はじめに
みなさんこんにちは。Qiitaで記事を書くのも数年ぶりとなりました。
その間に紆余曲折あり、配信を始めたと思ったら、Vの体を手に入れて、
転職をし新しくサービスを立ち上げ今運営をしています。そのサービスがWilladgeという配信者さんの情報共有サイトというものです。早い話が「配信者特化バージョンQiita」といえます。
今回はそのサイトを運営しているとき、GoogleAnalyticsを見ていたときのことでした。半年経過してこのサイトの利用者さんを洗い出してみると、このような結果が出てきました
・ モバイル、特にiPhoneで見ている人がめっちゃ多い。9割くらいいる
・ Twitter広告で見ている方はやはり配信をこれから始めたい人だが、トップページを見るだけで帰っているケースが多い
この2つのうち後者に対してなにかアプローチをしたいと考えた結果以下のような仮説が思い浮かびました。
”もしかして、サイト見に行ってみたら文字媒体だから避けようとした?”
そうだとすれば、どう生き残ればいいのか?そう考えたときに思いつきました
「タイパよくこなしたい方のために、もしくは情報にたどり着く障壁をもっと小さくするためにAIを作ってご案内してしまえばいいのではないか」という仮説をたて、作ることにしました。
かんたんにはいいますが私が人工知能を最後に触れたのは2年前。しかもPytorchがリリースされたてのときという時代背景からだいぶ時間が経過しています。そんな筆者でもできるのかどうかが不安でしたがなんとか作成できるまでに至りました。
これからサービスをリリースして運用に回るまでのフェーズの中でどういうふうにAIを開発していったのかを綴っていこうと思います。
目次
1. 作成した環境
2. 使用したソフト
3. 環境づくり
4. データセットの作成
(ここまでが前編)
5. 実装
6. 実装で躓いたポイント
7. 学習
8. 結果
9. まとめ
10. 今後の課題
作成した環境
環境は以下です
OS:Winodws10
Python:3.12.8
フレームワーク:Pytorch
学習モデル:Google-Gemma2b,Open-calm-1b
学習セット:Willadgeの記事のすべてをピックアップしたもの
GemmaはGoogleからリリースしている学習モデルです。今回は2億のパラメータを利用できるものを利用しました。また、Open-Calmはサイバーエージェントが開発した学習モデルです。それぞれをHuggingFaceからダウンロードし、転移学習を行いました。
今回使うWilladgeの記事は30記事ほどしかなく、まだまだ利用するにはデータの数が少なすぎますが、順次増やすことでこれらを補填していきたいと思っています。こちらもデータをHuggingFaceにアップロードして作成しました。
使用したソフト
Anaconda(Python環境)
Python環境を作成するときに必要でした。このソフトの選定理由は2つです
