初めに
本記事では、昨今の大規模処理には欠かせない並列分散処理の基本について、Open MPIを題材にかるーい解説を行う。
なお今回は、処理の対象として、マンデルブロ集合を採用する。
複素数と複素平面について
マンデルブロ集合を理解するには複素数と複素平面の理解は外せない。よって、まずこれを説明する。
複素数とは以下(式1)で定義される2つの実数$(a,b)$と虚数単位$i$ ($i^2=-1$)の2つの成分から表せる数$c$である。(複素数は$z$と表すのが定石、今回は以降の利便上$c$と表す)
\displaylines{
c = a+ib \tag{式1}
}
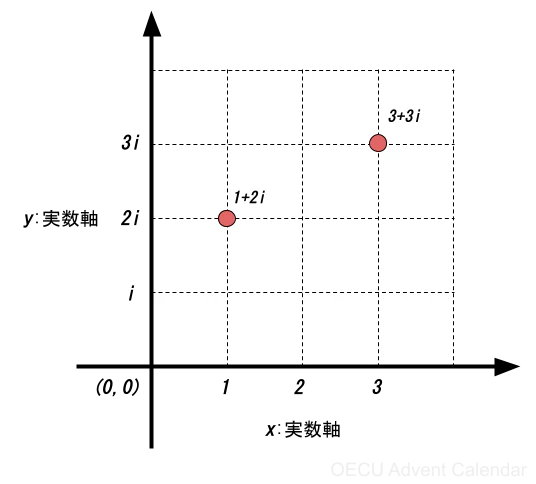
そして、この複素数は2次元の数として幾何学的に表せる。それが、直交座標$(x,y)$の各座標軸、$x$座標を実数軸 (real axis)、$y$座標を虚数軸 (imaginary axis) として、複素数$c$に対応付けたものが 複素平面である。定義を式2に示す。
\displaylines{
c = x+iy \tag{式2}
}
マンデルブロ集合とは
マンデルブロ集合とは、複素平面上の特定集合の事である。この集合は、式3の漸化式として定義される。
\left\{
\begin{array}{ll}
z_0 = 0 \\ \tag{式3}
z_{n+1} = z^2_n + c
\end{array}
\right.
数列${z_n}$に対して、複素平面上の任意の複素数$c$を導入し、式1の漸化式の演算を無限回繰り返した時に生成される集合がマンデルブロ集合である。この際、マンデルブロ集合の体を成すのが、複素数$c$に対して$|z_n|≦2$となる発散しない集合である。
収束する集合と発散する集合の具体例
ここでマンデルブロ集合に話を戻して、実際に収束する場合と発散する場合の具体例を複素数$c$の値を仮代入して${z_n}$を計算してみる。
- 収束する演算例を示す
- $c=0$
\displaylines{
z_0=0,z_1=0^2+0,z_2=0^2+0,z_2=0^2+0,.....
}
$c=0$を導入した場合、$|z_m|=0,m(1≦m≦n) $ となり収束する。この場合はマンデルブロ集合に属する。
- 発散する演算例を示す
- $c=1$
\displaylines{
z_0=0,z_1=0^2+1,z_2=1^2+1,z_2=2^2+1,.....
