はじめに
機械学習を実務で使い始めて、5か月が経過しました。
物体検出、画像認識をメインに取扱い、論文を読むのも多少慣れてきました。
ですが、まだまだ中身の数式などを理解しきれてないので、数学(今はベイズ統計学と最適数学)やフレームワークに対する理解を深める日々を送っています。
モチベーション
モチベーションは下記2点で、実務ですぐ使えるよう、備忘録として書きました。
- 物体検出では、SSDなどをメインで使っており、YOLOを使ったことがなかった
- Yolo v2を使ってみたという記事は多いが、自分で用意したデータを学習させる記事があまりなかった
Yolo v2とは
物体検出でよく使用されるモデルです。
SSDよりも検出速度が速く、そこまで精度も劣らないです。
最新ではYolo v3が出ていますが、検出速度に関しては、Yolo v2の方が良いので、Yolo v2を使ってみます。
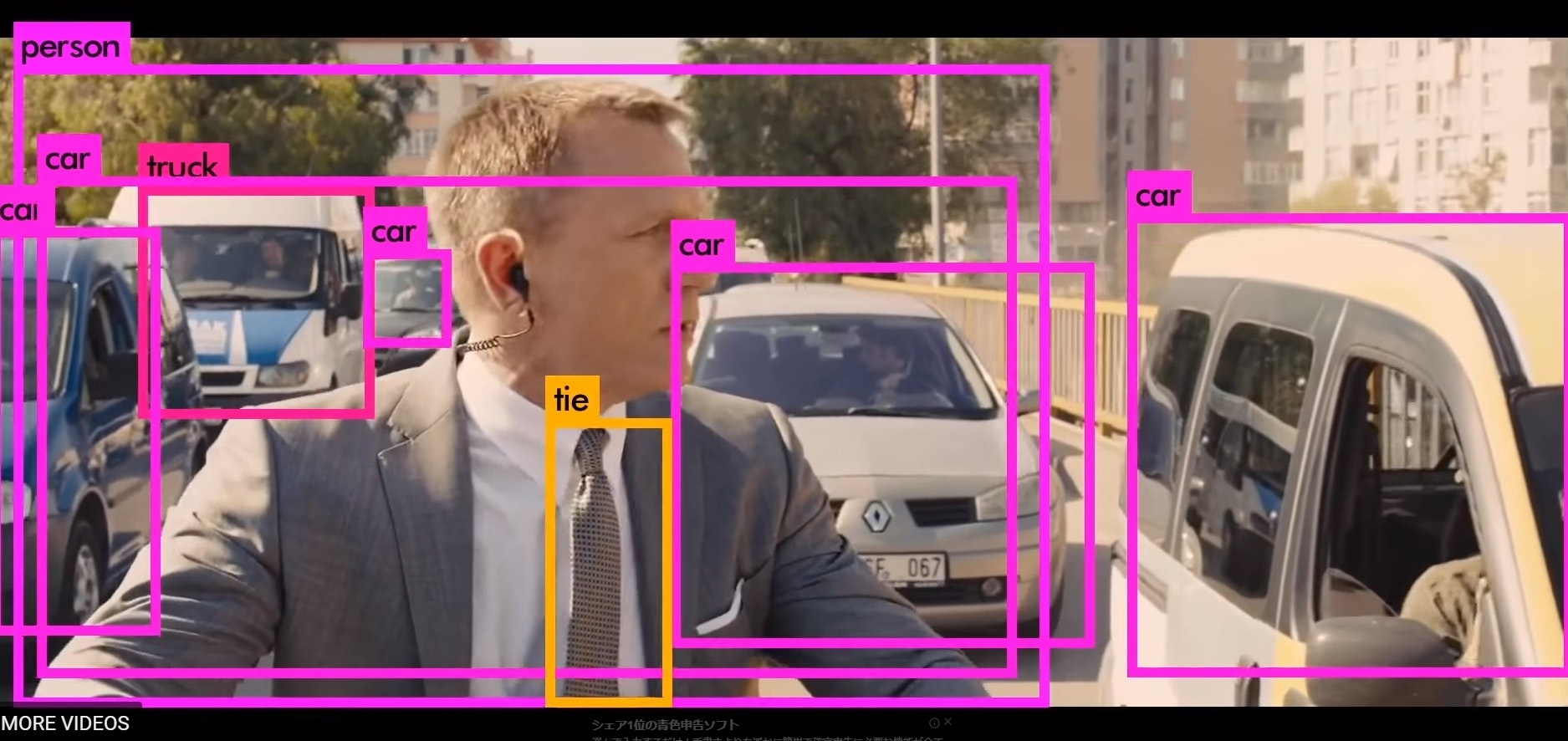
公式ページでYolo v2の検出結果を見ることができます。(007)
こんな感じ。動画ですが、キャプチャでとったので、違和感あるかも。
この動画はなぜか何度も見てしまう.......
