SRE Advent Calendar 2019 18日目の記事です。
https://qiita.com/advent-calendar/2019/sre
タイトルの意味は、「今後AIOpsを実践するのは、SREs の皆さんだ!」 です(意訳しすぎ?)。なおこのタイトルは、かつひささん が、NoOps Meetup#6(2019/6/4) に登壇された際のタイトル NoOpsを実現するSREの存在意義と役割 / class SRE implements NoOps を流用させていただいています!
ベースは、多分 The Site Reliability Workbook 第1章のサブタイトル(class SRE implements interface DevOps)です。
この記事では、AIOps 時代におけるシステム運用にてSREがどのような関係となるのか整理してみました。なお、AI(Artificial Intelligence)に関する技術的な内容は含んでいません。
AIOps とは
まず、AIOps とは何か、です。
現在AIOps という用語(バズワード)は、一般的に次の2つの意味で使われています。
- ① AI機能自体を運用する ≒ MLOps とも言われることがある
- ② AI技術を活用してシステム運用を行う
この記事では、主に②の意味でのAIOpsとして、次のようなGartnerの定義で考察を行っています。
AIOpsとは
ビックデータと機械学習を組み合わせることで、ITオペレーションの主要機能を高度化・自動化し、
「可用性とパフォーマンスのモニタリング」
「イベントの相関と分析」
「ITサービスの管理と自動化」などを行うこと(Gartner 2016)
AIOpsのイメージを以下に示します。
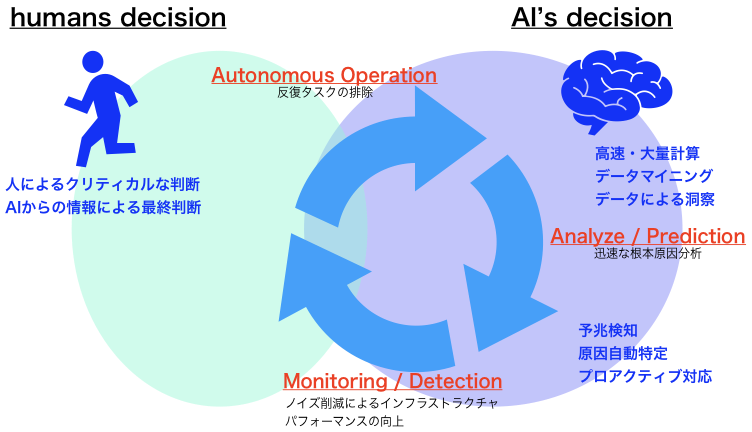
- 「ITサービスの管理と自動化」→ 反復タスクの完全排除
- 「可用性とパフォーマンスのモニタリング」→ モニタリングノイズを削減しインフラストラクチャパフォーマンスを向上させる
- 「イベントの相関と分析」→ 迅速な根本原因の分析と特定
これらは、従来のシステム運用管理でも取り組んでいたプロセスそのものになりますが、AIOpsではAI技術を活用してオペレーションを今以上に自動化・自律化していくことがポイントになります。
またAIOpsは、以下のような環境の変化に伴って必然的に利用することにならざるをえないと思います。
- 人が対応できない規模での管理対象数の増加、種類の増加
- 人による集計・分析できないデータ量の増加
- ビジネススピードの要求、ITシステムのビジネスインパクト直結化
- METI:2025年の崖
- 技術の急激な進化(5G, IoT, 機械学習・深層学習, 自動化、他)
そして、これらの環境の変化にSREの業務が深く関わってくるものと考えています。
SREが深く関与していく要素 (NoOps 的観点)
- Observability (可観測性)
- Configurability (構成設定管理)
- Predictability (予測可能性)
- Resiliency (回復性)
- Safety (安全性)
- Autonomy (自律運用性)
システム運用において何をAIに任せるのか
では、次にシステム運用におけるその作業難易度(縦軸)と運用技術者のノウハウ(横軸)との関係から、今後AIにどの部分を任せるべきか考えてみます。
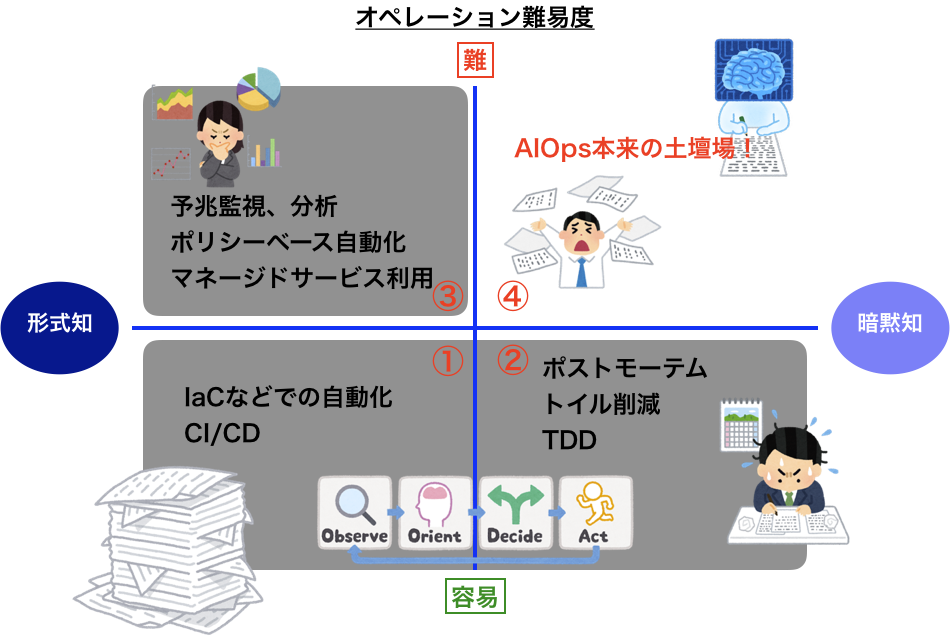
各象限について、現在(2019/12)どのような効率化・自動化ができているか以下に示します。