}
この場合、${z_n}$は再帰的に計算されるにつれ、無限大に値が増加し、発散する。
マンデルブロ集合の可視化
発散する集合と収束する場合を場合分けして視覚化すると以下のようなフラクタル図形が得られる事で有名である。
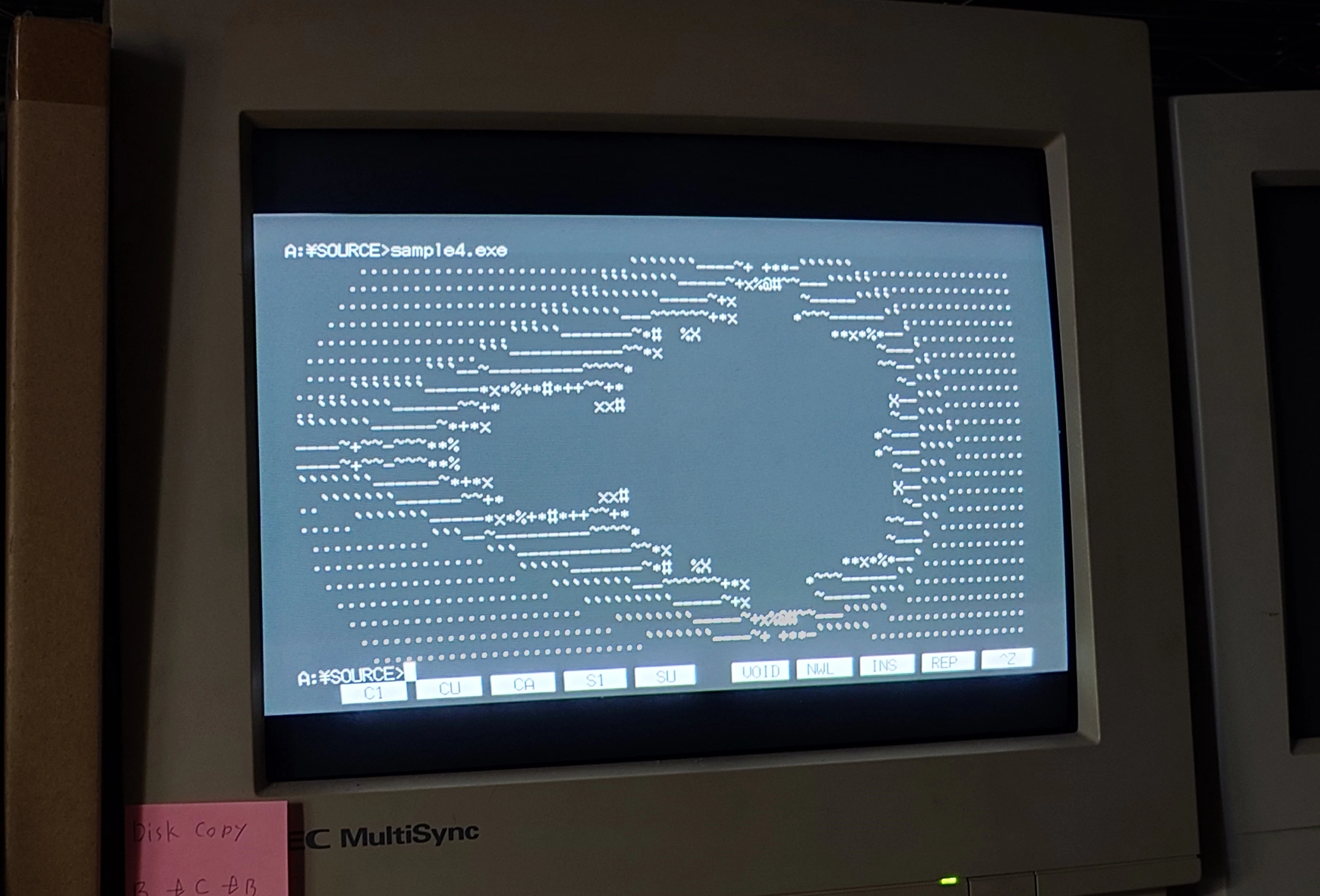
マンデルブロ集合を計算し、それをASCIIアートとして生成させるサンプルプログラムを以下に示す。
#include <stdio.h>
int main(void)
{
/* 表示領域サイズ(適宜変更可能) */
int width = 80;
int height = 25;
/* 複素平面上の表示範囲(適宜変更可能) */
double xmin = -2.0;
double xmax = 1.0;
double ymin = -1.0;
double ymax = 1.0;
/* 最大反復回数 */
int max_iter = 100;
const char *chars = " .`-~+*xX%#@";
int grad_len = 12;
{
int iy;
for (iy = 0; iy < height; iy++) {
double cy = ymin + (ymax - ymin) * (double)iy / (double)(height - 1);
{
int ix;
for (ix = 0; ix < width; ix++) {
double cx = xmin + (xmax - xmin) * (double)ix / (double)(width - 1);
double x = 0.0;
double y = 0.0;
int iteration = 0;
/* マンデルブロ判定用繰り返し */
while ((x*x + y*y <= 4.0) && (iteration < max_iter)) {
double x_new = x*x - y*y + cx;
double y_new = 2.0 * x * y + cy;
x = x_new;
y = y_new;
iteration++;
}
{
char c;
if (iteration == max_iter) {
/* 発散せず → 集合内 */
c = chars[0];
} else {
int index = (iteration * grad_len) / max_iter;
if (index >= grad_len) {
index = grad_len - 1;
}
c = chars[index];
}
putchar(c);
}
}
}
putchar('\n');
}
}
return 0;
}
MPIとは
MPI(Message Passing Interface)はMPI Forumによって標準化されている規格である。
並列分散処理には、大きく分けて共有メモリ型と分散メモリ型の2種類の処理形態が存在する。共有メモリ型と言うのは、シングルノード上のメモリ空間に展開されたデータを共有して利用する方式である。分散メモリ型はマルチノードにネットワーク等を介してメモリ空間を共有する方式である。
MPIはこれら2種類の処理形態に対応する。MPI標準化について、詳しくは以下を参照されたい。
少し古いが、日本語に翻訳されたドキュメントも存在する。
Open MPIとは
Open MPI (Message Processing Interface)はMPIを実装したパラダイムの事である。他にもMPIを実装したパラダイムとしてMPICHが存在するが、今回はOpen MPIを使用する。
Open MPIによる並列処理
今回はマルチノードによる並列分散処理を行いたい為、分散メモリ型の処理形態を採用する。MPIによる分散処理は、マスタースレーブ型による処理形態となる。これは命令係となるマスターノードと処理係からなる1対多の関係を持つノード群で構成されており、それらの間で互いに通信しながら並列分散処理が実現される。
マスターノードの役割
処理するデータの切り分けを行い、データの処理をどのノードに割り当てるかを決定する。最終的にマスターノードによって処理されたデータを統合する。つまり上記で述べたように命令係であり、全てのスレーブノードはこれによって制御される。
スレーブノードの役割
マスターノードから割り当てられたデータを受け取り処理を行う。最後に処理されたデータをマスターノードに返す。
Open MPIのセットアップ
マンデルブロ集合の並列分散処理
ここまで、必要な要素を説明したところで、今回の主眼となるマンデルブロ集合をOpen MPIによってどの様に並列分散処理するかを考える。
上で述べたように、マンデルブロ集合の計算は複素平面上にある点を処理する形となる。そこで、複素平面上の領域を細かく切り分けて、それぞれの領域を並列で分散処理させる方針にする。
