背景
SASを使っているが、Rやpythonも勉強しようかなと思ったことがある
RやpythonでSQLが使えることを知ってから、とりあえずSASでSQL練習し、再びRにチャレンジ
https://qiita.com/saspy/items/2829fdf6ab21ce9d9ce0
https://qiita.com/saspy/items/43b4c368d22f45f023a2
qiitaには載せていないがSQLで分割表の計算などもできたりし、Rはちょっとずつ慣れてきたかも
今度はpythonにチャレンジ👍
pythonでSQLのgroup byをやってみる
pythonではpandasqlやSQLite3などでSQLが使えるよう
準備
https://qiita.com/saspy/items/2829fdf6ab21ce9d9ce0
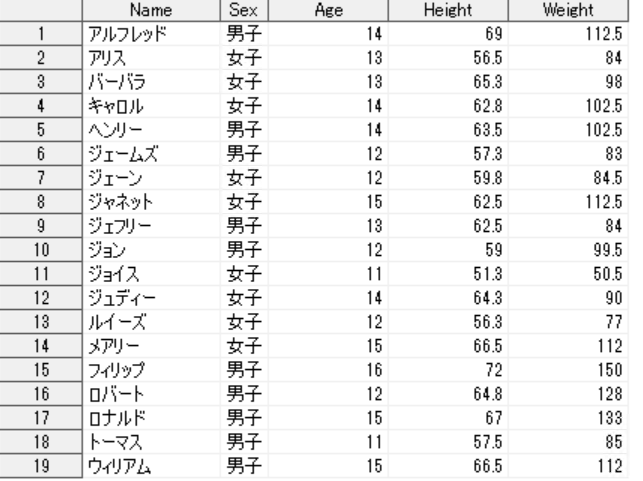
↑と同様、SASのCLASSデータを使用
# パッケージ
import pandas as pd
import numpy as np
import dask
import dask.dataframe as dd
import sqlite3
from pandasql import sqldf
from sas7bdat import SAS7BDAT
from dask_sql import Context
# フォルダパス
Data_Dir = "フォルダパス"
File_Name = Data_Dir + "/class.sas7bdat"
Sashelp_Class = SAS7BDAT( File_Name , encoding = "cp932" ).to_data_frame()
# pandasで読み込む場合(日本語入ってると、エラーにはならないが正しく読み込めない)
# Sashelp_Class = pd.read_sas( File_Name , format = "sas7bdat" )
pandasqlのsqldf使用
query = """
select AGE , count(*) as N
from Sashelp_Class
group by AGE;
"""
CLASS_STAT = sqldf( query , locals() )
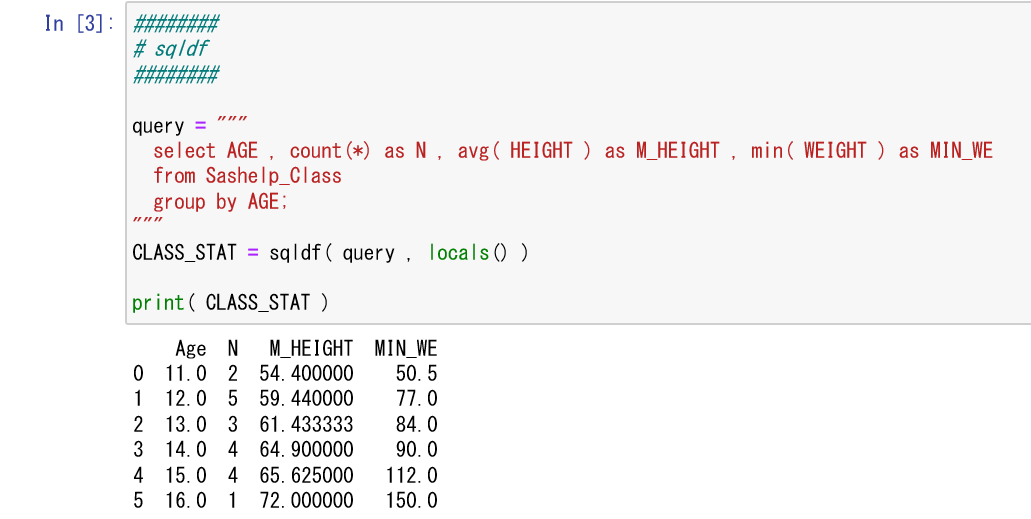
SASのSQLプロシジャと同様に、SQLの構文の最後に「;」が必要
SASのSQLプロシジャやRのsqldfともそんなに変わらないようなプログラムで集計できる
ちなみにSQL使わないでthe pythonっぽい感じなら
