0. 背景 & 未来予想(=妄想)
OpenAIが発表したFunction callingが話題ですね。
「ユーザの入力からJSONを出力させて、動的に関数を実行させる」といった仕組みは、Langchain・SemanticKernelなどにもありました。(本記事ではこの機能のことをエージェントと呼びます。)
今後、益々エージェントのような仕組みが流行るのではないかと感じています。
ただ、色々触っていると「 機能拡張しすぎたら エージェント君が迷ってしまうのでは? 」という疑問が浮かび上がりました。
ドメイン(ユースケース)ごとにエージェントを分けるのも拡張性・柔軟性が損なわれてしまいそうなので、なにかいい方法はないかと考えていました。
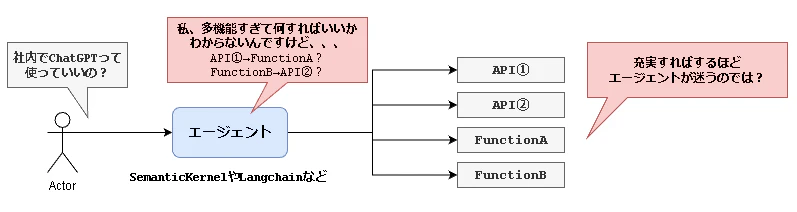
このような課題(妄想)を解決する方法はないかと探っている中で浮かんだ一つのアイデアです。
「 ユーザと対話しながら実行計画を作ればいいのでは? 」といった思想がアイデアのベースです。
対話しながら実行計画を作成できるのであれば、エージェントに機能追加し放題かもしれないと思い、プロトタイプを作成してみました。
1. 全体像
今回の構成では、エージェントを2人用意します。
-
紫エージェント: guidance
- ユーザと対話しながら実行計画のベースを作成していきます。
-
guidanceで実装します。
-
青エージェント: SemanticKernel(sk)
- 実行計画のベースを受け取り、必要な関数を実行します。
-
skで実装します
紫エージェントでざっくりとした実行計画のベースを作り、
青エージェントで引数を含む詳細な実行計画を作成します。
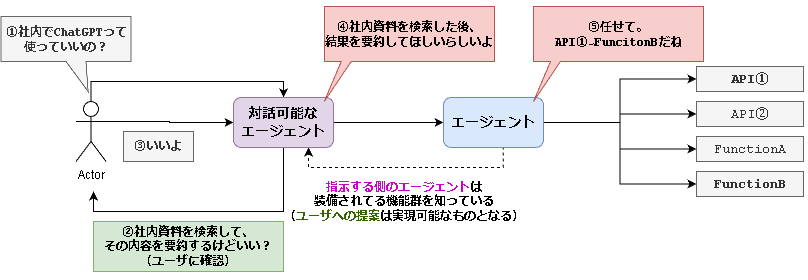
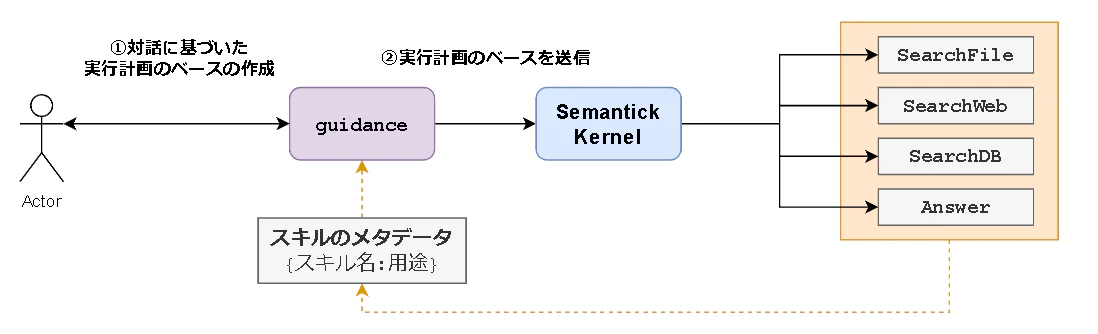
今回、青色のエージェントには以下の4つの機能を持たせています。
わざと似たような機能を用意してみました。
- SearchFile: 社内サーバから必要なファイルを取得することを想定した関数
- SearchWeb: Web検索で外部情報を取得することを想定した関数
- SearchDB: 社内データベースからデータを取得することを想定した関数
- Answer: 収集した情報とユーザの入力を基に回答を生成する関数
上記の機能(スキル)と実際の処理の流れを踏まえて図を書き直すと以下のようになります。
skでスキルを管理する時に、name=関数・スキル名とdescription=スキルの説明や用途を指定する必要があります。これをスキルのメタデータとして、guidance側にも渡してあげています。
「余談」
現在作成しているシステムではAnswerスキルをguidanceで実装しています。guidance on SemanticKernelとでも名付けましょう。このように名づけると大それたことのように聞こえますが、skのネイティブ関数はただのPythonとして記述できるため、guidanceをimportして使用しているだけです![]()
2. 実行例とソースコード
※今回Semantic Kernelで使用するスキルは適当に用意したものとなっています。呼び出されると文字列を返却します。

ソースコード全文
import os
import re
import json
import semantic_kernel as sk
from semantic_kernel.connectors.ai.open_ai import AzureChatCompletion
from semantic_kernel.skill_definition import sk_function, sk_function_context_parameter
from semantic_kernel import SKContext
from semantic_kernel.planning.basic_planner import BasicPlanner
import guidance
from dotenv import load_dotenv
load_dotenv()
# Semantic Kernel初期化
kernel = sk.Kernel()
deployment, api_key, endpoint = sk.azure_openai_settings_from_dot_env()
kernel.add_chat_service("gpt", AzureChatCompletion(deployment, endpoint, api_key))
# 実行計画のベース作成に使用するguidanceを初期化
guidance_llm = guidance.llms.OpenAI(
model="gpt-3.5-turbo",
api_type = "azure",
token=os.getenv("AZURE_OPENAI_API_KEY"),
endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
deployment_id=os.getenv("AZURE_OPENAI_DEPLOYMENT_NAME"),
api_version="2023-03-15-preview"
)