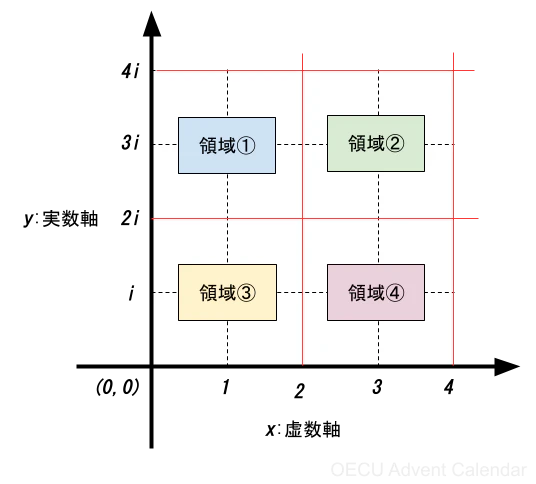
例えば、この平面を任意の$m×n$ずつ分割する場合は、タイルを敷き詰めて行く様なイメージで、$m,n ∈ bb(Z)$を用いて、式4の様に$R_{m,n}$の集合に切り分けていく。
R_{m,n} = \{Z=x+iy \mid xm≦x<(m+1),yn≦y<(n+1)\} \tag{式4}
つまり、以下の画像の様に領域を区切って、その領域の$z_n$をスレーブノードに並列に分配して処理するという方式をとる。
この方法を採用したフローは以下の様になる。
- マスターノードは任意の$m,n$に基づき領域$R_{m,n}$を作成して処理をスレーブノードに割り振る
- スレーブノードは割り振られた領域内の点$z_n$を演算し、マスターノードに転送
- マスターノードは全ての領域が転送されるまで待機し、最後に結果を全て統合する
- 統合した結果を画像化
Open MPIによる並列分散処理の実装
実際に先程の設計に基づいてC言語で実装したサンプルコードが以下のコードブロックである。
ここでは、計算したマンデルブロ集合をP3(PPM形式)で視覚化する。
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <mpi.h>
/*描画サイズ*/
#define WIDTH 1000
#define HEIGHT 1000
/*処理対象の複素平面*/
#define XMIN -2.0
#define XMAX 1.0
#define YMIN -1.5
#define YMAX 1.5
/*分割する領域サイズ*/
#define M 2 // x方向に M 分割
#define N 2 // y方向に N 分割
/*再帰処理回数*/
#define ROOP_ITER 100
/*rank の定義*/
#define MASTER 0
/*タグ*/
#define WORKTAG 1 // 領域IDを送る際のタグ
#define DIETAG 2 // 演算終了を送る際のタグ
#define IMGTAG 3 // 画像データ送受信用のタグ
#define IDTAG 4 // tile_id 送受信用のタグ
/*結果からppmを生成*/
void write_ppm(const char *filename, int width, int height, int max_iter, int **data)
{
FILE *fp = fopen(filename, "wb");
if(!fp){
fprintf(stderr, "Failed to open file: %s\n", filename);
return;
}
fprintf(fp, "P3\n");
fprintf(fp, "%d %d\n", width, height);
fprintf(fp, "%d\n", 255);
for(int j = 0; j < height; j++){
for(int i = 0; i < width; i++){
int iter = data[j][i];
int color = (iter >= ROOP_ITER) ? 0 : (int)(255.0 * iter / (ROOP_ITER - 1));
fprintf(fp, "%d %d %d ", color, color, color);
}
fprintf(fp, "\n");
}
fclose(fp);
}
/*マンデルブロ集合を演算*/
int mandelbrot(double start_x, double end_x,
double start_y, double end_y,
int tile_width, int tile_height,
int *iteration_array)
{
int sum_iter = 0;
double dx = (end_x - start_x) / tile_width;
double dy = (end_y - start_y) / tile_height;
for(int iy = 0; iy < tile_height; iy++){
for(int ix = 0; ix < tile_width; ix++){
double x0 = start_x + ix * dx;
double y0 = start_y + iy * dy;
double x = 0.0, y = 0.0;
int iter = 0;
while((x*x + y*y < 4.0) && (iter < ROOP_ITER)){
double xtmp = x*x - y*y + x0;
y = 2*x*y + y0;
x = xtmp;
iter++;
}