CLASS_STAT2 = Sashelp_Class.groupby( "Age" ).Name.count( )
とか
CLASS_STAT2 = Sashelp_Class.groupby( "Age" ).agg({ "Height" : [ np.size , np.mean ] , "Weight" : [ np.min ] , ...て集計内容書いていく } )
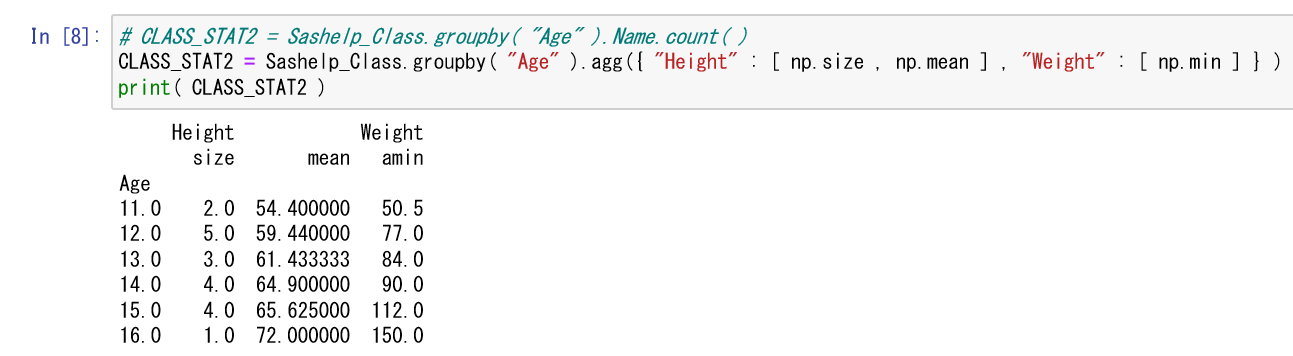
pandasとかの方が速いだろうし、python慣れたらこっちのほうがいいかもね
SQLの方がハンドリングきれいな気はするけど、好みかな
SQLite3とread_sql_query
# データベース(db指定する場合は""内にかく)
conn = sqlite3.connect( "" )
# SQL化
Sashelp_Class.to_sql( "Class_Sql" , conn )
query = """
select AGE , count(*) as N
from Class_Sql
group by AGE
"""
CLASS_STAT3 = pd.read_sql_query( sql = query , con = conn )
# データベース閉じる
conn.close()

こっちは、「;」不要
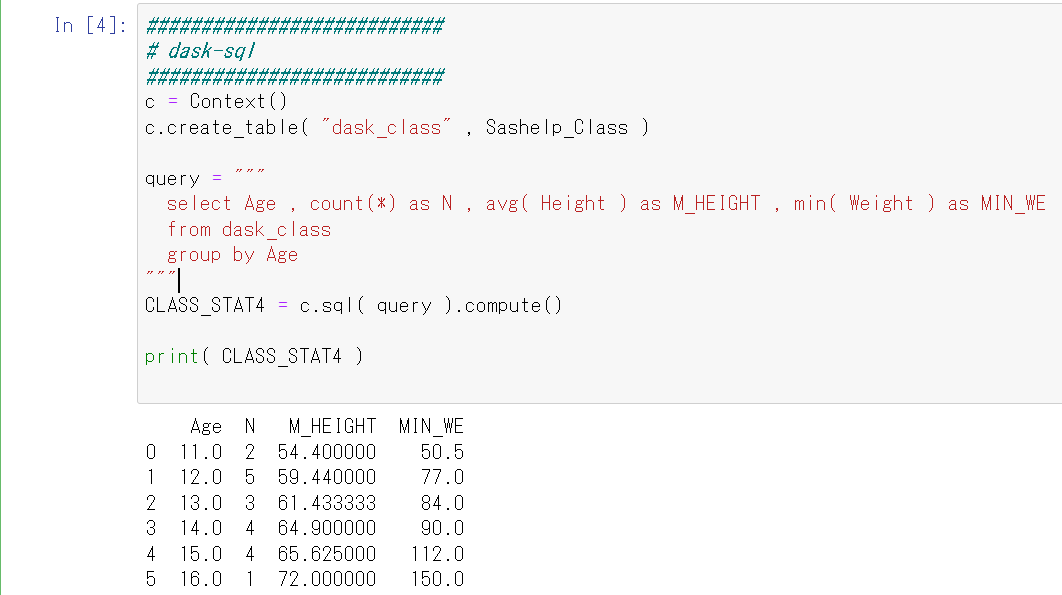
dask-sql
dask-sqlなるものもあったので追記
sqlite3&read_sql_queryを使う流れとほぼ同じ
# SQL化
c = Context()
c.create_table( "dask_class" , Sashelp_Class )
# クエリ
query = """
select Age , count(*) as N , avg( Height ) as M_HEIGHT , min( Weight ) as MIN_WE
from dask_class
group by Age
"""
CLASS_STAT4 = c.sql( query ).compute()
print( CLASS_STAT4 )
https://pypi.org/project/pandasql/
https://pandas.pydata.org/pandas-docs/stable/user_guide/index.html
https://docs.python.org/ja/3/library/sqlite3.html
https://dask-sql.readthedocs.io/en/latest/