はじめに
Azure Synapse Dedicated SQL Pool Connector は Azure Synapse Analytics の Apache Spark Pool から Azure Synapse Dedicated SQL Pool (Azure Synapse 専用 SQL プール) のデータを操作するためのものです。
今回は Apache Spark Pool からこのコネクターを利用して Azure Synapse Dedicated SQL Pool に対する読み取り/書き込みを実施するための導入手順を説明します。
導入手順
1. Azure Synapse Dedicated SQL Pool の作成
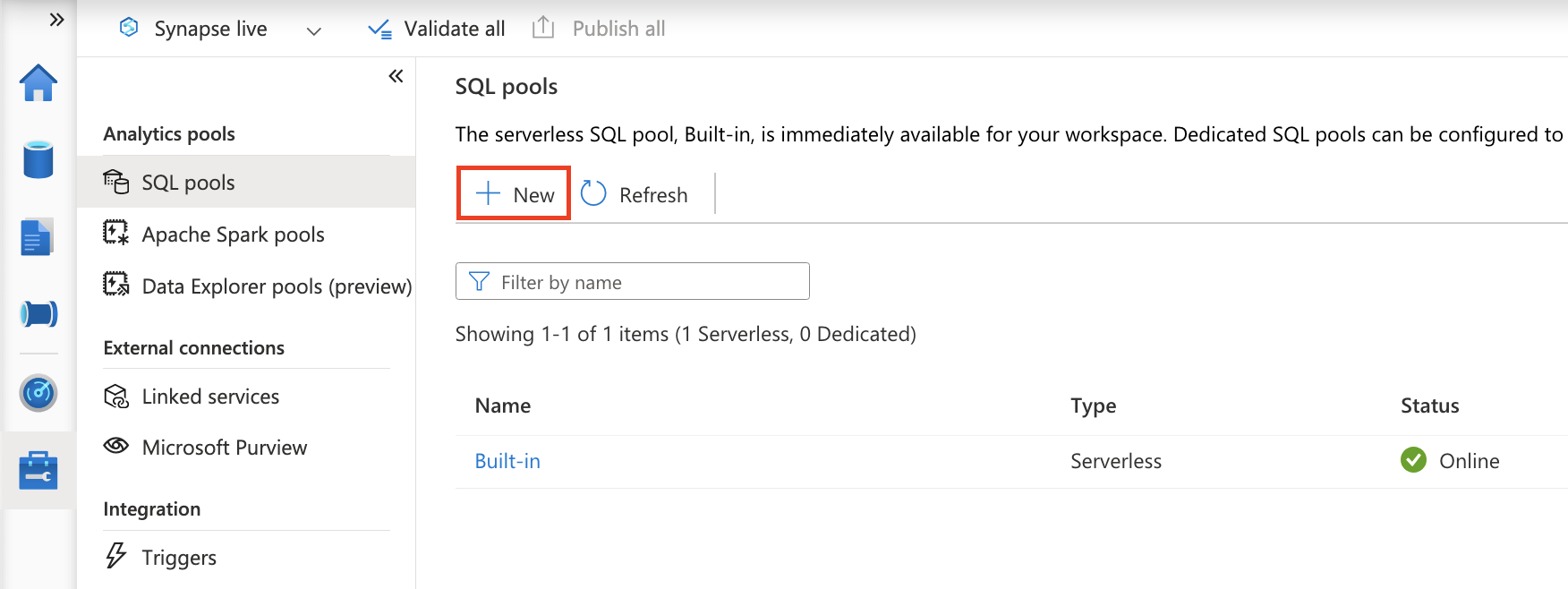
Azure Synapse Dedicated SQL Pool は Synapse Studio にて下図の赤枠ボタンより作成できます。
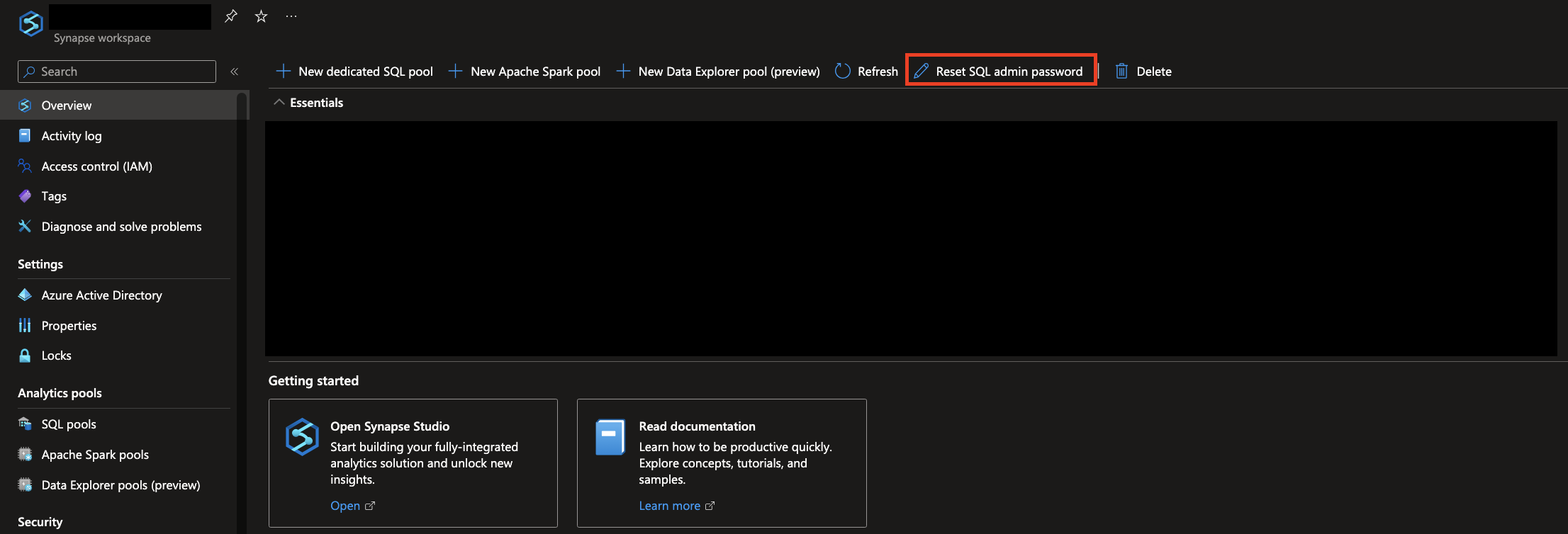
