こんなことをやってみた
警察庁がオープンデータとして公開している「交通事故統計情報(参照リンク)」のデータをQGISで読み込んで、DBSCANで交通事故の密集箇所を特定しました。
さらに、その箇所の集計情報を円グラフで可視化しました。
「この交差点はこんな事故が多い」といった考察に役立つ(はず)
QGISについて
QGIS(参照リンク)はオープンソースの地理情報システム(GIS)ソフトウェアです。
地理情報データの作成や加工・変換、可視化、分析処理に関する様々な機能が実装されています。
なお、今回の記事で私が使用しているバージョンは「3.28 Firenze」です。
カッコつけて英語表記のUIで使っているため、ツール名などは適宜日本語に置き換えて読んでください。
DBSCANについて
DBSCANはDensity-based spatial clustering of applications with noiseの略で、点密度に基づくノイズ(外れ値)ありの空間クラスタリング手法です。
大雑把にいうと、点が密集している箇所を特定してグループ分けする手法です。
QGISでのDBSCANの実施手順
データを用意する
今回は、警察庁のオープンデータ「交通事故統計情報(参照リンク)」の 2019年〜2022年の4年間 の情報をGIS用に独自加工したデータセットから、千葉県のデータを使います。
使用データはこちら(GitHubへのリンク)にて都道府県別のGeoPackage形式で格納してあります。
QGISで読み込む
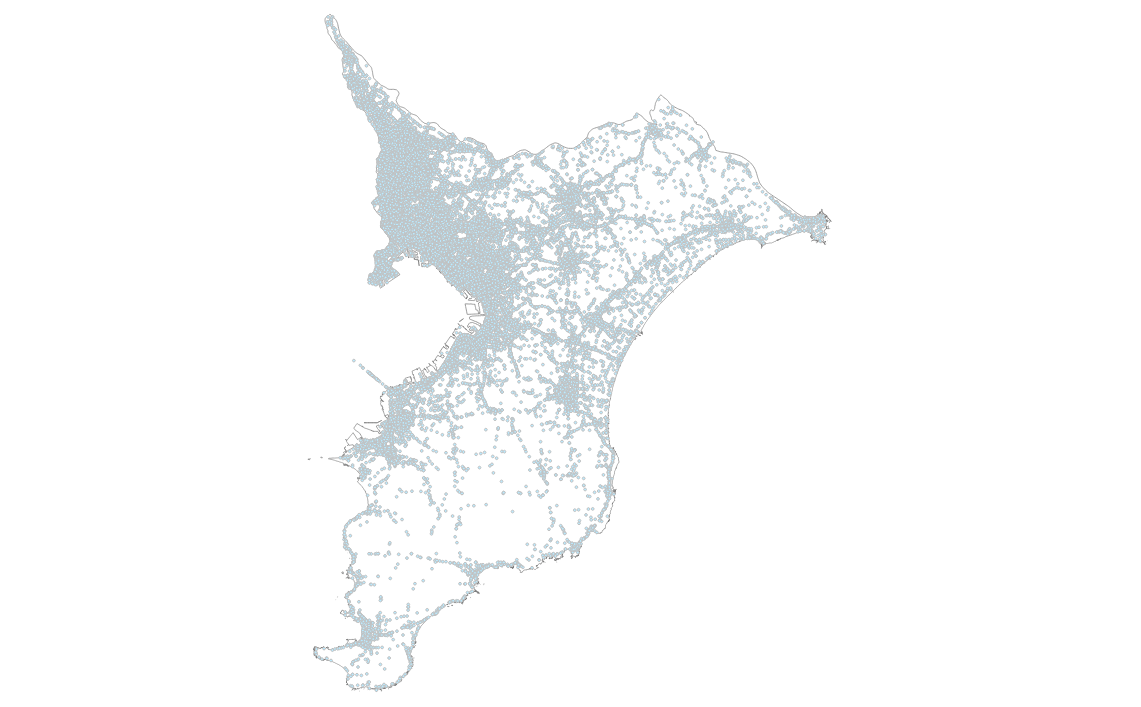
GeoPackage形式で加工してあるので、QGISにそのまま読み込めます。
