概要
初めてデータパイプライン(データ分析基盤)を構築する際にAWS Glueを利用しました。
その際に学んだパーティション毎のDynamicFrame作成処理やDataFrameのrepartition関数などについて備忘録としてまとめていきます。


この記事のゴール
AWS Glue(PySpark)の具体的なユースケースを通じてAWS GlueやSparkのとっかかりになること。
想定読者
- AWS Glueの導入を検討している人
- AWS Glueを使い始めたばかりの人
- その他、データパイブライン構築などに興味のある人など
実行環境
Glue 2.0(Spark 2.4.3/Python 3.7)
前提
- 作者は普段はバックエンドの開発(Go/AWSなど)をやっており、PythonやSpark、データ分析環境構築は初心者であること
- とりあえず素早く動くものを作ることが目的だった
上記理由のため、誤りや改善点等あるかもしれませんがご了承ください
AWS Glueについて
端的にいうと完全マネージド型ETLサービスです。
詳細は下記の公式ドキュメントを参照ください。
機能特徴
- 他の様々なAWSサービスと楽に連携してETL環境を構築できる
- 半構造化データを操作するように設計されていて初期スキーマが必要ない
- 完全マネージド型で自分でサーバー構築が不要で素早く環境構築できる(CloudFormationも対応)
- 定期実行やイベント駆動による実行の設定もとても簡単で、リトライ処理も自動でやってくれる
まとめるとS3などのAWSサービス上にあるデータ用にETL環境構築をしたい場合にとても便利なETLのサービスです
本題
【AWSインフラ構成イメージ図】

やりたいこと
AWS S3上の下記のようなパスのcsvファイル一覧をtask_id毎に、user_id.csvファイルをまとめてgz形式で圧縮したファイルをデータターゲット先のS3に出力すること。
背景は省略しますが、Glueのジョブ自体は毎日一回深夜に前日分のデータに対して実行します。
【データソース】
s3://バケットA/{YYYY-MM-DD}/{task_id}/{user_id}.csv
↓
【データターゲット】
s3://バケットB/{YYYY-MM-DD}/{task_id}.gz
具体例
S3://data_source_bucket_a/2020-12-23/task_01/user_id01.csv
S3://data_source_bucket_a/2020-12-23/task_01/user_id02.csv
S3://data_source_bucket_a/2020-12-23/task_02/user_id01.csv
S3://data_source_bucket_a/2020-12-23/task_02/user_id04.csv
↓
S3://data_target_bucket_b/2020-12-23/task_01.gz // user_id01.csv,user_id02.csvの圧縮ファイル
S3://data_target_bucket_b/2020-12-23/task_02.gz // user_id01.csv,user_id04.csvの圧縮ファイル
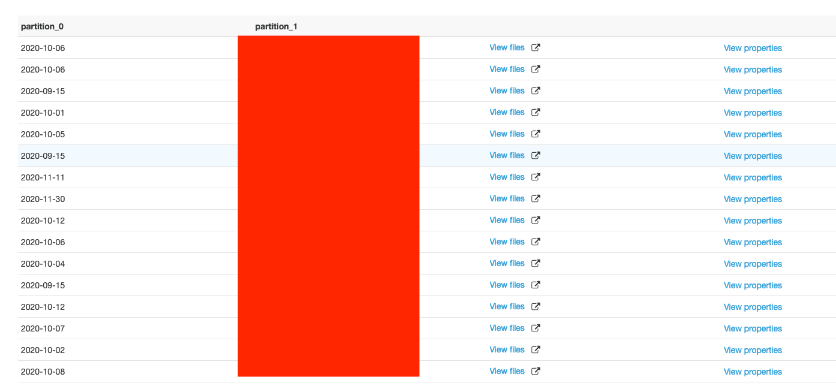
参考として、Glueのテーブルのスキーマとパーティションは下記のようなイメージです(カラムの構成とpartiton_1の値は伏せてあります)
【スキーマ】
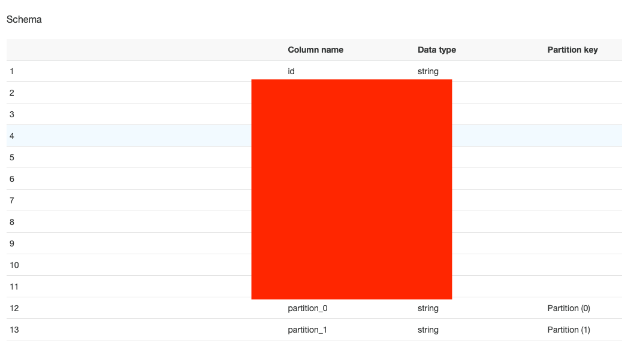
【パーティショ】
ソースコード
実装の方をみていきます。
まず始めに全体のソースコードは下記になります
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
import datetime
import boto3
# ジョブの実行時にスクリプトに渡される引数にアクセス
args = getResolvedOptions(sys.argv, ['JOB_NAME','S3_BUCKET_NAME_BEFORE','S3_BUCKET_NAME_AFTER','GLUE_DB','GLUE_TABLE'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
today = datetime.datetime.today().astimezone(datetime.timezone(datetime.timedelta(hours=+9)))
yesterday = (today.date() - datetime.timedelta(days=1)).strftime('%Y-%m-%d')
prefix = yesterday + '/'
# ジョブパラメータから各環境に応じた値を取得
# glueのデータソースのS3のバケット名
S3_BUCKET_NAME_BEFORE = args['S3_BUCKET_NAME_BEFORE']
# glueで加工した結果のCSVファイルの保存先S3のパス
S3_BUCKET_NAME_AFTER = args['S3_BUCKET_NAME_AFTER']
# glueのデータベース名
GLUE_DB = args['GLUE_DB']
# glueのテーブル名
GLUE_TABLE = args['GLUE_TABLE']
s3 = boto3.resource('s3')
bucket = s3.Bucket(S3_BUCKET_NAME_BEFORE)
result = bucket.meta.client.list_objects(