・ 学生時代につかっていたソフトであるため、勝手がわかっているから
・ JupyterNoteBookとVSCodeの相性がいいから(他でもつかえるかもだけど)
Cursor (コーディング環境)
VSCodeベース(多分)でOpenAIが合体したようなソフト。
プロンプトを打って相談したり、やってほしい作業を入力すると自動的にコードを打ってくれる機能が入っている。
これで動かして、テストしてを繰り返してコーディングする。もちろん動作原理の勉強はわすれずにね。
Github (ソースコード管理)
数年の時を経ると有料だったプライベートリポジトリも無料になりましたね。(何年前の話をしているんだ)
これもソース管理するには必須のツールですから使っていきます。
CUDA+CuDnn (GPUプログラミング)
ソフトといえるかはわからないけど、この環境入れてないと時間がどんどん溶けます。入れておきましょう
タスクマネージャ(負荷監視)
これ紹介する必要あるんか?と思った方、私も迷ったんですが、
2つの観点から必要だと思ったので起動しながら監視しておくといいと思います
・ メモリに負荷がかかり過ぎてしまわないように
・ 学習ができているかの確認(とある項目の負荷がかかっていないと学習できていないことが判別可能)
環境づくり
Anacondaや、Cursor、Githubはナレッジが豊富なため省略しても問題ないと思います。
一番苦労したのはCUDAとCuDNNでした。
CUDA,CuDnn導入
ポイントは2点です
・ 対応バージョンをあわせること
・ 環境変数を設定できていること
以下の記事を参考にしました。
CUDA+cuDNNのインストールまとめ
PyTorch GPU 環境構築
私の場合は、CUDAのバージョンを対応するPytorchのバージョンに合わせるとこからはじまりました。
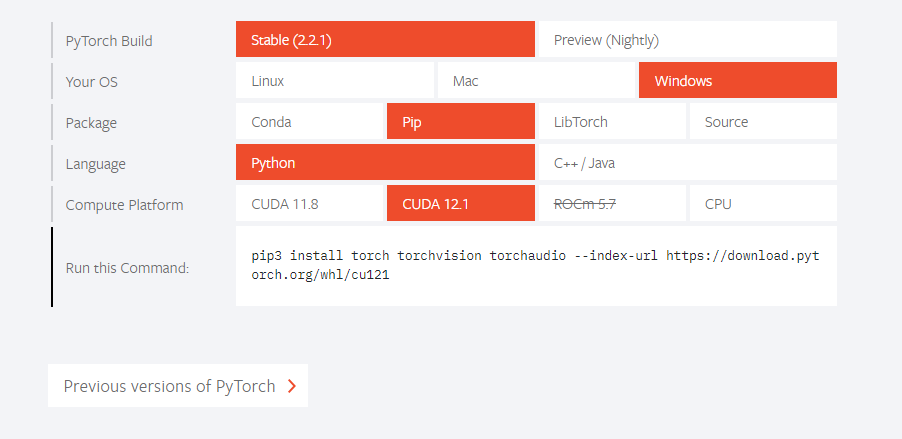
今回はCUDA11.8をインストールすることにし、それに伴いCuDNNは8.9.7にしました。
まずはCUDA11.8をダウンロードします。
https://developer.nvidia.com/cuda-12-1-1-download-archive
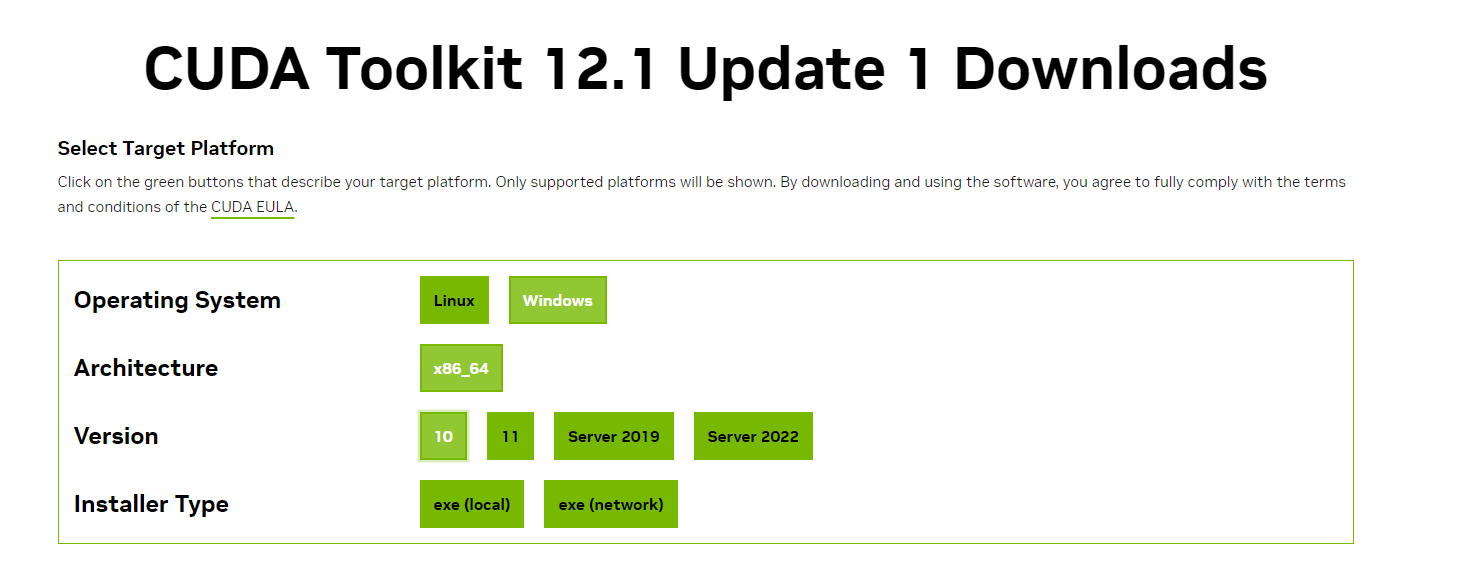
大学時代の教授の言葉で「ローカルでダウンロードすることをおすすめします」と言っていたので今回も教授の言葉を信じてローカルで入れます。
環境変数が通ってることも確認しましょう。
nvccコマンドで確認できると思います
nvcc -V
その後、CuDNNを入れます。
https://developer.nvidia.com/rdp/cudnn-archive
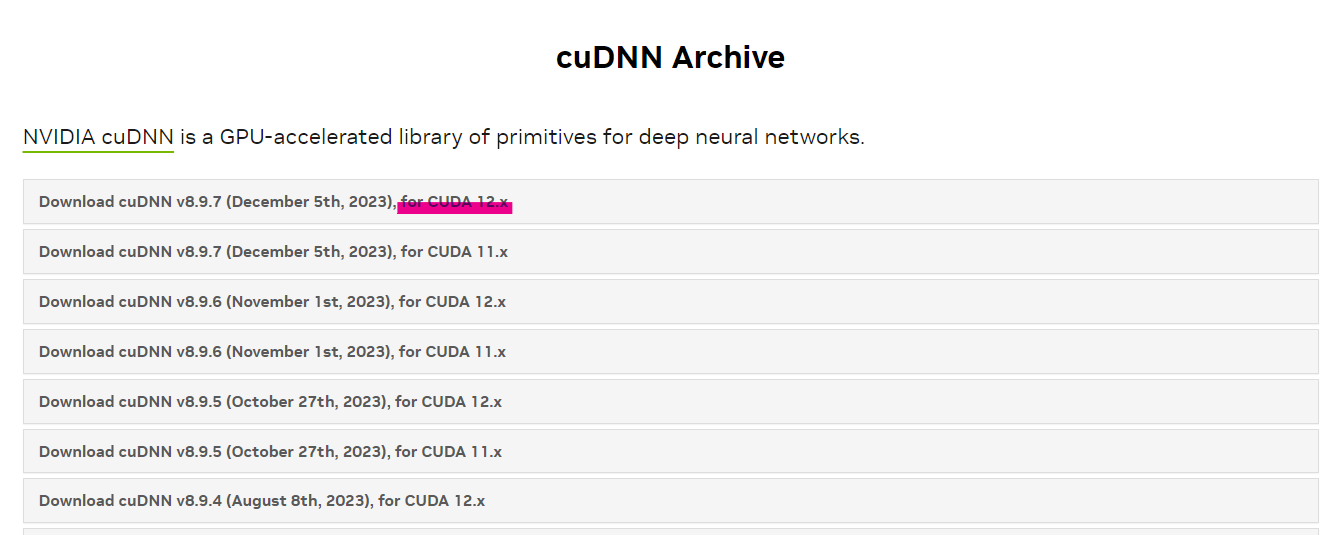
大体バージョンが合うもので新しいものを入れておけば間違いないと思います。