- ①オペレーションが比較的簡単・単純なものや、繰り返し作業、数が多いものなどについて、様々な仕組みや手順で効率化、自動化を実現しています。
- ②ノウハウが要員の暗黙知1に依存している場合、できるだけ形式知化していくような活動を実施します。ドキュメント化したり、自動化していく標準化活動を進めていきます。ここでは主にリアクティブな対応となります。
- ③プロアクティブに自動化を進めていく仕組みを活用して、かなりの判断を機械に任せていくようにします。
- ④現時点では、実現できていない世界です。真のAIOpsとしては、この象限をAIに任せていく必要があると考えます。
筆者の整理では、以下のようになると考えています。
| DevOps | ①+② |
| NoOps | ①+②+③ |
| AIOps | ①+②+③+④ |
システム運用にて現時点(③)でAI に任せられること
上記図の③での現在の技術でAIに任せられる点は以下のようなものになります。
- 早期に異常を予測・検知する
- 大量のデータを分析する
- ポリシーベースで決められた範囲で自動修復・保護する
- 初期オンコール対応(ナレッジベース)
システム運用者は、このようなAIが通知・洞察した「重要な異常」状態を最終判断(予算、SLA、ビジネスインパクト..)し、対処を決定する(承認する)ことになります。
(現時点で)AI が実現することが遠いこと
以下は、現状AIでは実現が容易でない事項(チャレンジ項目)になります。
- 未定義の事象に対して、機械学習結果をもとに適切な判断と処置を自律的に実施する(失敗が許されない状況において)
- システム要件(機能要件、非機能要件)との解離を判断し、AP開発・システム構成(変更)設計・製造を自動的・自律的に行い、再配置する
Resiliency (回復性)をAIで実現することが一番難易度が高いと思います。
言い換えると、これらができるようになると、AIによる学習や洞察での完全自動化・自律化が近くと思います。
(参考)AIOps を称しているプロダクトの現状
現状、AIOpsを称している商用プロダクトは、上記図の③ができつつあるものが大半だと思います。
特にイベントの高度な集約や予兆検知を行う、という点に注力されています。
現時点では、AIOpsはツールを利用したソリューション提供型が多くなっています。
-
AppDynamics
- Cisco との連携
- 可視化、Insight, アクション
-
BMC TrueSight
- 性能、セキュリティ、コストに対するソリューションを提供
-
FixStream
- オーピンデータ取り込み
- 自動検出、相関関係、可視化、機械学習、自動化
-
MICRO Focus AIOps for Cloud Monitoring: Operations Bridge
- AIOps アナリティクス
-
OpsRamp
- インテリジェントなイベント管理、強力なアラート相関、迅速な修復を備えた世界初のサービス中心のAIOpsプラットフォーム
- イベントの集約、アラートの相関・洞察、アラートエスカレーション、自動修復
-
Optanix for AIOps
- ソリューション
- フルスタックの検出と監視、予測分析とスマート分析、真の実用的な根本原因分析、ビジネスサービスの優先順位付け
-
ScienceLogic
- データ分析が主要なソリューション
-
StackState
- monitoring and AIOps platform for hybrid IT
-
IBM
- Big Blue AI !
