はじめに
仕事でデータレイクを構築する際に AWS Data Pipeline を初めて使用しましたが、インターネット上にあまり情報が見つからずかなり手探りで進めることになりました。
(触り始めはほんとうにどこをどう触ってよいかわからなかった…)
わずかばかりの知見ですが、これから取り組む方の役に少しでも立てばと思い、いくつかのTipsを記事にしてみました。
AWS Data Pipelineはどんなサービス?
公式ドキュメントにある下図1がイメージをつかみやすいです。
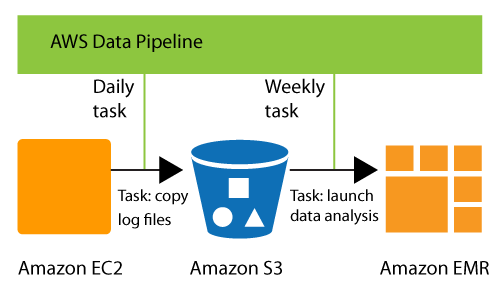
RDS、DynamoDB、S3等AWSの各種サービス上にあるデータのクレンジングや移動を定期タスクで処理させることができます。単にEC2を立ててシェルを実行させるだけのタスクを組むこともできるので、タスクスケジューラ的な使い方もできる様子。
タスクはAWSコンソールからブロック(AWSから提供される機能の箱)を繋いで組み立てるか、AWS CLIからJSON形式の定義ファイルをアップロードして作成します。公式にチュートリアルやテンプレートはいくつかあるので、やりたいことに合致しそうであればそのまま流用できると思います。
実際に触ってみるとわかりますが、ブロックの編集の仕方には少し癖があります…。
