面白そうな論文があったのでまとめてみました.
正直うまく訳せない部分があったり,理解に欠ける部分もあるので,編集リクエストなど出していただけると大変うれしく思います![]()
どんな論文?
"Image Inpainting"とは,NVIDIAが公開した写真の欠落した部分を自動修復させる技術.
画面左の写真の石を塗りつぶすと,右側の写真から石が削除され,その場所に地面や木の枝が補完されている.
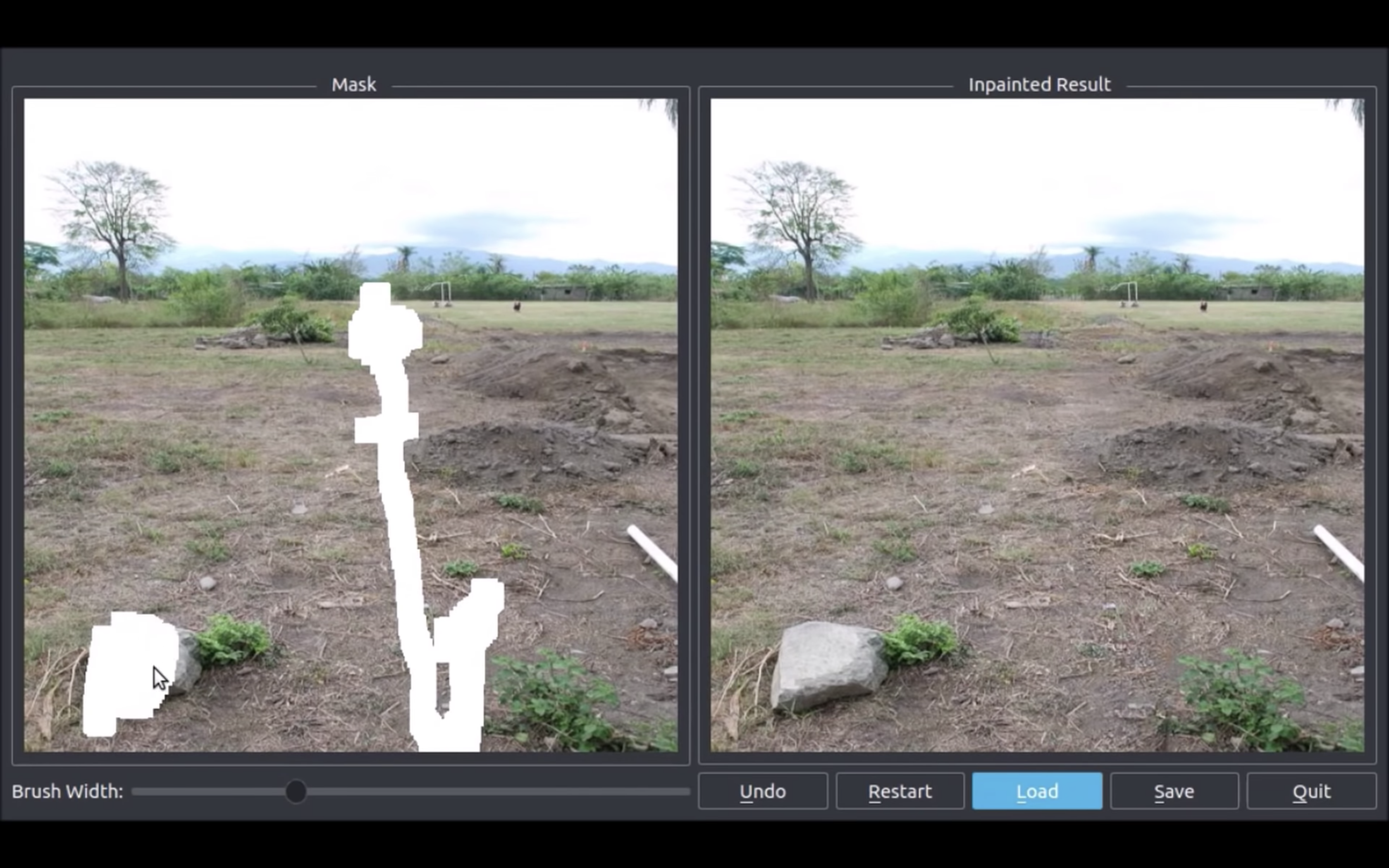

