概要
自然言語処理における文書ベクトル化の手法を応用して、テキストで記述された地域情報をもとに各地域を色分けした地図を作成する、ということを行いました。
具体的には、首都圏の都市計画(整備、開発、保全の方針:いわゆる整開保)の文書をトピックモデル(LDA)で分類した結果を、RGB値で地図上に表現するというものです。
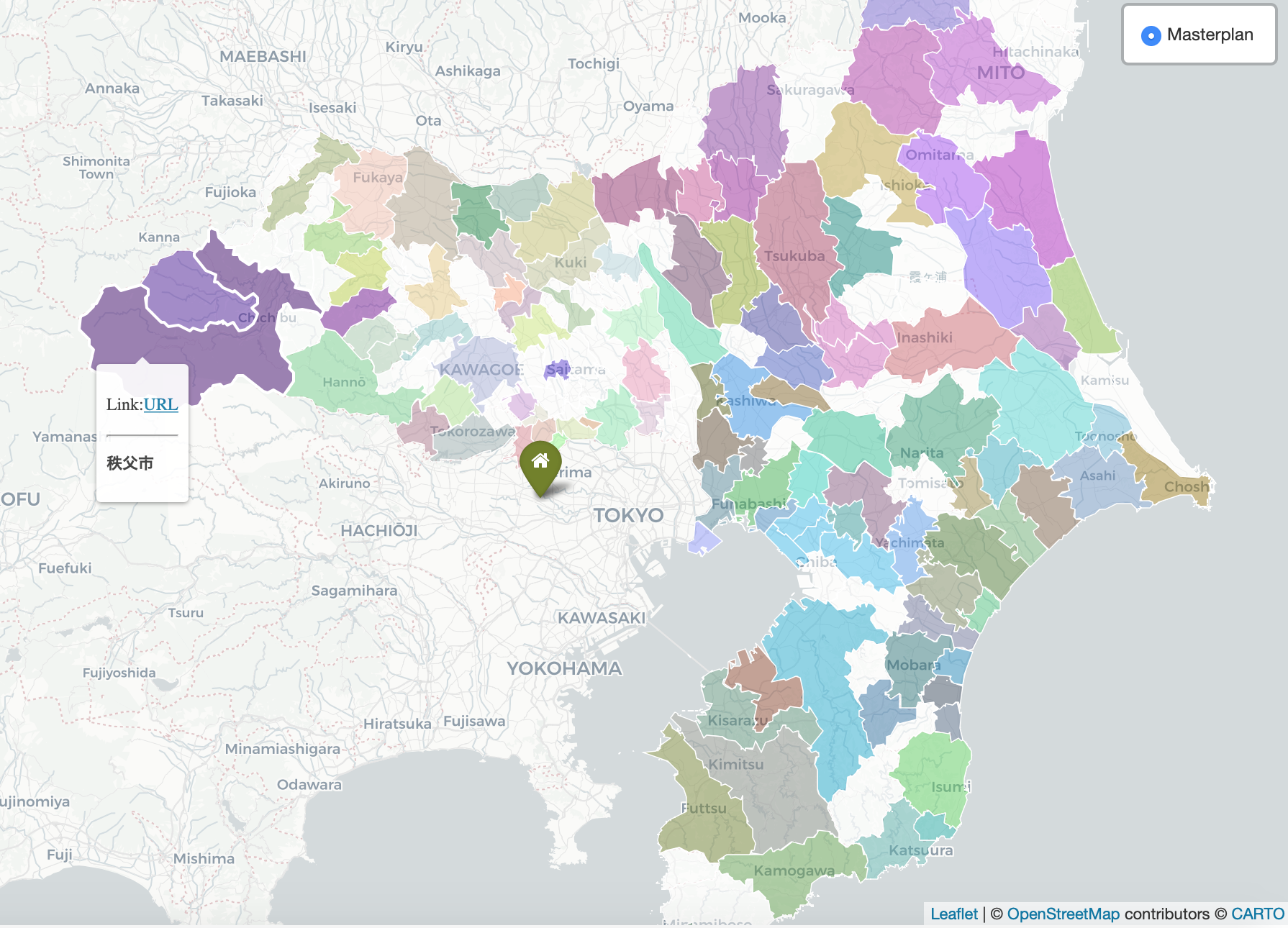
これにより、「この地域とあの地域は地理的には離れているけど意外と同じ様な特性がある」といった概念的な発見に繋げられないか、と考えて実施しています。
現状はデータが整理しきれておらず歯抜け状態ですが、例えば茨城県は紫色っぽいのが多いのに対し、千葉県・埼玉県は緑・茶系が多い。しかし、埼玉でも秩父など西側は茨城県と近い色を示しています。また君津と所沢なども意外と近そう。なぜ埼玉市の中心(大宮)も紫なのかは謎、、などなど。データ数が増えれば精度の納得感は向上するかもしれません。
元のデータ
国土交通省都市計画マスタープランリンク集から千葉・埼玉・茨城の都市計画文書を取り繕ってきました。ただし、全ての地域は網羅できておらず、あくまでサンプルとなります。こんな感じのデータセット(CSV形式)をインプットとして作成しました。
| name | description | |
|---|---|---|
| 1 | 竜ヶ崎・牛久 | 竜ヶ崎・牛久都市計画(龍ケ崎市,牛久市,利根町)都市計画区域の〜(略)〜近隣都市間の連携を強化し,豊かな自然・田園環境と共生しながら,職・住が一体となった〜 (略) |
| 2 | 飯能市 | 飯能都市計画(飯能市)都市計画区域の〜(略)〜公共交通の利用促進やみどりの創出などにより、低炭素社会の実現を図る。地域の個性ある発展〜 (略) |
文書のベクトル化
-
実際に作成したコードは下記となります。MeCabで形態素解析、gensimでトピックモデルによるベクトル化、scikit-learnでTSNEによる次元削減を行っています。改善点は多いかもですが、その辺りは随時修正したいと思います。
-
実行環境>> OS: MacOS Catalina | 言語: python3.6.6
from sklearn.manifold import TSNE
from gensim import corpora, models
import string
import re
import MeCab
import pandas as pd
import numpy as np
# Text Tokenizer by MeCab
def text_tokenizer(text):
token_list = []
tagger = MeCab.Tagger()
tagger.parse('')
node = tagger.parseToNode(text)
while node:
pos = node.feature.split(",")
if pos[0] in ["名詞", "動詞", "形容詞"]: #target word-class
if pos[6] != '*': #lemma is added when it exists
token_list.append(pos[6])
else:
token_list.append(node.surface)
node = node.next
return list(token_list)
# Loading input dataset
df = pd.read_csv('input.csv', encoding="utf-8")
df['text'] = df['description'] #set target column
# Remove https-links
df['text_clean'] = df.text.map(lambda x: re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-]+', "", x))
# Remove numerals
df['text_clean'] = df.text_clean.map(lambda x: re.sub(r'\d+', '', x))
# Converting all letters into lower case
df['text_clean'] = df.text_clean.map(lambda x: x.lower())
# Creating DataFrame for Token-list
df['text_tokens'] = df.text_clean.map(lambda x: text_tokenizer(x))
# LDA
np.random.seed(2000)
texts = df['text_tokens'].values
dictionary = corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