ただし、上記のデータはEPSG:4326で加工してあるので、座標参照系は適宜変換してください。
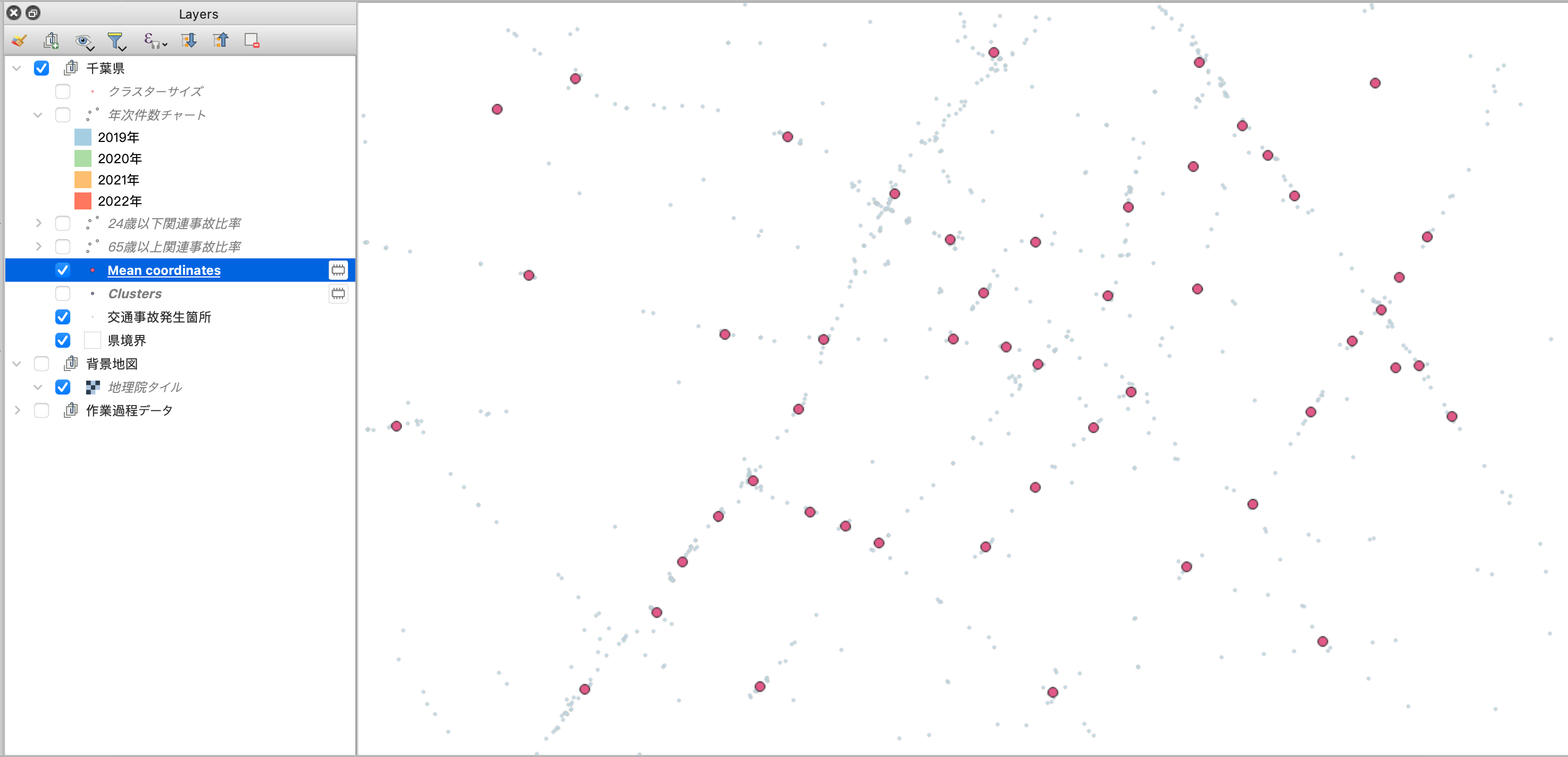
見ての通り、交通事故が起こった箇所が地図上に大量に分布しています。
DBSCANの処理を実施
QGISでDBSCANの処理を実行する場合、ツールボックスで「DBSCAN」と検索すると、「DBSCAN clustering」というツールが出てきますので、ここから設定に移ります。
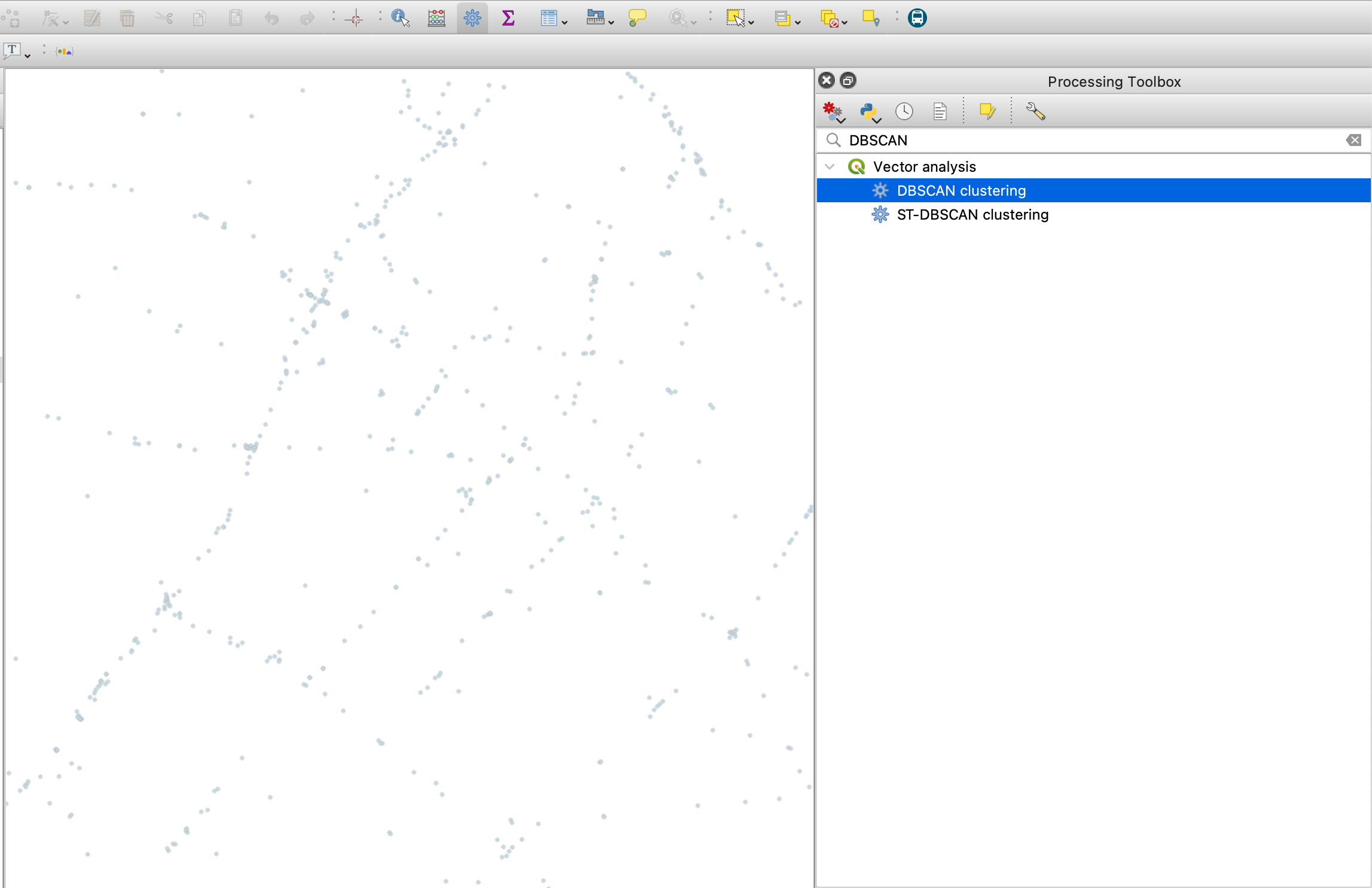
「ST-DBSCAN clustering」というのも出てきますが、これは時間を考慮してクラスタリングできるアルゴリズムのようです。まだ試したことないので気になります。
さて、気を取り直してDBSCANの設定画面を見てみましょう。
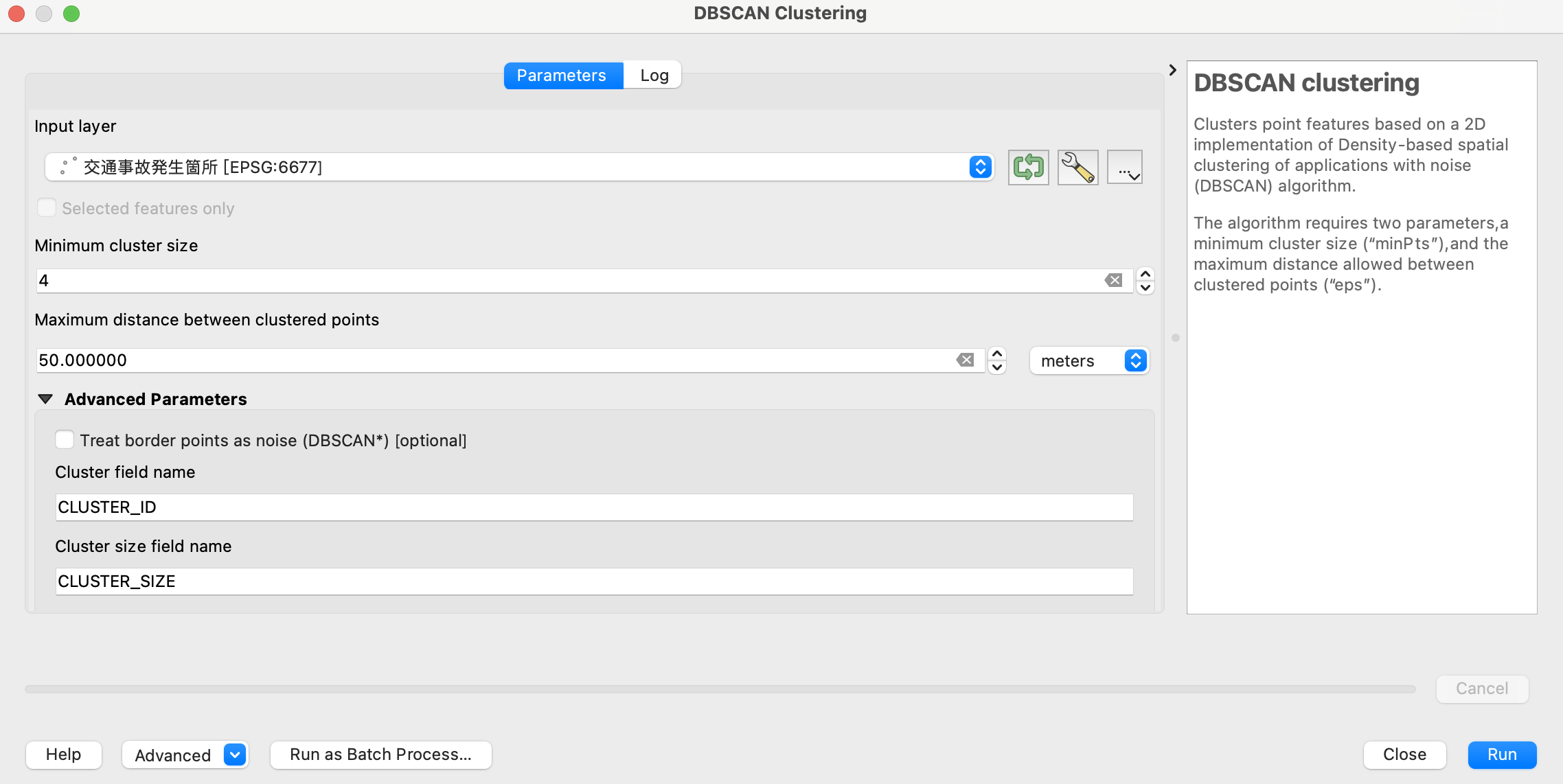
対象とするレイヤ(ポイントデータ)を選択したら、その後の基本的な設定項目は2箇所です。
「最低限のクラスタサイズ」と「最大範囲」を設定します。
ざっくりした説明になりますが、最低限のクラスタサイズは「最小で何件集まっていればクラスタとみなすか」、最大範囲は「最大で何メートルまでの範囲を1グループのクラスタとして判定するか」という閾値になります。
今回は、それぞれ4件(年平均1件以上)、50m(それ以上の連なりは別クラスタとして分ける)に設定しました。この設定は手動なので恣意性が入ります。
実行するとこのような状態になります。

「あれ、元の点データと一緒じゃない?」と思いますが、その通りです。
