Webサイトをリリースしました

今年はコロナの影響で卒業式が中止になったりしましたね。
それと比べるとあまり知られてないかもしれませんが、
美大・アート系の学校の卒業展示、
いわゆる 卒展 も数多くが中止を余儀なくされました。
部活でいうと引退試合が中止になったようなものです。
悲しいですね。
そこで、卒展で展示する予定だった作品をTwitteにアップするムーブメントが起きました。
#桑沢2020 #かってに卒制展 などのハッシュタグで様々な作品が見れます。
卒業制作
— 蓮(Hasu) (@hasu_ird) February 28, 2020
くつ下の柄によって靴の表情が変わる靴を制作。
透明や半透明の素材を使っている靴が増えていているけど『くつ下を見せるため』の靴はないよなぁってとこから発想しました。
LINE(くつ下の色彩を見せる)FRAME(くつ下の柄を見せる)の2種類デザインしました。#桑沢2020 pic.twitter.com/nq0apG4uzs
#桑沢2020
— 藤原光平 (@fuji_kohei) February 27, 2020
私は紙で椅子をつくりました。
桑沢の卒展は、自分にとってすごくすごく特別な想いがありました。
小学生から憧れ続けた桑沢卒展、中止。 pic.twitter.com/2Q1oZ0RvAm
これらの作品をアーカイブしたのが今回のWebサイトになります。
使用技術
- React
- GatsbyJS
- GraphQL
- Twitter API
- S3
- CloudFront
- Lambda@Edge
特に要となっているのは GatsbyJS です。
GatsbyJS とは
詳細は色々と記事が見つかるのでそちらに任せますが、
(例:Reactの最強フレームワークGatsby.jsの良さを伝えたい!!)
GatsbyJSとは、静的サイトジェネレータであり、
Reactアプリケーションを動かすフレームワークです。
npmでインストールして、create-react-app的なノリで使用できます。
ビルドしてHTMLを生成する部分はGo製の Hugo みたいのをイメージしてもらえればいいんですが、Gatsby はただの静的ジェネレータにはとどまりません。
完全なReactアプリとして動作するので、
外部のデータソースと接続すれば、動的なアプリとして振る舞います。
この辺りの仕組みを理解するには以下の記事が最高にわかりやすいです。
Reactベース静的サイトジェネレータGatsbyの真の力をお見せします
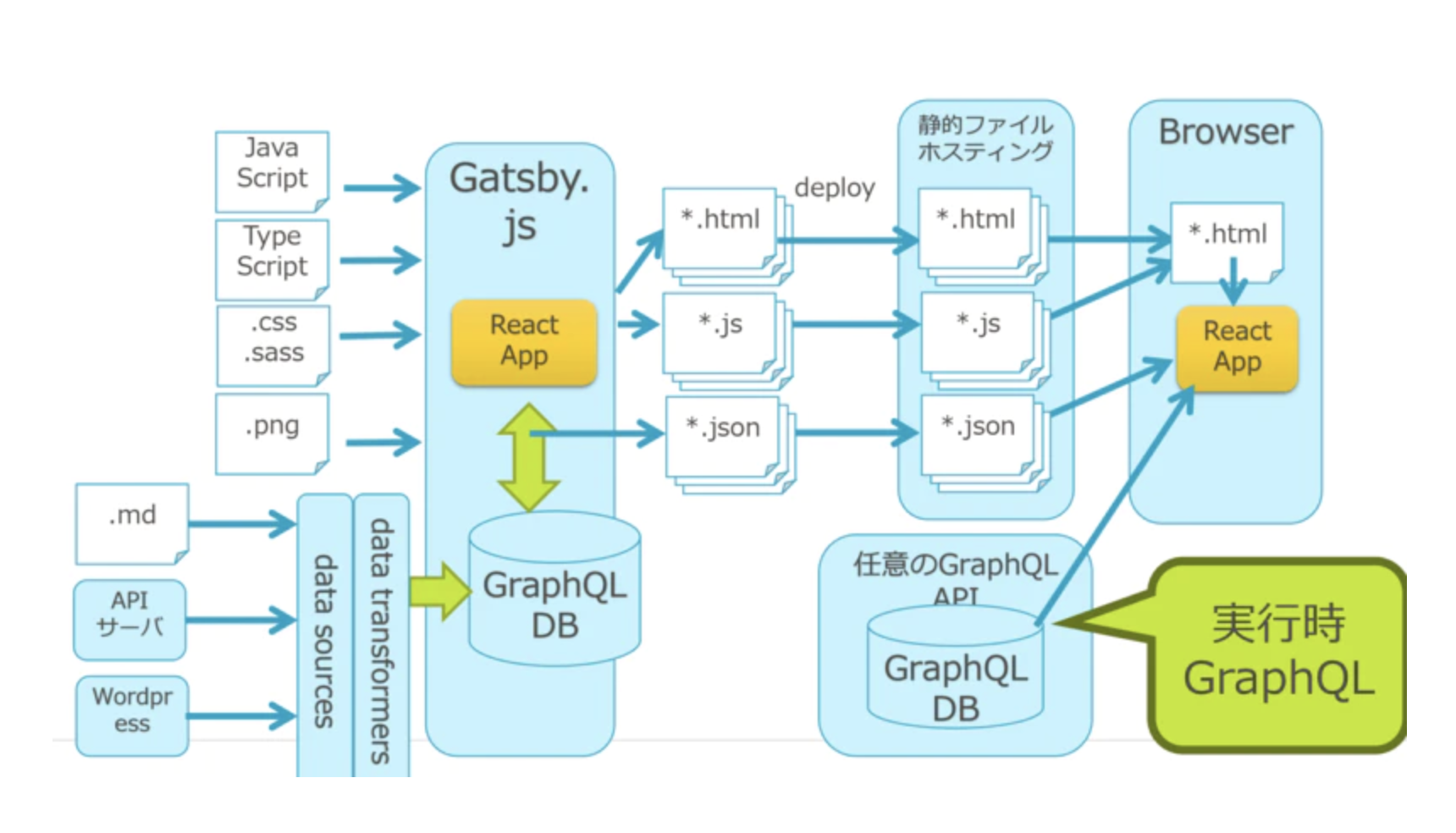
GatsbyはGraphQLを介してデータにアクセスするのですが、
ビルド時には、ローカルのGraphQLからデータを抽出して静的ファイルを出力します。
それに加えて、ブラウザでの実行時に外部のデータソースと接続してアプリにマージすることもできるのです。
例えばブログアプリを作るときに、記事はマークダウンとしてソースに含めてビルドし、
スター数やコメントはDynamoDBに保存してAppSync経由でリアルタイムに取得・表示する、
といった設計とかが可能。
データソースをどうするかで迷う
ブログやコーポレーションサイト、ポートフォリオなどの事例が多く、
それらではファイルシステムがデータソースとなっていました。
任意のディレクトリにマークダウンとしてデータを記述しておく形です。
今回使うデータは、元ツイートと、ツイートに含まれる画像の2つです。