-
Moogsoft
- Event Ingestion, Noise Reduction, Correlation and Detection, Causality, Collaboration
-
Red Sky Ops
- サイオステクノロジープレスリリース(2019/10/23)国内初、AIOpsツール「Red Sky Ops」の取り扱いを開始
- Linuxコンテナー操作を自動化するオープンソースプラットフォームであるKubernetesの環境をAI(人工知能)や機械学習によって最適化するソリューションです。
上記製品一覧は、以下のレポートを参考にしています
その他
-
AWS Summit 2019 Tokyo より
- クラウド運用管理の最前線 ~日米の最新状況から~
- 次世代のクラウドマネージメントの説明で、Machine Learning Enablied と表してAIOps に関係する説明がされていました。
- キャパシティプランニング
- Rredictive Scaling for EC2
- Tried Storage - Intelligent-Tiering
- 異常検知
- Amazon Kinesis Data Analytics - RANDOM_CUT_FOREST
- ノイズキャンセンリング
- Amazon CloudWatch Math Expression
- Resiliency
- 回復力、回復機能
- システムやネットワークが障害発生後に元の正常状態に戻すこと
- Error Ingestion
- 障害発生時にシステムが想定どおりに振舞うことを確認するために継続的かつ意図的に障害を引き起こす
- Chaos Engineering
- キャパシティプランニング
- Red Hat Decision Manager
- IBM Resiliency Orchestration
AIOps までの道筋 (AIOps Journey) とSRE の役割
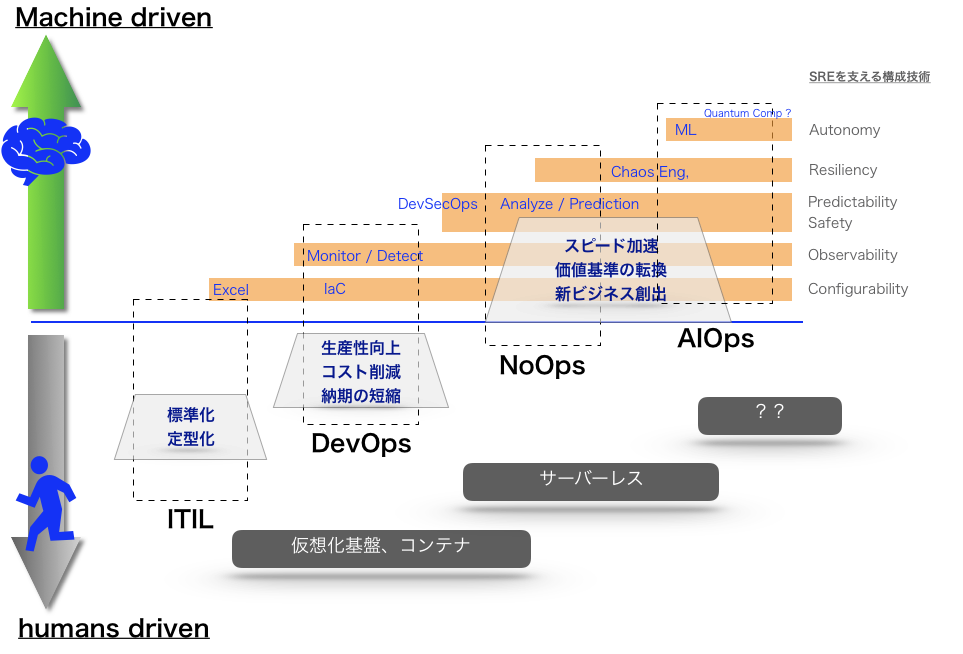
時間軸で見ていくと、ITIL → DevOps → NoOps → AIOps と進んでいき、人手による操作や作業はほとんど無くなっていく、という未来予想になっています。
- この図のベースは、2018/5 日経システムズ NoOpsがやってきた の図2を参考にして、AIOps を追記したものになります。
SREで活躍されている方々は、NoOpsの領域の実現を日々目指して活動されていると思います。今後AI技術をシステム運用に取り入れていく方向であったとしても、ベースとなる活動の違いはないと思います。
- SREが継続・強化すること
- 自動化の推進の継続
- 故障を前提とした設計 (Design for Failure)
- 回復性設計 (Design for Resiliency)
- AIを使うことでの新たな活動
- AIエンジンの設定や必要なデータの受け渡し
結果的には、もう一つの意味でのAIOps(AI 自体の運用管理)を行うエンジニアリングが必要になってくるのでしょう。
システム運用においてAIに何を学習させるべきか
話は少し脱線して、システム運用においてAIは何を学習していけば良いのか考えてみます。