注意点として、この時点では入力された点の属性情報にクラスタIDが振られている状態で出力されるので、見た目は元のポイントデータと一緒になります。
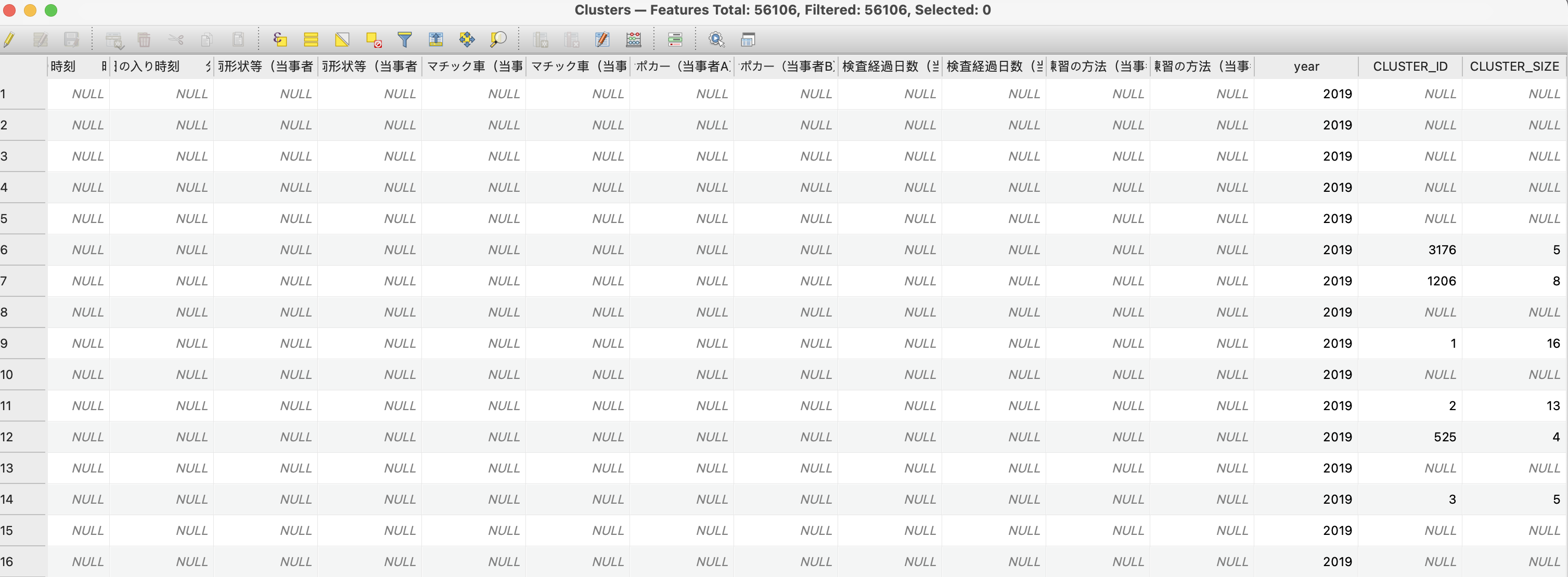
属性テーブルの右端をみると、クラスタIDとサイズ(同一クラスタに分類されたポイントの数)が格納されていることがわかります。
また、ここがNULLになっているものは、外れ値(どのクラスタにも属さなかった点)となります。
密集箇所を割り出す
次に、密集箇所を特定するため、クラスタの中心点を割り出してみましょう。
まず、ベクター解析のメニューから「Mean Coordinates」を選択します。
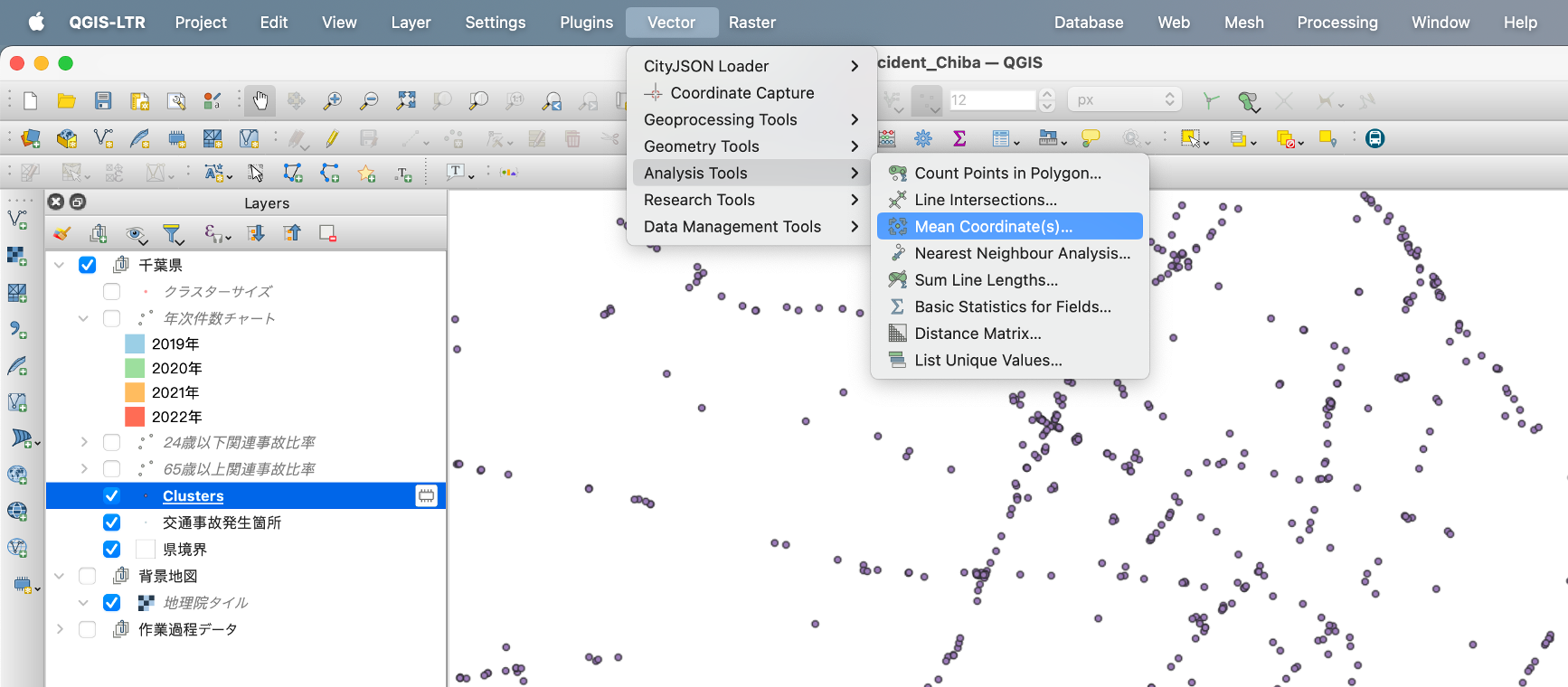
「Mean Coordinates」、つまり中心点を割り出すためのダイアログが開くので、入力レイヤにクラスタリングした点データを設定し、さらにオプション項目の「Unique ID field」に"CLUSTER_ID"を設定します。
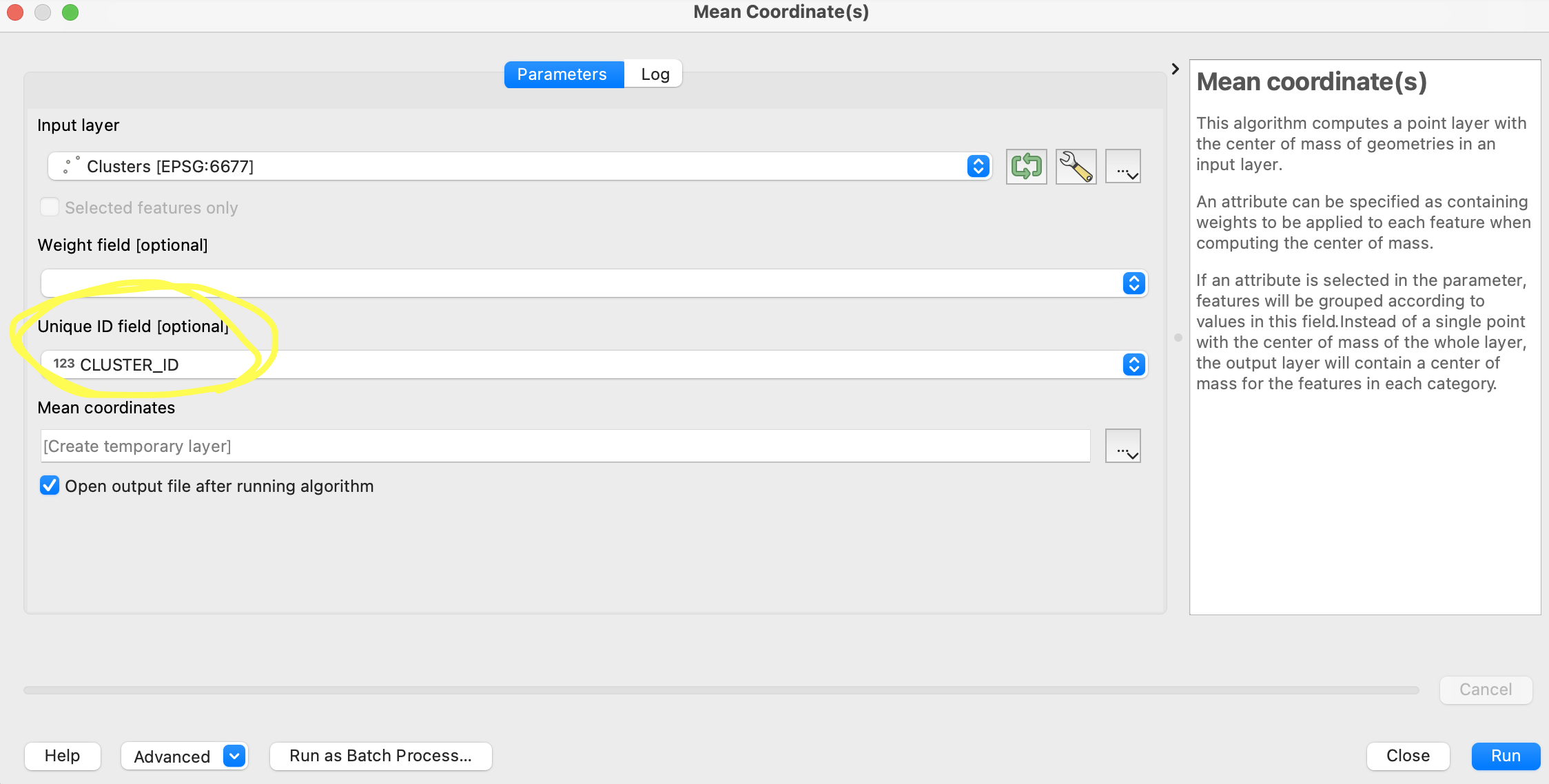
その結果、このような形で各クラスタの中心点が割り出されました。
ただし、この時点では、この「Mean Coordinates」の属性データには"CLUSTER_ID"しか入っていません。
だんだんイライラしてきました。全部一発で出来ればいいのに。
落ち着いていきましょう。
密集箇所の集計情報を整理する
次に、このクラスタ中心点に、クラスタごとの集計データを格納していきます。
ここはもう少し効率的な手法があるかもしれませんが、現状は数ステップに分けて実施しています。
クラスタIDごとの件数集計
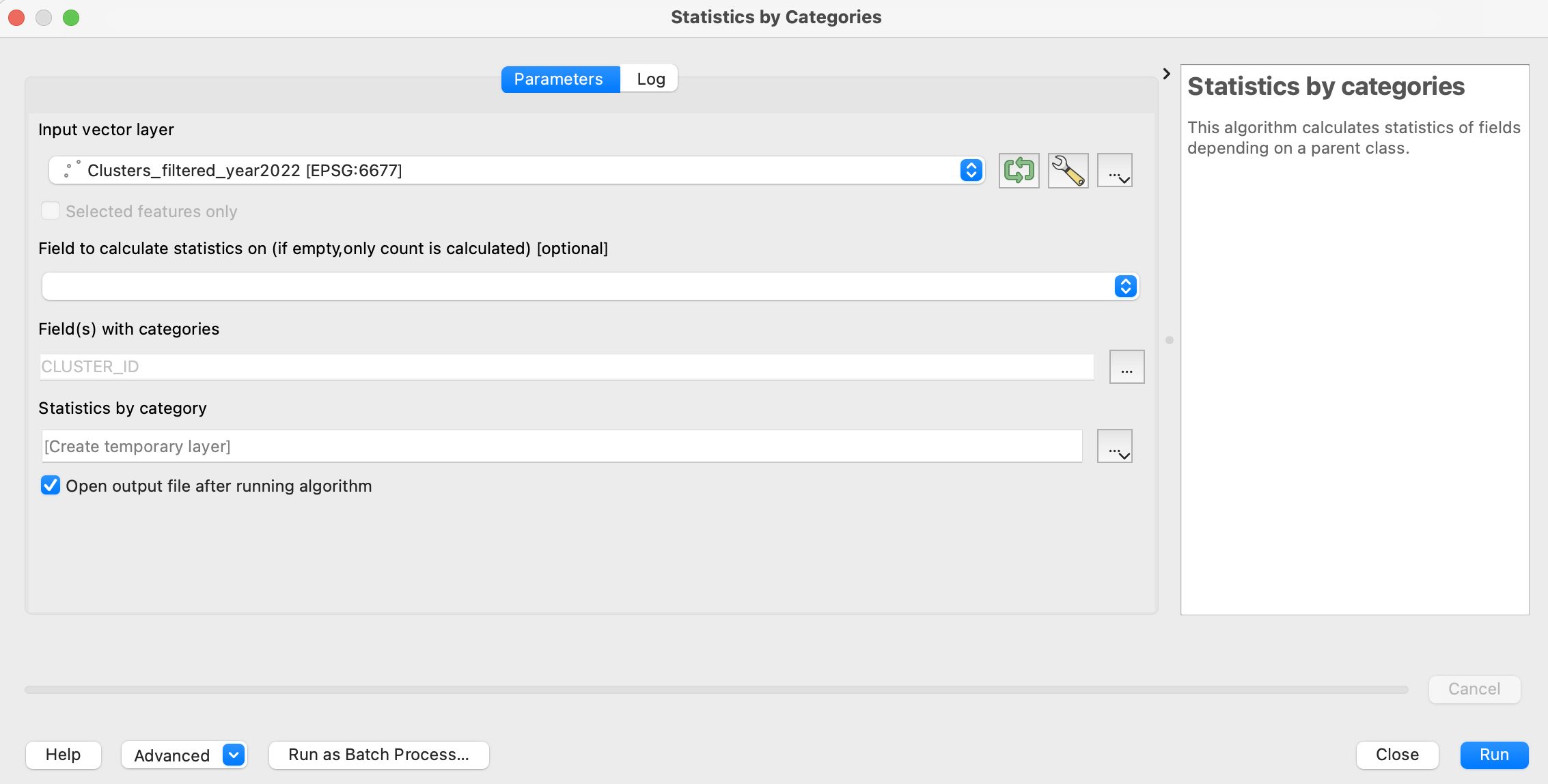
