スクレイピングをしてた時にどーしても取れない要素があったがとんでもないアホなやり方をしてたので自分への戒めとしてメモしたい。
とある求人サイトで会社名、住所、電話番号のスクレイピングを試みた。
会社名はhタグでidもついてる。これは簡単に取れた。しかし問題は住所、電話番号。
<tbody id="w_7_detail_1_1-tbody">
<tr>
<td class="w_7_detail_1_1-td-label" id="w_7_detail_1_1-td-address">住所</td>
<td class="w_7_detail_1_1-td-value">福岡市○○区○○町111-111</td>
</tr>
<tr>
<td class="w_7_detail_1_1-td-label" id="w_7_detail_1_1-td-phone">電話番号</td>
<td class="w_7_detail_1_1-td-value">090-1111-2222</td>
</tr>
</tbody>
検証ツールで見るとこれら二つはtbodyの中のtrタグ、tdタグに入ってる。
しかしよく見ると・・・
<td class="w_7_detail_1_1-td-value">福岡市○○区○○町111-111</td>
<td class="w_7_detail_1_1-td-value">090-1111-2222</td>
classが全く同じなのだ。
なのでこれら二つを一個ずつ取るしかない。find_allでとってforで回す、そして配列番号で取得できるじゃないかと思いこんなコードを書いてみた。
t_body = soup_3.find('tbody', id='w_7_detail_1_1-tbody').find_all('td', class_='w_7_detail_1_1-td-value')
print(name)
for i in t_body:
if t_body[0]:
company_adress = i.text
print(company_adress)
elif t_body[1]:
company_number = i.text
print(company_number)
d_list.append({
'name': name,
'url': company_adress,
'number': company_number
})
print(d_list[-1])
一番上でtbodyを一つとってその後で全てのtdを取得。その下でforを回してます。
もしtdの配列0番目があるならcompany_adressに格納。
そんでもってもし1番目があるならcompany_numberに格納。
取得した結果を空の配列d_listに格納。余裕余裕〜
と思いきや
ホテル 南国アイランド
福岡市○○区○○町111-111
Traceback (most recent call last):
File "/Users/sasaki/Desktop/work-scraping/check.py", line 52, in <module>
'number': company_number
NameError: name 'company_number' is not defined
(scraping-work) (base)
一応ホテル名と住所は取れた。だがしかし電話番号が取れない!
company_numberが定義されてない?目の節穴かお前は!とエラーに怒ってもしょうがない。
色々試行錯誤し行き着いた結果・・
if文いらねくね?
と思い下記のコードに修正
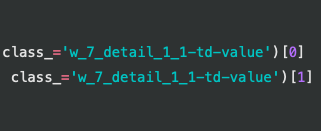
t_body = soup_3.find('tbody', id='w_7_detail_1_1-tbody').find_all('td', class_='w_7_detail_1_1-td-value')[0]
t_body1 = soup_3.find('tbody', id='w_7_detail_1_1-tbody').find_all('td', class_='w_7_detail_1_1-td-value')[1]
print(name)
company_adress = t_body.text
company_number = t_body1.text
print(company_adress)
print(company_number)
d_list.append({
'name': name,
'url': company_adress,
'number': company_number
})
print(d_list[-1])
最初にfind_allで取ったらその直後に配列指定👇。
あっさり成功。ここまで4時間かかりました。
自分バカすぎる・・なぜifを使おうと思った・・
ここで得た教訓はなるべくシンプルにコードを書こうと思いました。
親要素、子要素を気にしすぎると訳わからなくなるし、直感的に取得するのが一番の近道だと思う。