はじめに
機械学習を勉強し始めましたので、Kaggleの初心者向けTitanicチュートリアルをやってみました。
kaggleでコンテストの詳細とフローを学び、最初の提出を行いました。
Challenge
Titanicの乗客データ(name, age, price of ticket, etc)を使用して、誰がSurvived、誰がDeadかを予測する
Data
データには、3つのファイルがあります。
(1)train.csv、
(2)test.csv
(3)gender_submission.csv
(1) train.csv
891 passengers詳細データ、
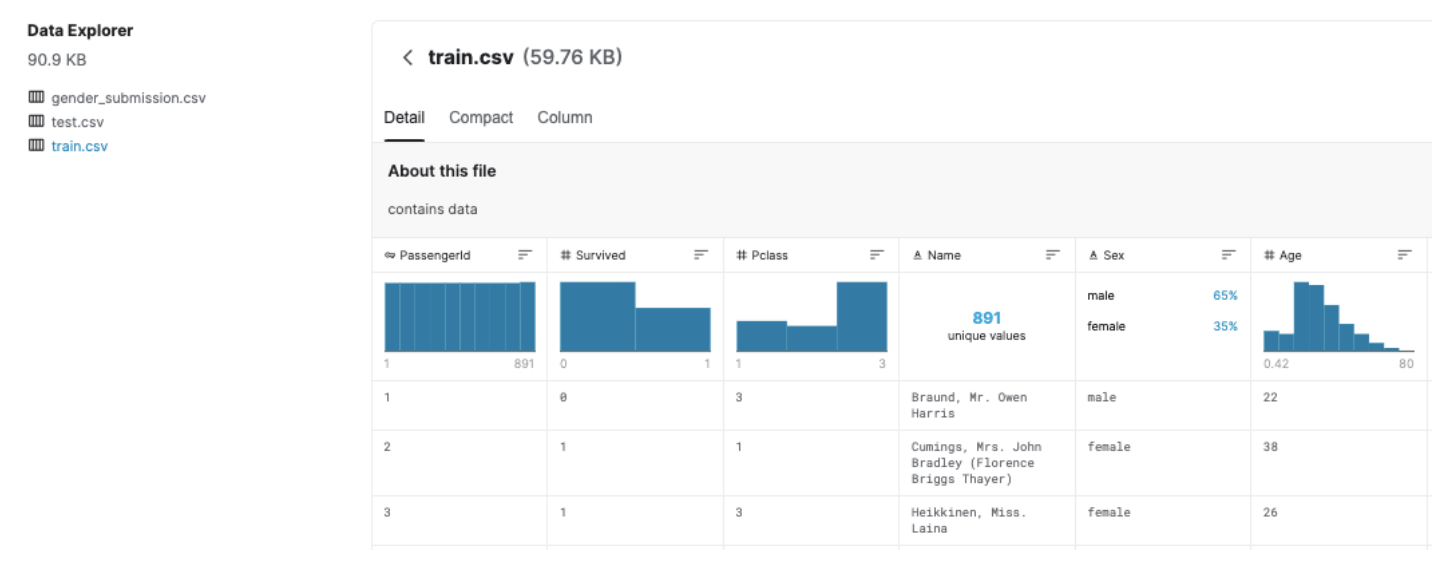
Survivedカラムの値で、aliveかdeadの判断できるデータ。
1の場合, survived
0の場合, dead
(2) test.csv
上記のtrain.csvファイルで見つけたパターンを使用して、test.csv内の他の418人の乗客がSurvivedかどうかを予測する。
test.csvファイルにはSurvivedカラムがないです。