ツールボックスにて"Statistics by categories"を検索して選択します。
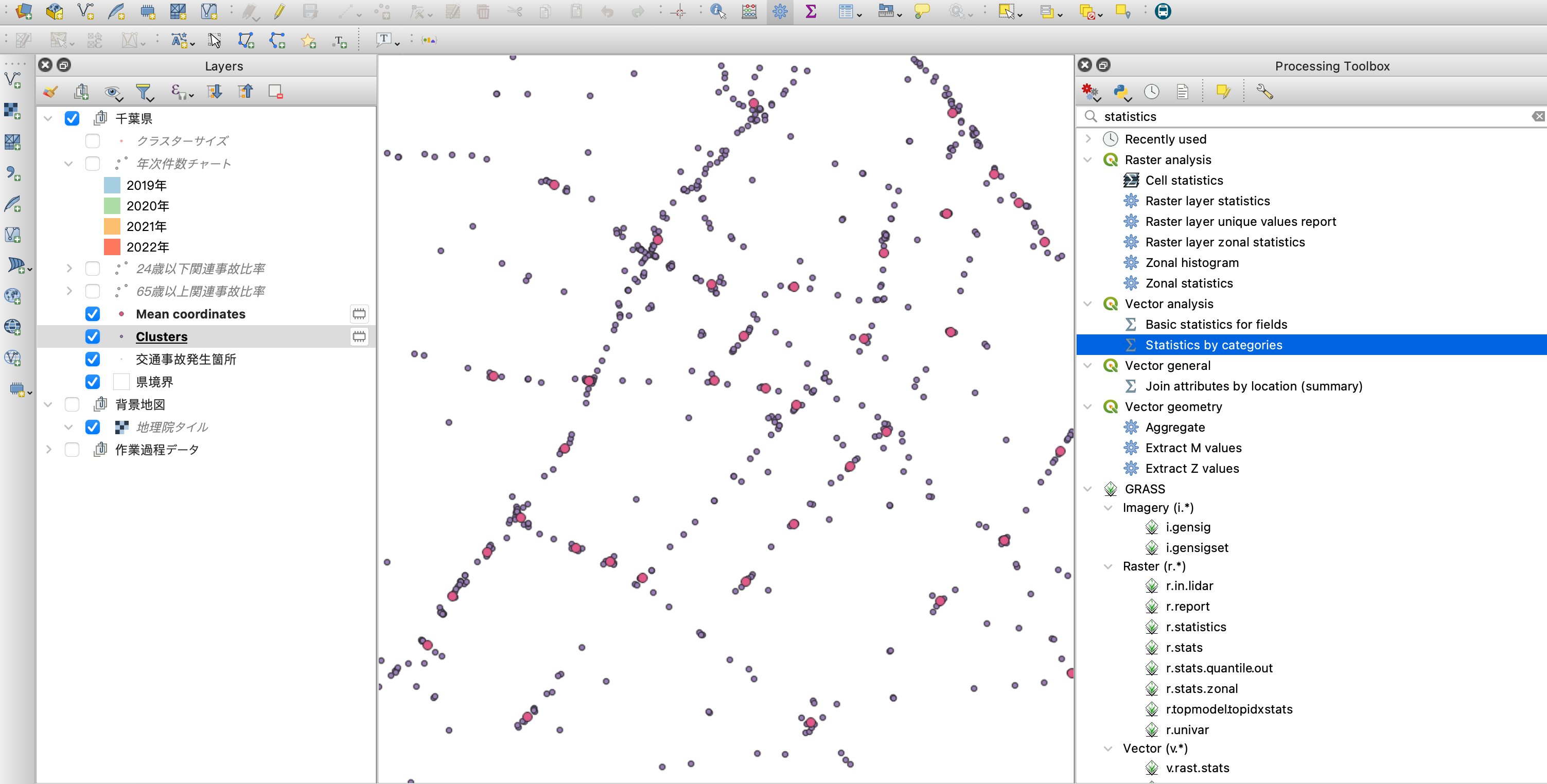
このツールは、分類ごとに特定の項目の数値を集計した表を出力します。
集計対象項目(下図2行目のセレクトボックス)を空のままにすれば、単純に分類ごとの合計件数をカウントしてくれます。
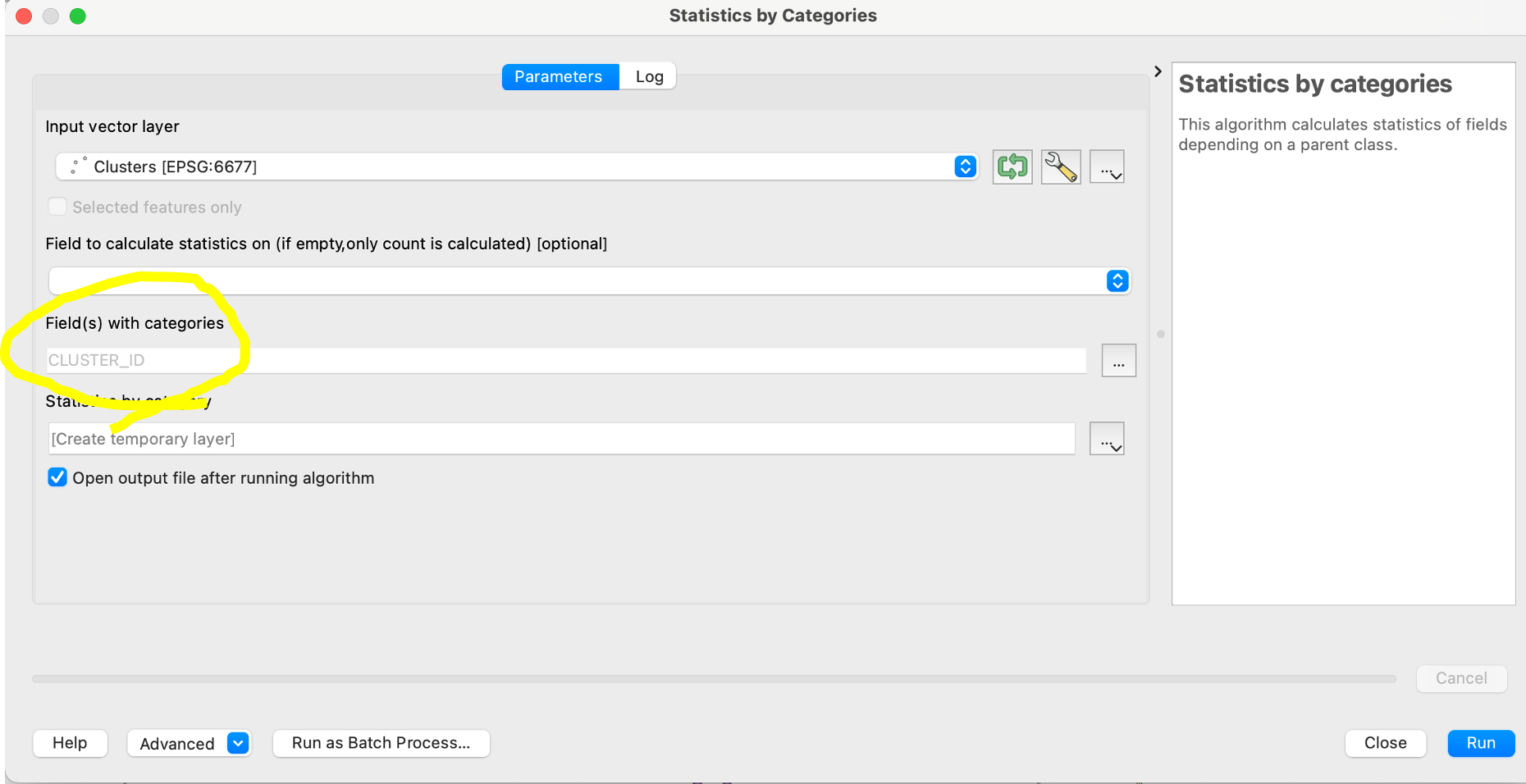
対象となる分類の項目は、下図の黄色線箇所のように「CLUSTER_ID」を設定しておきます。
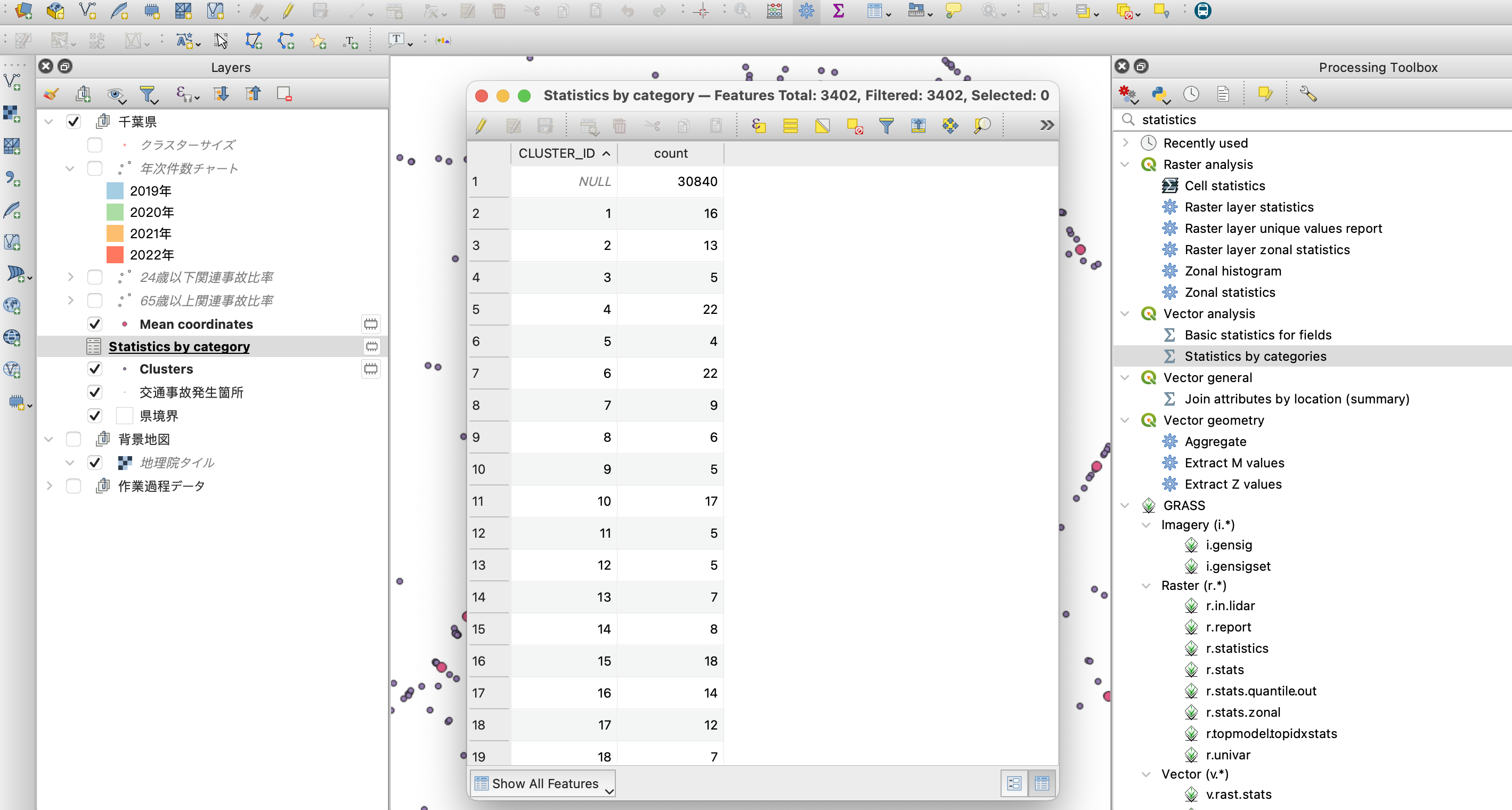
出力結果を確認すると、このようにクラスタIDと件数の対照表が見れます。
クラスタの点データと集計情報の紐付け
それでは、「Mean Coordinates」で生成した密集箇所(クラスタ)の点データと、集計情報を紐付けます。
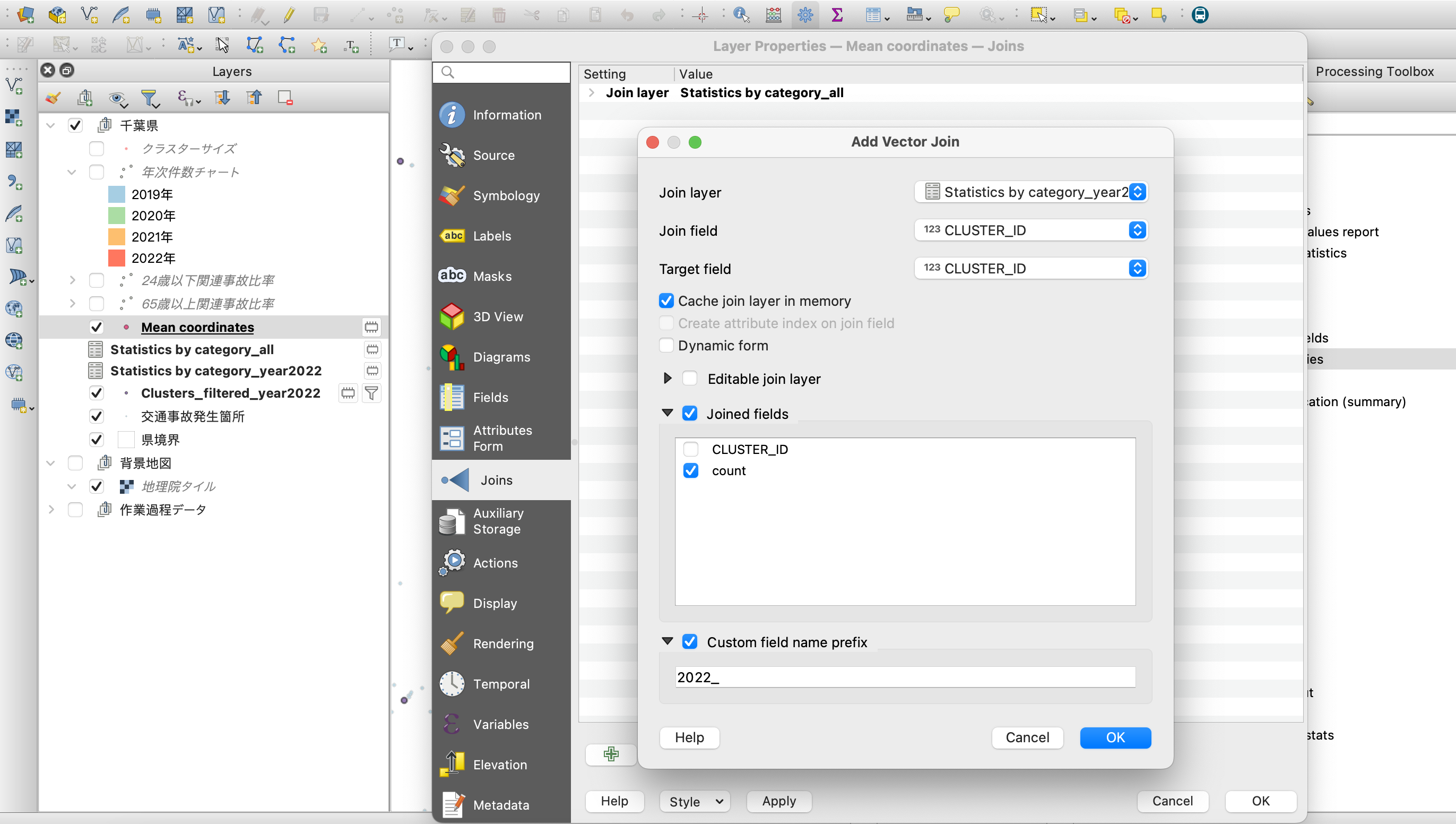
両方ともクラスタIDの項目を持っているので、「Mean Coordinates」で生成したレイヤを右クリックしてプロパティのダイアログ画面を開き、その中の「Joins」にて属性項目を結合します。
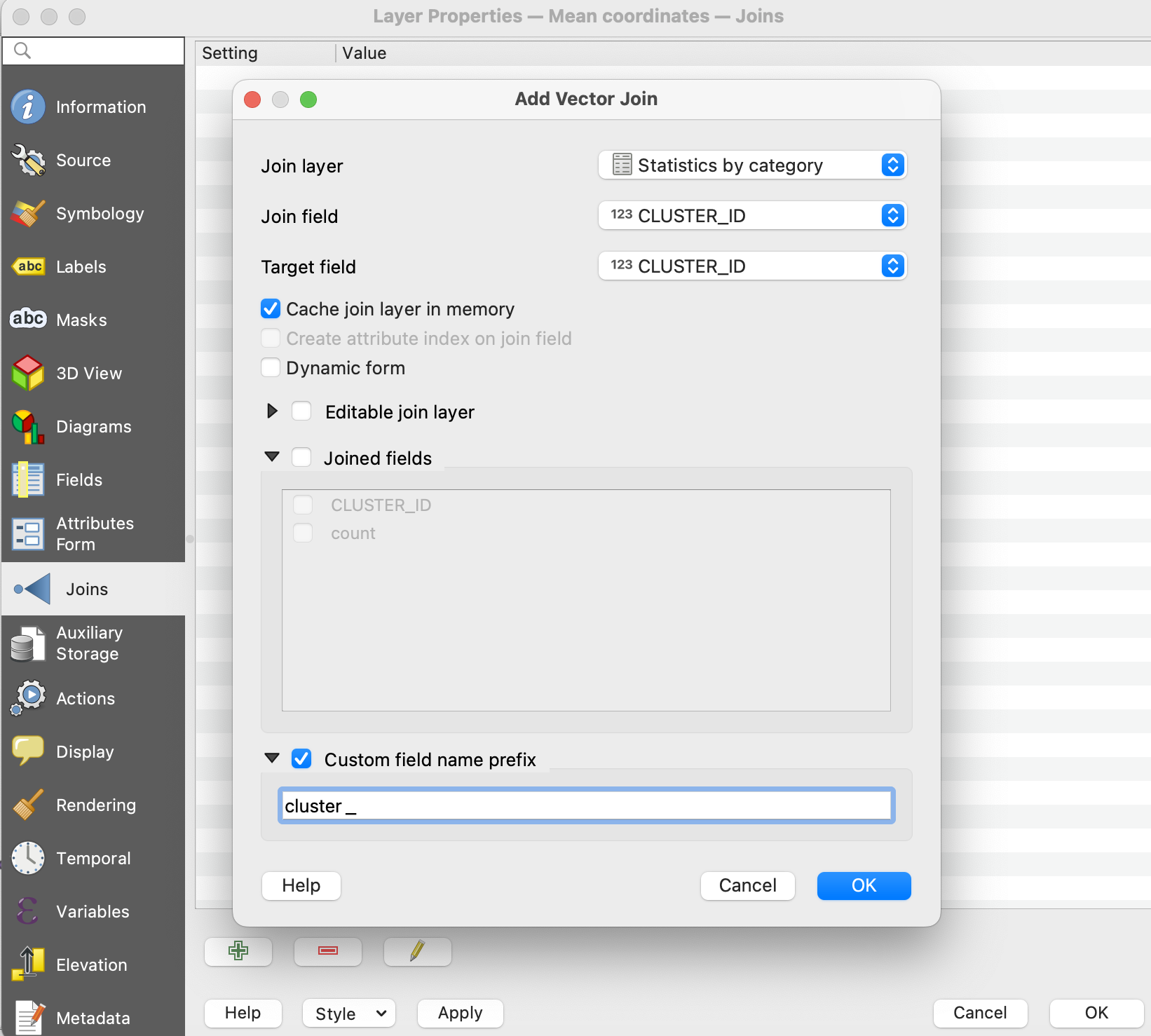
設定の方法は上図を参考にしてください。重要なのはお互いの”CLUSTER_ID”をキーとするくらいで、属性名のPrefix(接頭文字)などは適宜わかりやすいように設定すればOKです。
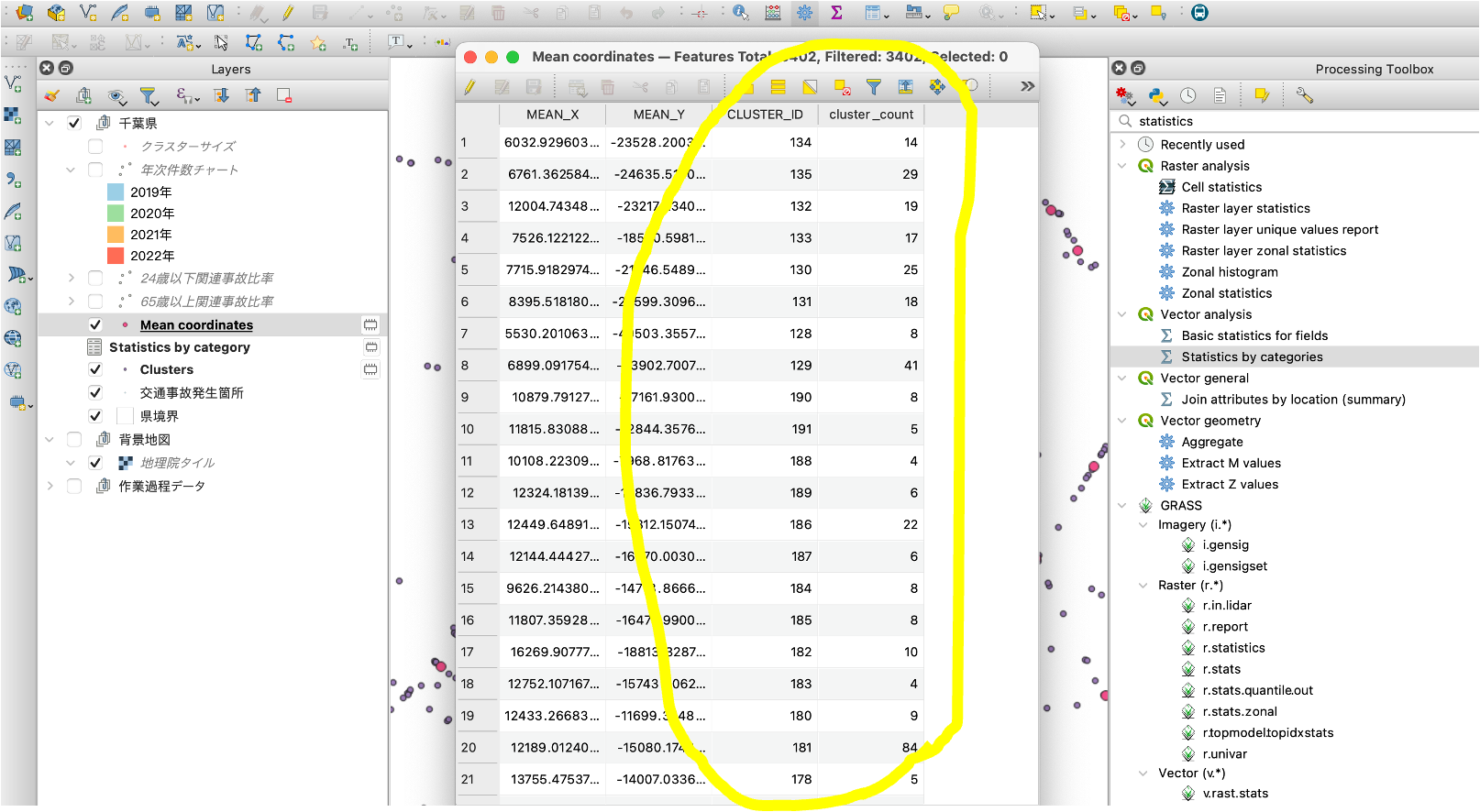