ブロックを追加する際は下図左上の「Add」からブロックの種類を選択するのですが、フォーカス中のブロックの下に追加されるわけではなくルートにぶら下がるような形になります。
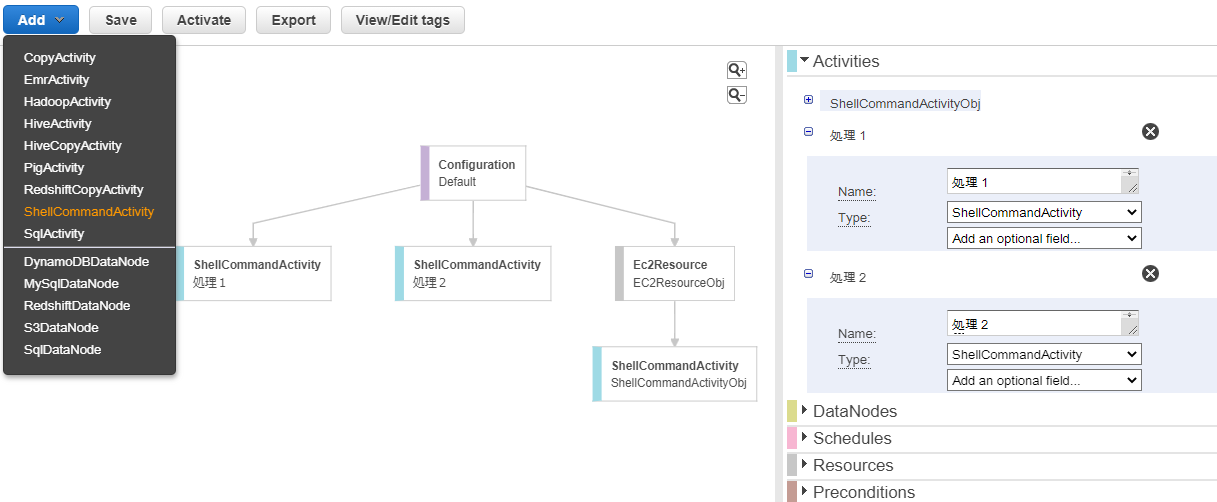
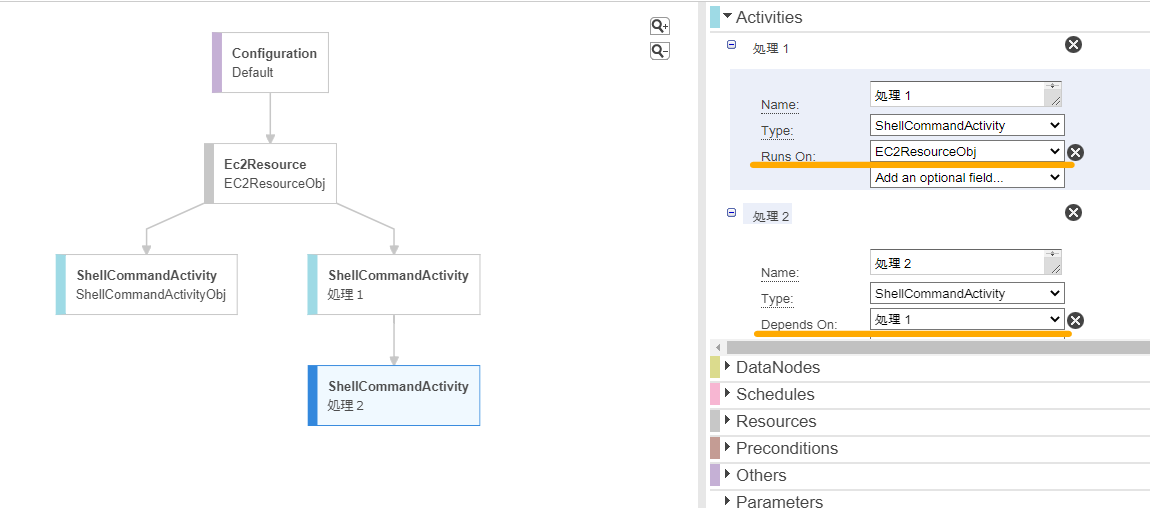
そこで、下図のように右側メニュー内の「Runs On」や「Depends On」で各ブロックごとに親を設定する必要があります。
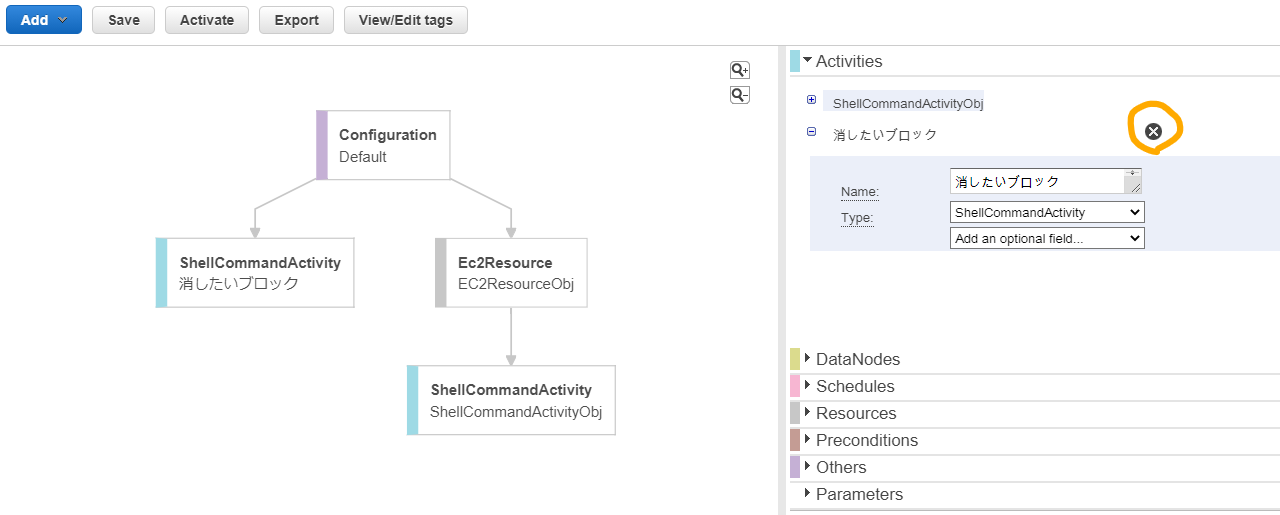
ブロックを削除したい場合は右側メニュー内から消したいブロックを探して名前横の×印を押す必要があります。
ちなみに右側メニューの「Activities」の横にある▼ですが、クリックしても閉じません。他の閉じている項目の▶をクリックすることで今開いている項目が閉じて新たにクリックした項目が開きます😅
このあたりの操作があまり直感的ではなくて、最初とても戸惑いました。が、設定できるパラメータを眺めることで大体すべきことが見えてくるのでそこは理解しやすくてよいなーと思いました。
Tips
スケジュール実行/オンデマンド実行
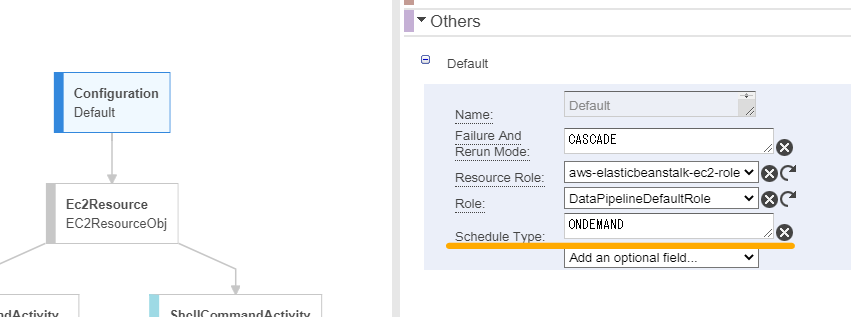