Bucket=bucket.name,
Prefix=prefix,
Delimiter='/'
)
# 指定したprefixのS3のフォルダ一覧を走査
# ターゲットのS3のパス: s3://bucket_name/{YYYY-MM-DD}/{task_id}/user_id.csv
# prefix(ex:2020-08-16/)で指定したフォルダの配下の一覧({task_id})を走査
if result.get('CommonPrefixes') != None:
for o in result.get('CommonPrefixes'):
# {task_id}のフォルダ名を抜き出し
# o.get('Prefix') ex:2020-07-30/task_id01/ → partition1: task_id01
partition1 = o.get('Prefix').replace(prefix,"").replace('/','')
# データカタログからDynamicFrameを取得
datasource0 = glueContext.create_dynamic_frame.from_catalog(
database = GLUE_DB,
table_name = GLUE_TABLE,
transformation_ctx = "datasource0",
push_down_predicate = '(partition_0 == "'+ yesterday + '" and partition_1 == "' + partition1+ '")'
)
# DynamicFrameをSparkのDataFrameに変換し、repartitionメソッドによりファイルをパーティション毎に結合
dataframe1 = datasource0.toDF().repartition(1)
# DataFrameをDynamicFrameに再変換
repartition1 = DynamicFrame.fromDF(dataframe1, glueContext, 'repartition1')
# csvファイル保存先のS3のパスを指定
s3_path = S3_BUCKET_NAME_AFTER + yesterday
# DynamicFrameをCSVファイル形式でS3に出力
datasink1 = glueContext.write_dynamic_frame.from_options(
frame = repartition1,
connection_type = "s3",
connection_options = {
"path": s3_path,
"compression": "gzip"
},
format = "csv",
transformation_ctx = "datasink1"
)
job.commit()
解説
ポイント1
# データカタログからDynamicFrameを取得
datasource0 = glueContext.create_dynamic_frame.from_catalog(
database = GLUE_DB,
table_name = GLUE_TABLE,
transformation_ctx = "datasource0",
push_down_predicate = '(partition_0 == "'+ yesterday + '" and partition_1 == "' + partition1+ '")'
)
glueのcreate_dynamic_frame作成処理でプッシュダウン述語(上記のpush_down_predicateが該当)を利用します。
これにより、Glueのカタログで利用可能なパーティションのメタデータに直接フィルターを適用することで処理が必要なS3パーティションのみを残した状態でジョブを実行できるためコストを削減できます。
ポイント2
# DynamicFrameをSparkのDataFrameに変換し、repartitionメソッドによりファイルをパーティション毎に結合
dataframe1 = datasource0.toDF().repartition(1)
SparkのDataFrameのrepartition関数により、パーティション毎にファイルを結合するようにしています。これにより本来は分割されて出力されるファイルを指定パーティションで結合することができます。
(パーティションが未指定の場合は1つ目のパーティションが使用されます。repartitionの代わりにcoalesce関数でも利用できます)
ここでは、DataFrameの関数であるrepartitionを利用するためにtoDF関数を利用してDynamicFrameをDataFrameに変換しています。
なお、repartitionを実行するとデータの再配置が実施されるためデータ量によってはパフォーマンスに影響が出る恐れがあるため事前に検証しておくと良さそうです。
その他
- データソースなどのS3バケット名やGlueのDB名などは環境変数としてGlueのジョブパラメータで外から渡すように設定してます
- GlueではPythonとSparkに加えてGlue独自の
DynamicFrameの関数が利用できるため、上記例のtoDF()関数などを利用してSparkのDataFrameと相互に変換して柔軟なデータの加工処理が行うことができます
まとめ
AWS Glueはとても便利で強力なETLのマネージドサービスであることが分かりました。
今後本格的にAWS上でデータ分析基盤を構築する際は、AWS GlueやSpark等を活用していければなと思いました。