はじめに
Azure Synapse Analytics では Spark Pool を利用して、Spark 処理を実行することが可能です。
今回は Spark Pool から ADLS Gen2 に接続する際の方式を説明します。
ストレージの種類
Azure Synapse Analytics で利用するストレージは 2 種類存在します。
| # | 名前 | 説明 |
|---|---|---|
| 1 | Primary Storage | Synapse ワークスペース作成時に指定するストレージであり、Spark Application Log などが格納される |
| 2 | Non-Primary Storage | 上記以外の任意のストレージであり、Spark 処理対象のデータなどの格納先として利用される |
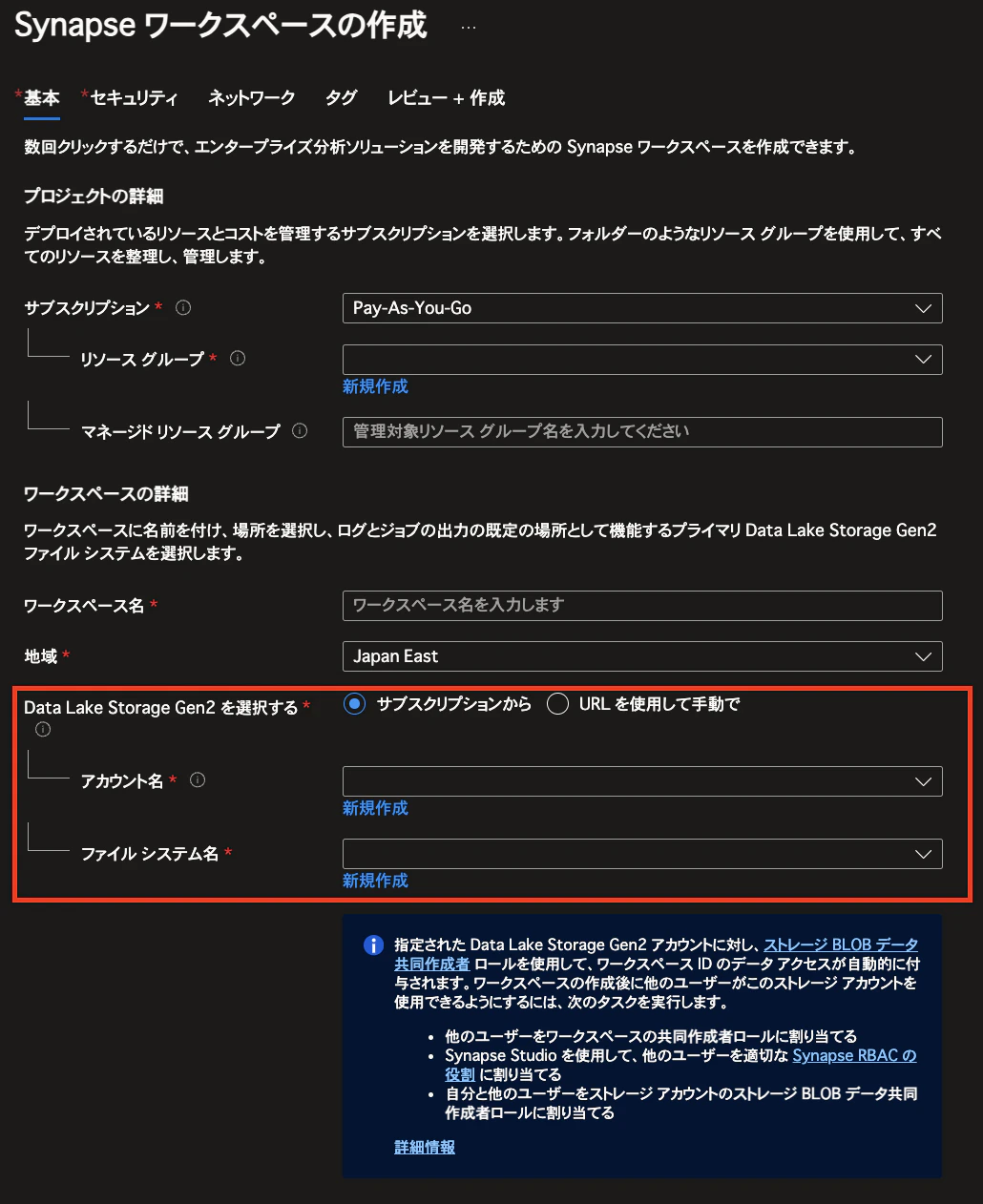
Primary Storage は、下図のように Synapse Analytics ワークスペース作成時に指定できます。
ネットワーク
Azure Synapse Analytics ではマネージド仮想ネットワークを指定できます。これを有効化することで、Spark Pool から他の Azure サービスにマネージド プライベート エンドポイント経由で接続できます。
マネージド仮想ネットワーク無効のとき、Spark Pool から ADLS Gen2 への接続はパブリックとなります。
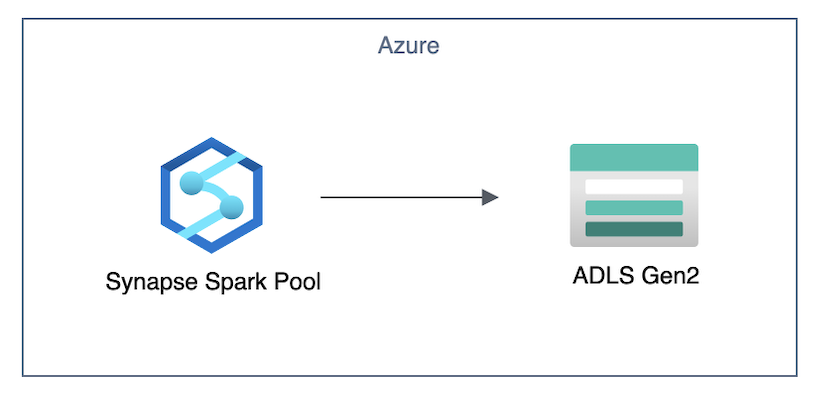
マネージド仮想ネットワーク有効でマネージド プライベート エンドポイント未作成のとき、Spark Pool から ADLS Gen2 への接続はパブリックとなります。
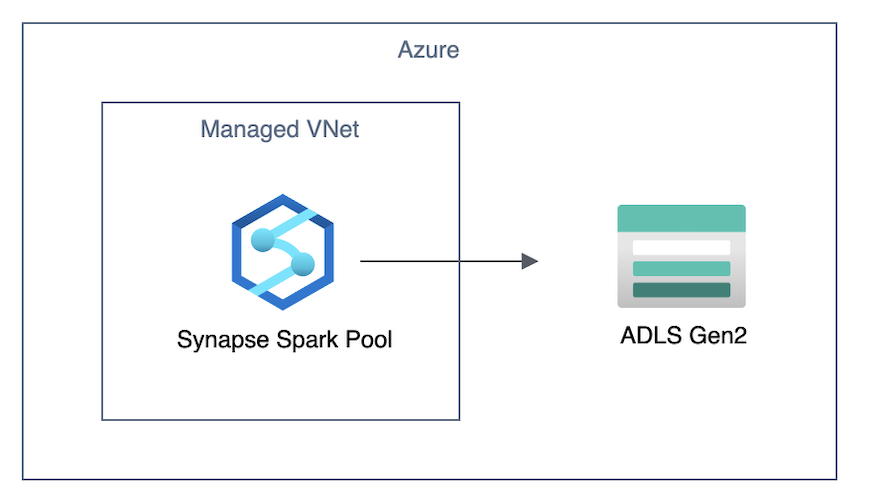