Twitter APIの制限もあるし、コンテンツもちゃんとフィルタリングしたかったので、
静的に固めることは早々に決めたのですが、マークダウンはちょっと抵抗があります。
最初はローカルでMySQLを立てて実装しました。
データベースの接続もプラグインによって幅広くサポートされています。

ただSQLは情報が少なく、ジョインが絡む複雑なクエリを書くのが難しかったり、
サロゲートキーがGraphQLが生成するNodeのIDとバッティングしたり、
なんやかんやで面倒だったので途中からJSONに変更しました。
静的なのにソースとデータが分離されてるのもなんか気持ち悪いし。。。
ファイルシステムのプラグインを使えばJSONもこんな感じで簡単にクエリできます。
[
{
"tweet_id": "1232842391867912192",
"created_at": "2020-02-27T01:38:25.000Z",
"text": "#桑沢2020 \n\n私は紙で椅子をつくりました。\n\n桑沢の卒展は、自分にとってすごくすごく特別な想いがありました。\n\n小学生から憧れ続けた桑沢卒展、中止。 https://t.co/2Q1oZ0RvAm",
"hashtags": "桑沢2020",
"user_id": "1093916680504336384",
"user_screen_name": "fuji_kohei",
"embed_html": "<blockquote class=\"twitter-tweet\"><p lang=\"ja\" dir=\"ltr\"><a href=\"https://twitter.com/hashtag/%E6%A1%91%E6%B2%A22020?src=hash&ref_src=twsrc%5Etfw\">#桑沢2020</a> <br><br>私は紙で椅子をつくりました。<br><br>桑沢の卒展は、自分にとってすごくすごく特別な想いがありました。<br><br>小学生から憧れ続けた桑沢卒展、中止。 <a href=\"https://t.co/2Q1oZ0RvAm\">pic.twitter.com/2Q1oZ0RvAm</a></p>— kohei_fuji (@fuji_kohei) <a href=\"https://twitter.com/fuji_kohei/status/1232842391867912192?ref_src=twsrc%5Etfw\">February 27, 2020</a></blockquote>\n",
"images": [
"https://pbs.twimg.com/media/ERvvnNqUYAAKtTL.jpg",
"https://pbs.twimg.com/media/ERvvnVmVUAA71I6.jpg",
"https://pbs.twimg.com/media/ERvvnYPU4AA5u5w.jpg",
"https://pbs.twimg.com/media/ERvvnsOVUAA5_ht.jpg"
]
},
{...
export const query = graphql`
query {
allTweetsJson {
edges {
node {
id
tweet_id
text
user_screen_name
images
}
}
}
}
`
ツイートの取得
Twitter APIを使ってツイートを取得してMySQLにぶっ込むNode.jsのスクリプトが手元にあったのでそれを流用しました(最初MySQLを使ってたのはこういう事情もある)。