ldamodel = models.ldamodel.LdaModel(corpus, id2word=dictionary, num_topics=20, passes=5, minimum_probability=0)
ldamodel.save('lda_bz.model')
print(ldamodel.print_topics())
# Converting Topic-Model result into numpy matrix
hm = np.array([[y for (x,y) in ldamodel[corpus[i]]] for i in range(len(corpus))])
# Dimensionality reduction by tsne
tsne = TSNE(n_components=3, init='pca', verbose=1, random_state=2000, perplexity=50, method='exact', early_exaggeration=120, learning_rate=200, n_iter=1000)
embedding = tsne.fit_transform(hm)
x_coord = embedding[:, 0]
y_coord = embedding[:, 1]
z_coord = embedding[:, 2]
# RGB conversion with normalization
def std_norm(x, axis=None):
xmean = x.mean(axis=axis, keepdims=True)
xstd = np.std(x, axis=axis, keepdims=True)
y = (x-xmean)/xstd
min = y.min(axis=axis, keepdims=True)
max = y.max(axis=axis, keepdims=True)
norm_rgb = (y-min)/(max-min) * 254
result = norm_rgb.round(0)
return result
x_rgb = std_norm(x_coord, axis=0)
y_rgb = std_norm(y_coord, axis=0)
z_rgb = std_norm(z_coord, axis=0)
embedding = pd.DataFrame(x_coord, columns=['x'])
embedding['y'] = pd.DataFrame(y_coord)
embedding['z'] = pd.DataFrame(y_coord)
embedding["r"] = pd.DataFrame(x_rgb)
embedding["g"] = pd.DataFrame(y_rgb)
embedding["b"] = pd.DataFrame(z_rgb)
embedding['description'] = df.description
# export to csv
embedding.to_csv("output.csv", encoding="utf_8")
-
基本的なコンセプトは、自然言語処理においてよく行われる”文書ベクトルの3次元可視化”を実施し、その3次元ベクトル(x,y,z値)をRGB値に変換しています。
-
今回、文書のベクトル化ではトピックモデルを採用しています。その理由として、その他のベクトル化手法(例えばtf-idfやword2vecベース)では次元削減後のxyz値に外れ値が出てくるケースが多く、0〜255のRGB値に変換した際にその影響が大きすぎたためです。トピックモデルの場合、パラメータを適切に設定すれば外れ値が生じにくく、この問題をクリアできると考えました。
地図上での可視化
-
文書情報をRGB値に変換したあとは、各市町村のRGB値をマップ上で可視化します。
私の場合、QGISで地理情報との紐付けを行い、Leafletを使って描画しました。こちらは今回は省略しますが要すれば別記事にて詳述します。 -
QGISで属性情報にあるRGB値をそのまま色で表現する方法があるのか、どなたかご存知であれば教えてください。
留意点と今後の課題
-
文書ベクトルは大まかに言って、語られている内容(単語の出現傾向やトピックなど)が近ければベクトルとしても近い距離に現れるため、それを色に変換すれば、似た様な色合いの街は語られている内容も近いと判断できるかなと考えています。このあたり、もしカウンターパンチがあれば謹んでお受け致しますのでご指摘ください。
-
この色は地域同士の相対的な関係性を示すため、初期値を変えて解析をするとその度に色が変わります。「毎年この作業を実施して経年で変化を追う」といった場合に使いづらいので、このあたりの解決策も模索したい。
-
今回とりあえず試験的に都市計画文書を用いていますが、まだ全ての市町村をカバーできていないことだけでなく、それ以前にこれらが「街の特色」を表しているかというと、一般的な感覚とは乖離があると思います。ゆくゆくは、観光客の声や住民参加型ワークショップの協議録などを反映させたものができたら面白いと思っています。