マネージド仮想ネットワーク有効でマネージド プライベート エンドポイント作成済みのとき、Spark Pool から ADLS Gen2 への接続はプライベートとなります。

コード実行方法
Spark Pool でコード実行する方法は 2 種類存在します。実行方法によって使用される権限が異なることに注意しましょう。
| # | 名前 | 説明 | 使用される実行者権限 |
|---|---|---|---|
| 1 | ノートブック実行 | ノートブック画面から実行する方法 | Synapse ワークスペース ログイン ユーザー |
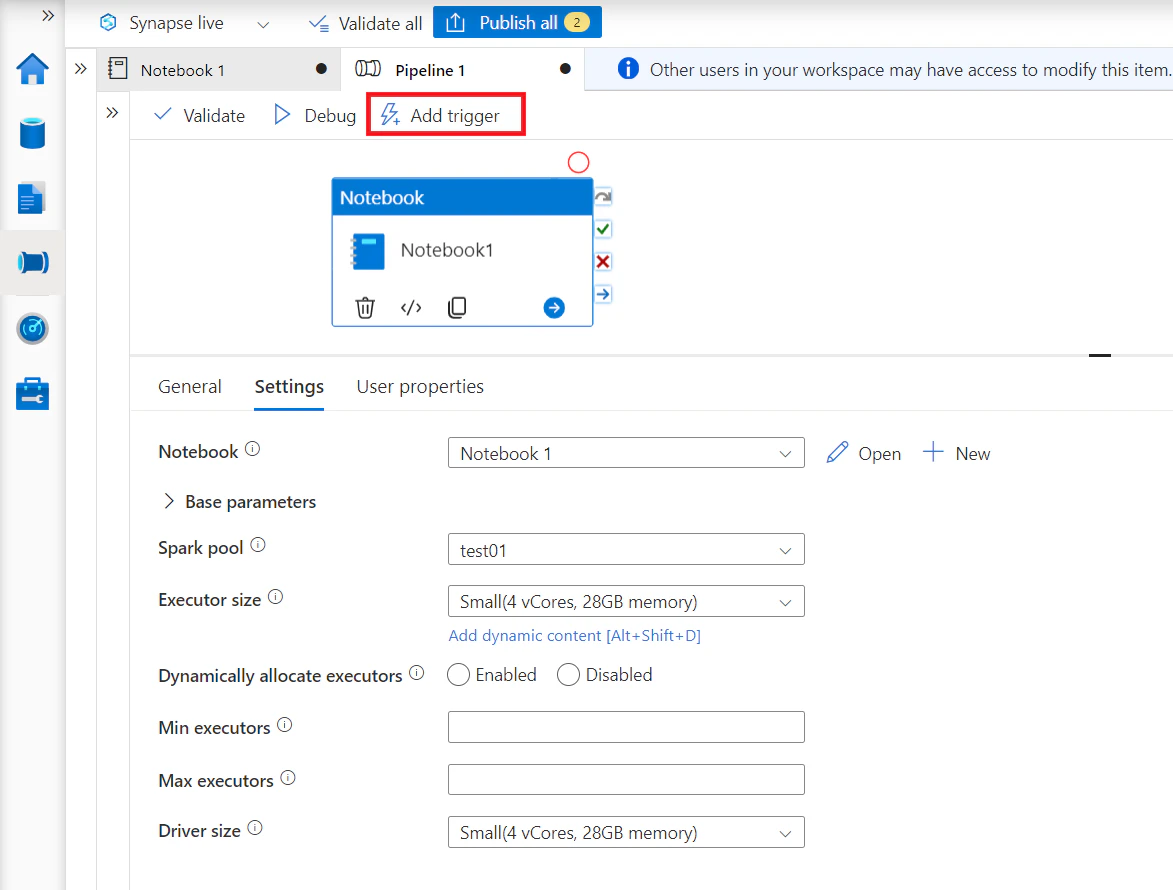
| 2 | パイプライン実行 | パイプラインのノートブック アクティビティから実行する方法 | Synapse ワークスペース System Managed ID |
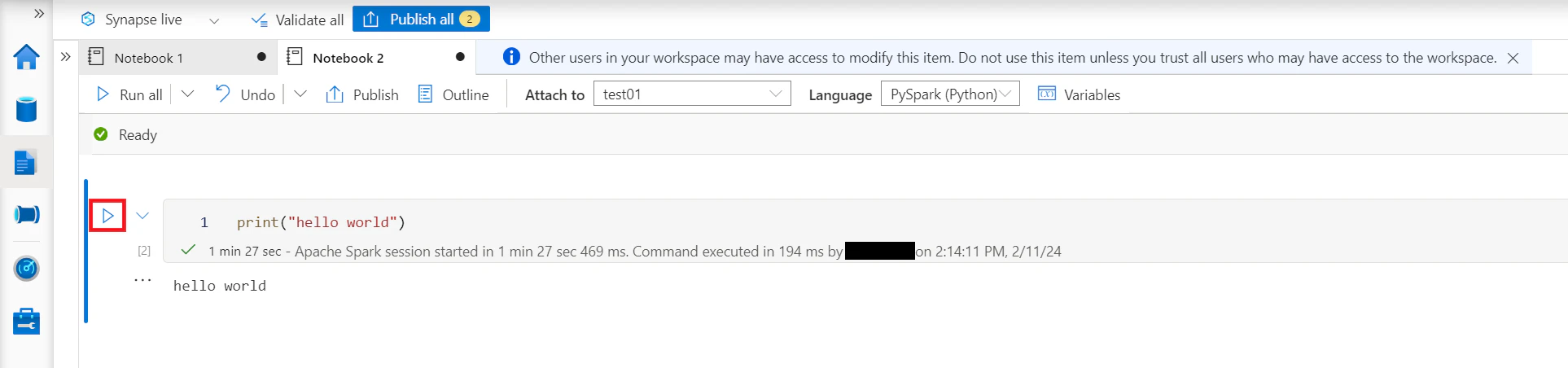
下図はノートブック実行を表します。
下図はパイプライン実行を表します。
認証
5 つの認証パターンを説明していきます。各認証パターンの利用可否を纏めたものが下表となります。
| Primary Storage (spark) | Primary Storage (pandas) | Non-Primary Storage (spark) | Non-Primary Storage (pandas) | |
|---|---|---|---|---|
| 実行者権限 | ◯ | ◯ | ◯ | ◯ |
| リンクサービス | ✕ | ◯ | ◯ | ◯ |
| アカウントキー | ✕ | ◯ | ✕ | ◯ |
| SAS トークン | ◯ | ◯ | ◯ | ◯ |
| サービス プリンシパル | ◯ | ◯ | ◯ | ◯ |
1. 実行者権限