流れとしてはこんな感じ。
- それっぽいハッシュタグで検索をかける。
- 取得したツイートでサイトに展示するものを目視で選定する。
- 選定したツイートの埋め込みコードをAPIで取得・保存する。
検索の search/tweets ではパラメータに include_entities: true を指定して、画像のURLが取れるようにする(ものによっては画像があるのになぜか取れない謎)。
キーワードはハッシュタグを指定するのだが、以下のようにしてリツイートを省かないとノイズが大きい。
{q: "#岡山県立大学卒展2020 exclude:retweets}
レートリミットがあるので、効率的に取得するためにcountは最大の100件を指定。
最新のツイートが取得されるので、さかのぼって取得するループを回すためには、
都度 max_id を指定してカーソルを移動させる必要がある。
埋込み用のコードは statuses/oembed で取得できる。
この埋め込みコードには、ツイート展開用の
<script async src=\"https://platform.twitter.com/widgets.js\" charset=\"utf-8\"></script>
が含まれるが、各ツイートに含める必要はないので、これは削除しておく。
必要なフィールドをいい感じにJSONに保存してデータの準備は完了。
無限スクロール
ページングはユーザー側の操作が手間なので避けたくて、
TwitterやPinterestのような無限スクロールを実装した。
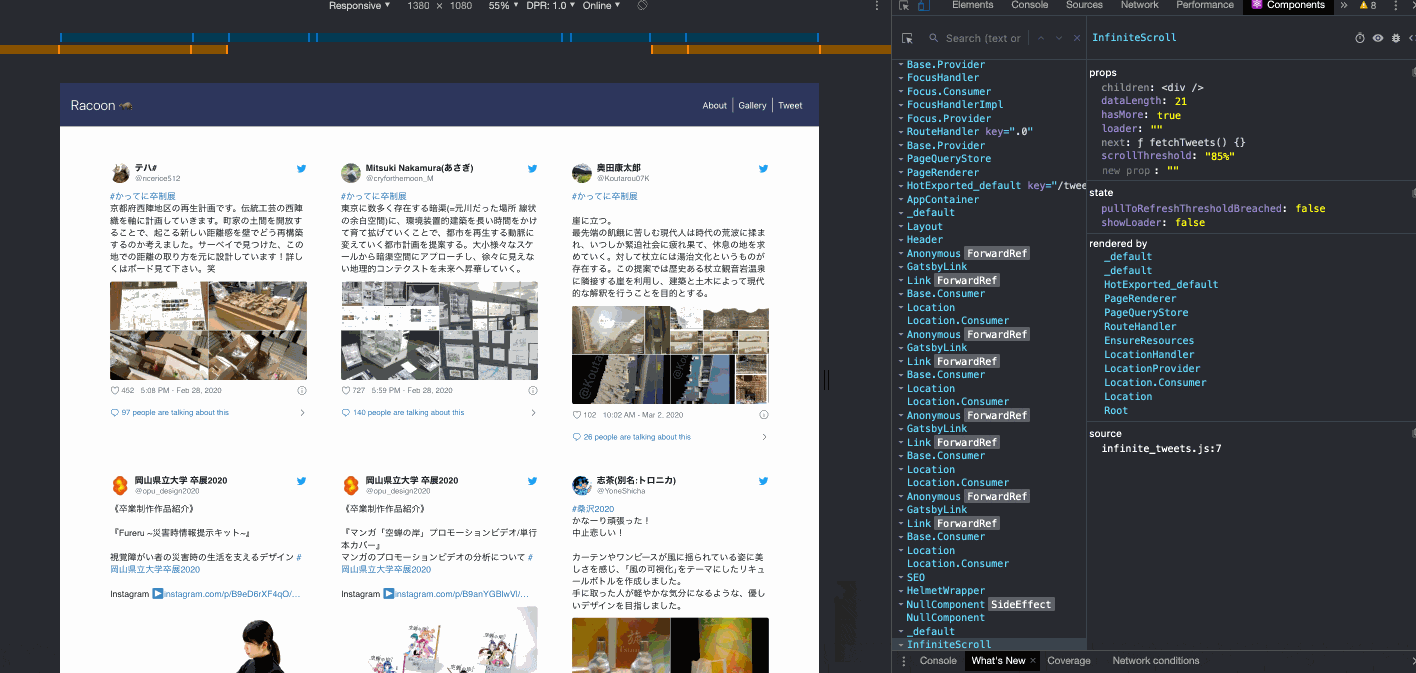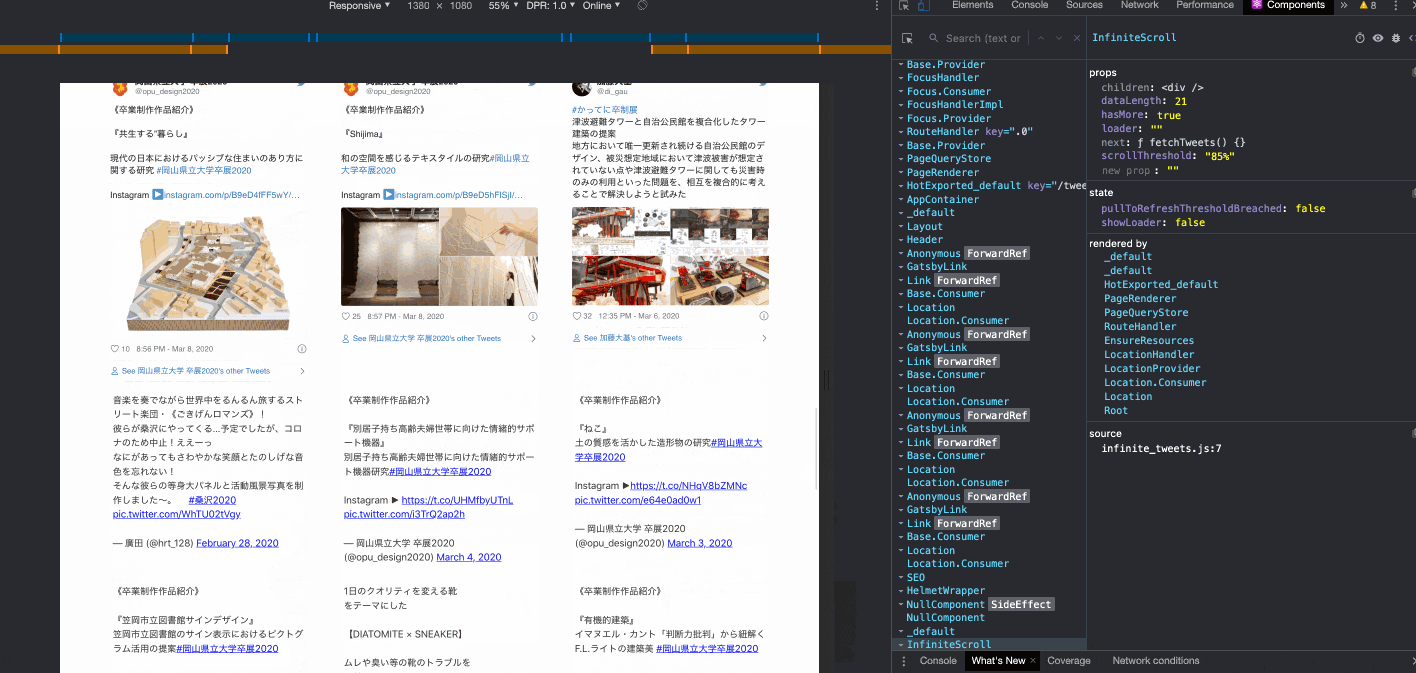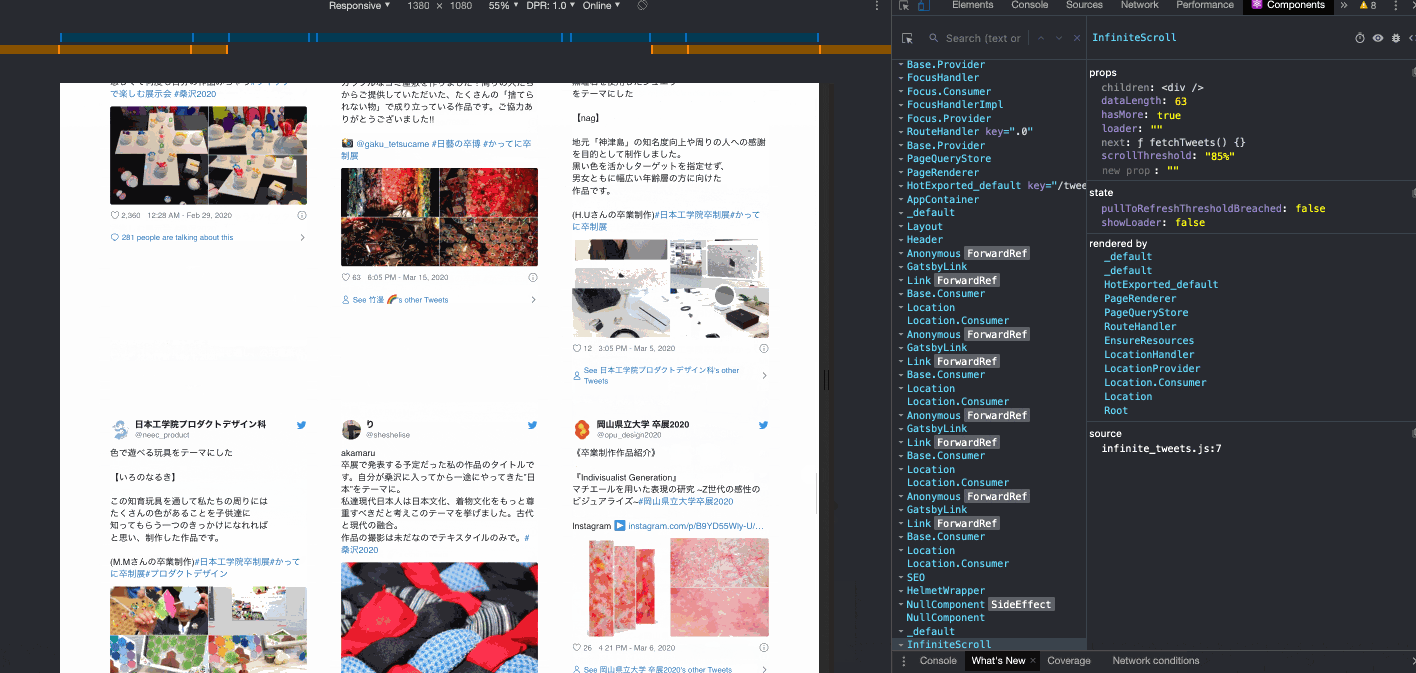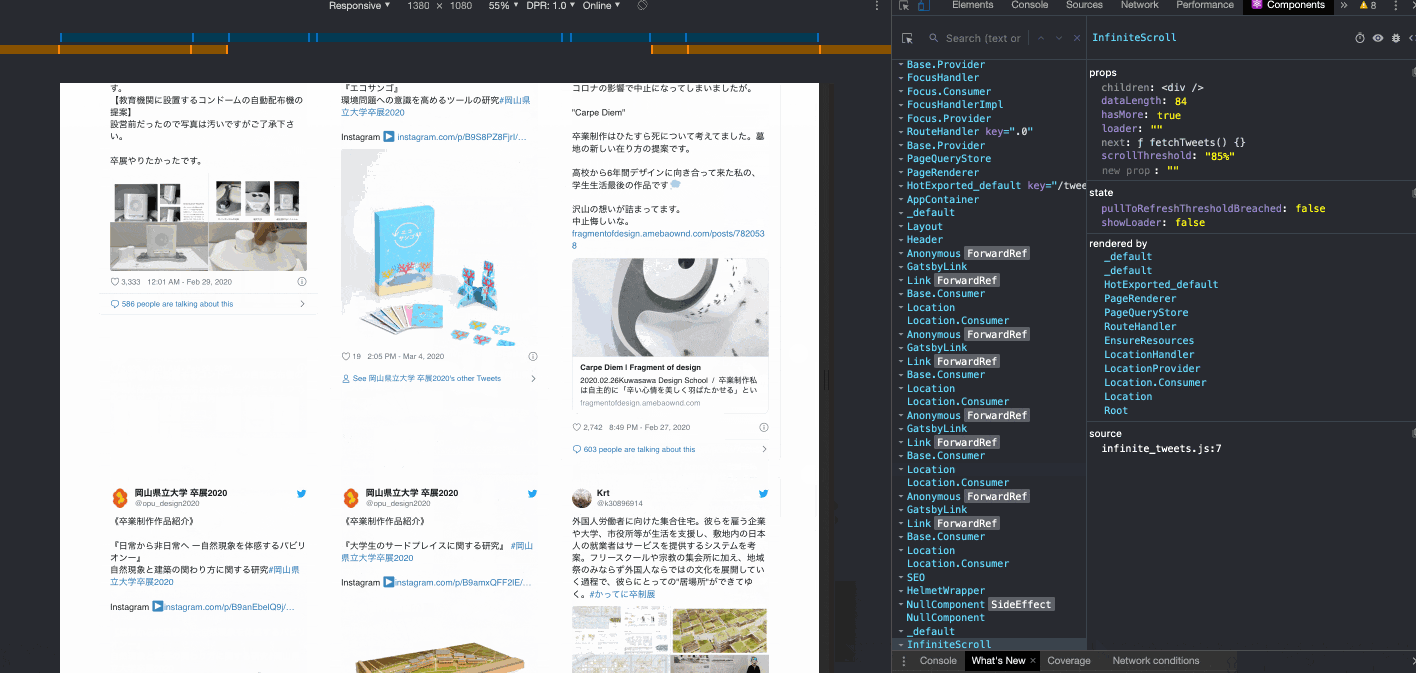
IntiniteScroll の dataLength が21ずつ増えているのがわかると思う。
Twitterのウィジェットが重いので、カード展開前に素のテキストが一瞬見えてしまうことがあるが、もう少しみ読み込み位置を早くすれば対処は可能。
いまはコンテナの高さの85%まで来ると読み込みが走るようになっている。
ライブラリには react-infinite-scroll-component を使用した。
これをラップしたコンポーネントを作り、
親コンポーネントの useState, useEffectで更新を制御している。
let allTweets = null
export default ({data}) => {
const [tweets, setTweets] = useState([])
const [hasMore, setHasMore] = useState(true)
const [page, setPage] = useState(0)
const PER = 21 // dividable by 3
useEffect(() => {
allTweets = data.allTweetsJson.edges.sort(() => { return Math.random() - .5 })
fetchTweets() // initialize
}, [])
const fetchTweets = () => {
const pageResult = allTweets.slice(page * PER, page * PER + PER)
