はじめに
皆さん苦手な食べ物はありますでしょうか?
私にはいくつか苦手な食べ物がありますが、その中でも***「豆全般」苦手***です。
え?豆?なんで?ってよく言われますが、正直なんでかはよくわかりません。
細胞が拒否している(アレルギーではありません)のかなと思います。
(こしあん、味噌、醤油OK/つぶあん、豆腐NG)
前置きはさておき、私は小学生の頃毎月配布される給食の献立表をもらったらすぐに、豆が書かれている箇所すべてにマーカーを引いていました(笑)。
献立表にマーカーを引くメリットは以下の通りです。
- 前もって豆が出てくるとわかるため心の準備ができる
- その日の給食までに、友人に食べてほしいとお願いできる
とはいえ、毎月献立表のすべての豆にマーカーを引くのは非常に大変です。
そこで、今回はどうにか「小学生の頃の僕」を楽にしてあげたいと思います。
調べてみた
じゃあ実際にどうやるのか?と考え調べてみたところなにやら***「OCR」***という技術がよさげな感じがした。
OCRとは?
OCRは、Optical Character Reader(またはRecognition)の略で、画像データのテキスト部分を認識し、文字データに変換する光学文字認識機能のことを言います。具体的にいうと、紙文書をスキャナーで読み込み、書かれている文字を認識してデジタル化する技術です。
参考:業務効率ツールとして注目!「OCR」とは
OCRを使って、献立表を認識し、文字データに変換しNGワード(まめ等)をハイライトすればよさそう。
もっとスマートなやり方はあるとは思いますが、思い浮かばなかったOCRを使ってみたいのでこの方法でやっていきます。
「OCR プログラミング」と調べてみると***「Tesseract」というワードがちらほら確認できました。Tesseractは、オープンソースのOCRエンジンである。
追加で調べてみると、TesseractをJavaScriptに移植したTesseract.js***があるらしいので今回はこれを使ってみることにします。
参考:テキスト認識エンジン「Tesseract」をJavaScriptに移植した「Tesseract.js」
開発
今回は、しっかりと完成させるというよりはお試しで作ってみるだけなのでTesseract.jsはCDNで使用します。
<body>
<div>
<input type="file" id="uploader">
</div>
<div>
進捗: <span id="progress">0</span>%
</div>
<div>
<div id="ocrResult"></div>
</div>
</body>
const files = evt.target.files;
if (files.length == 0) {
return;
}
Tesseract
.recognize(files[0], { lang: 'jpn', tessedit_pageseg_mode: "RAW_LINE" })
.progress(function (p) {
// 進歩状況の表示
let progressArea = document.getElementById("progress");
progressArea.innerText = p.status + " " + Math.round(p.progress * 100);
})
.then(function (result) {
// 結果の表示
$replaceResult = highlight(result)
let ocrResult = document.getElementById("ocrResult");
ocrResult.innerHTML = $replaceResult;
});
}
const elm = document.getElementById('uploader');
elm.addEventListener('change', recognize);
function highlight(result) {