コードの中で認証情報を記載しない場合、実行者の権限に基づきストレージへのアクセス可否が決定します。アクセスを許可したい場合は実行者にストレージ BLOB 共同作成者の権限を付与します。
すなわちノートブック実行のときは Synapse ワークスペース ログイン ユーザーに、パイプライン実行のときは Synapse ワークスペース System Managed ID に権限を付与することになります。
なお、 Synapse ワークスペース System Managed ID にはワークスペース作成時に自動でストレージ BLOB 共同作成者の権限がストレージに付与されます。
spark、pandas でのサンプルコードは以下となります。
%%pyspark
df = spark.read.load("abfss://<CONTAINER>@<STORAGE_ACCOUNT>.dfs.core.windows.net/input/test.csv", format="csv")
df.show()
df.write.format("csv").mode("overwrite").save("abfss://<CONTAINER>@<STORAGE_ACCOUNT>.dfs.core.windows.net/output")
%%pyspark
import pandas as pd
df = pd.read_csv("abfss://<CONTAINER>@<STORAGE_ACCOUNT>.dfs.core.windows.net/input/test.csv")
print(df)
df.to_csv("abfss://<CONTAINER>@<STORAGE_ACCOUNT>.dfs.core.windows.net/output/test.csv")
2. リンク サービス
事前に設定した ADLS Gen2 のリンク サービスを利用する際のサンプルコードは以下となります。Primay Storage は spark で失敗するので注意しましょう。