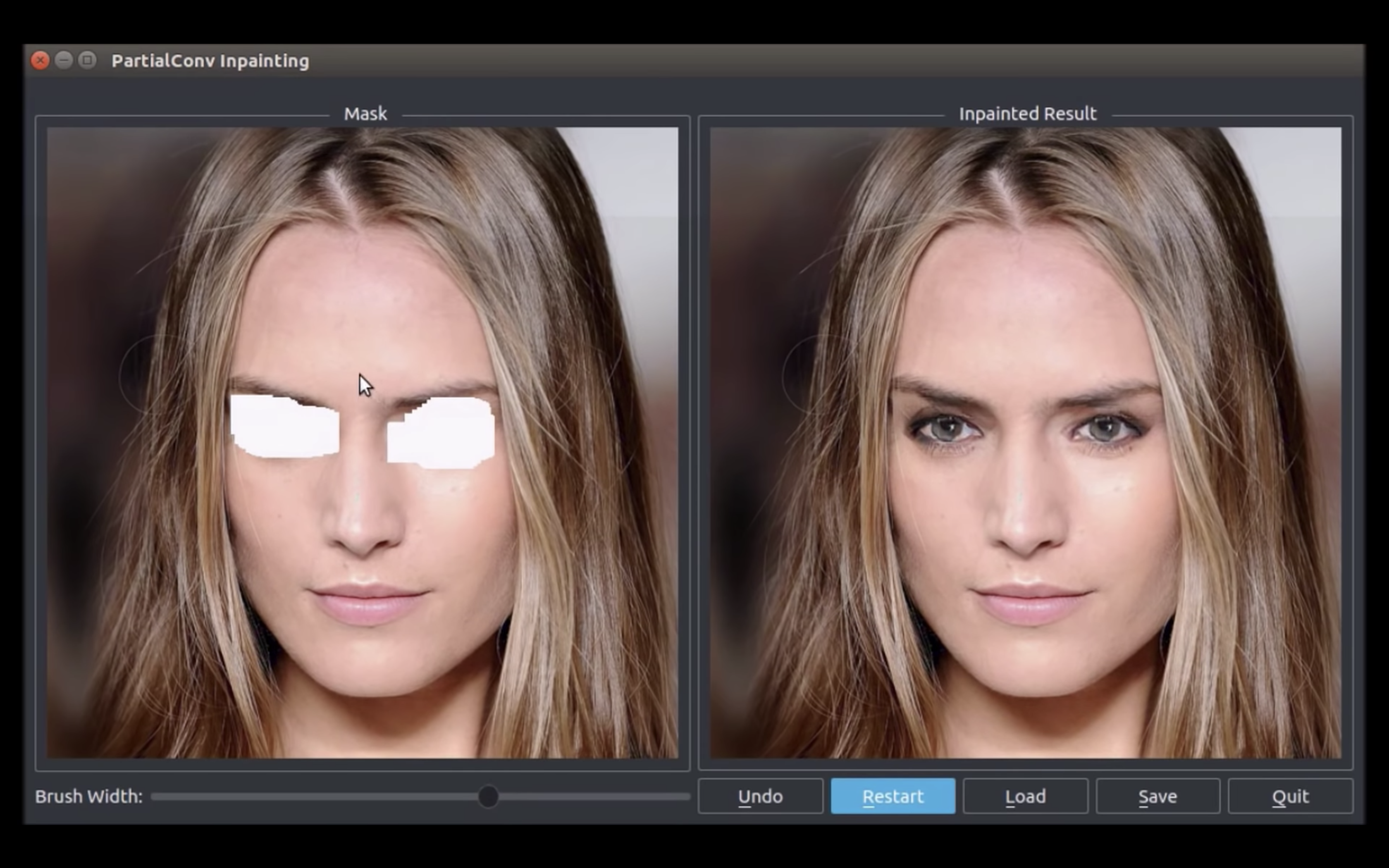
人の目を塗りつぶすと,目が補完されることがわかる.

