前回の記事👆でAPI取得からどうやってコードに落とし込むかを紹介しました。
今回はそのAPIをPythonでどう処理したのかを解説したいと思います。
from flask import Flask, render_template
import git
app = Flask(__name__)
@app.route('/')
def scraping_api():
return render_template('index.html')
@app.route('/results', methods=['POST'])
def do_scraping():
results = git.git_api()
return render_template('results.html', results=results)
if __name__ == ('__main__'):
app.run()
まずはflaskのインポート。からのインスタンス作成。👉app = Flask(name)
(なぜか消えてますがnameの両端にアンダーバーがはいります)
今回は別でスクレイピングを処理するファイルを作ったのでそれをgit.pyに格納。
import git はそのファイルを呼び出してます。
インスタンスからの@app.routeはデコレーターと呼ばれるもの。これイマイチ仕組みがわかってないんだけど、クラスの継承みたいなものでしょうか?また随時調べたいと思います。
その下の関数、scraping_api()とdo_scraping()でrender_templateを使ってHTMLと繋げる処理、
git.pyで書いたスクレイピング処理を引っ張ってきて結果ページのresults.htmlに繋げるコードを記述。
最後にif文でアプリを起動させてます。これはお決まりの呪文の様なものですが、これもイマイチよく分かってない汗 追々調査したいと思います。
そして今回の心臓部と言っても過言ではないスクレイピング関数、git_api()をご紹介。
import json
import requests
import time
from flask import request
def git_api():
serchfor = request.form.get('rank_git')
serchfor = str(serchfor)
url = 'https://api.github.com/search/repositories?q=stars%3A%3E1+created%3A' + serchfor + '&type=Repositories&ref=advsearch&l=&l='
response = requests.get(url)
data = json.loads(response.text)
api_lists = []
i = 0
while i < 5:
ranks = [['第' + str(i + 1) + '位 ユーザー名: ' + data.get('items')[i].get('name')], ['スター獲得数: ' + str(data.get('items')[i].get('stargazers_count'))]]
time.sleep(3)
i += 1
ranks = str(ranks).replace('[','').replace(']','')
ranks = str(ranks).replace('\'','').replace('\'','')
api_lists.append(ranks)
return api_lists
上から順に必要なライブラリーのインポート。requestsやtimeはお決まりですが、今回はjsonを使います。beautifulsoupを使わない代わりにjsonで解析するようです。
あとはhtmlから値を取得するのにflaskのrequestを使います。
ややこしいですがrequestsとrequestは間違えないようにしましょう。私は最後のsの有無でエラーを起こしましたw
関数内をざっと説明すると、URLの取得から解析、欲しい情報を取ってます。
詳しく解説したいのですが改めてコードを見ると、あぁクソコードやな・・と思ってしまいます。
自分で書いたのに「これ何の処理してるコードだっけ?」と思いながら記事を書いてることはおそらくエンジニアあるあるなんでしょう。そういうことにしときますw。
でも敢えて解説するなら、while文の処理はかなり手こずりました。まずユーザー名とスター数をjsonの中から探すranks変数。
もうリストやら辞書型やら階層が深すぎぃ!
APIの中身は👇の様になってるんですが、
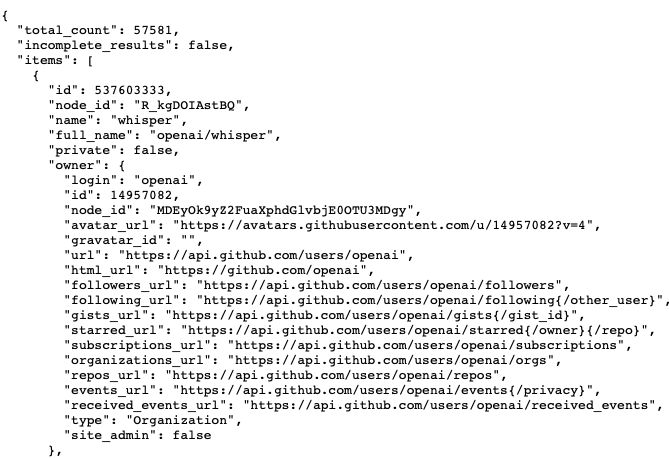
上の"total_count" や "incomplete_resuts" はシンプルに取れるんです。でも欲しいのはそのちょっと下にある"name" と、画像では見れないですがもっと下にある"stargazers_count"。
これらを取得するのに
[['第' + str(i + 1) + '位 ユーザー名: ' + data.get('items')[i].get('name')], ['スター獲得数: ' + str(data.get('items')[i].get('stargazers_count'))]]
こんなコードを書いてみました。これ絶対もっと良い書き方あるよね・・・って自分でも思いますw
まぁこれが今の自分の限界ってことで。
どうでも良いですがstargazers_countってなんかカッコいい。
あとスクレイピングで大事なのはsleep!APIの規則上、アクセスに負荷をかけてはいけないので3秒の間隔と取ってます。
そして取得結果には鉤括弧や句読点が付いてくるので見た目のデザイン考慮してreplaceで削除。(正確には空の文字列に置き換えてるだけだけど)
ここまで出来たらあとは事前に用意したapi_lists = []に格納。
今回はTOP5のランキングなので5つの値を取得してますが空のリストに入れないと取得は出来ても表示することは出来ません。
なんていうかこれ、釣りのキャッチアンドリリースみたいなものですね。
魚=欲しい値、魚は取れてもクーラーボックスのような箱に収めない限りリリースして川に戻すみたいな?
ターミナル上で結果を表示しても一応TOP5は取れてるんです。でもターミナル上で表示されるだけ。納める箱(空のリスト)がないとHTMLに運べないしブラウザで表示も出来ません。
そしてクーラーボックスに入れた魚たち(TOP5の値)をレストランに持っていきhtmlとCSSで美味しく調理しますよ!
一応ここまで一通り書きましたが長くなりそうなので今回はここまで。次回はフロントサイドの処理を紹介したいと思います。