setTweets(tweets.concat(pageResult))
setPage(page + 1)
if (page * PER >= allTweets.length) {
setHasMore(false)
}
if (window.twttr) {
window.twttr.widgets.load(document.getElementById(styles.tweet_container))
}
}
まず useEffect 内で全てのツイートをJSONから読み込んでランダムにソートしている。
なるべくいろんな作品を見てもらえるように閲覧のたびにファーストビューの作品は入れ替えたかったので、ランダムに取得する必要があった。
静的に作った場合だとこれは不可能。
ビルド時に順番は固定されてしまい、再ビルドされるまでは変わらないことになってしまう。
これは無限スクロールの話とは別で、静的なページにはデータを持たせずに、
非同期に外部からデータを取得してくる設計にする必要がある。
そうなると別にGatsbyじゃなくてよくね...という話になるのだが、
他のページは静的にビルドしているし、動的にしたいのはここだけ、
そこはReactでいろいろ書けばいいよね!というのがまさにこのフレームワークの強みなんだと思う。
無限スクロールの話に戻るが、propsには、新しいページの結果だけでなく、
これまでの結果をマージして渡す必要があるので結合している。
const pageResult = allTweets.slice(page * PER, page * PER + PER)
setTweets(tweets.concat(pageResult))
そして新たに追加されたツイートをカードとして展開するには、再度ウィジェットの読み込みを走らせる必要がある(Twitterの公式ドキュメント)。
if (window.twttr)
window.twttr.widgets.load(document.getElementById(styles.tweet_container))
}
そもそもカードの展開には最初 gatsby-plugin-twitter というプラグインを使っているのだが、
こいつの仕組みがよくわからなかったのでやめた。
widgets.js が読み込まれた形跡がなく、
twttr オブジェクトもスコープに存在しないため、load() を呼び出すことができなかったからだ。
代わりに自前で <script>タグを追加する方法を取っている。
import Helmet from "react-helmet"
<Helmet>
<script src="https://platform.twitter.com/widgets.js" type="text/javascript" async></script>
</Helmet>
Pinterest風レイアウト
ツイートには最大4枚の画像が含まれるので、それらを取り出してランダムに並べる画面を別で作っています。
無限スクロールで仕組みは前述のものと同じです。

GatsbyJSで画像を使う際は、gatsby-image コンポーネント使うことが推奨されています。
Working with Images in Gatsby
これは何かというと、閲覧しているデバイスに応じて複数のサイズ・解像度に画像を最適化してくれるライブラリで、GraphQLでクエリできるようになっています。
他にも以下のような特徴があります。