こんな感じで、密集箇所として特定した各クラスタに、IDと件数(何件の点が密集しているグループか)が属性情報として格納できました。
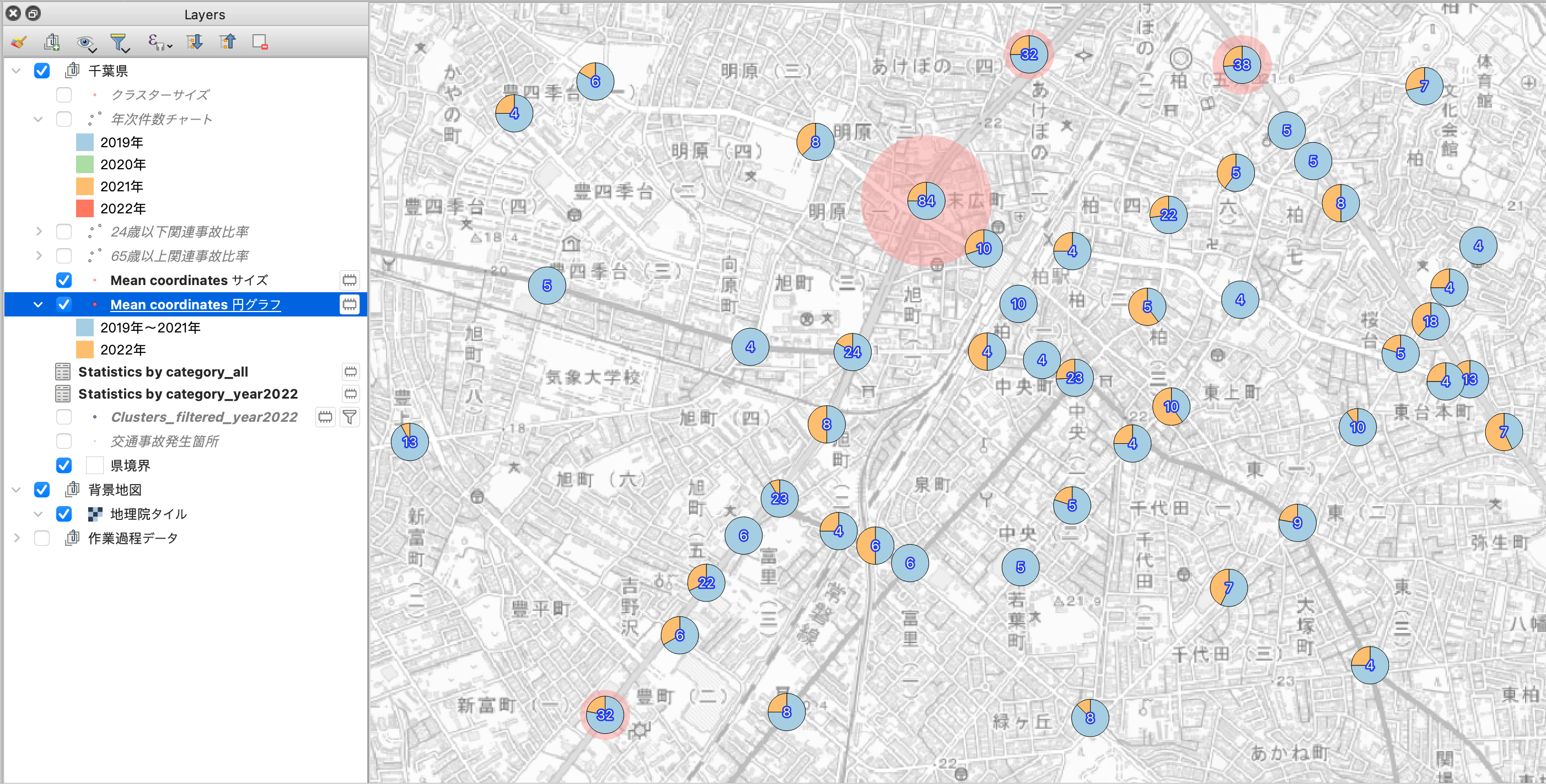
「CLUSTER_ID = 134番の箇所には14件の事故が集中している」という内容になります。
密集箇所の件数サイズを可視化
クラスタに集計値が紐づいたので、簡単に可視化してみます。
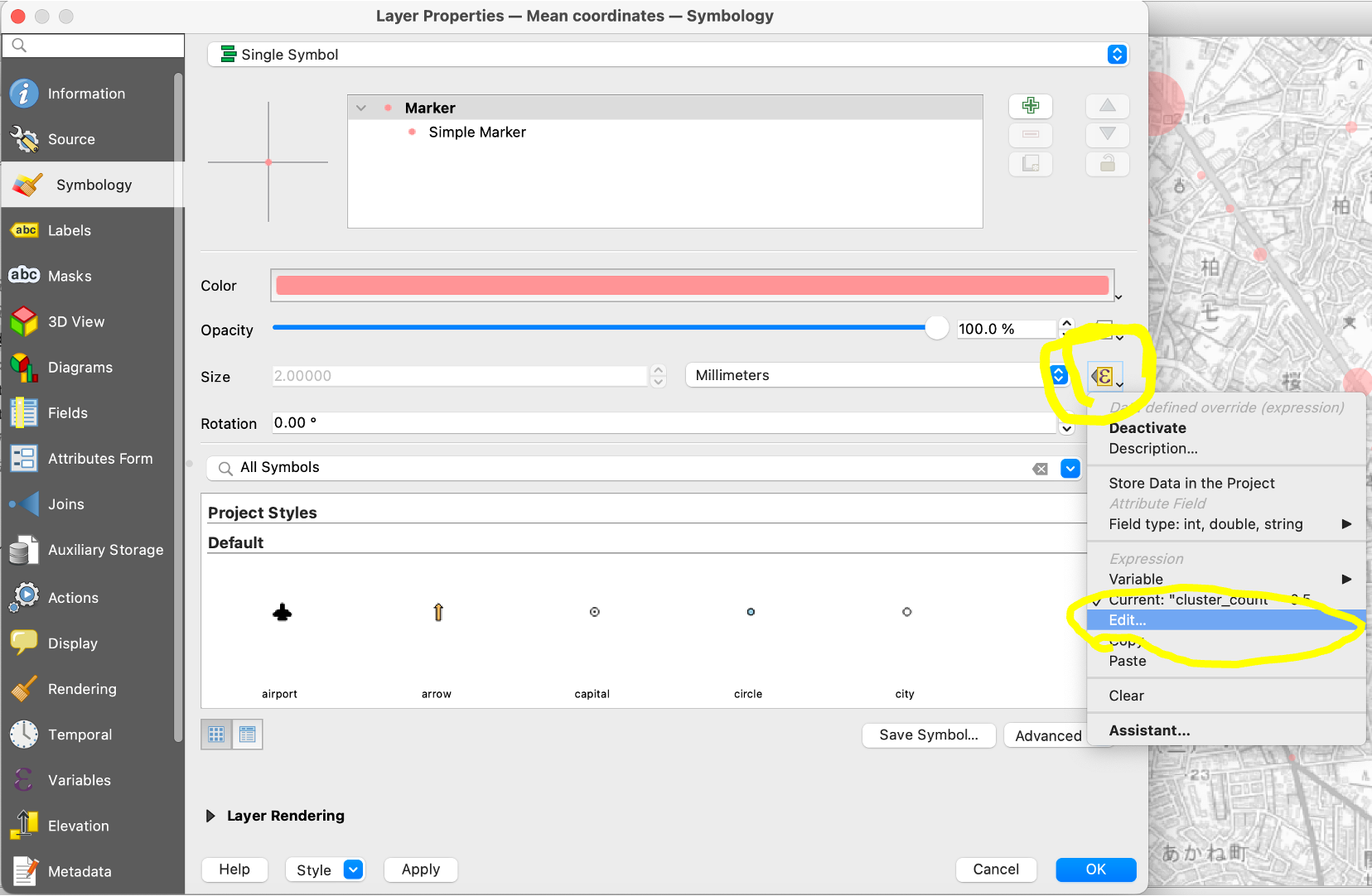
クラスタのレイヤを右クリックしてプロパティを開き、「Symbology」を変更します。件数によってポイントのサイズを変更したいので、下図の黄色強調した箇所から、"Edit"を選択しましょう。
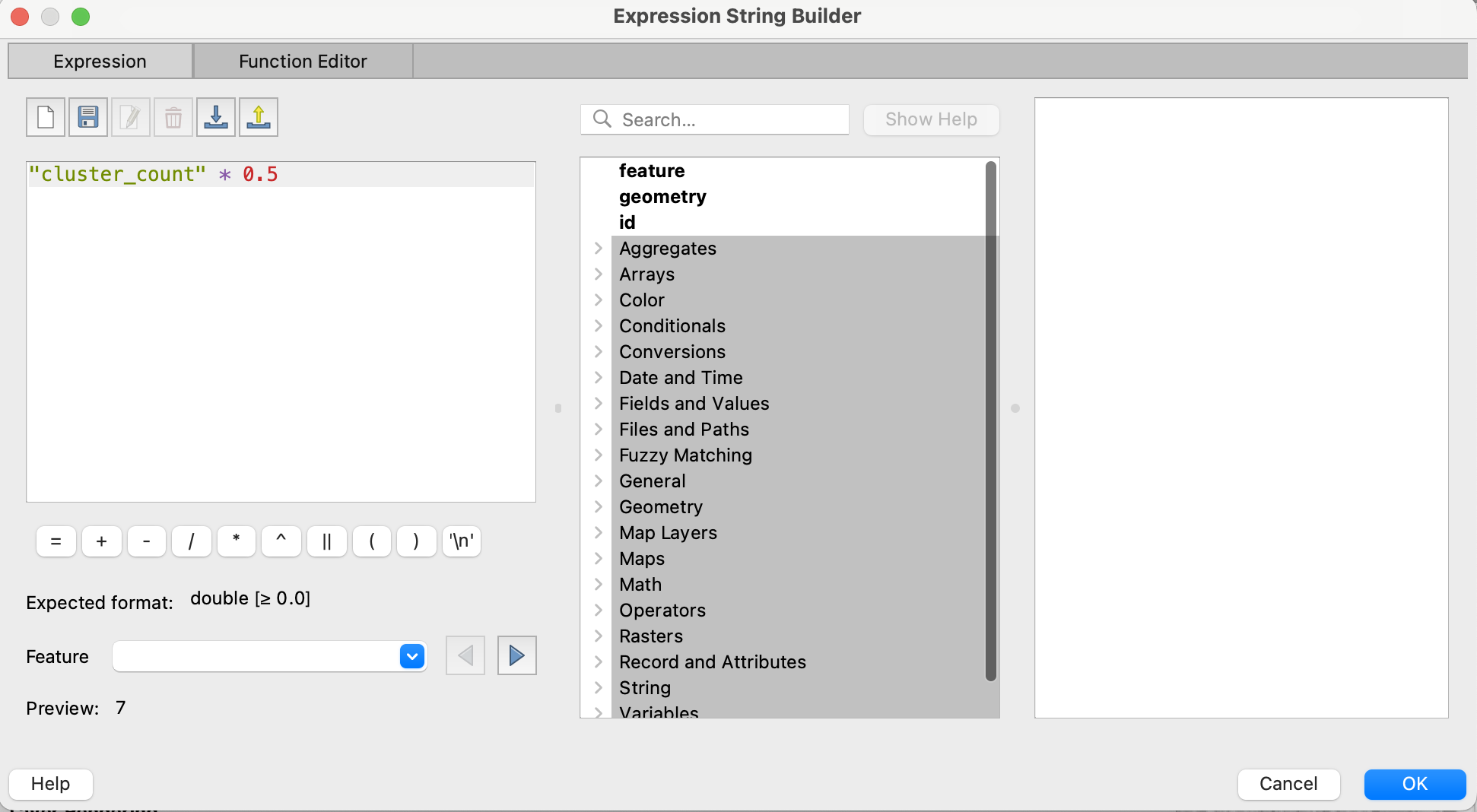
この数式は好みによって調整が必要ですが、私はこのように設定しました。(単純に倍とかにすると大きくなりすぎるので)
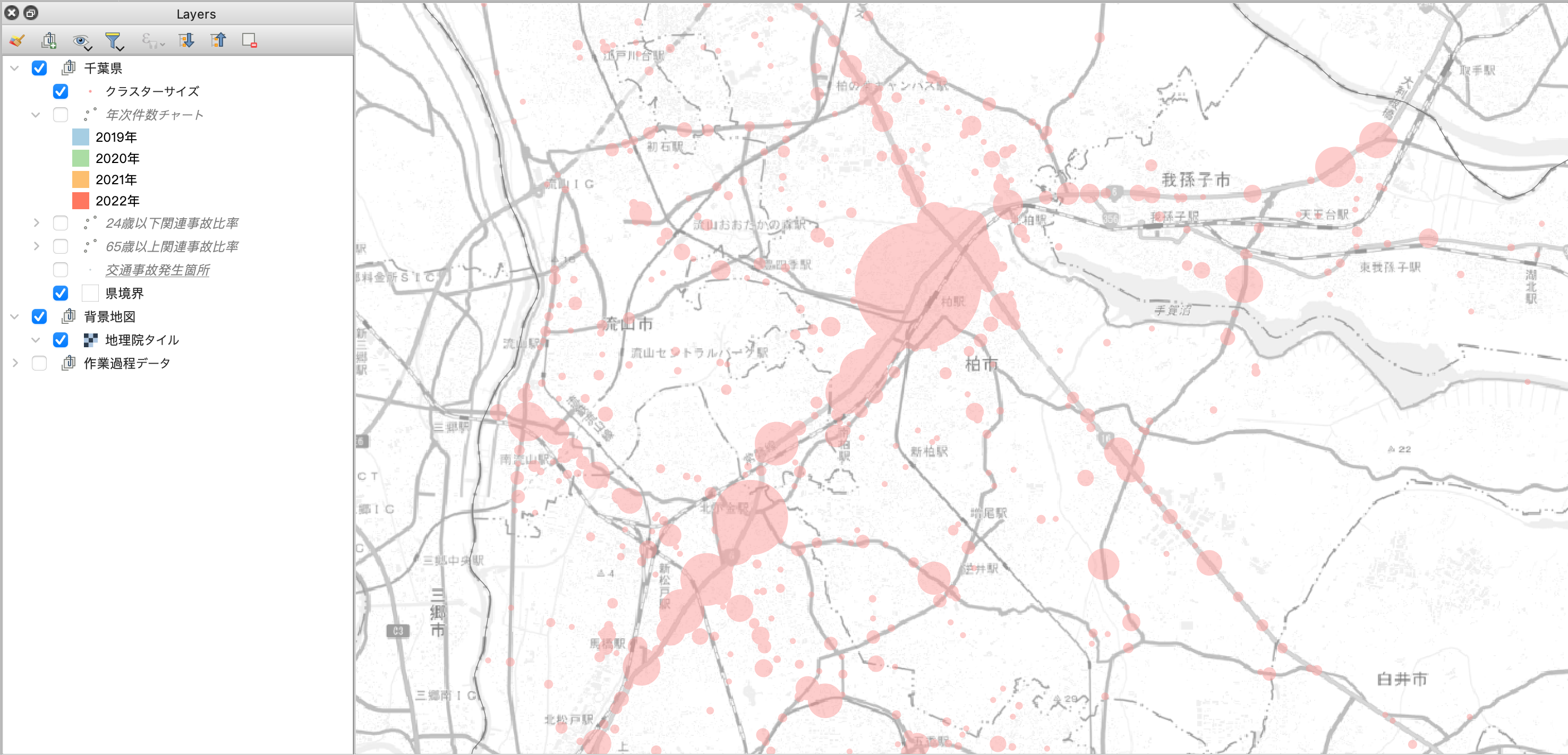
その結果、こんな感じで可視化できました。
視認性は目的や背景地図などに応じて適宜調整してください。
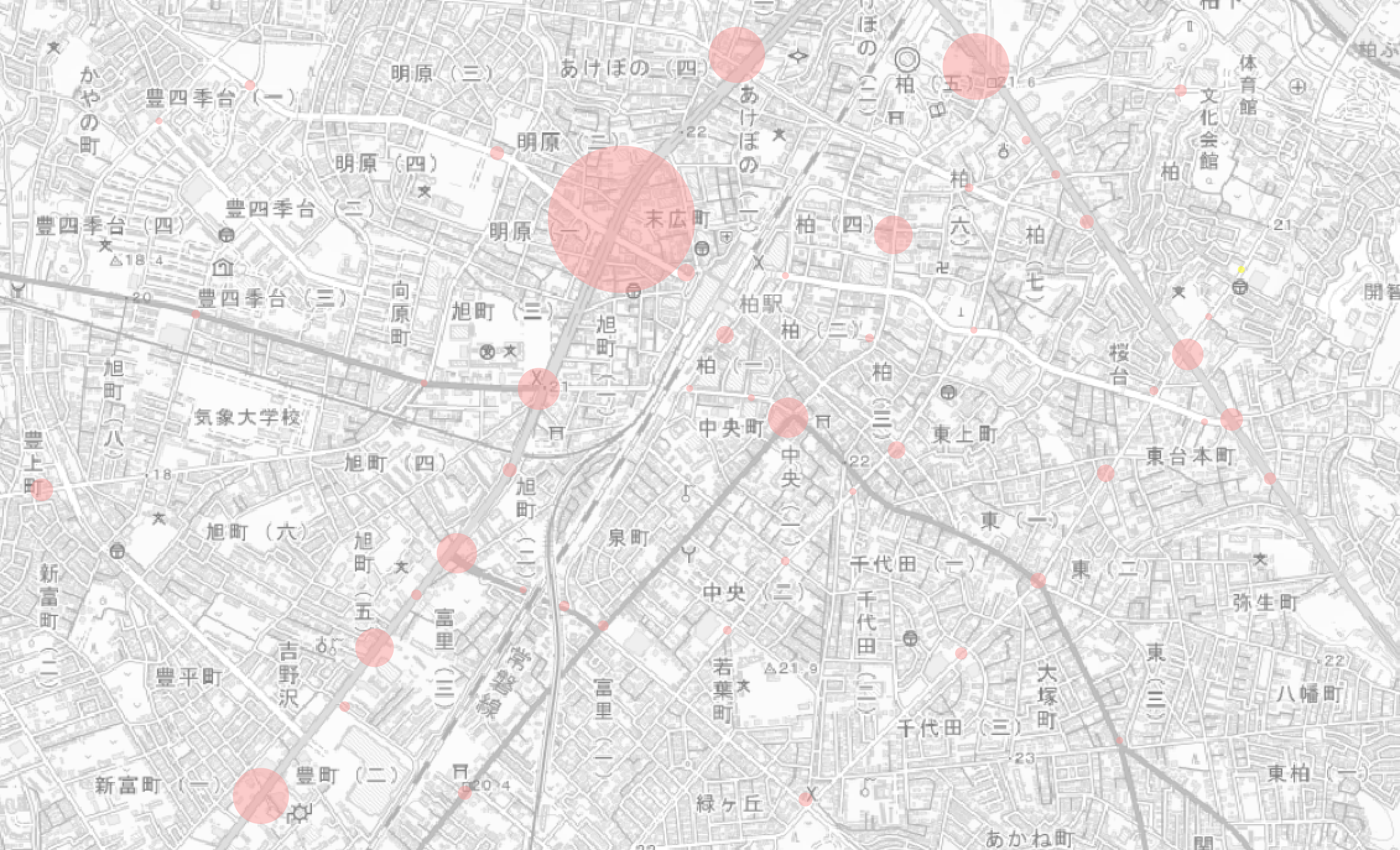
密集箇所の特徴を円グラフで可視化する
上述の工程でDBSCANの出力結果を可視化できましたが、正直なところ、「どこで事故が多いか」というのを調べる目的の可視化であれば、点データの分布をヒートマップ化すれば事足りそうです。
個人的に、クラスタリングにより密集箇所を特定するメリットは、その箇所の特徴を定量評価できることにあると思います。
ということで、もうひと頑張りしてみましょう。
円グラフ用の集計データの整理
