はじめに
理系大学生で現在修士2年生です。
専攻は情報系ですが、金融に関してはほぼ知識はないので勉強中です。
今回Smart Tradeでインターンすることになり、QuantXで機械学習を使ったアルゴリズムを開発しので、まとめてみます。
目標
・QuantX上で簡単な機械学習を試してみる。
作りたいアルゴリズムと方針
教師あり学習を使って、10日後の株価が現在の価格よりも「上がっているか(下がっているか)どうか」を予測するアルゴリズム。
大まかな手順
- 教師データの生成 → 今回は10日後の価格が上がっているかどうか
- 株価データから特徴抽出 → 今回はテクニカル指標を使用
- 学習
- QuantX上でバックテストと結果を可視化
完成したサンプルコードはこちら。
コードみながら読み進めてくれたらと思います。
また、QuantXの詳しい使い方についてはこちらを参照してください。
解説
手順に沿って、重要な部分だけ解説します。
0.準備
今回使用するライブラリ一覧
import numpy as np
import pandas as pd
import talib as ta
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
使用する銘柄と要素の選択。今回は日経225連動型上場投資信託と終値のみを使用。
(ここで扱う銘柄とか決めれます。)
ctx.logger.debug("initialize() called")
ctx.configure(
channels={ # 利用チャンネル
"jp.stock": {
"symbols": [
"jp.stock.1321", #日経225連動型上場投資信託
],
"columns": [
"close_price_adj", # 終値(株式分割調整後)
]
}
}
)
1. 教師データの生成
各時刻での10日後の価格との差分を計算し、上がってれば True、下がってればFalseを代入。
(ここで何日後の価格を予測するか、設定できます。)
# ここから手順1(教師データの生成)
# 教師データを入れる型を用意
y = pd.DataFrame(0, index = cp.index, columns = cp.columns)
y = cp.diff(-10) # ここで何日後を予測するかを決めれる
y = y['jp.stock.1321']<0 # True, Falseに変換
2. 株価データから特徴量を抽出
特徴量を入れるための型を準備します。(今回は適当に選びました。)
# ここから手順2(株価データから特徴抽出)
# 特徴量を入れるための準備
rsi7 = pd.DataFrame(0, index=cp.index, columns=["rsi7"])
sma14 = pd.DataFrame(0,index=cp.index, columns=["sma14"])
sma7 = pd.DataFrame(0,index=cp.index, columns=["sma7"])
sma7_diff = pd.DataFrame(0,index=cp.index, columns=["sma7_diff"])
sma14_diff = pd.DataFrame(0,index=cp.index, columns=["sma14_diff"])
sma_diff = pd.DataFrame(0,index=cp.index, columns=["sma_diff"])
bb_mid = pd.DataFrame(0,index=cp.index, columns=["bb_mid"])
bb_up = pd.DataFrame(0,index=cp.index, columns=["bb_up"])