%%pyspark
spark.conf.set(f"fs.azure.account.auth.type", "SAS")
spark.conf.set(f"fs.azure.sas.token.provider.type", "com.microsoft.azure.synapse.tokenlibrary.LinkedServiceBasedSASProvider")
spark.conf.set(f"spark.storage.synapse.linkedServiceName", "<LINKED_SERVICE>")
df = spark.read.load("abfss://<CONTAINER>@<STORAGE_ACCOUNT>.dfs.core.windows.net/test.csv", format="csv")
df.show()
df.write.format("csv").mode("overwrite").save("abfss://<CONTAINER>@<STORAGE_ACCOUNT>.dfs.core.windows.net/output")
%%pyspark
import pandas as pd
df = pd.read_csv("abfss://<CONTAINER>@<STORAGE_ACCOUNT>.dfs.core.windows.net/test.csv", \
storage_options={"linked_service":"<LINKED_SERVICE>"})
print(df)
df.to_csv("abfss://<CONTAINER>@<STORAGE_ACCOUNT>.dfs.core.windows.net/output/test.csv")
3. アカウントキー
ADLS Gen2 のアカウントキーを利用する際のサンプルコードは以下となります。
先述の通り、spark では Read/Write 処理両方に成功することはありませんので、アカウントキーを利用するときは pandas の利用が必須となります。
%%pyspark
spark.conf.set("fs.azure.account.key.<STORAGE_ACCOUNT>.dfs.core.windows.net", "<ACCESS_KEY>")
df = spark.read.load("abfss://<CONTAINER>@<STORAGE_ACCOUNT>.dfs.core.windows.net/test.csv", format="csv")
df.show()
df.write.format("csv").mode("overwrite").save("abfss://<CONTAINER>@<STORAGE_ACCOUNT>.dfs.core.windows.net/output")
%%pyspark
import pandas as pd
df = pd.read_csv("abfss://<CONTAINER>@<STORAGE_ACCOUNT>.dfs.core.windows.net/test.csv", \
storage_options = {"account_key": "<ACCESS_KEY>"})
print(df)
df.to_csv("abfss://<CONTAINER>@<STORAGE_ACCOUNT>.dfs.core.windows.net/output/test.csv")
4. SAS トークン
ADLS Gen2 の SAS トークンを利用する際のサンプルコードは以下となります。
%%pyspark
spark.conf.set("fs.azure.account.auth.type", "SAS")