学習の流れ
- 環境構築
- アノテーション
- 設定ファイル準備
- 学習
- 検証
環境
CentOS7.2でvirtualenvで仮想環境を構築しました。
pip listの結果
absl-py 0.6.1
astor 0.7.1
cycler 0.10.0
Cython 0.29.2
darkflow 1.0.0
gast 0.2.0
grpcio 1.17.1
kiwisolver 1.0.1
Markdown 3.0.1
matplotlib 3.0.2
numpy 1.15.4
opencv-python 3.4.4.19
pandas 0.23.4
pip 18.1
protobuf 3.6.1
pyparsing 2.3.0
python-dateutil 2.7.5
pytz 2018.7
setuptools 39.1.0
six 1.12.0
tensorboard 1.9.0
tensorflow-gpu 1.9.0
termcolor 1.1.0
Werkzeug 0.14.1
wheel 0.32.3
使用するリンク
本家ページ(Yolo v2)
https://pjreddie.com/darknet/yolov2/
今回使用するリンク
https://github.com/thtrieu/darkflow
Youtube
https://www.youtube.com/watch?v=eFJOGsQ_YTA&t=213s
アノテーション
下記のgitをクローンし、アノテーション作業を行います。
LabelImg
https://github.com/tzutalin/labelImg
LabelImgは、Object Detection API使うときにも使えるのでよく使ってます。
設定ファイル準備
今回は、転移学習を行うので、Yolo V2の公式リンクから、cfgファイルとweightsファイルを取ってきます。
この2つのファイルを同じところ(v2ならv2のもの)からとってこないと、後々エラーが発生します。
たとえば下記のようなエラー
https://github.com/thtrieu/darkflow/issues/465
Configファイル設定
ここでは、2つ設定を行います。
configフォルダは、cfgというフォルダ配下に設置します。
yolo v2の公式サイトからとってきたconfigファイルをここに新しく設置します。
Classs
ここは自分がアノテーションで作ったクラスの数を設定します。
私の場合、personというクラスのみなので、1を設定します。
Filter
filterについては、下記のようにドキュメントで書かれています。
In tiny-yolo-voc-3c.cfg, change filters in the [convolutional] layer (the second to last layer) to num * (classes + 5). In our case, num is 5 and classes are 3 so 5 * (3 + 5) = 40 therefore filters are set to 40.
tiny-yoloの例ですが、yolo-v2でもこの計算で動かすことができました。
私の場合、計算は下記のようになります。
num * (classes + 5) = 5 * (1 + 5) = 5 * 6 = 30
なので、30をconfigに設定します。
学習
コマンドは下記を実行します。
python flow --model cfg/yolov2.cfg --load bin/yolov2.weights --train --dataset train/Images/ --annotation train/Annotations/ --epoch 100 --gpu 2.0 --trainer adam
--modelなどが、darknet/defaults.pyファイルに設定されています。
もろもろ説明
--model cfg/yolov2.cfg
→これは先ほど設定した、cpnfigファイルのことを指します。
--load bin/yolov2.weights
→これも最初にyolo v2の公式サイトからとってきた重みのことです。
--train
→これはtarinさせるよーという宣言。
--dataset train/Images/
→アノテーションで使った画像を設置します。
--annotation train/Annotations/
→アノテーションで出力したxmlファイルを設置します。
--epoch 100
→epoch
--gpu 2.0
→gpu番号何を使うか決定。
--trainer adam
→optimizerの設定。
出力されるファイル達
学習中は、下記4つのファイルが作成されます。
yolov2-1000.data-00000-of-00001
yolov2-1000.index
yolov2-1000.meta
yolov2-1000.profile
後半の様子とってしまったけど、こんな感じで学習してくれる。
検証
検証のコマンドは、下記のような感じ。
python flow --model cfg/yolov2.cfg --load 1000 --demo VIDEO.mp4 --saveVideo
もろもろ説明
--load 1000
→この1000は、yolov2-1000.~の1000とリンクしています。そして数値を宣言するだけで、勝手にckptフォルダの中を見にいってくれます
--saveVideo
→自分の場合、動画でYolo v2の速さを見たかったので、このオプションをつけています。
同じフォルダ配下に、video.aviファイルが作成されます。
感想
Yolo v2の検出速度速い!!と今更ながらに感じる。
次は、mobile netとかshuffle netを組み合わせたらどうなるか見てみたいと思いますー。
タイトル007を使ったから、最後の検出結果に007の動画をのせるべきだったなーと思ったけど、もう書き終えた感が自分の中で発生してしまったので、終わらしてください、すいません。