なお、SQL Admin ユーザーのパスワードは Azure Portal にて変更できます。
2. テーブルの作成
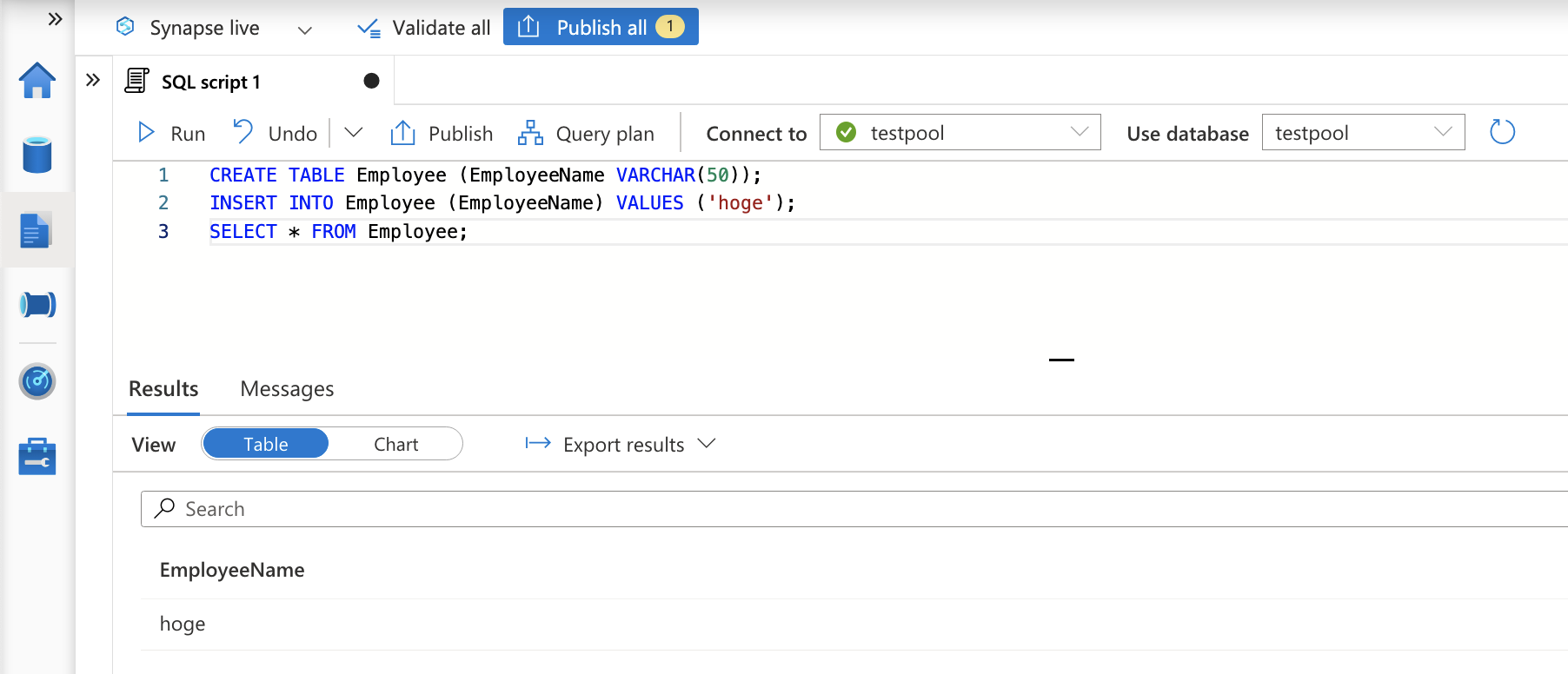
Synapse Studio の SQL スクリプトにて、以下のクエリを実行しテーブルを作成しデータを投入します。
CREATE TABLE Employee (EmployeeName VARCHAR(50));
INSERT INTO Employee (EmployeeName) VALUES ('hoge');
SELECT * FROM Employee;
3. データ ソースの作成
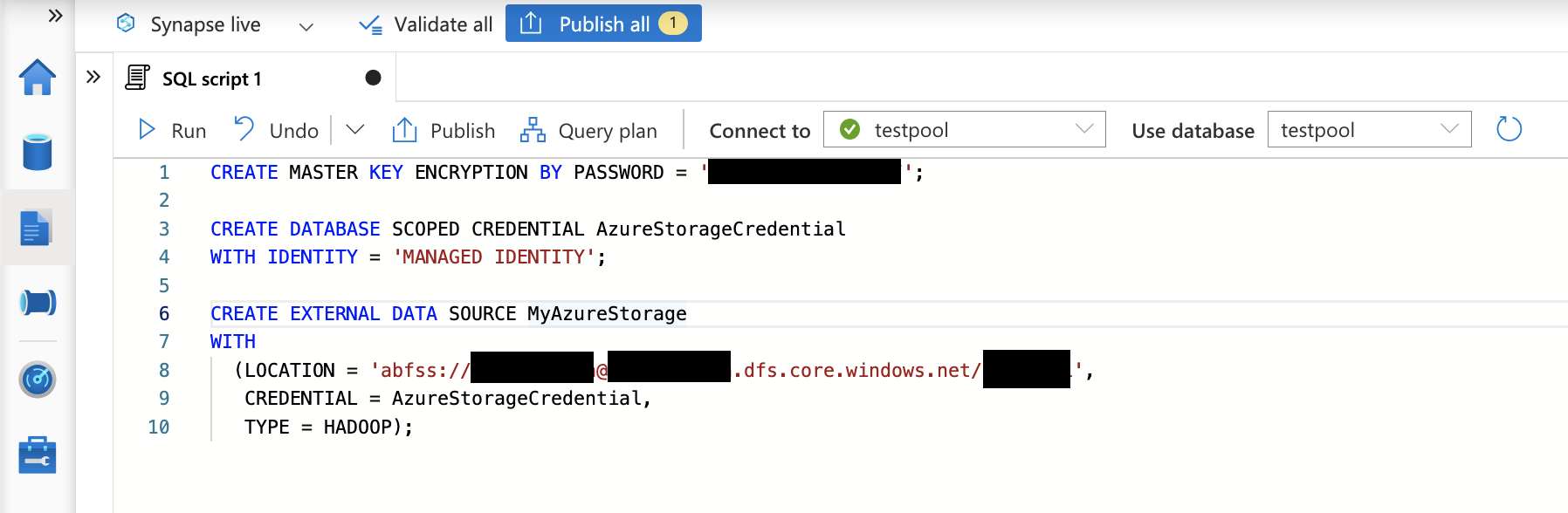
Synapse Studio の SQL スクリプトにて、以下のクエリを実行しデータ ソースを作成します。
データベースのマスターキーは手順 1 で説明した SQL Admin パスワードとは別物であり、ここでは任意の値を入力すればよいことになります。