gatsby-image is a plugin that automatically creates React components for optimized images that:
・Loads the optimal size of image for each device size and screen resolution
・Holds the image position while loading so your page doesn’t jump around as images load
・Uses the “blur-up” effect i.e. it loads a tiny version of the image to show while the full image is loading
・Alternatively provides a “traced placeholder” SVG of the image
・Lazy loads images, which reduces bandwidth and speeds the initial load time
Uses WebP images, if browser supports the format
使い方には fluid と fixed があって、
コンテナのサイズに応じて伸び縮みする fluid と、固定サイズの fixed を使い分けます。
レスポンシブ対応で、スマホサイズでは fixed にするみたいな使い分けをしています。
GraphQLはこういう風に書く
query($id: String!) {
tweetsJson(tweet_id: { eq: $id }) {
id
text
tweet_id
embed_html
featuredImg {
childImageSharp {
fluid(maxWidth: 400, quality: 100) {
...GatsbyImageSharpFluid
}
fixed(width: 200, height: 200) {
...GatsbyImageSharpFixed
}
}
}
}
}
と、ここまで説明したところでなんなんですが、
アニメーションやスタイルの関係上、この画面ではあえて使っていません。
flexboxと一緒に使うと表示されなかったり、なかなか使い勝手が難しいライブラリです😢
(※ホバー時に元ツイートの情報を表示するようにしてたりする)

スタイルの問題は他にもあって、
Pinterest風にマルチカラムにするのにCSSのcolumnsプロパティを使っているんですが、
画像の高さがそれぞれ違うので次ページ読み込み時に並び替えが起こってしまいます。
columnsはコンテンツを左から埋めていくので、
画像が追加された時に前ページの画像が全て左に寄せられてしまい、
見ていたコンテンツが消える事象が発生することなります。
これではユーザーが?となるので、これまで見ていたページの並びは固定するために、
ページごとにcolumnsを指定するコンテナでラップすることにしました。

画像の組み合わせによっては不要な余白が生じてしまうのですが。
別の仕組みでグリッドレイアウトを作れば良い話なんですが、
時間があるときでもやろうと思います。
外部画像を最適化するトリック
ソースファイルに含まれているデータは tweets.json 1ファイルのみです。
[
{
"tweet_id": "1232842391867912192",
"created_at": "2020-02-27T01:38:25.000Z",