以下は公式Youtubeのリンクです.
Research at NVIDIA: AI Reconstructs Photos with Realistic Results - Youtube
※arXiv,Githubのリンクは一番下にまとめています.
既存技術
- 画像の"穴"(上の写真の白く塗りつぶした箇所)に対して,正常なピクセルや,穴の代替値によって調整された畳み込みフィルタを利用した,典型的な畳込みネットワークによって画像修復を図る
問題点
- 色が一致しなかったりぼやけたりする問題がある
- 画像の中心付近にある長方形の領域に焦点を当てており,高価な後処理に依存がちで,尚且失敗する可能性もある
提案手法
- 不足している領域と元の写真の両方を調べることでピクセルを再構築する方法を学習した.
- その中でPartial Convolution(部分的な畳み込み)を提案する
- これは,有効なピクセルにのみ条件づけをするために,マスク化され,再度正規化された畳み込みのことである
- マスク画像を自動的に生成するというメカニズムが含まれ,他の不規則なマスクの生成方法よりも優れている
コントリビューション
- Image Inpainting(画像修正・補完)
- どんな形状,サイズのマスクでも、そして画像の四辺端っこに接した穴でさえも、堅実に対応可能
- マスク部分が大きくなっても精度が急激に低下することが無いため,任意の箇所を高精度で修復可能
- 大規模マスク画像の生成
- どのような穴があっても修正出来る,かつ追加の後処理は必要としないネットワークが理想.
- 汎用性の高いものにするために,様々なサイズの不規則マスク画像を用意して学習させる.
- 不規則な形状の穴でディープラーニングによる画像修復モデルの効果を実証するのは初の例
- この大規模なマスク画像のデータセットは,一般公開予定.
- 実験では穴の大きさだけではなく,それが画像の枠に接している場合の影響も調べる.
Partial Convolutional Layer
不規則なマスク画像を適切に扱うことが出来る層.
出力は欠損の無い領域にのみ依存し,マスク画像を更新するというステップも含んでいる.
少なくとも1つの有効な入力値(=穴でない,つまりマスクされていない箇所の値)で出力を調整出来る場合,その場所のマスクを削除する.
この層が十分な大きさであれば,マスク画像は徐々に縮小され,有効な値のみがfeature mapに残る.
引用: MathiasGruber/PConv-Keras/Step2 - Partial Convolution Layer.ipynb
既存技術についてもう少し詳しく
これまでは,画像の中心の周辺の短形領域に焦点を当て,高価な処理をして,後処理(=ぼやけた箇所などを修正することだと思われる)に頼っている.
この作業の目的は,不規則に空いてしまっている穴に対して、ロバストな画像修復モデルを作成することと,追加の後処理や,何かと混合するようなことを必要とせずに,画像修復を行うことである.
最近のDeepLearningを使用しない画像修復の手法では,画像の穴を埋めるのに統計的手法(image statistics)を使用する.
PatchMatchでは,穴を埋めるために,最も適切なパッチを繰り返し検索する.
メリット
- そこそこの結果が得られる(図1(b)参照)
デメリット
- 利用可能なimage statisticsによって制限がかかる
- visual semanticsという概念が無い
- 例えば,図1(b)ではPatchMatchは周囲の影や壁からの画像パッチを使用して欠落した部分をうまく埋めようとするが,semantically-aware approachは,変わりのペイントのパッチを使おうとする(would make use of patches from the painting instead.)
図1(e)(f)に,様々な穴に対して様々な初期値を利用した,典型的な畳込み層を有したU-Netアーキテクチャを使用した例を示す.

提案モデル
Partial Convolutionの積み重ねと,マスク画像の更新によって画像の修復を行っていく.
Partial Convolutional Layer
簡潔にするために,Partial Convolutional Layerとマスク画像更新機能をPartial Convolutional Layerとする.
全ての場所で,Partial Convolutional Layerは以下のように定義される.

$W$: 重み
$b$: バイアス
$X$: 現在の畳込みのウィンドウのfeature value(pixels value)
$M$: 対応するバイナリマスク
$1/sum(M)$: スケーリング係数.有効な(マスクされていない)入力の変化量を調整する
Partial Convolutionでは演算の度にマスクを更新する.
この機能は以下の式で表すことが出来,Forward Passの一部として簡単に実装出来る.
入力画像が有効な画素を十分に含んでいれば,最終的に全てのマスクは1になり,画像修正が完了ということになる.