spark.conf.set("fs.azure.sas.token.provider.type", "com.microsoft.azure.synapse.tokenlibrary.ConfBasedSASProvider")
spark.conf.set("spark.storage.synapse.sas", "<SAS_TOKEN>")
df = spark.read.load("abfss://<CONATINER>@<STORAGE_ACCOUNT>.dfs.core.windows.net/test.csv", format="csv")
df.show()
df.write.format("csv").mode("overwrite").save("abfss://<CONTAINER>@<STORAGE_ACCOUNT>.dfs.core.windows.net/output")
%%pyspark
import pandas as pd
df = pd.read_csv("abfss://<CONTAINER>@<STORAGE_ACCOUNT>.dfs.core.windows.net/test.csv", \
storage_options = {"sas_token" : "<SAS_TOKEN>"})
print(df)
df.to_csv("abfss://<CONTAINER>@<STORAGE_ACCOUNT>.dfs.core.windows.net/output/test.csv")
5. サービス プリンシパル
サービス プリンシパルを利用する際のサンプルコードは以下となります。
なお、サービス プリンシパルに ストレージ BLOB 共同作成者の権限を付与しておく必要があります。
%%pyspark
spark.conf.set("fs.azure.account.auth.type", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id", "<CLIENT_ID>")
spark.conf.set("fs.azure.account.oauth2.client.secret", "<CLIENT_SECRET>")
spark.conf.set("fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com/<TENANT_ID>/oauth2/token")
df = spark.read.load("abfss://<CONTAINER>@<STORAGE_ACCOUNT>.dfs.core.windows.net/test.csv", format="csv")
df.show()
df.write.format("csv").mode("overwrite").save("abfss://<CONTAINER>@<STORAGE_ACCOUNT>.dfs.core.windows.net/output")
%%pyspark
import pandas as pd
df = pd.read_csv("abfss://CONTAINER@STORAGE_ACCOUNT.dfs.core.windows.net/test.csv", \
storage_options = {"tenant_id": "TENANT_ID", \
"client_id" : "CLIENT_ID", \
"client_secret": "CLIENT_SECRET"})
print(df)
df.to_csv("abfss://<CONTAINER>@<STORAGE_ACCOUNT>.dfs.core.windows.net/output/test.csv")
注意点
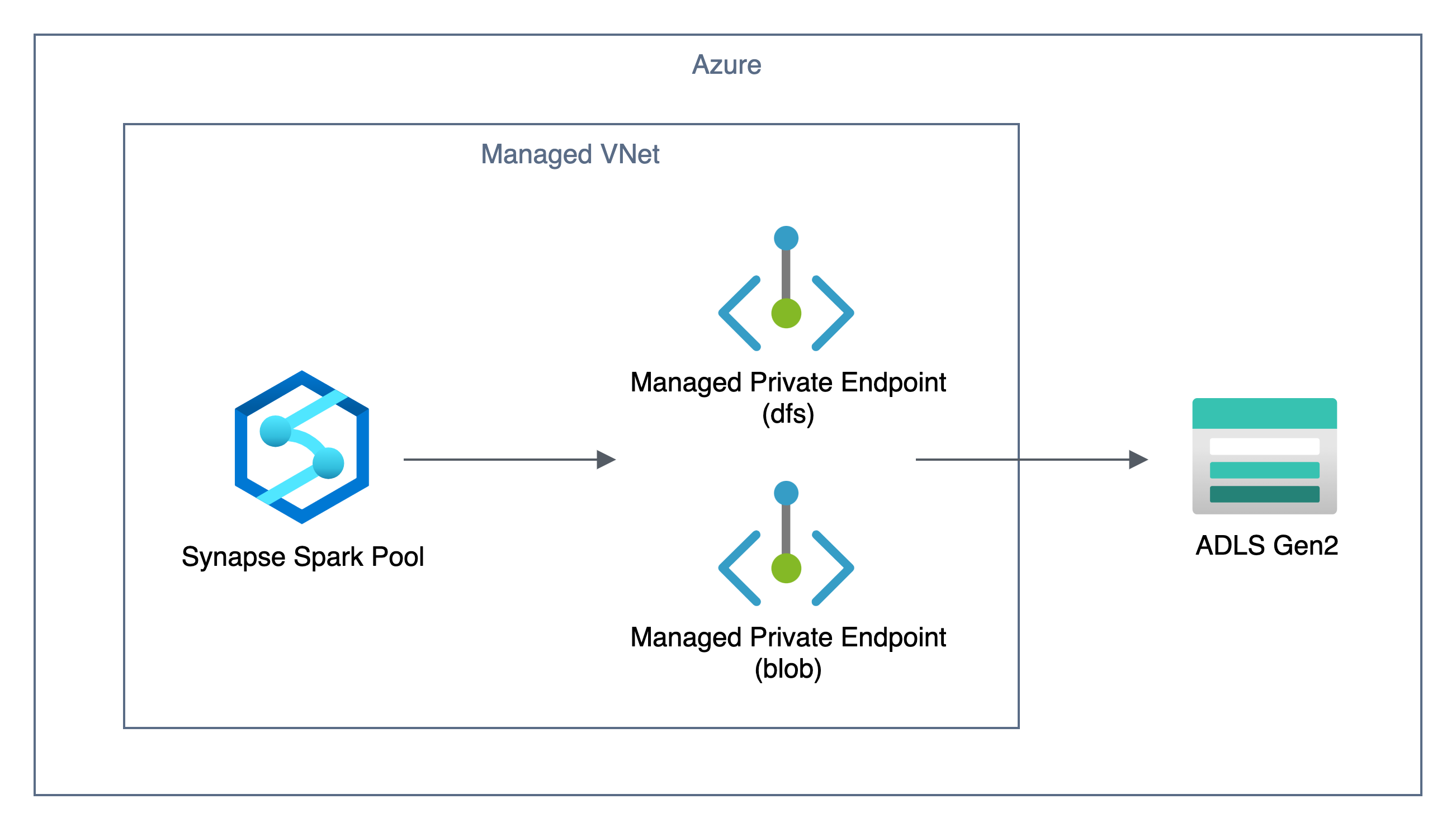
1. マネージド プライベート エンドポイントの種類