(3) gender_submission.csv
予測をどのように考えるかの例です。
この例で、すべての女性の乗客→Survived、すべての男性の乗客→Deadことを予測しています。
PassengerIdとSurvivedのカラムMUSTで入ってれば、違う予測を考えても良いです。
Code
ここで予測を改善するために、機械学習モデルをトレーニングします。
コードを実行するために好きのnotebookを使う,私kaggle notebookを使ってました。
・kaggle notebook/jupyter notebook/google colab
・データが保存されている場所が示される
・データをロードする
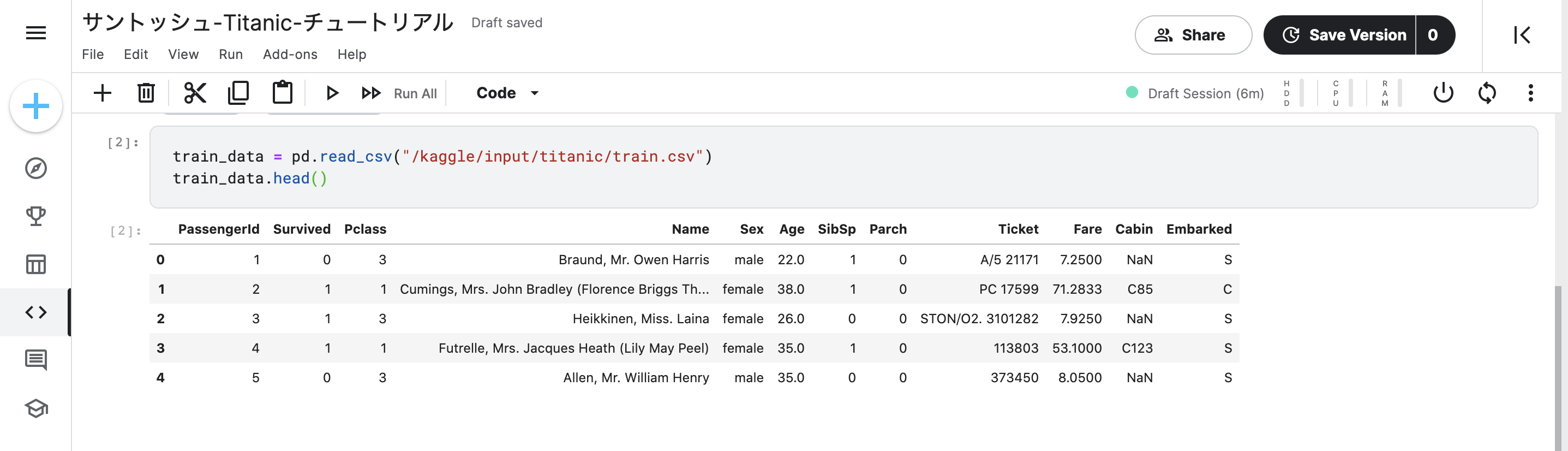
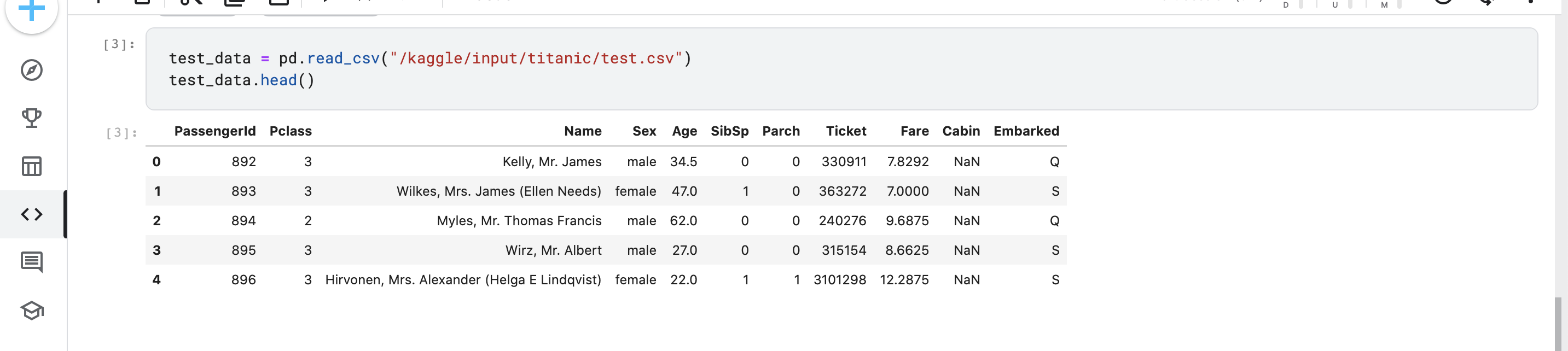
- ↑head()で最初の5行しか表示されない
GOAL:
test.csvの乗客がSurvivedかどうかを予測するのに役立つtrain.csvのパターンを見つけたい!