クラスタ分類済み点データのフィルタリング
さて、更にここから集計データを追加していきます。今回は例示として、2022年に起きた事故のみで件数を集計してみましょう。
対象レイヤを右クリックして「Filter」を選択し、下図のようにQuery Builderを設定します。
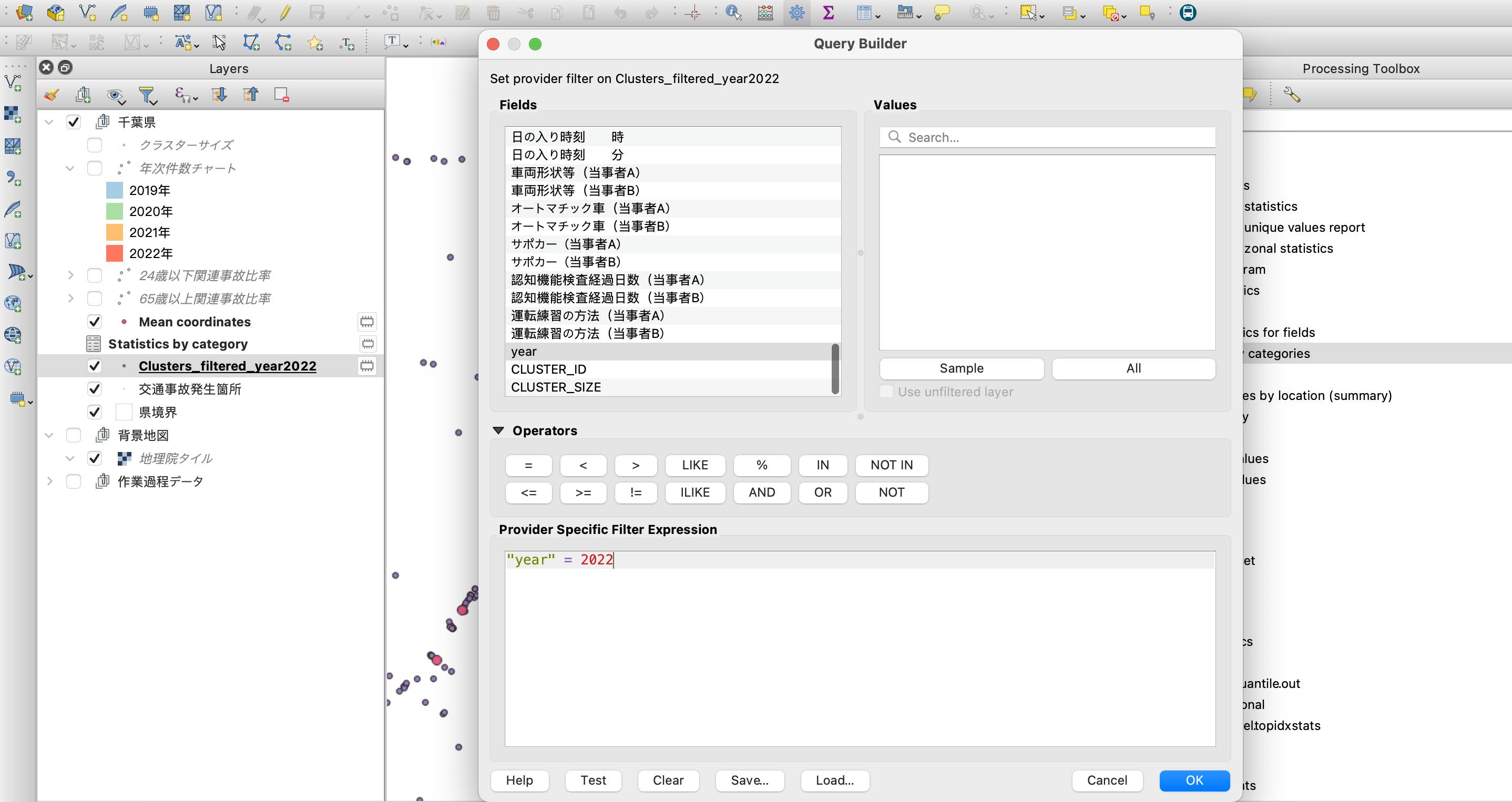
これで、CLUSTER_IDが付与された事故発生箇所の点データを2022年のものだけにフィルタリングできました。
なお上図では、レイヤ名を「Clusters」から「Clusters_filtered_year2022」に一時的に変更しています。
実際の作業では、Temporaryレイヤを別名保存したり、レイヤ名称をわかりやすく変更しておくほうが良いと思いますが、ここでは説明の簡素化のため、仮想レイヤのまま進めていきます。
クラスタの点データと追加した集計情報の紐付け
面倒ですが、もう一度ツールボックスの「Statistics by categories」で集計をとります。
対象は先ほどフィルターをかけたクラスタID付き事故発生箇所データのレイヤで、「Field with categories」は先ほどと同じく「CLUSTER_ID」に設定して実行します。
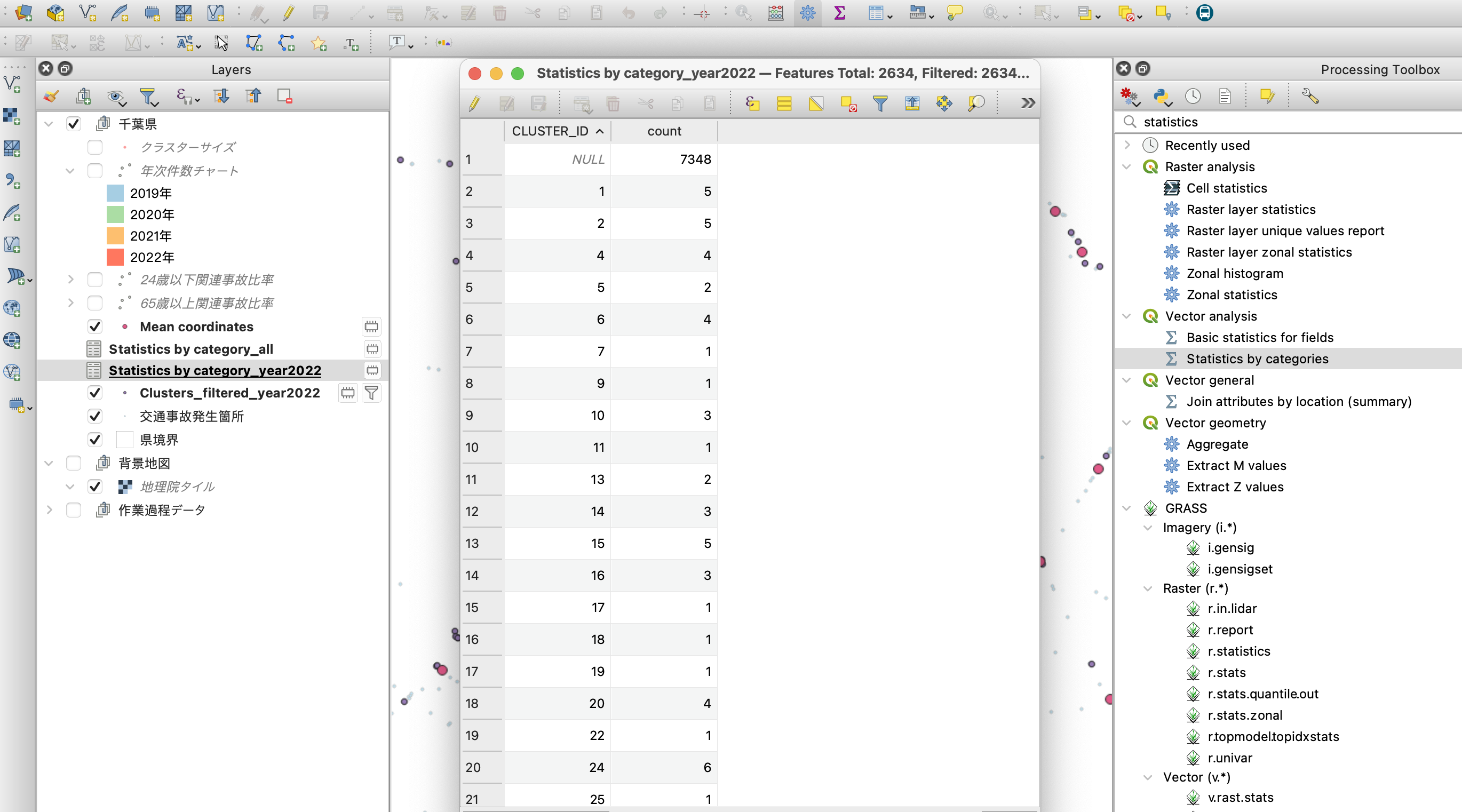
これによって下図のように、2022年の事故だけに絞った状態で、CLUSTER_IDと件数の対照表が生成されます。
その後は同様に、クラスタの中心点レイヤと集計情報をCLUSTER_IDをキーとして紐付けします。
この際、属性名のPrefixは”2022_”などに設定しておくと後から見てわかりやすいので良いと思います。