マネージド仮想ネットワークが有効化された Synapse ワークスペースにおいて、マネージド プライベート エンドポイントが作成された ADLS Gen2 に接続する際には dfs.core.windows.net だけでなく、blob.core.windows.net にも接続が発生することがあるようです。
マネージド プライベート エンドポイントは dfs だけでなく blob のマネージド プライベート エンドポイントも作成することを推奨します。
推奨する構成は下図のようになります。
公式ドキュメントに記載されている通り、基本的に Azure Storage のプライベート エンドポイントは dfs と blob 両方のサブリソースを作成することが推奨されています。

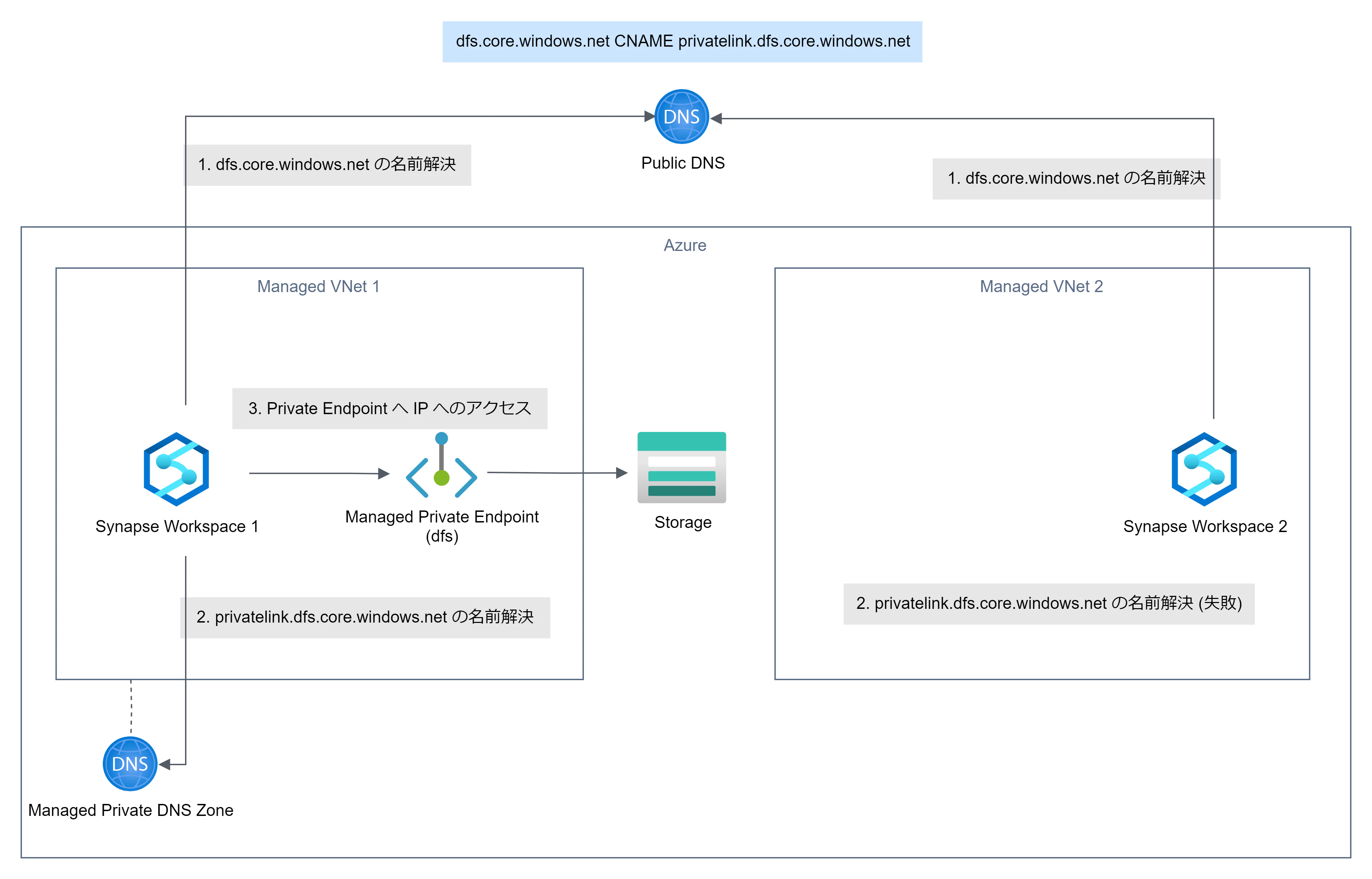
2. 名前解決
2 つのワークスペースから同一ストレージにアクセスする際、片方でプライベート エンドポイントを作成していると、Public DNS にプライベート エンドポイントへの CNAME レコードが登録され、もう片方で名前解決に失敗することがあります。
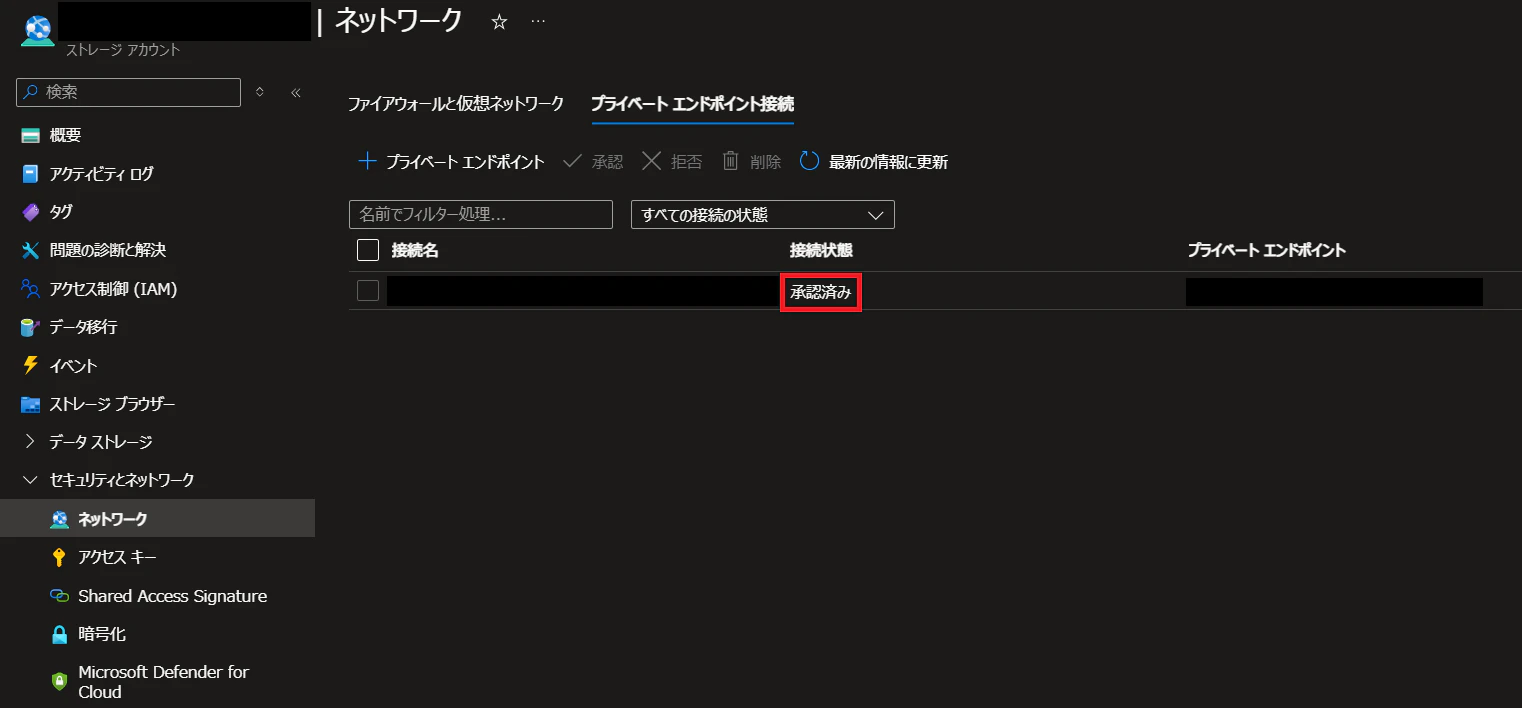
3. マネージド プライベート エンドポイントの存在
Synapse ワークスペースにて作成したマネージド プライベート エンドポイントは Azure Portal にて承認できます。Azure Portal 側で削除してしまった場合、接続することができなくなり、マネージ プライベート エンドポイントの再作成が必要となります。
おわりに
Azure Synapse Analytics の Spark Pool から ADLS Gen2 に接続する際の方式について説明しました。先述の通り、ノートブック実行とパイプライン実行は実行者が異なることを把握していないと問題切り分けに苦労するので注意しましょう。
参考