pattern探し
今回は、一番最初に例としてもらった、パターンを使います。
gender_submission.csv、(Assume)
・すべての女性の乗客 → Survived
・すべての男性の乗客 → Dead
このパターンがtrain.csvデータに当てはまるかどうかを確認する
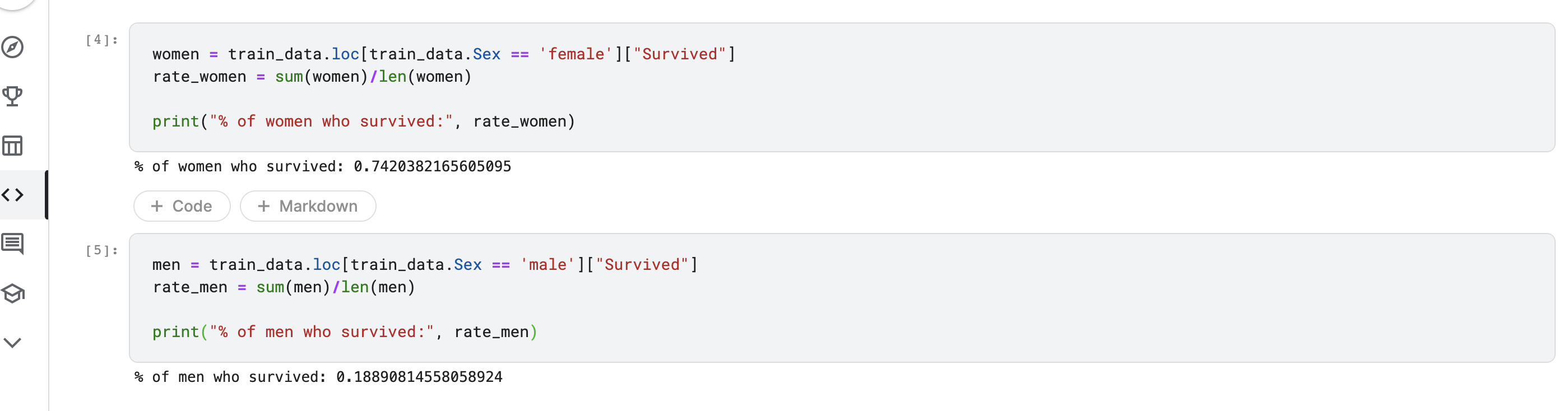