Pipelineのタスクはスケジュールで動かしたいけれど、開発中は任意のタイミングで処理を動かしたい!という場合はルートにあるConfigurationブロックの「Schedule Type」を ONDEMAND にすることでアクティベーションごとに都度実行させることができるようになります。
シェル異常終了時のリトライ回数指定
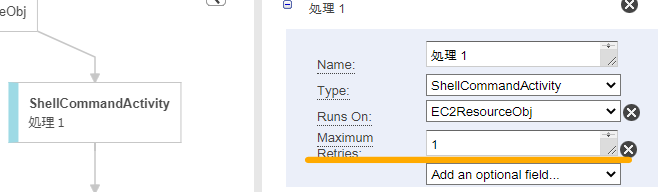
デフォルト設定では、シェルの異常終了が3回繰り返された後にタスクがFAILEDで終了するようになっています。シェルブロックの「Maximum Retries」を1にしておくと、1回の異常終了ですぐにタスクを終了させることができるため異常ケースのテスト時など設定しておくと便利です。
設定のエクスポートとインポート
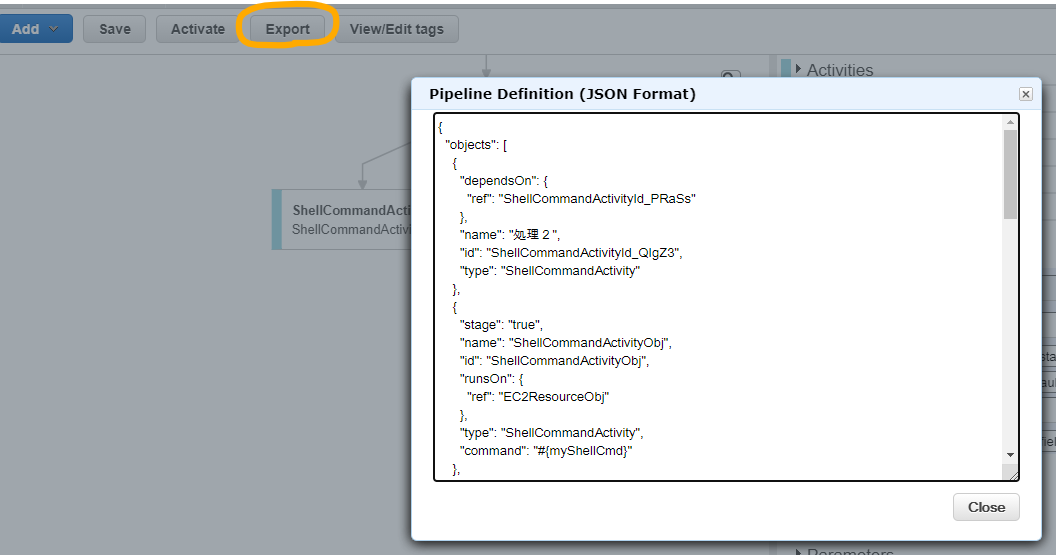
別の環境に構築済みのPipelineをコピーしたい場合は、コンソールの「Export」ボタンを押下してJSON定義を表示し、コピーしてJSONファイルとして保存することでエクスポートができます。
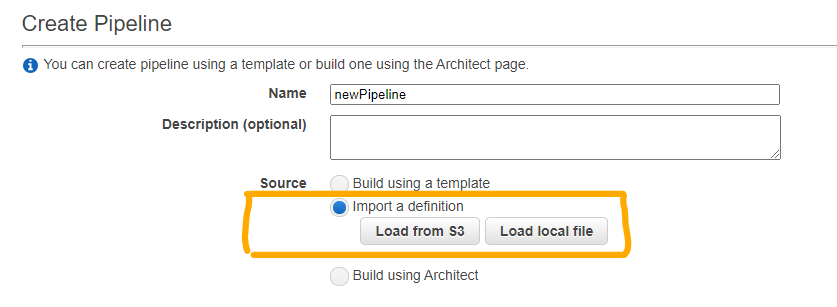
エクスポートしたJSON定義は、新たなPipeline構築時にインポートすることができます。
※ブロック名が日本語だと文字化けしたので、基本英数使用がよさそうです
実行権限