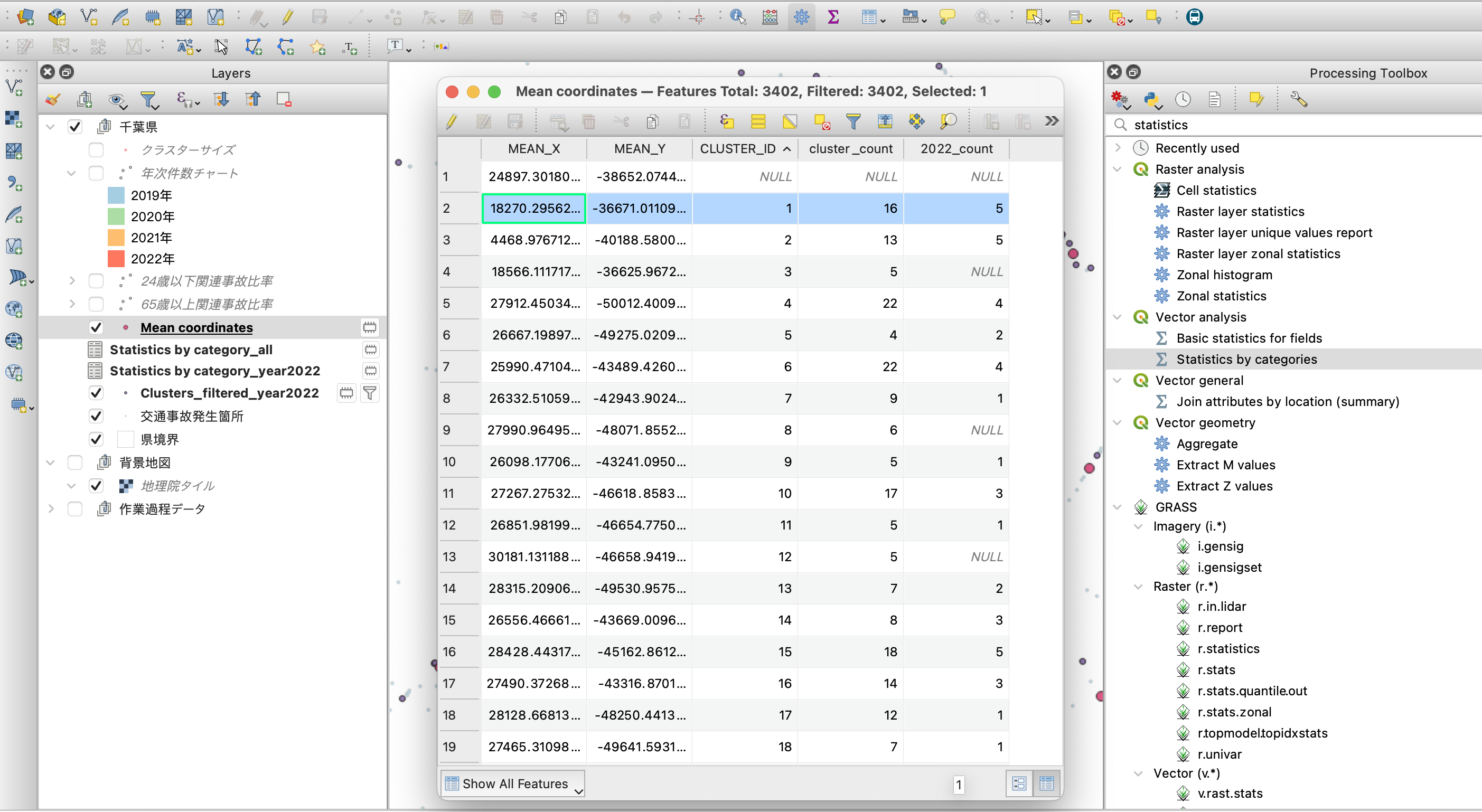
結合した属性テーブルを見てみると、下図のようにクラスタIDとそこに含まれる事故件数、そして2022年のみの事故件数が、それぞれの属性項目に含まれていますね。
例えば、CLUSTER_ID=1のクラスタ(密集箇所)は、16件の事故が集中している箇所であり、そのうち2022年に起きた事故の件数は5件だったという内容になります。
かなり冗長な手法になりましたが、これで集計作業は完了です。
同様の手順で、例えば「夜間に起きた事故件数」とか「高齢者が関連した事故件数」などを集計していくと、分析に活用できると思います。
密集箇所における情報の可視化
上記で生成したレイヤを使って、地図上に交通事故密集箇所の位置とその性質を示す円グラフを描画してみましょう。
まず、対象レイヤを右クリックして「プロパティ」を選択し、プロパティのダイアログを開きます。
その中から、「Diagrams」を選択し、上記のメニューから「Pie Chart」(円グラフ)を選択します。
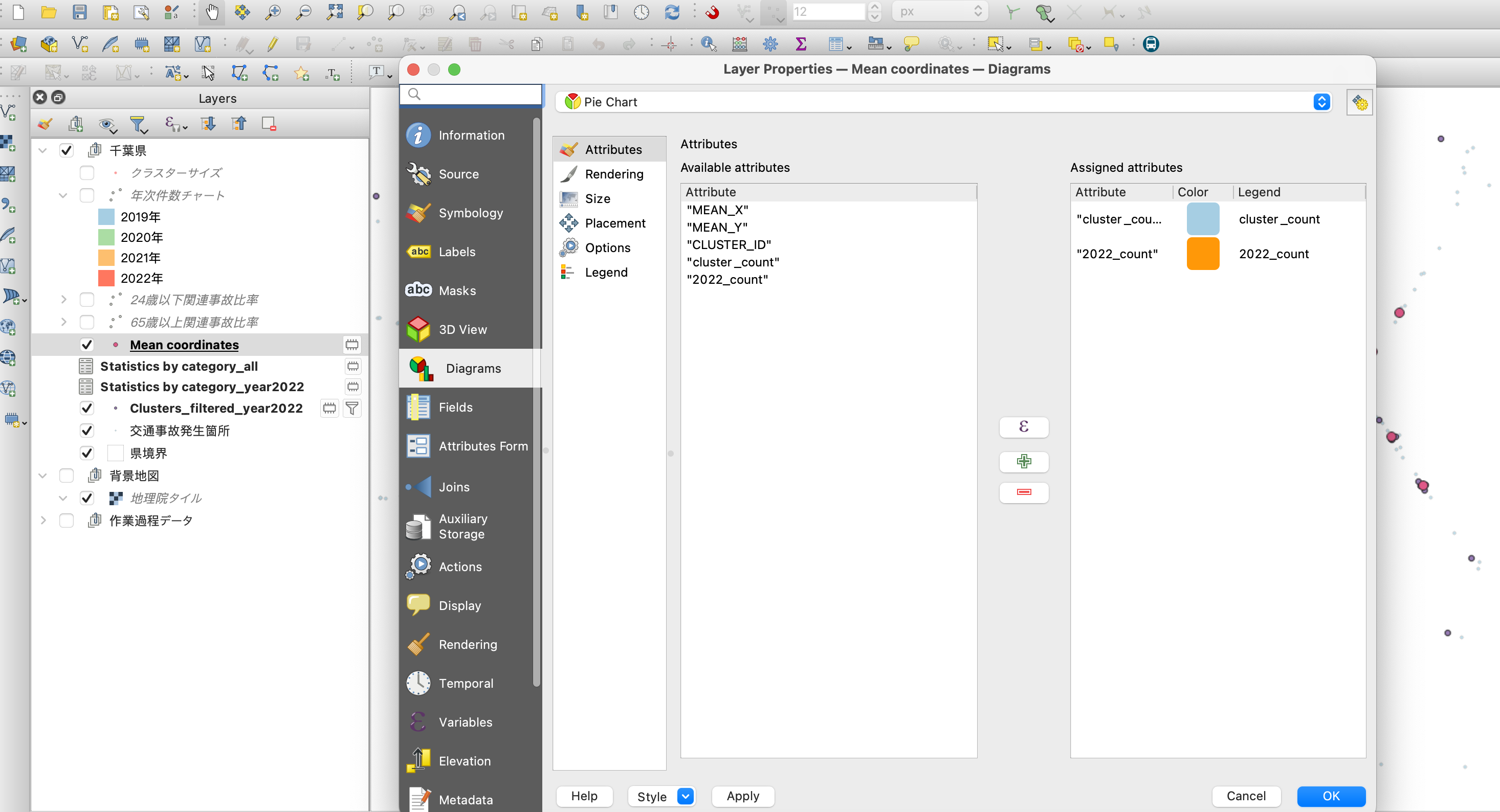
円グラフの設定はお好みですが、今回の例では、「2022年に発生した事故件数」と「それ以外(2019年〜2021年)の事故件数」の円グラフを描画したいので、後者の「Attribute」の箇所を選択し、次のように計算式を入れておきます。
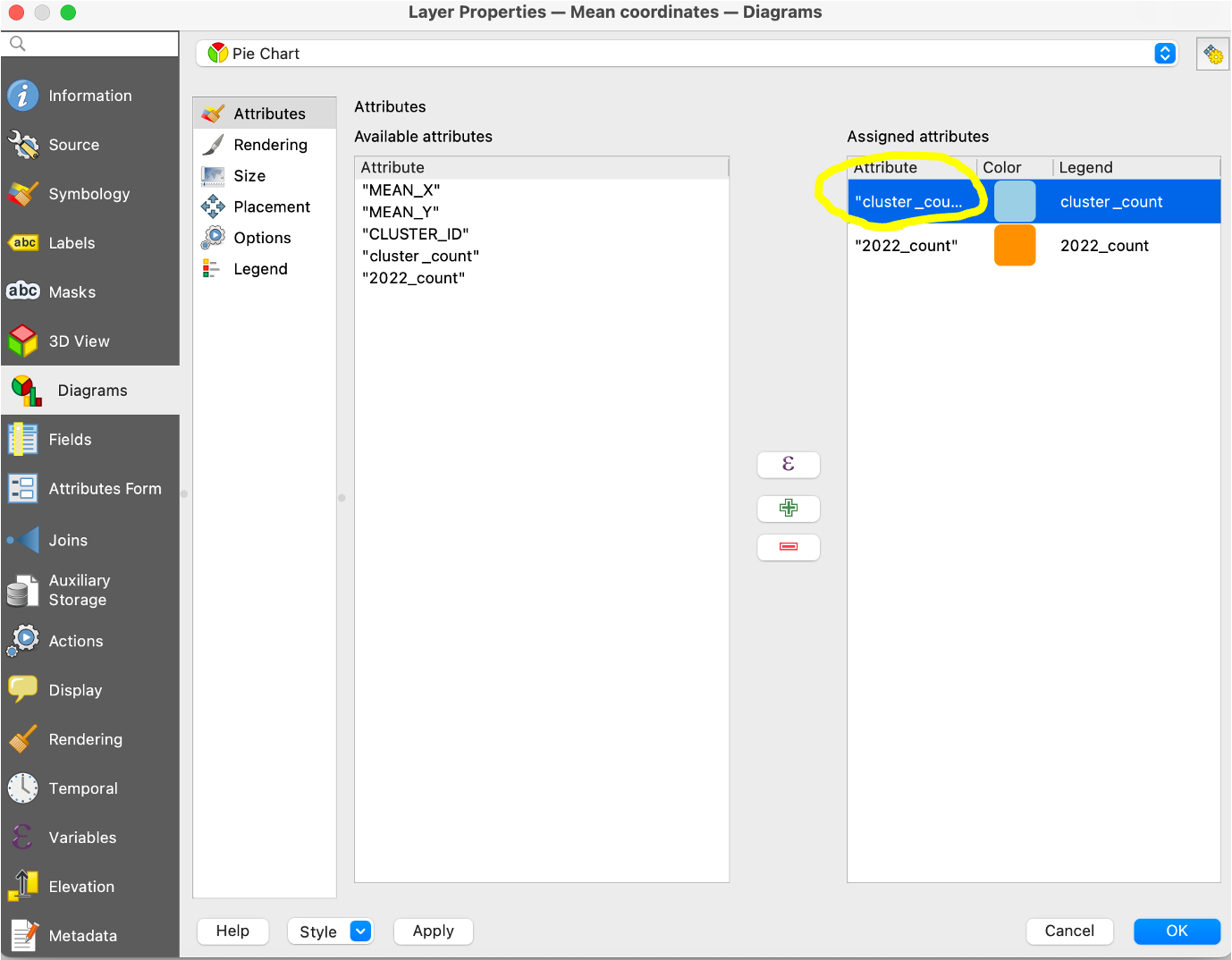
計算式は単純に、「"cluster_count" - "2022_count"」と設定します。このあたりは属性名や目的に応じて適宜アレンジしてください。