なお、該当のストレージ アカウントには IAM 設定で Synapse マネージド ID に対してストレージ BLOB 共同作成者権限を付与していることを前提とします。
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<任意の値>';
CREATE DATABASE SCOPED CREDENTIAL AzureStorageCredential
WITH IDENTITY = 'MANAGED IDENTITY';
CREATE EXTERNAL DATA SOURCE MyAzureStorage
WITH
(LOCATION = 'abfss://<コンテナ名>@<ストレージアカウント名>.dfs.core.windows.net/<フォルダパス>',
CREDENTIAL = AzureStorageCredential,
TYPE = HADOOP);
4. コードの実行
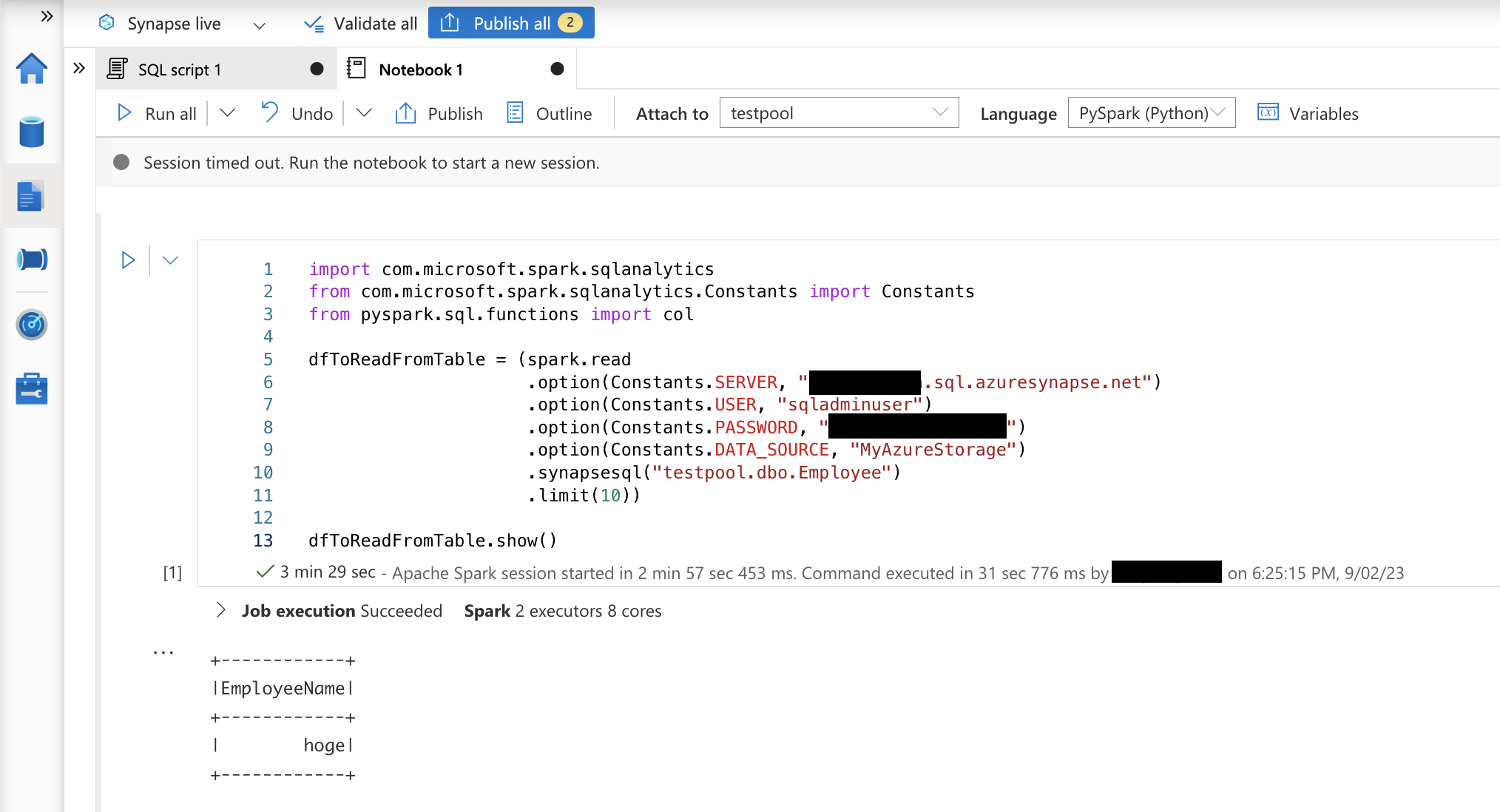