実装
Partial Convolution層はPyTorchを拡張して実装した(参考にKerasとChainの再現実装のGithub有り).
画像と同じサイズの(CxHxW)バイナリマスクを定義し,部分畳み込み演算と同じカーネルサイズを持つ,固定畳み込み層を使用してマスク画像の更新する.
画像サイズが512x512の場合,全体の推論にかかる時間は,穴の大きさに関係なく0.23秒であった(NVIDIA V100 GPU).
ネットワーク
UNet-likeなアーキテクチャを設計した.
カーネルサイズは7,5,5,3,3,3,3,3.
チャネルサイズは64,128,256,512,512,512,512,512.
デコーダーは8つのアップサンプリング層を含んでいる.
デコーダー内のPartial Convolution層の出力チャネルは512,512,512,512,256,128,64,3.
Partial Convolution層では,画像の境界(=画像の外枠)付近では既存の畳込みは使用せず,マスキングで直接処理する.
よって画像の境界にある修復された内容は,画像の外にある無効な値の影響を受けなくなり,画像は別の穴と判断される.
実験
マスク画像データセット
これまでは画像内に,画像から短形領域をランダムに切り取ることでデータセットを作成してきたが,今回は,ここで説明されているように,ビデオの連続した2つのフレーム間のocclusion/dis-occlusion maskの推定方法の結果を参考にランダムな線や任意の形状を持ったマスク画像を作成した.
尚,作成したマスク画像の枚数は以下の通りである.
トレーニング用
55,116枚(512x512)
更に,この中からランダムにサンプリングした画像に対して,水増し(拡大,回転,切り取り)を行う.
テスト用
24,866枚(512x512)
同じく水増し(拡大,回転,切り取り)を行う.
Global and loccaly consistent image completionなどの既存の方法では画像の境界付近の穴で正しく修復出来ていなかった.
そのためテストセットは,外枠に近い穴がある場合と,無い場合の2つに分割した.
また,マスクの穴のサイズは6種類ある((0.01, 0.1], (0.1, 0.2],
(0.2, 0.3], (0.3, 0.4], (0.4, 0.5], (0.5, 0.6]).
それぞれは境界線の有無に関わらず1000個のマスクが含まれる.

トレーニング方法
NVIDIA Tesla V100 GPUとcuDNN、PyTorchを使用し,生成されたマスクをImageNet,Places2,CelebA-HQデータセットの画像に適用することによってニューラルネットワークを訓練します.
トレーニングの期間は,ImageNetとPlaces2は10日,CelebA-HQは3日間であった.
実験結果
以下の4つの方法を用いて比較していく.
| 方法 | 説明文 |
|---|---|
| PM | PatchMatch.最先端の非学習ベースのアプローチ |
| GL | Global and loccaly consistent image completion.Izukaらによって提案された方法 |
| GntIpt | Generative image inpainting with contextual attention.Yuらによって提案された方法 |
| Conv | ネットワーク構造は今回提案するものと同じだが,典型的な畳込み層を使用する方法 |
評価画像は12,000枚で,無作為にマスク画像を当てはめる.
GTは正解画像(Ground Truth).
ImageNet