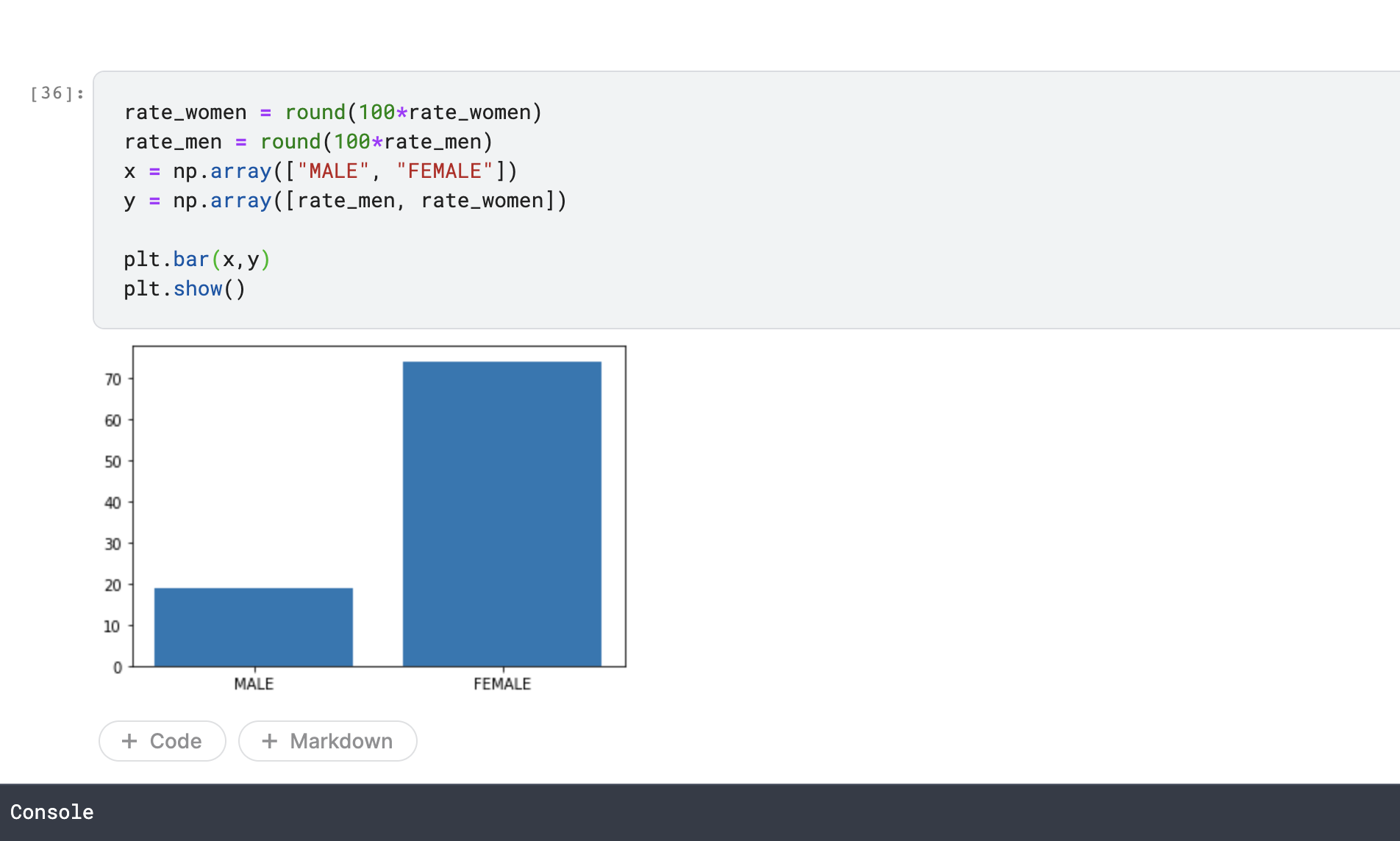
上記の結果を見ると、75%女性の乗客がSurvived
一つのカラムのみで予測するのも中々難しいので、色んなカラムを使ってmachine learning modelでやる。
最初の機械学習モデル
random forest modelをbuildする
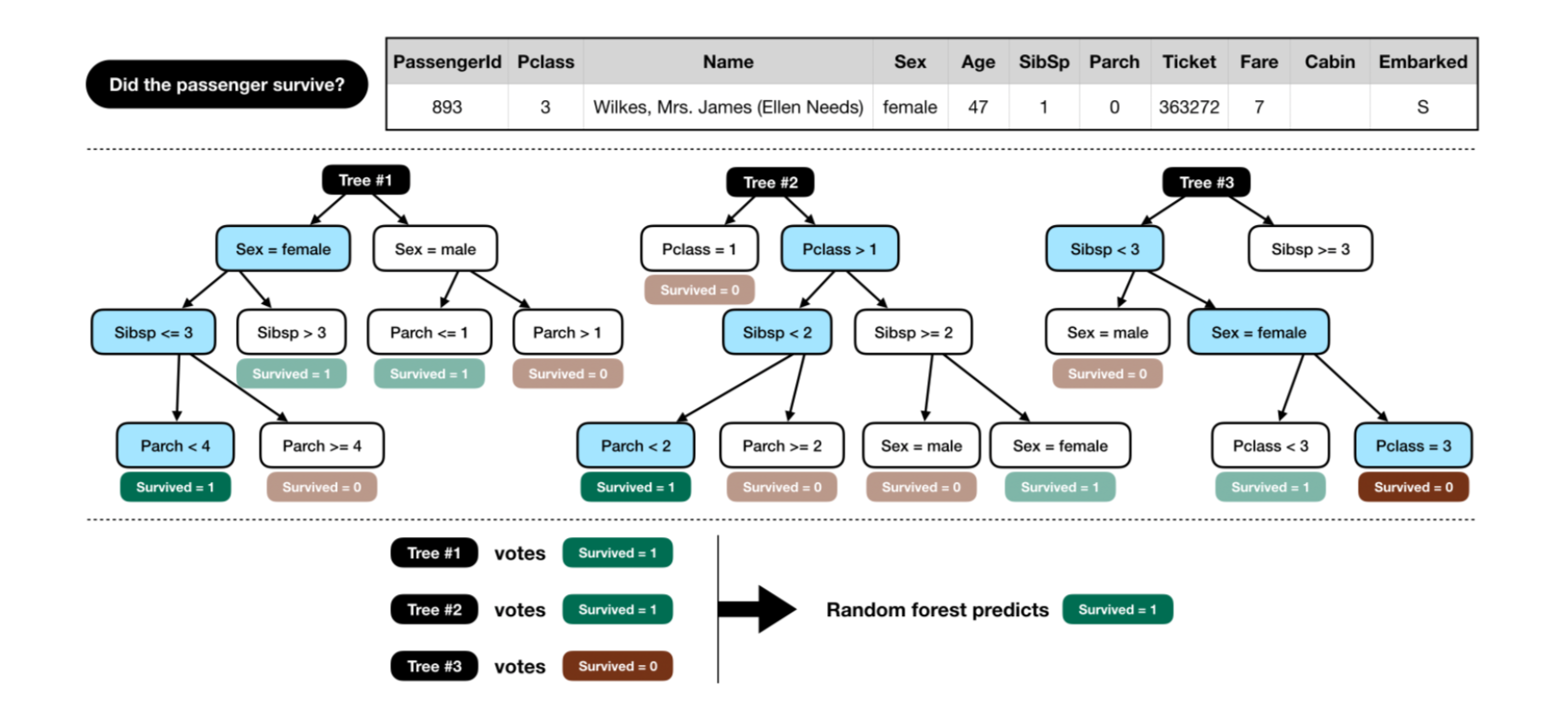