NECが考える「AI」とは にある考え方(AI技術の方向性)を参考にさせてもらっています。
システム運用でAIに学習させる事項として以下が考えられます。
- AIに学習させる「ゴールの定まらない問題」
- SREの暗黙知
- AIに学習させる「ゴールが定まった問題」
- ベストプラクティス
- ポストモーテム
- 要求定義、システム設計書
- テスト設計、実行結果
- IaC コード
- ベストプラクティス (AWS Well-Architectedなど)
- 監視ログ
- 障害ナレッジ
- セキュリティインシデント
- オンコール対応
SREの暗黙知は、「ゴールの定まった問題」を大量に学習させること、想定外の対応での人のオペレーションの動きを学習させる、などでデータを収集することが考えられますが、もっと独創的な方法が見出されるかもしれません。
その「暗黙知」学習データは、企業秘密か、社会資産となるかといった新たな課題も出てくると思います。
気になる自動化関連技術
今後、AIOpsを検討するにあたって詳細に見ていきたい技術やソリューションを以下に示します。
- Zebrium
- https://www.zebrium.com
- AIを活用したソフトウェア障害解析の自動化ソリューション、研究テーマ
- Zebriumの目指すところは、人間の関与なしに自動的に障害箇所を特定すること
- 参考: https://codezine.jp/article/detail/11794
- Intent Based Network (IBN)
- Chaos Engineering
-
Googleが従業員に対して実践している「カオスエンジニアリング」とは?
- オペレーション自体をカオスに行うという記事
- 【Chaos Conf 2019 視察レポート】Chaos Engineeringの盛り上がりを実感
-
Googleが従業員に対して実践している「カオスエンジニアリング」とは?
さらなる未来
現実的に、SREの保有する暗黙知を「機械」が習得するには単に大量なデータを集めれば良いだけではなく、ベースとなる技術革新が更に必要になってくると思います。その一端が以下のような研究テーマに見て取れます。
- 量子コンピューティング
-
超個体型データセンタ
- さくらインターネット研究所が提唱している、独立分散型のデータセンタ構想
- 可搬性の高いコンテナ型データセンタ
- HPE、データセンター運用におけるAI活用の研究を米国立再生可能エネルギー研究所と共同で実施

まとめ
AIが技術的に進化し、必要不可欠となってくることは、そう遠くはないと思います。その中で、SREは今まで以上に重要な役割を負うことになると思います。SREの活動自体の一部(もしくはほとんど)が機械学習の対象となっていき、その仕組みやデータ取り扱いなど今後研究されていくものと思います。
今後のAI技術の進化を注視しつつ、(ビックバン的にではなく)少しずつ上手く活用できることを考えていきたいです。

and I can't wait to SRE NEXT!
-
②の「暗黙知」は、正確には「暗黙知」と言えず、整理ができていないような形式知と言った方がいいかもしれません ↩