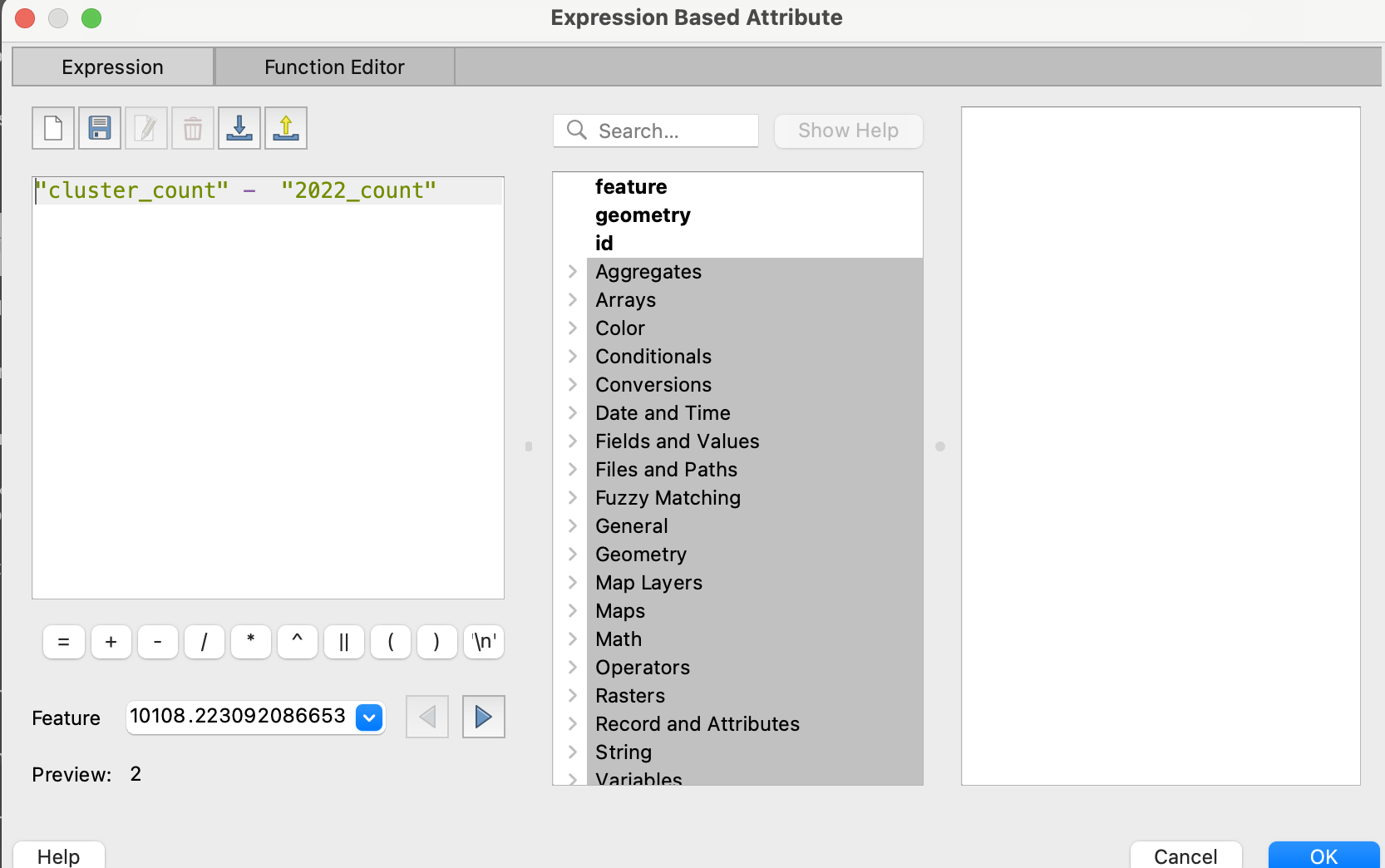
ここまで完了すると、円グラフが出てきます。が、何かおかしいですね。
空白の円があることと、円グラフがクラスタの点上にきていません。
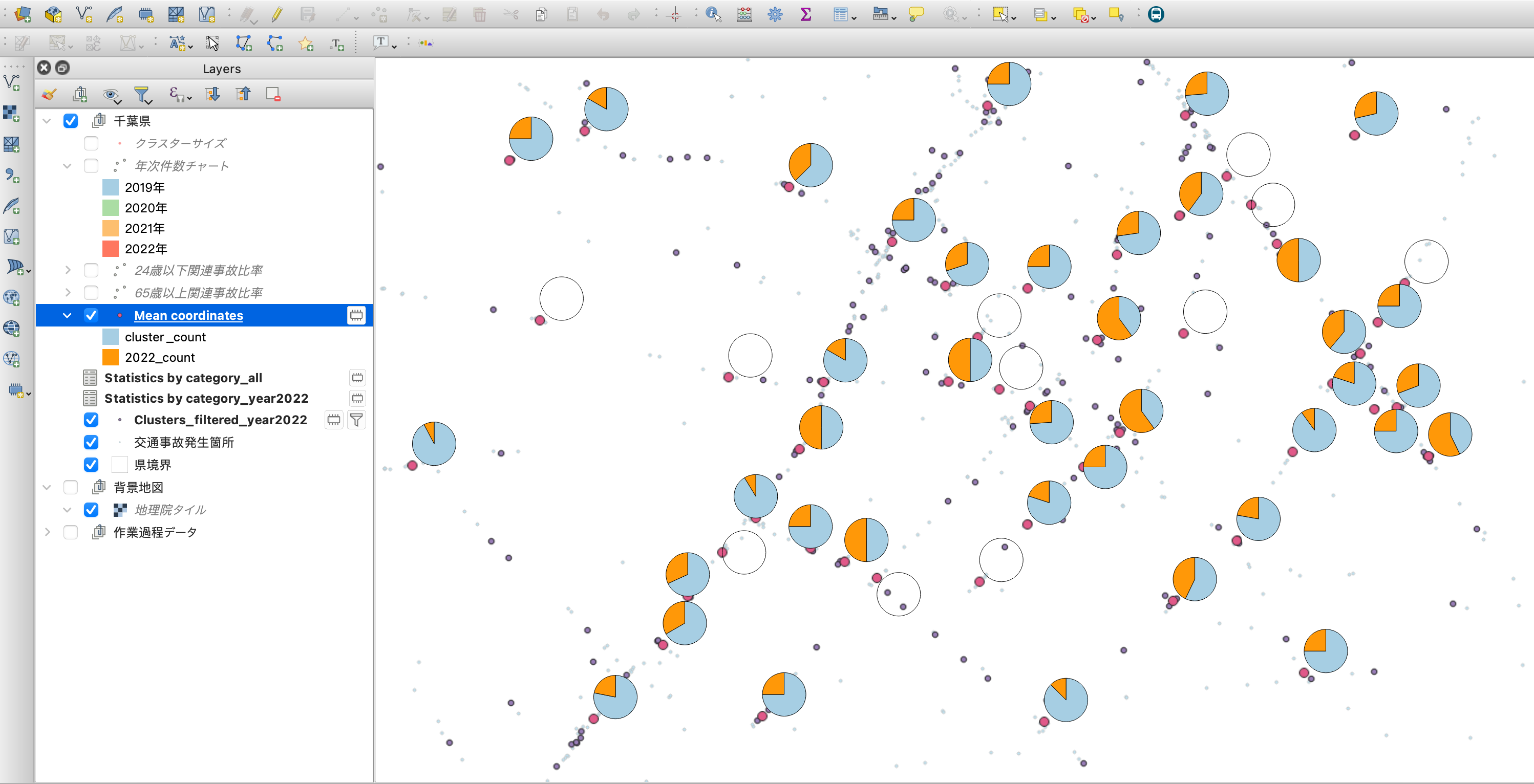
円グラフを点の上に設置する方法は簡単です。円グラフのプロパティのうち、"Placement"にて"Over point"を選択すればOK。
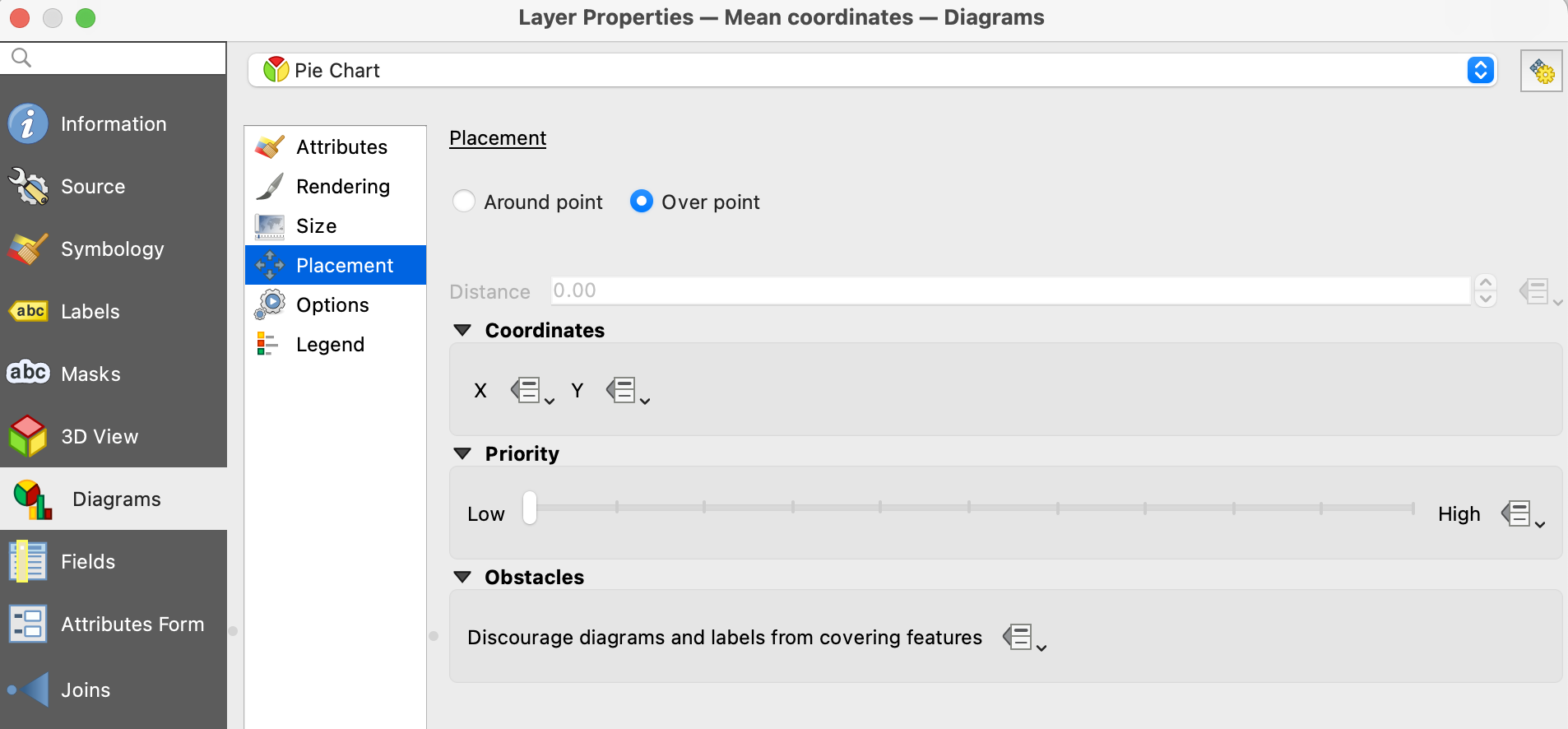
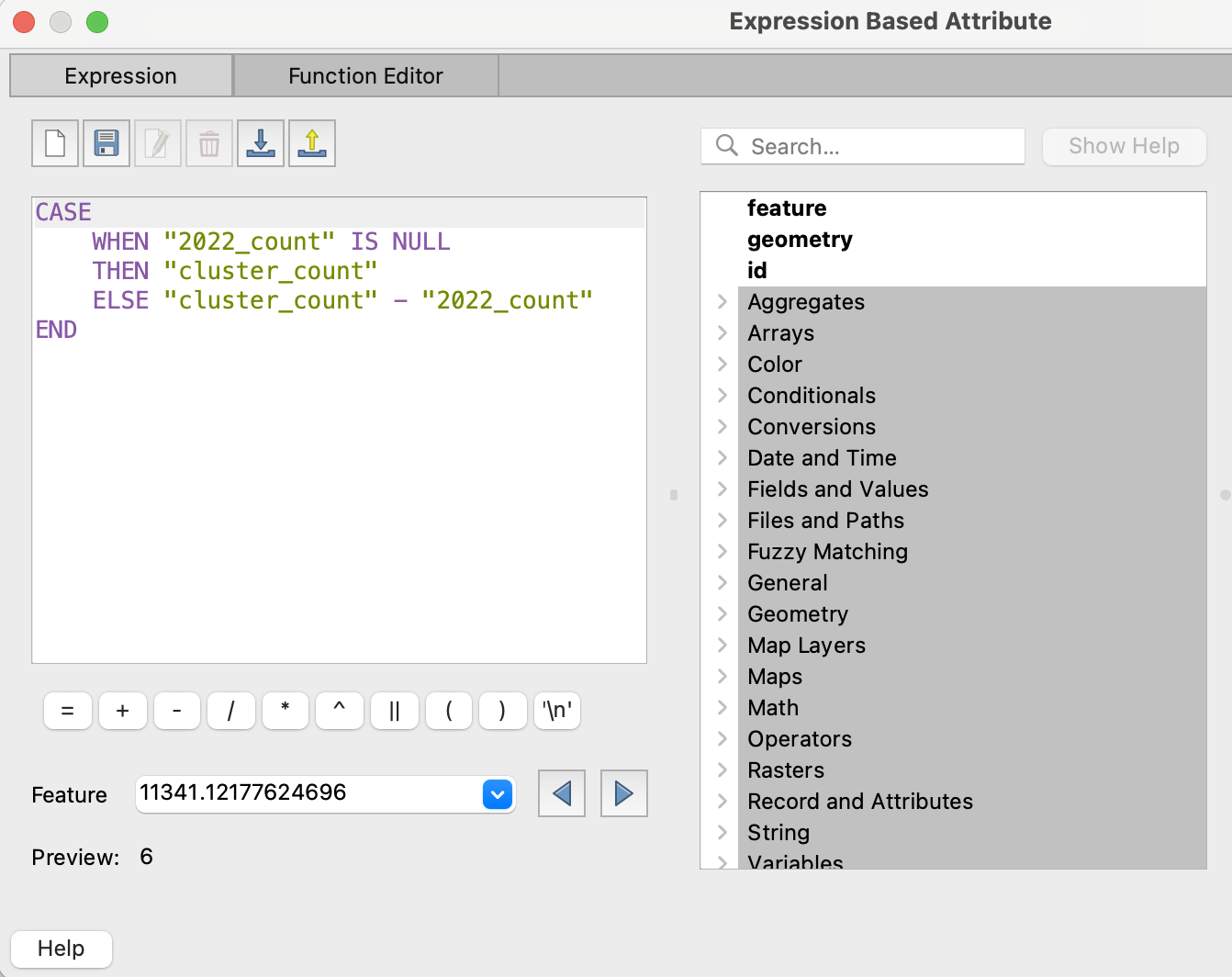
厄介なのは、中身が空白の円グラフです。これは、"2022_count"がNULLであるケースが原因のようです。
そのため、何らかの方法でNULLを0に置き換える必要があります。
一例として、QGISの計算機上で置き換える式を示します。下図のように、CASE WHEN〜で条件分岐させています。
注意点として、NULLの判定は = (イコール)ではなく、IS NULL にて行います。
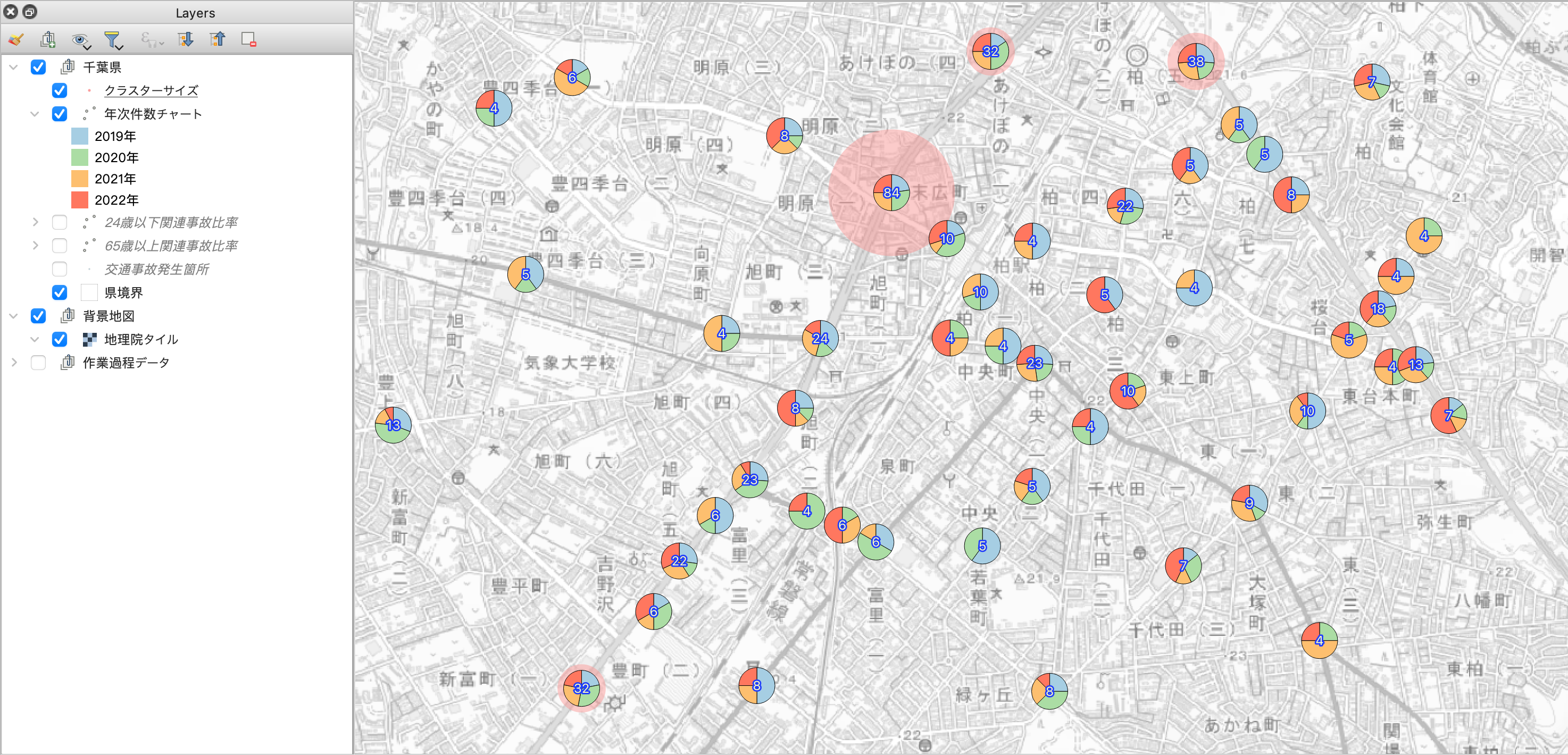
これで円グラフの描画が出来ました。
あとはお好みですが、下図のように各クラスタの件数をラベル表示させてあげると「件数」と「比率」が一目でわかって良いですね。
おわりに
以上でこの記事は終了です。
もし私の理解が間違っていたり、さらに効率的な手法の提案があれば、ご教示ください。
とても長くなってしまいましたが、DBSCANによる処理実行と、その出力結果の可視化までいくつかのステップがありますので、どれか部分的にでも参考になれば幸いです。