const ngWords = ['そらまめ', 'ひよこまめ', 'えだまめ', 'なっとう'];
let resultHtml = result.text.replace('会', '金'); //「金」を「会」と誤認してしまうため置き換える
//NGワードにハイライト用のクラスをつける
for (let i = 0; i < ngWords.length; i++) {
resultHtml = resultHtml.replace(new RegExp(ngWords[i], "g"), '<span class="highlight">' + ngWords[i] + '</span>');
}
return resultHtml;
}
CSSは省略
今回のコードの大半はこちらのサイトのコードを使用しました。
参考:Tesseract.js を使った最小 OCR サンプル
解説
recognize
recognize(files[0], { lang: 'jpn', tessedit_pageseg_mode: "RAW_LINE" })
recognize関数は、OCR解析を実行する関数。
第一引数には対象の画像を、第二引数にはオプションを指定する。
tessedit_pageseg_modeは、ページ区切りモードを指定するオプション。RAW_LINEでページ固定している。
progress
progress(function (p) {
// 進歩状況の表示
let progressArea = document.getElementById("progress");
progressArea.innerText = p.status + " " + Math.round(p.progress * 100);
})
progress関数は、ジョブ(解析)が進行したときに呼ばれるcallback関数をセットすることが出来る。
getElementByIdでprogressの要素を取得し、progressArea変数にいれる。
innerTextでprogressAreaに解析の進行状況を反映させている。
Math.round関数で、四捨五入している。
参考
・Tesseract.jsを使ってブラウザだけでOCRする方法
・JS向けOCR Tesseract.jsのドキュメント和訳
ハイライト用の処理
function highlight(result) {
const ngWords = ['そらまめ', 'ひよこまめ', 'えだまめ', 'なっとう'];
let resultHtml = result.text.replace(new RegExp('会', 'g'), '金'); //「金」を「会」と誤認してしまうため置き換える
//NGワードにハイライト用のクラスをつける
for (let i = 0; i < ngWords.length; i++) {
resultHtml = resultHtml.replace(new RegExp(ngWords[i], 'g'), '<span class="highlight">' + ngWords[i] + '</span>');
}
return resultHtml;
}
こちらは、指定の文字(NGワード)にハイライトをいれるための処理です。
今回は、豆の中でも特に苦戦を強いられる四天王をチョイスしました。
あとで説明しますが、Tesseract.jsの精度がよいとは言い切れない(やり方次第で向上すると思います)です。とりあえず今回は金曜日が会曜日になってしまうためその箇所だけ修正。
ループ処理で、NGワードをハイライト用のクラスを付けた状態に置き換えます。
この時、少し躓いたのがreplace()を使う際、以下のようにPHPと同じように記載すると
[例]
const colors = ['red','blue','green'];
const replaced = colors.replace(',', ' ');