Places2

PConvとConvの比較

CelebA-HQ

Quantitative comparisons
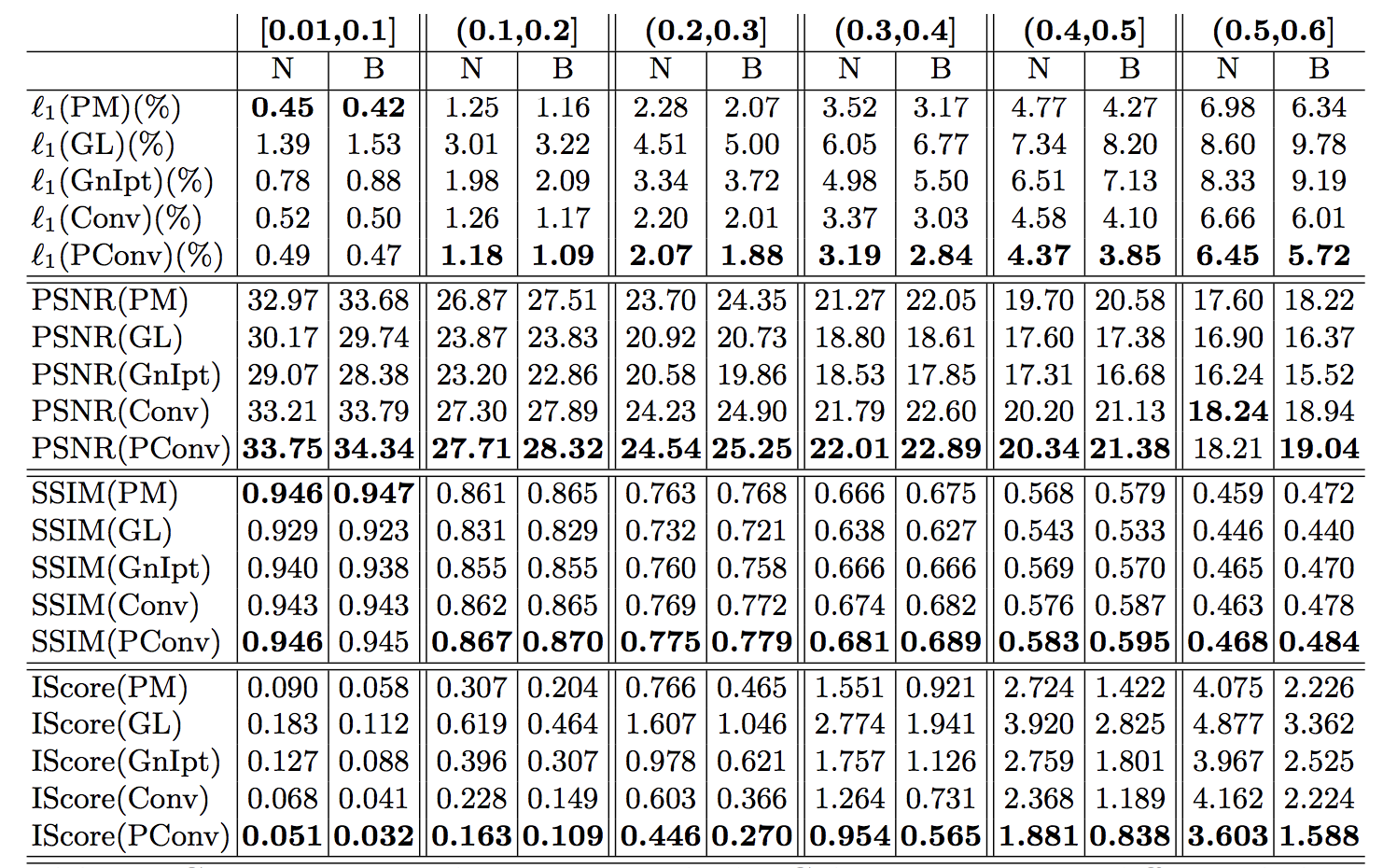
L1誤差を用いて,定量的な比較を行う.
各列は穴と画像の面積比を表し,Nは境界無し(No border),Bは境界有りを表す.
PConvは不規則なマスクに対して他のどの方法よりも有効な手段であることがわかる.
User Study
次は,定量的な評価ではなく,主観的な評価(A/Bテスト)をAmazon Mechanical Turk(MTurk)を用いて行う.
時間制限無し(A),有り(B)の2種類の実験がある.
- A
- PConvと他のネットワークによって生成された画像を比較
- グラフにはPConvの方が好まれた結果を表示している
- 50%である場合2つの方法が等しいことを表す
- 1行目は,穴が境界に触れてはならないが,2行目はそれが許されている
- B
- 時間は250ms,1000ms,4000msの3種類
- GTが他の方法より好まれている割合をグラフに示しており,曲線が低いほどよいことを示す
- 提案手法のPConvは,おおよそ他の手法より良いことを示している

参考
公式
- arXiv: Image Inpainting for Irregular Holes Using Partial Convolutions
- Youtube: Research at NVIDIA: AI Reconstructs Photos with Realistic Results
再現実装
- Keras: MathiasGruber/PConv-Keras
- Keras: chuangtc/PConv-Keras
- 上のKerasで書かれたものをForkして食べ物の画像を用いてやってみたもの
- Jupyter上だけでなくコマンドラインを用いて実行できるPythonファイルが入っていて参考になりました
- Chainer: SeitaroShinagawa/chainer-partial_convolution_image_inpainting