ノートブックで以下のコードを実行して、データの読み取りができることを確認します。
import com.microsoft.spark.sqlanalytics
from com.microsoft.spark.sqlanalytics.Constants import Constants
from pyspark.sql.functions import col
dfToReadFromTable = (spark.read
.option(Constants.SERVER, "<SQLサーバー名>.sql.azuresynapse.net")
.option(Constants.USER, "<ユーザー名>")
.option(Constants.PASSWORD, "<パスワード>")
.option(Constants.DATA_SOURCE, "MyAzureStorage")
.synapsesql("<SQLデータベース名>.dbo.Employee")
.limit(10))
dfToReadFromTable.show()
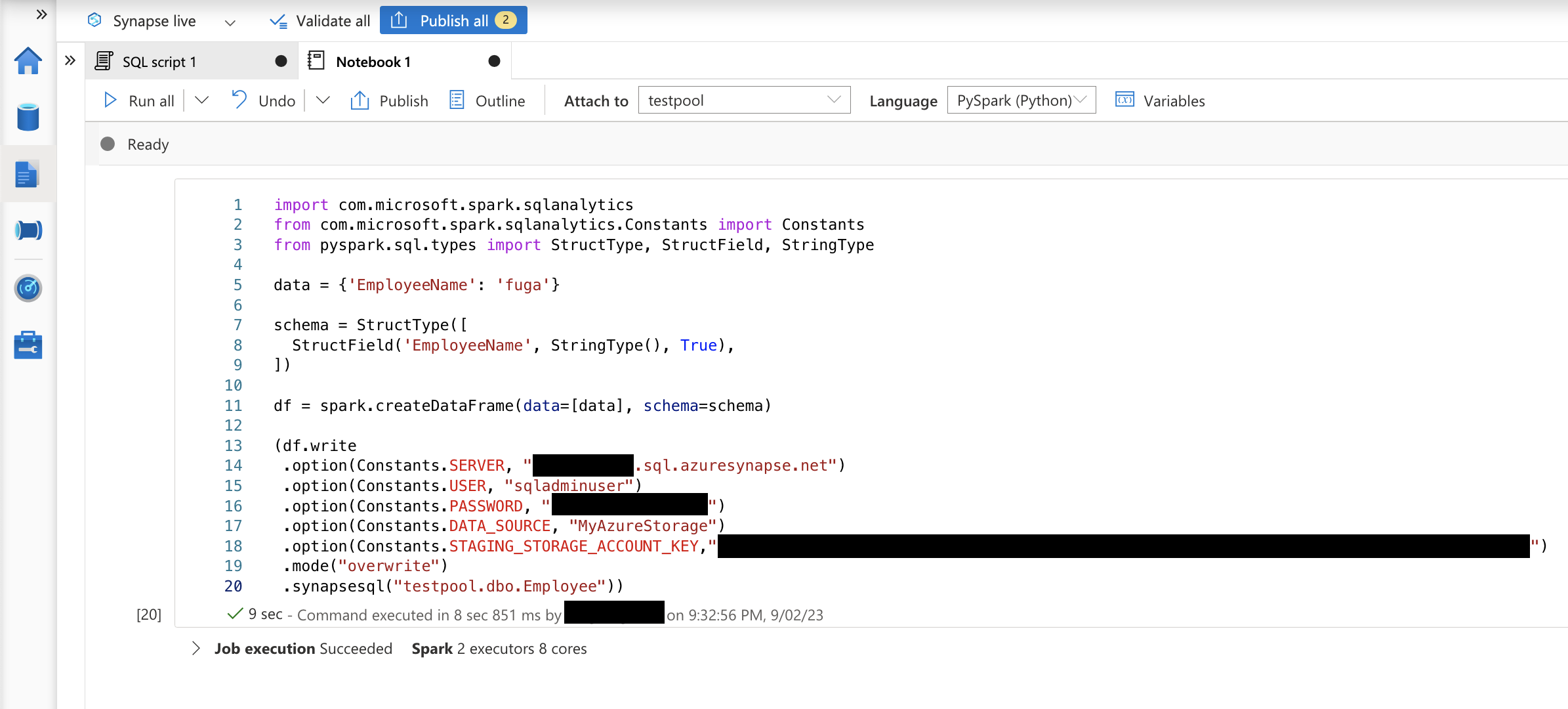
ノートブックで以下のコードを実行して、データの書き込みができることを確認します。
import com.microsoft.spark.sqlanalytics
from com.microsoft.spark.sqlanalytics.Constants import Constants
from pyspark.sql.types import StructType, StructField, StringType
data = {'EmployeeName': 'fuga'}
schema = StructType([
StructField('EmployeeName', StringType(), True),
])
df = spark.createDataFrame(data=[data], schema=schema)
(df.write
.option(Constants.SERVER, "<SQLサーバー名>.sql.azuresynapse.net")
.option(Constants.USER, "<ユーザー名>")
.option(Constants.PASSWORD, "<パスワード>")
.option(Constants.DATA_SOURCE, "MyAzureStorage")
.option(Constants.STAGING_STORAGE_ACCOUNT_KEY,"<ストレージアカウントキー>")
.mode("overwrite")
.synapsesql("<SQLデータベース名>.dbo.Employee"))
おわりに
Azure Synapse Analytics にて Azure Synapse Dedicated SQL Pool Connector を利用して Apache Spark Pool から Azure Synapse Dedicated SQL Pool に対して読み取り/書き込みが実行できることを確認しました。
今回は基本認証を利用していますが、Azure AD 認証を利用することも可能です。
参考