"text": "#桑沢2020 \n\n私は紙で椅子をつくりました。\n\n桑沢の卒展は、自分にとってすごくすごく特別な想いがありました。\n\n小学生から憧れ続けた桑沢卒展、中止。 https://t.co/2Q1oZ0RvAm",
"hashtags": "桑沢2020",
"user_id": "1093916680504336384",
"user_screen_name": "fuji_kohei",
"embed_html": "<blockquote class=\"twitter-tweet\"><p lang=\"ja\" dir=\"ltr\"><a href=\"https://twitter.com/hashtag/%E6%A1%91%E6%B2%A22020?src=hash&ref_src=twsrc%5Etfw\">#桑沢2020</a> <br><br>私は紙で椅子をつくりました。<br><br>桑沢の卒展は、自分にとってすごくすごく特別な想いがありました。<br><br>小学生から憧れ続けた桑沢卒展、中止。 <a href=\"https://t.co/2Q1oZ0RvAm\">pic.twitter.com/2Q1oZ0RvAm</a></p>— kohei_fuji (@fuji_kohei) <a href=\"https://twitter.com/fuji_kohei/status/1232842391867912192?ref_src=twsrc%5Etfw\">February 27, 2020</a></blockquote>\n",
"images": [
"https://pbs.twimg.com/media/ERvvnNqUYAAKtTL.jpg",
"https://pbs.twimg.com/media/ERvvnVmVUAA71I6.jpg",
"https://pbs.twimg.com/media/ERvvnYPU4AA5u5w.jpg",
"https://pbs.twimg.com/media/ERvvnsOVUAA5_ht.jpg"
]
},
画像のURLとしてTwitterのURLが格納されていますが、
アプリケーションから参照しているのはこのURLではありません。
これは作品の詳細ページですが、画像のsrcは
/static/f6862a78b0b14267e3e9188b58d053a6/25252/ESUa1ooUYAAOn4I.jpg
となっています。
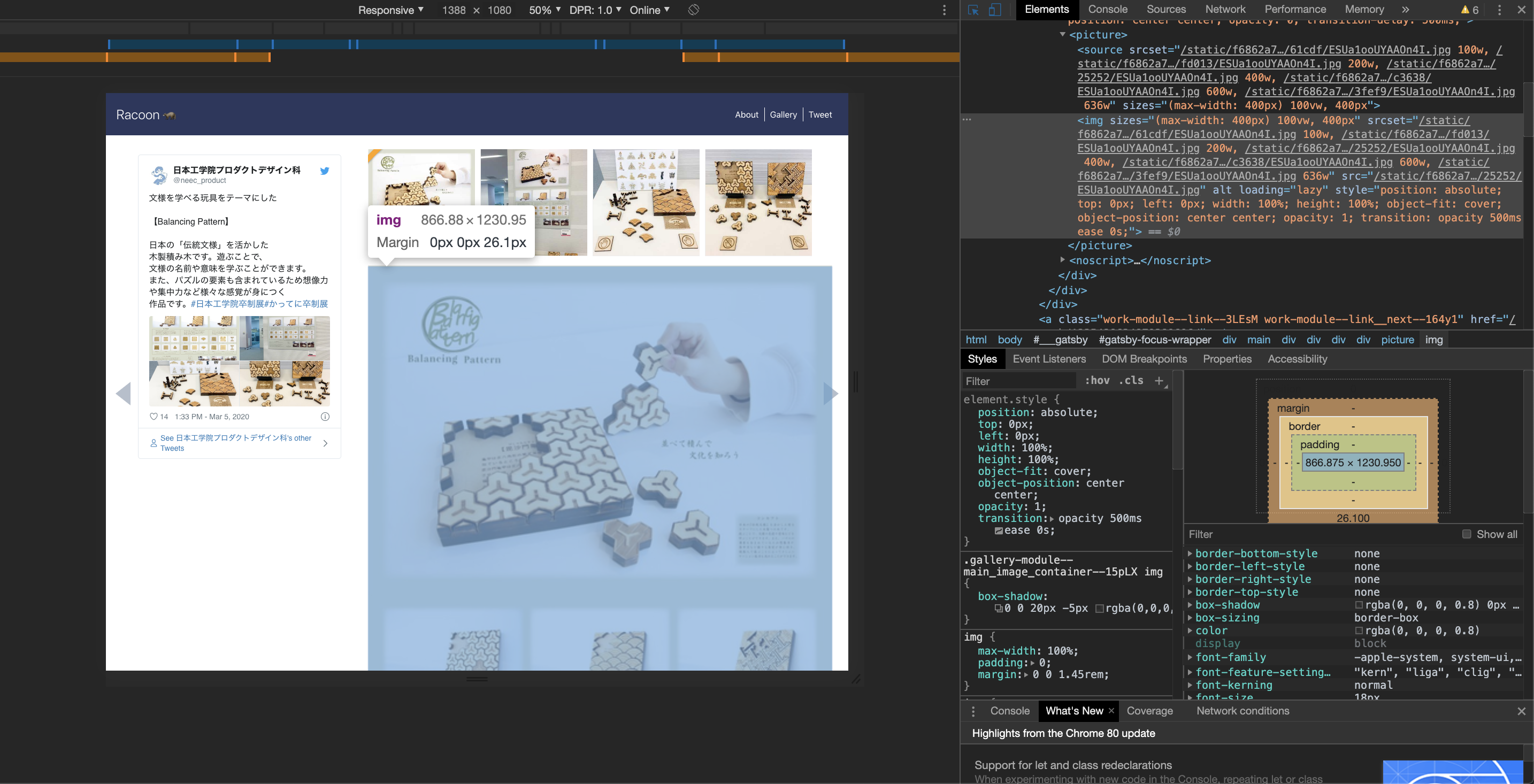
GatsbyJSの仕様では、プロジェクトルートに static という名前のフォルダを置いて、
画像などのアセットを含めるのが通例です。
そうすると、ビルド時に成果物の public の下に static が残ります。
しかし今回は static の下に画像を置くのではなく、JSONにリモートのURLを記述しているだけです。
これをビルドの成果物に含める、かつ、先述の gatsby-image の最適化を施す必要があります。
gatsby-imageに処理をさせるためには、なんらかの形でこのURLをGraphQLのNodeに変換する必要があるのですが、これを createRemoteFileNode という Gatsby Node APIs を利用して実現します。
そしてGraphQLのresolverとしてこのNodeを登録します。
(うまく説明できなくてすまぬ...)