iteration_array[iy * tile_width + ix] = iter;
sum_iter += iter;
}
}
return sum_iter;
}
/*スレーブノードの処理*/
void slave_code()
{
MPI_Status status;
int tile_id;
// 領域あたりのピクセル幅・高さ
int tile_width = WIDTH / M;
int tile_height = HEIGHT / N;
// 領域内ピクセル格納用
int *iteration_array = (int*)malloc(sizeof(int) * tile_width * tile_height);
while(1)
{
// 領域IDを受信
MPI_Recv(&tile_id, 1, MPI_INT, MASTER, MPI_ANY_TAG, MPI_COMM_WORLD, &status);
// 終了タグを受信した場合はループを抜ける
if(status.MPI_TAG == DIETAG) {
break;
}
// 領域ID → 領域座標へ変換
int iy = tile_id / M; // 領域の「縦」方向インデックス
int ix = tile_id % M; // 領域の「横」方向インデックス
// 領域の複素平面上の範囲を算出
double x_split_area = (XMAX - XMIN) / M;
double y_split_area = (YMAX - YMIN) / N;
double start_x = XMIN + ix * x_split_area;
double end_x = start_x + x_split_area;
double start_y = YMIN + iy * y_split_area;
double end_y = start_y + y_split_area;
// 領域を計算
int sum_iter = mandelbrot(start_x, end_x,
start_y, end_y,
tile_width, tile_height,
iteration_array);
// (1) tile_id を送信 (タグ: IDTAG)
MPI_Send(&tile_id, 1, MPI_INT, MASTER, IDTAG, MPI_COMM_WORLD);
// (2) 領域のピクセル反復回数を送信 (タグ: IMGTAG)
MPI_Send(iteration_array, tile_width*tile_height, MPI_INT,
MASTER, IMGTAG, MPI_COMM_WORLD);
// (3) 合計反復回数 sum_iter を送信 (タグ: WORKTAG で流用)
MPI_Send(&sum_iter, 1, MPI_INT, MASTER, WORKTAG, MPI_COMM_WORLD);
}
free(iteration_array);
}
/*マスターノードの処理*/
void master_code(int num_procs)
{
int num_tiles = M * N;
int total_sum_iter_global = 0;
// 領域あたりのピクセル幅・高さ
int tile_width = WIDTH / M;
int tile_height = HEIGHT / N;
// 大域画像データ (2次元配列動的確保)
int **image_data = (int**)malloc(sizeof(int*) * HEIGHT);
for(int i = 0; i < HEIGHT; i++){
image_data[i] = (int*)malloc(sizeof(int) * WIDTH);
}
// スレーブにタスク(領域ID)を割り当て
int ntasks_sent = 0; // 送信済み領域数
// まずは num_procs-1 個のスレーブに順次タスクを渡す
for(int rank = 1; rank < num_procs; rank++)
{
if(ntasks_sent < num_tiles)
{
MPI_Send(&ntasks_sent, 1, MPI_INT, rank, WORKTAG, MPI_COMM_WORLD);
ntasks_sent++;
}
}
// 各領域の結果を受け取ったら次の領域を送る
MPI_Status status;
for(int i = 0; i < num_tiles; i++)
{
// (1) tile_idを先に受信 (IDTAG)
MPI_Probe(MPI_ANY_SOURCE, IDTAG, MPI_COMM_WORLD, &status);
int source = status.MPI_SOURCE;
int tile_id;