bb_low = pd.DataFrame(0,index=cp.index, columns=["bb_low"])
bb_diff = pd.DataFrame(0,index=cp.index, columns=["bb_diff"])
mom = pd.DataFrame(0,index=cp.index, columns=["mom"])
上で用意した型に、はじめにimportしたtalib(テクニカル指標を計算してくれるライブラリ)を使って値を代入します。
talibに関してはこちらを参照ください。
for (sym,val) in cp.items():
rsi7['rsi7'] = ta.RSI(cp[sym].values.astype(np.double), timeperiod=7)
sma14['sma14'] = ta.SMA(cp[sym].values.astype(np.double), timeperiod=14)
sma7['sma7'] = ta.SMA(cp[sym].values.astype(np.double), timeperiod=7)
bb_up['bb_up'], bb_mid['bb_mid'], bb_low['bb_low'] =
ta.BBANDS(cp[sym].values.astype(np.double), timeperiod=14)
mom['mom'] = ta.MOM(cp[sym].values.astype(np.double), timeperiod=14)
先ほど求めた特徴量(テクニカル指標の値)を、意味のあるデータに変換してみます。
例えば、sma(単純移動平均線)の値自体には意味がないので、1つ前の値との差分をとってみました。(smaの傾き的なイメージ)
sma7_diff['sma7_diff'] = sma7.diff()
sma14_diff['sma14_diff'] = sma14.diff()
sma_diff['sma_diff'] = sma7['sma7'] - sma14['sma14']
bb_diff['bb_diff'] = bb_mid['bb_mid'] - bb_up['bb_up']
上で用意した特徴量を1つのデータフレームに統一。(学習するときに必要な形に変換)
# 特徴量の結合
df_x = pd.concat([rsi7, sma7_diff, sma14_diff, sma_diff, bb_diff, mom], axis = 1)
何が起きてるか分からない方は、コメントアウト外して実行してみると、イメージが掴めるかもしれません。
# ここで確認できるよ。
# ctx.logger.debug(df_x)
3. 学習
モデルの汎化性能を測るために、学習データとテストデータに分割します。今回は前半5割を学習データにします。shuffleは必ずFalseにして下さい。
(ちなみにQuantXは、(バックテストの期限+1年)分のデータを読み込んでいます。また現状では、バックテスト期間の最長は3年なので、一つの銘柄につき4年分のデータしか読み込むこどができません…。)
# ここから手順3
# 学習データとテストデータに分割(前半5割を学習データ,後半5割をテストデータ)
X_train, X_test, y_train, y_test = train_test_split(df_x, y, train_size=0.5,shuffle = False)
X_trainの中身を見て貰えれば分かるのですが、最初のn行には値が入っておらずNANになっています。
これは各時刻で指標を計算するとき、過去のn日分のデータを使用します。ですので、最初のn行は指標を計算する過去データがないため、NANになります。
学習をする際、このデータが混じっているとエラーになってしまうので消しときます。