console.log(replaced); //red blue,green 最初にマッチしたものしか置換できていない
マッチしたもの一つしかハイライトされませんでした。
正規表現を使うことで全置換を行うことが出来るんだとか。
RegExpの第二引数で指定している"g"は、グローバルマッチングのフラグでこちらを指定することでNGワードがでてくるたびにハイライトするようにできます。
参考
・replaceに変数を使ってグローバルマッチさせる2つの方法
・RegExp
・String.prototype.replace()
then
then(function (result) {
// 結果の表示
$replaceResult = highlight(result)
let ocrResult = document.getElementById("ocrResult");
ocrResult.innerHTML = $replaceResult;
});
thenでは、ジョブ(解析)が完了したときに呼ばれるcallback関数をセットします。
結果を、先ほど説明したhighlight関数の引数に渡す。
結果
先に言いますが、うまくいきませんでした!!!温かい目で見てください。
一般的な給食の献立表
使用した画像はこちら(そもそも今回指定したNGワードはない(笑))
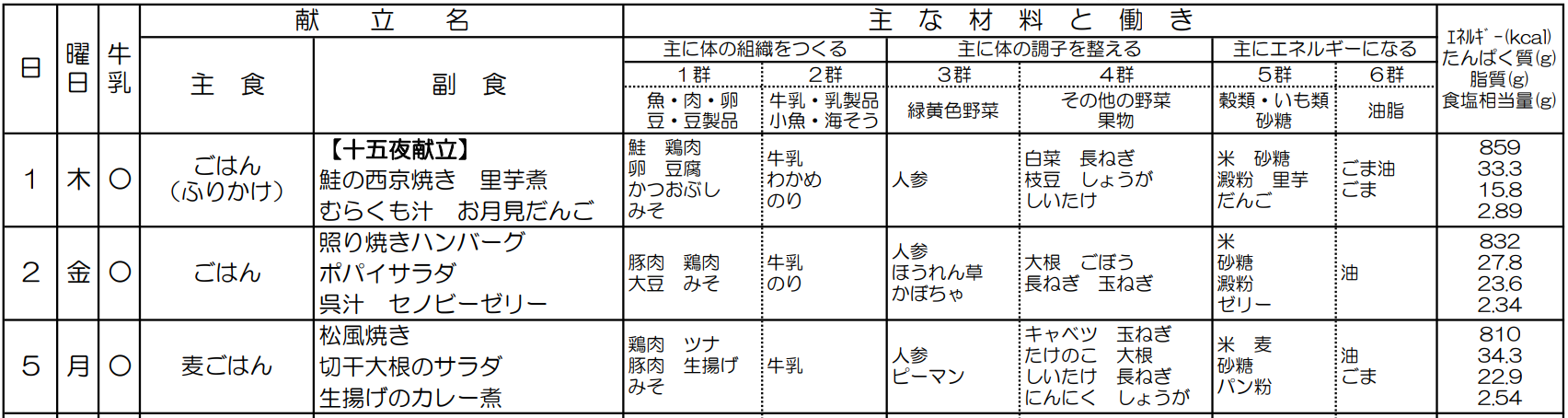
懐かしいですね。※私は、あげパンが好きでした。
結果がこちら

複雑すぎたか、全然読み取れていませんでした。
かなーり簡略化した特製の献立表
あの頃の自分を思うと、どうしても献立表にマーカーを引いてあげたい…。
そのため、今回は妥協して特別製の献立表を作りました。
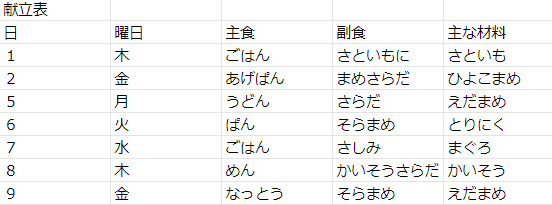
9日の献立は絶望的です。
結果がこちら

なっとうだけうまく認識できませんでしたが、その他3つのまめは無事認識できすべてハイライトできています。(所々ミスはありますが)
何度かやってみて感じたこととしては、
- カタカナの認識は苦手そう
- 周りの文字しだいで認識できていたものが出来なくなったりする(なつとうと認識したこともあった)
- 細かい箇所で間違えている部分はあるがやり方次第で精度はあがりそう
- 英語の認識精度はよさそう
おまけ(特製の献立表 改)
上記の献立表の文字を太字にしてみてやってみたら結果が変わるのか試しにやってみました。文字はくっきりしているので精度があがると予想。
結果がこちら

結果は、予想に反して悪化しました。
確認してみるとえだまめの「え」、ひよこまめの「よ」、さといもの「い」など以前より大文字と小文字の区別の精度が下がっていました。
どうすれば精度はあがるのか?
◯適切な文字サイズで読み取ること
文字が小さいと認識率は下がります。画像を拡大してから読み取ることが重要。
◯高解像度の画像を使用する
人の目で確認できるレベルでも画像が粗いと認識率は下がる。できるだけ高解像度の画像を使用すること。
◯ブラックリスト、ホワイトリストを活用する
読み取る際に、絶対に使用しない文字なのに誤認識されてしまうという状況があったとき、オプションでブラックリストの設定をすることで、誤認識を防ぐことが出来ます。
(今回でいうと、「金」が「会」になってしまうケース)
特定の文字しか使用しない場合は、ホワイトリストを使って指定文字のみに絞ることが出来ます。
まとめ
今回は、Tesseract.jsを用いて給食の献立表の指定ワード箇所をハイライトするものを作りました。
今後本格的に取り組んで、完璧なものを作り上げることがあったらまたQiitaでお伝えします。
やっぱり自分で「これ作りたい!」ってものがあると勉強も楽しくできますね。
よくよく思い出してみると、豆は本当に苦手ですがなんだかんだ給食の献立表にマーカーを引く作業は楽しんでいたような気もします(笑)。
たまには非効率な作業もありなんじゃないでしょうか!
p.s.あの頃、まめを食べてくれた関係者の皆様(友達)ありがとう!本当に助かりました。