GraphQLのリゾルバとは
コードはこんな感じ。
exports.createResolvers = ({
actions,
cache,
createNodeId,
createResolvers,
store,
reporter,
}) => {
const { createNode } = actions
createResolvers({
TweetsJson: {
featuredImg: {
type: [`File`],
resolve(source, args, context, info) {
return source.images.map((image) => {
return createRemoteFileNode({
url: image,
store,
cache,
createNode,
createNodeId,
reporter,
})
})
},
},
},
})
}
まずこのファイルだが、プロジェクトルートにある gatsby-node.js いうファイルで、
ビルド時に実行されるもの。
ここにコードを書いておくと、GraphQLのNode生成などのイベントを拾ってなんらかの処理を行うことができる。
そこで createResolvers を呼んで、TweetsJson(tweets.jsonから生成されたスキーマ)に featuredImg というフィールドを生やしている。
中身は File の配列で(画像が複数枚の場合があるため)、
createRemoteFileNode の戻り値を追加している。
この前処理があってこそ、前述のこのクエリが実行できるという仕組み。
query($id: String!) {
tweetsJson(tweet_id: { eq: $id }) {
id
text
tweet_id
embed_html
featuredImg {
childImageSharp {
fluid(maxWidth: 400, quality: 100) {
...GatsbyImageSharpFluid
}
fixed(width: 200, height: 200) {
...GatsbyImageSharpFixed
}
}
}
}
}
Nodeにあるフィールドを追加したければ、
onCreateNode で createNodeFieldを呼ぶのがシンプルで簡単な方法です。
実際 チュートリアル でもそうやっています。
わざわざ createResolvers なんてややこしいのを使っているのはちょっとしたハックで、
これが、全てのスキーマの処理が完了してから最後に呼ばれるAPIだからです。
TweetsJson というスキーマの元はJSONファイルであり、
このファイルをまずGraphQLのスキーマに変換する処理が発生します。
必ずこの作業が終わった後に処理をする必要があるため、createResolvers にしてあるというわけです。
これで無事に gatsby-image が処理できる形にリモートの画像URLが変換されたので、
ビルド時に様々なデバイスサイズ、解像度向けに static 配下に画像が生成されるようになります。
作品ページの生成
作品ごとのページを作ります。

(サムネイルをクリックすると画像が変わる仕様。)
チュートリアルでは、マークダウンから記事ページを作成しています。
Programmatically create pages from data
ユースケースとしてはこういう使い方が多いと思いますが、今回のデータソースはJSONです。
GatsbyJSでは、あらかじめ src/pages に置いてあるファイルはビルド時に自動的にページとして出力されています。
それ以外に任意にページを作成したい場合は、先述の gatsby-node.js から createPage APIを呼び出すことになります。
exports.createPages = async ({ graphql, actions }) => {
const { createPage } = actions
const result = await graphql(`
query {
allTweetsJson {
edges {
node {
id
tweet_id
images
}
}
}
}
`)
result.data.allTweetsJson.edges.forEach(({ node }, index) => {
createPage({
path: `/work/${node.tweet_id}/`,
component: path.resolve(`./src/templates/work.js`),
context: {
id: node.tweet_id,
next: index !== result.data.allTweetsJson.edges.length - 1 ? result.data.allTweetsJson.edges[index + 1].node : null,
prev: index !== 0 ? result.data.allTweetsJson.edges[index - 1].node : null,
},
})
})
}
component にテンプレートとなる Reactコンポーネントのファイルを渡しています。
context で渡した値は、テンプレート側で pageContext で受けることができます。
前後のページのリンクを作りたかったので、ここでは前後のNodeを受け渡すようにしています。
export default ({data, pageContext}) => {
}
idは該当記事を取得するページクエリで $id で参照します。
export const query = graphql`
query($id: String!) {