データの以下のカラム、"Pclass", "Sex", "SibSp", and "Parch"でパターンを検索するモデルです。
train.csvのパターンに対して、random forest modelでtreeを作成し、test.csvのデータに対してpredictionsする。(->submission.csv)
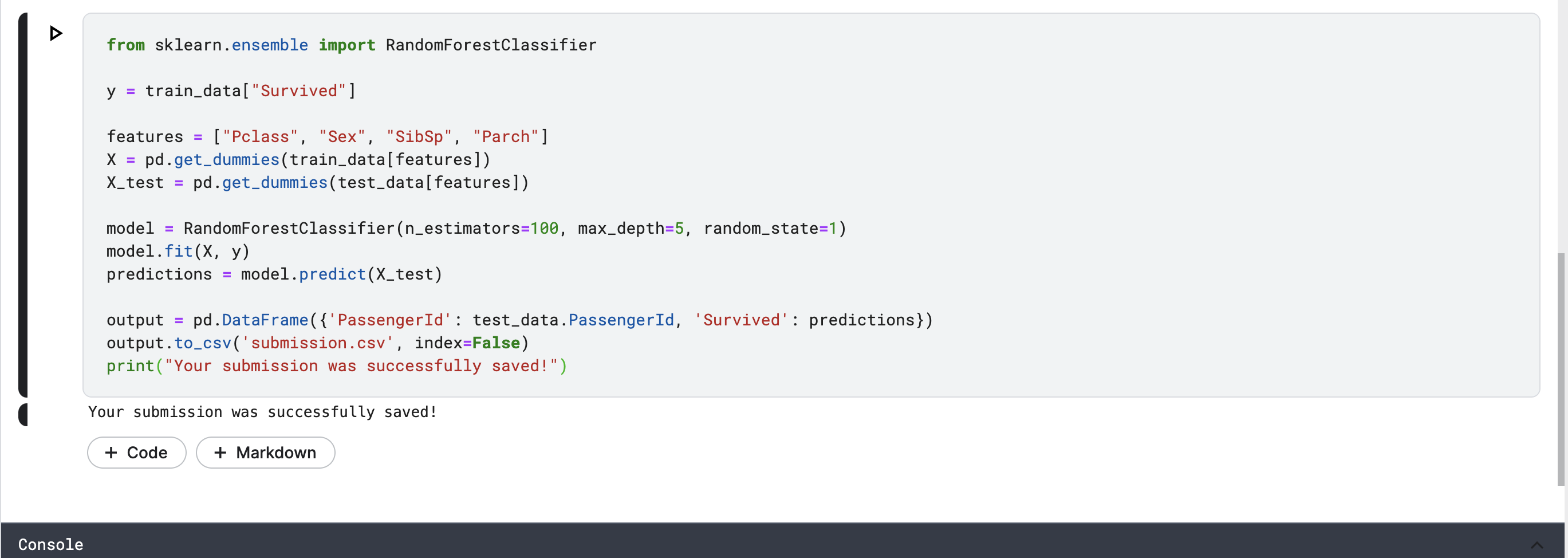