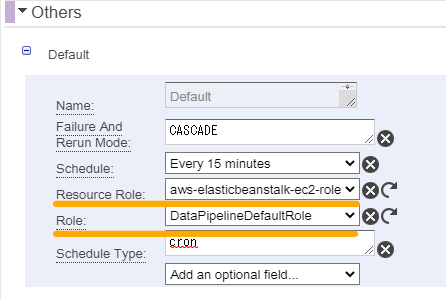
Configurationブロックのパラメータには「Resource Role」と「Role」があります。
それぞれ
Resource Role:DataPipelineから作成されたEC2に付与されるIAMロール
Role:DataPipelineがEC2を作成する際に使用するIAMロール
となっているので、データ処理の際にEC2からアクセスするリソース(S3のシェルなど)の権限はResource Roleの方に付与する必要があります。
パラメータの説明確認
「Add an optional field...」のセレクトボックス項目からこのパラメータ何を設定すればいいんだろう?と思った時は、一度追加してパラメータ名をクリックすると説明とドキュメントへのリンクを表示することができるのでスムーズに調べられます。
おわりに
DXでデータの需要が高まってゆく昨今、インフラとして採用率の高いAWSの各種データリソースを手軽に扱えるため、使えるようになっておいて損はないように感じました。(癖は強めですが)
記事では細かい内容は紹介していませんが、EMRのクラスタを作成してそれなりに重い処理ができたり、Pipelineで実行するシェルの上でAWS CLIを動かせばPipelineのブロックでできないことにも対応できたりと、かなり応用が利きそうです。
参考