tweetsJson(tweet_id: { eq: $id }) {
id
text
tweet_id
embed_html
hashtags
images
featuredImg {
publicURL
childImageSharp {
fluid(maxWidth: 400, quality: 100) {
...GatsbyImageSharpFluid
}
fixed(width: 200, height: 200) {
...GatsbyImageSharpFixed
}
}
}
}
}
URLは path で指定するのですが、Nodeの id は避けたほうがよいです。
コンテンツの追加/削除、再ビルドで変化する可能性があるので、
不変なユニークな値を指定しておくのが無難です。
チュートリアルにならってスラッグを指定するといいと思います。
OGP画像
デフォルトで SEO というコンポーネントがついてくる。
内部的には react-helmet を使っている。
作品のページでは、その作品の画像やテキストに切り替えたいので以下のようにして使う。
<SEO description={data.tweetsJson.text} image={data.tweetsJson.featuredImg[0].publicURL} />
createRemoteFileNode で Nodeにした外部画像ですが、
出力された static/***のパスを publicURL で取得することができます。
作品のOGPはこんな感じ。
— 青いエンジニア🦋 (@itmono_sakuraya) March 21, 2020
通常のOGPと変わっていることがわかります。
(アライグマ(racoon)は Corona のアナグラムです)#桑沢2020 #かってに卒制展 #岡山県立大学卒展2020 #日本工学院卒制展https://t.co/Q8Sgg3F5ot
— 青いエンジニア🦋 (@itmono_sakuraya) March 21, 2020
ホスティング
このサイトは CloudFront で配信しています。
S3のWebホスティング機能は使用していません。
独自ドメイン(CNAME)とSSLも設定済み。

Origin Access Identity を指定して、バケットの直接参照は禁止しています。
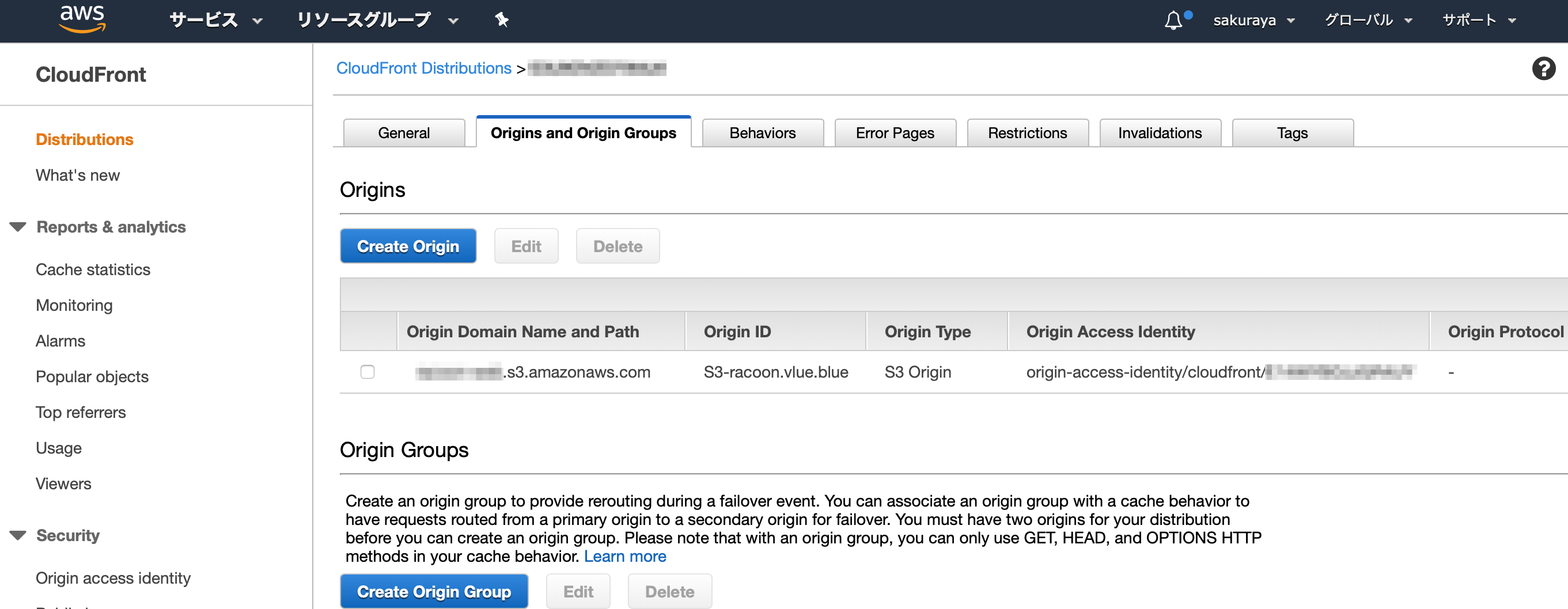
以下バケットポリシー
{
"Version": "2008-10-17",
"Id": "PolicyForCloudFrontPrivateContent",
"Statement": [
{
"Sid": "1",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::cloudfront:user/CloudFront Origin Access Identity ******"
},
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::{bucket_name}/*"
}
]
}
また、サブディレクトリのルートオブジェクトを設定するために、Lambda@edgeをかましてあります。
静的Webサイトホスティングでは、 /hoge/ へのアクセスを /hoge/index.html に補完してくれるのですが、
CloudFront単体ではルートでしかこれが効かないので、自前で対処する必要があります。
サブディレクトリ以下のアクセス /*/ に対して、
Lambda@Edge を関連づけた Behavior を最優先で設定します。

'use strict';
exports.handler = (event, context, callback) => {
const request = event.Records[0].cf.request;
request.uri = request.uri.replace(/\/$/i, '/index.html');
callback(null, request);
};
Lambda@Edgeってなに?っていう方は拙著をお読みください。
Lambda@Edgeを完全に理解する🧘♀️
さらにもう一手間。
存在しないURLに対して正しく404を出すために、Custom Error Response の設定をします。

404だけでなく403も設定しているのは、
S3は404エラーを403エラーで隠蔽することがあるからです。
ListBucket権限がないのが原因だったりします。
詳しくは。これも拙著です。
CloudFront×S3で403 Access Deniedが出るときに確認すべきこと
デプロイ
gatsby-plugin-s3 でやってます。
npm run deploy を流すだけです。
ドキュメントがないのですが、acl: null を指定しないと権限エラーになります。
{
resolve: `gatsby-plugin-s3`,
options: {
bucketName: "******",
acl: null
},
},
まとめ
こんなところです。
GraphQL初めて触るし、React書くの2年ぶりとかなので割と時間がかかってしまいましたが、
GatsbyJSはかなり可能性のあるフレームワークだなーと感じました。
特有の癖はありつつも、覚えてしまえばまあ。
あまりWebに馴染みのない人が、楽にWebサイトを構築できる手段だと思って使うと痛い目を見るかもしれません。
この記事でも紹介した通り、基本静的で動かしたい、でも動的にしたいところもある、
というユースケースでは力を発揮するんじゃないですかね。
何はともあれみなさんアートを楽しんでください。
— 青いエンジニア🦋 (@itmono_sakuraya) March 22, 2020