whereコマンドで該当するDllが入っているか確認しましょう
where cudnn64_8.dll
これで長いGPUプログラミングの旅は終了です。
データセットの作成
結果から言うとSQLでWilladgeのデータをとってきて、Pythonでそのデータを加工しJsonで出力するプログラムを組みました。以下はサンプルコードになります。
# SQL
import json
import mysql.connector
# MySQL
from sshtunnel import SSHTunnelForwarder
import pymysql.cursors
# MySQL接続
connection = mysql.connector.connect(
host='ホスト名',
user='DBユーザ',
password='DBパスワード',
database='DB名',
port='3306'
)
# DBの接続確認
if not connection.is_connected():
raise Exception("MySQLサーバへの接続に失敗しました")
# 取得結果を辞書型で扱う設定
# カーソル作成
cursor = connection.cursor()
query="""SELECT page_id, page_namespace, page_title, page_latest "rev_id", old_text "text"'
'FROM page'
'INNER JOIN slots on page_latest = slot_revision_id'
"INNER JOIN slot_roles on slot_role_id = role_id and role_name = 'main'"
'INNER JOIN content on slot_content_id = content_id inner join text on substring( content_address, 4 ) = old_id and left( content_address, 3 ) = "tt:" and old_flags = "utf"'
"""
# クエリ実行
cursor.execute(query)
# 結果取得
results = cursor.fetchall()
# Jsonファイルに変換して保存
with open('output.json', 'w') as f:
json.dump(results, f)
# MySQL接続をクローズ
connection.close()
このコードは自分が運営しているDBに
これにより抽出されたデータをHuggingFaceにアップロードしてまずは学習させるデータを抽出しました。
のちほど課題となるとは思いますが、ひとまずはこれでいきます。
それでは次回は実装をしていこうと思いますので、そのときに躓いたポイントなども合わせて共有できればと思います。