結果:
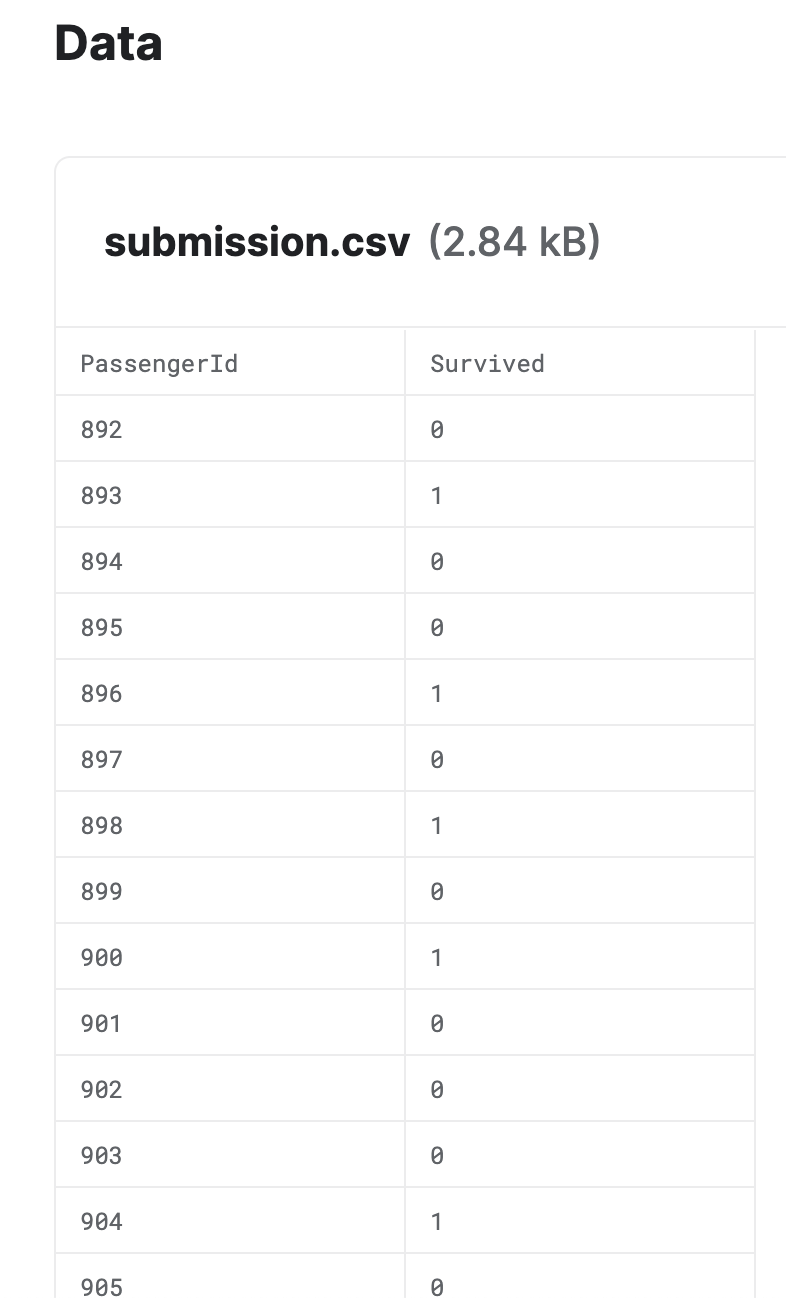
- 上記のデータの詳細を確認方法、グラフ化表示
-
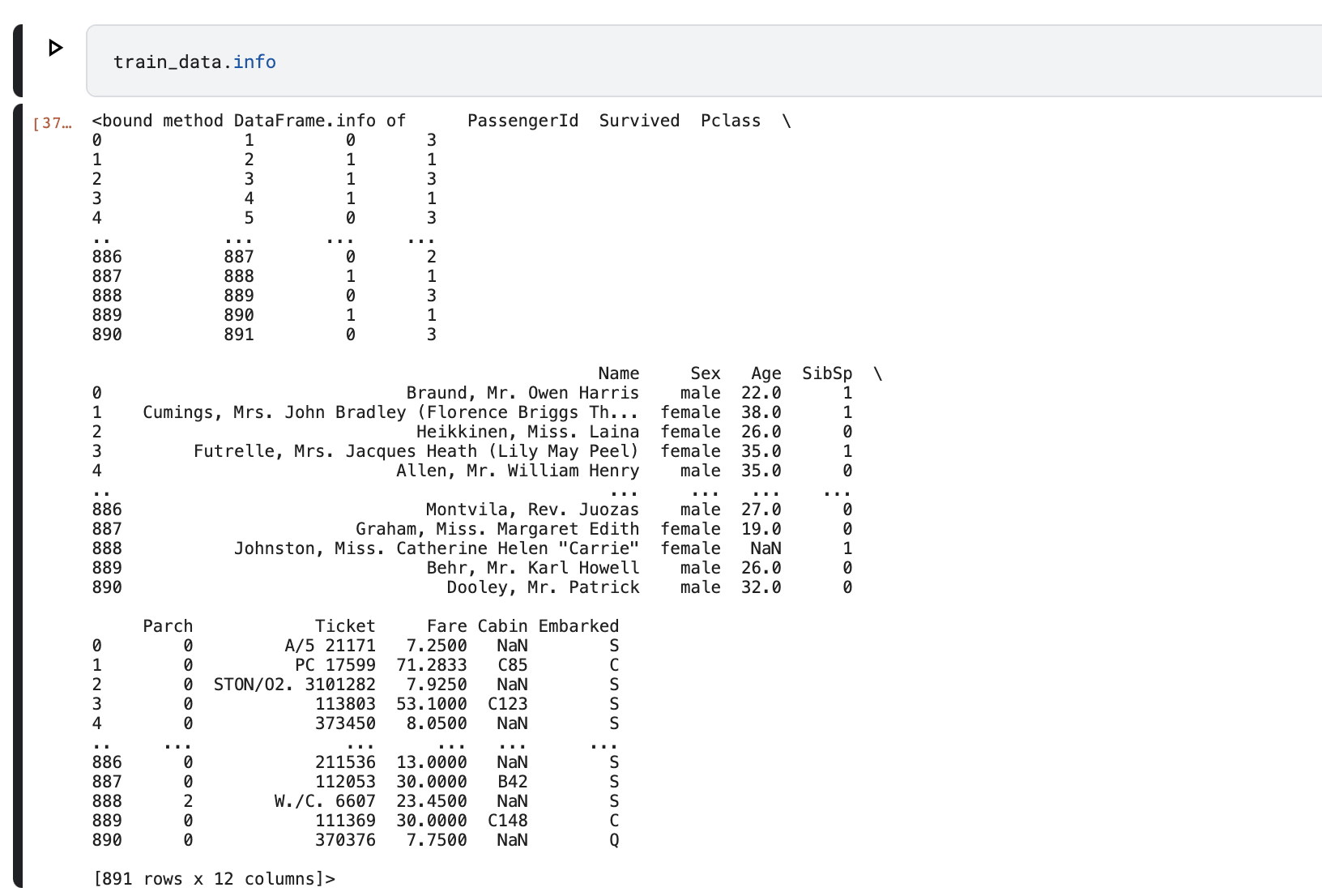
train_data.info を実行するとファイルの詳細確認できる
-
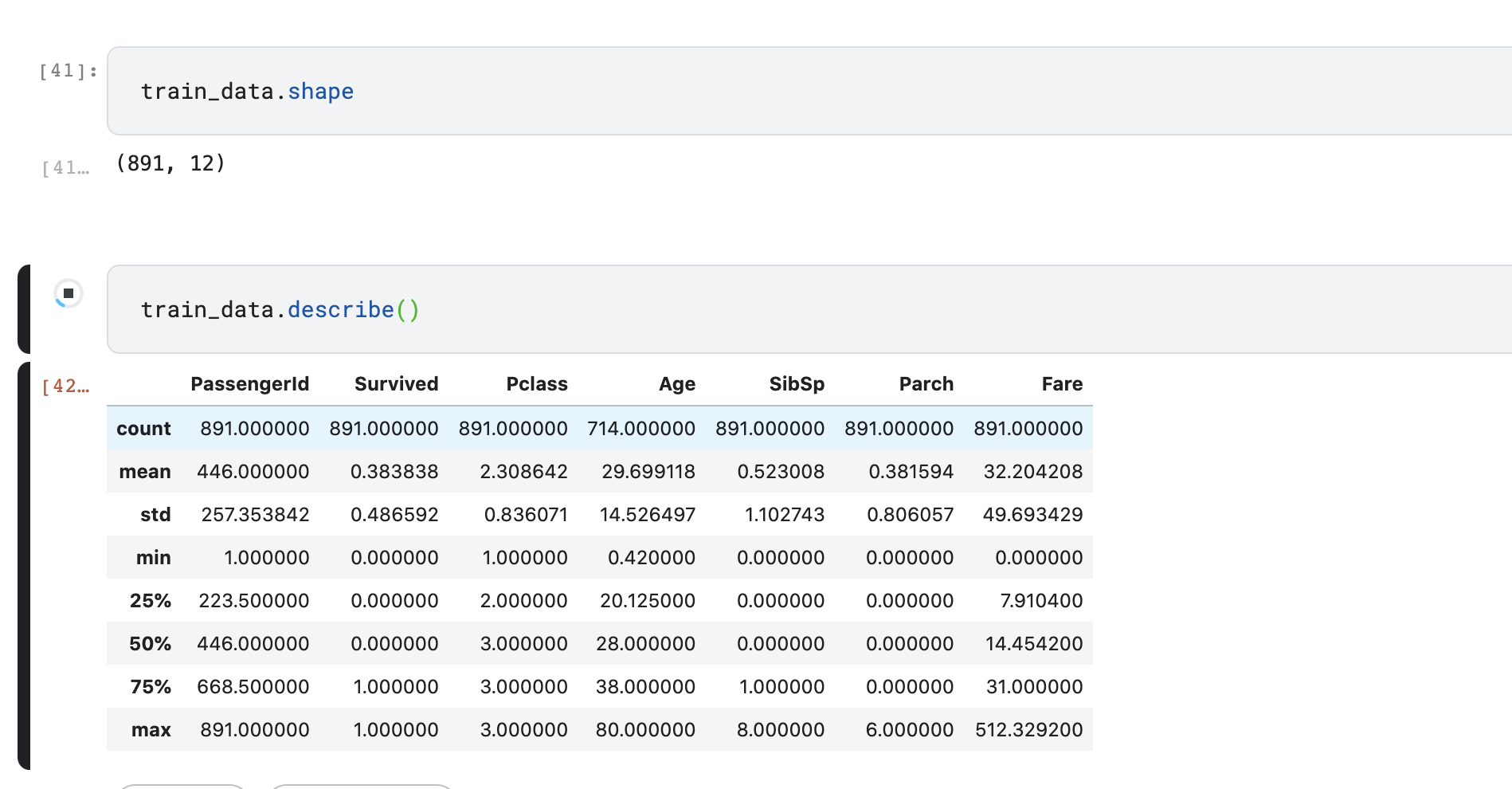