MPI_Recv(&tile_id, 1, MPI_INT, source, IDTAG, MPI_COMM_WORLD, &status);
// (2) ピクセルデータを受信 (IMGTAG)
MPI_Probe(source, IMGTAG, MPI_COMM_WORLD, &status);
int count;
MPI_Get_count(&status, MPI_INT, &count);
if(count != tile_width * tile_height){
fprintf(stderr, "Error in receiving tile pixel data.\n");
MPI_Abort(MPI_COMM_WORLD, 1);
}
int *tile_buffer = (int*)malloc(sizeof(int) * count);
MPI_Recv(tile_buffer, count, MPI_INT, source, IMGTAG, MPI_COMM_WORLD, &status);
// (3) 合計反復回数 sum_iter_local を受信 (WORKTAG)
int sum_iter_local;
MPI_Recv(&sum_iter_local, 1, MPI_INT, source, WORKTAG, MPI_COMM_WORLD, &status);
// グローバルの合計に加算
total_sum_iter_global += sum_iter_local;
// 受け取った tile_id を元に領域が画像全体のどこに対応するかを決定
int iy = tile_id / M;
int ix = tile_id % M;
int y_start = iy * tile_height;
int x_start = ix * tile_width;
// 画像全体へ書き込む
for(int ty = 0; ty < tile_height; ty++){
for(int tx = 0; tx < tile_width; tx++){
image_data[y_start + ty][x_start + tx]
= tile_buffer[ty * tile_width + tx];
}
}
free(tile_buffer);
// 次の領域がまだあれば送る
if(ntasks_sent < num_tiles)
{
MPI_Send(&ntasks_sent, 1, MPI_INT, source, WORKTAG, MPI_COMM_WORLD);
ntasks_sent++;
}
}
// 全領域が終わったら、残りのスレーブに終了通知を送る
for(int rank = 1; rank < num_procs; rank++)
{
int end_signal = -1;
MPI_Send(&end_signal, 1, MPI_INT, rank, DIETAG, MPI_COMM_WORLD);
}
// 画像をファイルへ出力
write_ppm("mandelbrot.ppm", WIDTH, HEIGHT, ROOP_ITER, image_data);
// 動的に確保した二次元配列の解放
for(int i = 0; i < HEIGHT; i++){
free(image_data[i]);
}
free(image_data);
}
/*メイン関数*/
int main(int argc, char *argv[])
{
int rank, size;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
if(rank == MASTER)
{
master_code(size);
}
else
{
slave_code();
}
MPI_Finalize();
return 0;
}
これをmpiccによるコンパイルを行う。
以下のコマンドを実行して、コンパイルする。その後格ノードに配置する。
mpicc -o Multi-node Multi-node.c
コンパイルしたファイルをMPIで並列実行する場合はmpirunコマンドを使用する。
mpirun --hostfile hosts.txt -np 4 ./Multi-node
本コマンドにより、hosts.txtに記述されたノードによって並列分散処理が行われる。
全ての領域の割り当て・計算が終了するとmandelbrot.ppmが生成される。
ppmをファイルをpngに変換する場合は、以下のコマンドを実行する。
convert mandelbrot.ppm mandelbrot.png
これによりmandelbrot.pngが処理され、マンデルブロ集合を可視化することが出来る。
サンプルとして、本プログラムで処理されたpngは以下である。