(今回の場合でいうと、手順2でテクニカル指標を計算する際、最大過去14日分のデータを使ったので、nは14になります。)
# はじめのNAN削除
X_train = X_train[14:]
y_train = y_train[14:]
最後に学習データを使ってモデルを学習します。
今回はランダムフォレストを使いましたが、色々試してみるといいと思います。(パラメータもいじってみてください。)
# 学習データを使って学習(モデルはランダムフォレスト)
clf = RandomForestClassifier(random_state=1, n_estimators = 300,
max_leaf_nodes = 10, max_depth=6, max_features=None, min_samples_split = 0.15)
clf = clf.fit(X_train, y_train)
4. 予測
最後に学習したモデルを使って、テストデータに対して予測しています。
QuantX上でバックテストを行う場合、初めに読み込んだ「cp」とインデックスを合わせないとエラーになってしまいます。ですので「test」にはテストデータに使ったデータと手順3で取り除いだNANの分のsignalを用意します。(全てFalse)
これに予測したpredを結合し、QuantX上でエラーを出さない形に変換します。
# ここから手順4
# テストデータを使って予測
pred = clf.predict(X_test)
# signalのインデックスを合わせる
test = np.ones(len(X_train)+14, dtype=np.bool) * False
signal = np.hstack((test, pred))
signal = pd.DataFrame(data = signal, columns=cp.columns, index=cp.index)
注文方法の設定
最後に注文の設定をします。
今回はTrueと予測した時に、50%ポジション持つように、Falseと判断した場合はポジションを解消するようなルールにしました。
def handle_signals(ctx, date, current):
'''
current: pd.DataFrame
'''
# 1321を取引するため
bull = ctx.getSecurity("jp.stock.1321")
# シグナルを取得
signal = current["signal"][0]
if signal == True:
bull.order_target_percent(0.5, comment="BULL BUY")
else:
bull.order_target_percent(0, comment="BULL SELL")
結果
QuantXファクトリー上で左上のテストをおし、期間を決めることで簡単にバックテストを行い、画像のように結果を可視化してくれます。
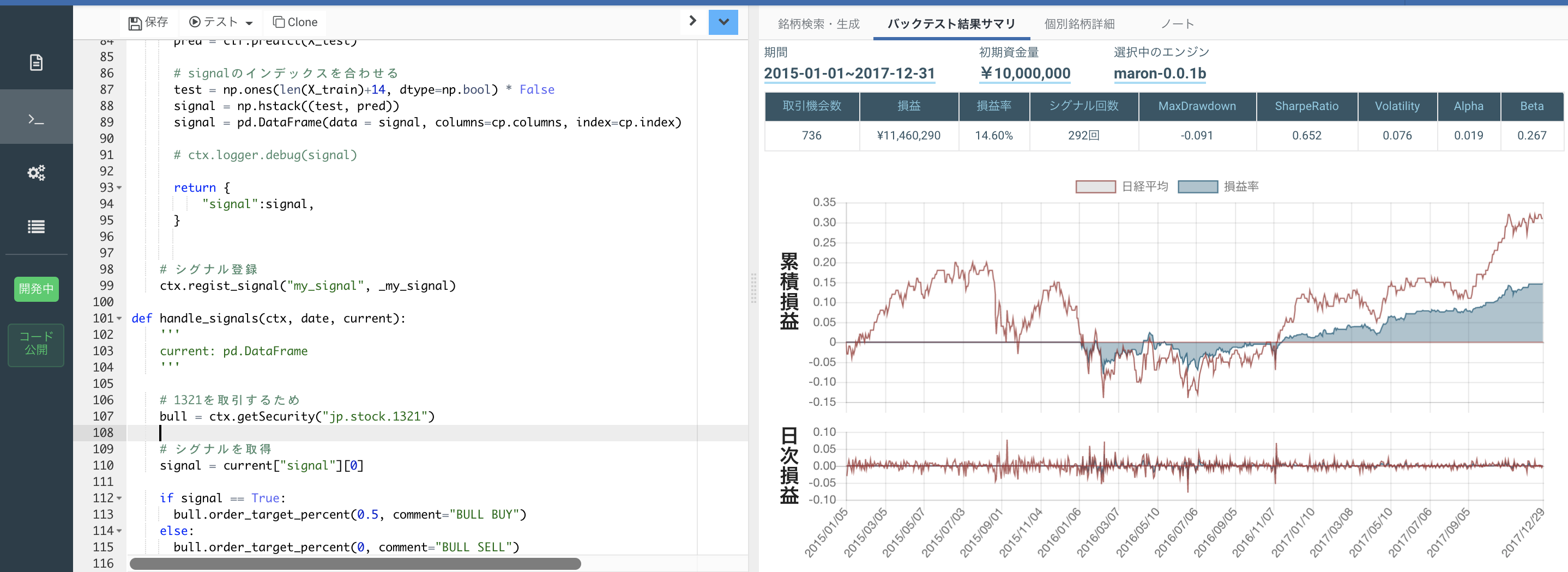
今回の結果は、日経平均と同じような動きをしているので、いいモデルとはいえません。
改善案
最後に今後の改善点をいくつか挙げます。
手順1. 問題設定 (何をラベルを何にするか?)
⇨ 例えば10日後に2%以上上昇したらTrueとか…。
⇒ そもそもの売買条件をルールベースで絞り込むんで学習
手順2. データの整形(何を使って予測するか?)
⇒ ここを頑張る!
手順3. モデルを使って学習
⇒ 時系列データを扱えるアルゴリズム(LSTMとか)。ただ、QuantX上でやるのは微妙かも…。
最後に
最後まで読んでいただきありあがとうございました。
今回はとりあえず機械学習使ってみようって感じで作った物ですので、今後はもっと頑張って作ってみます。
記事に関する誤った知識がごいざいましたらご指摘よろしくお願いします。