shape、describeでレコード数と形を確認
-
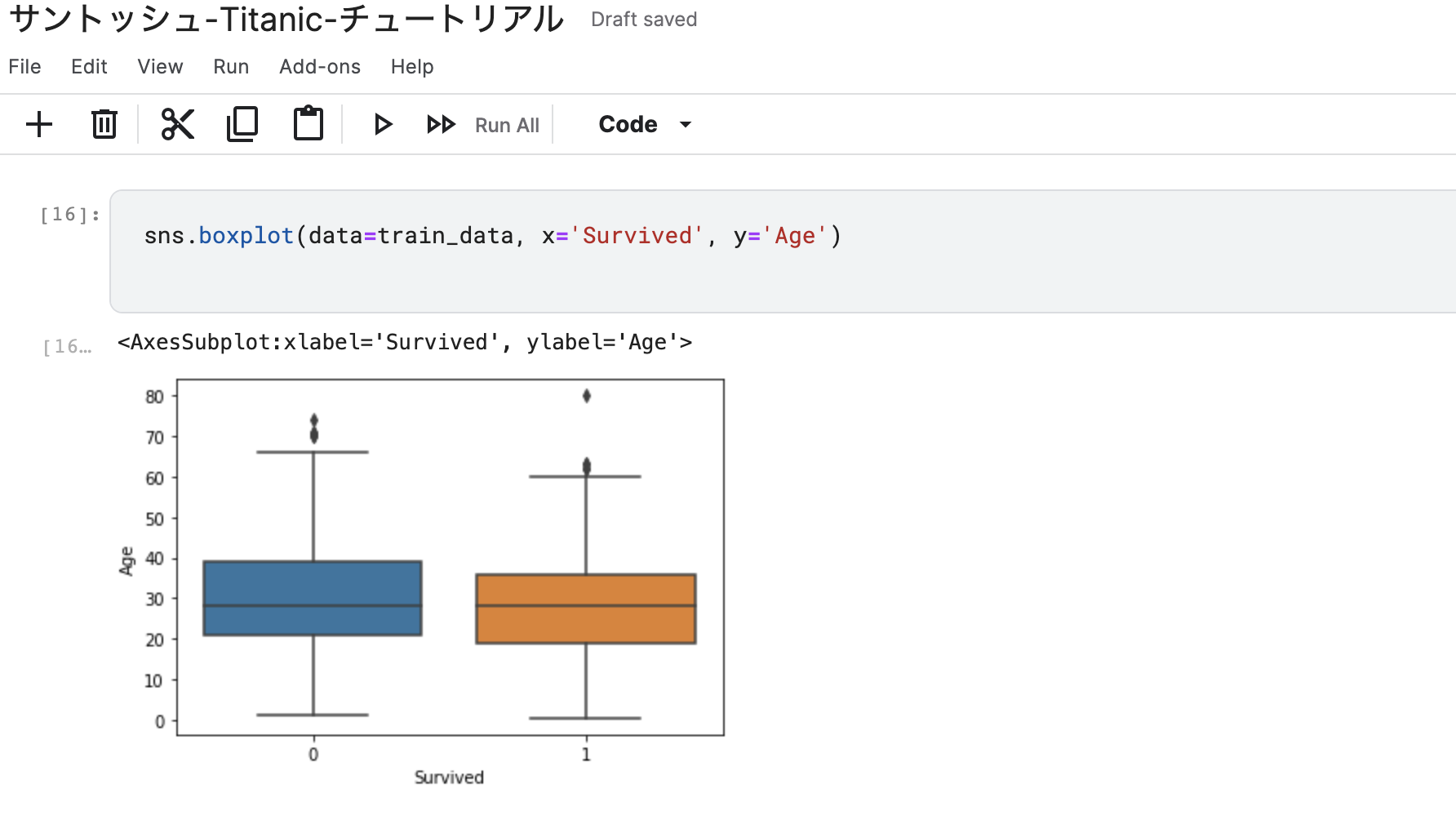
最後にmatplotlib、seabornを使って結果をグラフ化にしてみました。
-
1回目の勉強ここまででした。
機械学習、モデルなどを勉強中です↓。次のtopicも勉強終わったら記事にまとめます。
https://www.kaggle.com/learn/intro-to-machine-learning
参考:
https://www.kaggle.com/
https://www.geeksforgeeks.org/random-forest-classifier-using-scikit-learn/
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.head.html