきたいと思います。
参考文献
[1] https://arxiv.org/pdf/1602.04938.pdf
[2] https://lime-ml.readthedocs.io/en/latest/lime.html
[3] XAI(説明可能なAI)--そのとき人工知能はどう考えたのか?
関連記事