# テキスト分類に使用するguidanceを初期化
text_llm = guidance.llms.OpenAI(
model="text-davinci-003",
api_type = "azure",
token=os.getenv("AZURE_OPENAI_API_KEY"),
endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
deployment_id="text-davinci-003",
api_version="2022-12-01"
)
# guidance/Semantic Kernelで使用する関数(スキル)の定義
skills = [
{"name": "SearchFile", "description": "社内のサーバから必要なファイルを検索する関数"},
{"name": "SearchWeb", "description": "Web検索を行い必要な情報を収集する関数"},
{"name": "SearchDB", "description": "データベースから必要な情報を検索する関数"},
{"name": "Answer", "description": "ユーザの質問や最終的な出力を生成する関数"}
]
GUIDANCE_PROMPT = """
{{#system~}}
# 前提条件
- あなたはユーザの入力に基づいて実行計画を作成するプランナーです。
- 実行計画は「使用可能な関数」で定義された関数のみを使用できます。
{{~/system}}
{{#user~}}
# ゴール
- ユーザの入力から実行計画を作成すること
- 出力形式は以下のようなJSONフォーマット
```
{
"best_plan": [実行する関数名のリスト],
"description": "実行する関数名と目的の説明"
}
```
# 実行のプロセス
1. ユーザの入力を受け取り、実行計画を3つ作成する
2. 最も有効な実行計画が1位となるようにランク付けする
3. 1位の実行計画をJSONフォーマットに変換
4. JSONフォーマットに変数した実行計画のみを出力する
# 使用可能な関数
{{#each skills}}
- {{this.name}}: {{this.description}}
{{/each}}
{{~/user}}
{{#assistant~}}
はい。ユーザの入力に基づいて実行計画を作成し、JSONのみを出力します。
また、実行計画の作成には使用可能な関数を使用します。
{{~/assistant}}
{{#geneach 'chat' stop=False}}
{{#user~}}
ユーザの入力: {{set 'this.user_input' (await 'user_input')}}
必ずJSONだけを出力して
{{~/user}}
{{#assistant~}}
{{gen "this.plan" n=1 temperature=0 max_tokens=256}}
{{~/assistant}}
{{/geneach}}
"""
# JSONフォーマットのチェック・変換を行う関数
def format_json(current_plan:str)->dict:
try:
plan_dict = json.loads(current_plan)
except:
# {任意の文字列}を抽出する。DOTALLで改行も含めて検索
pattern = r"{.*}"
plan_json = re.search(pattern, current_plan, re.DOTALL).group()
plan_dict = json.loads(plan_json)
return plan_dict
# guidanceで実行計画のベースを作成
def generate_plan_base(first_user_input:str, user_input:str, executed_prompt=None):
# プロンプト初期化
prompt = guidance(GUIDANCE_PROMPT, llm=guidance_llm)
# ユーザの入力を基に実行計画のベースを作成するプロンプトを実行
if executed_prompt is None:
executed_prompt = prompt(
skills=skills,
user_input=user_input
)
else:
executed_prompt = executed_prompt(
skills=skills,
user_input=user_input
)
# 実行計画のベースを辞書型に変換
plan_base = format_json(executed_prompt["chat"][-2]["plan"])
# Semantic kernelに渡す情報
plan_base_str = f"ユーザの入力:{first_user_input}\n使用する関数:{plan_base['best_plan']}\n実行計画ベース:{plan_base['description']}"
return plan_base_str, executed_prompt
# ユーザの入力を分類する関数
def check_user_input(user_input:str) -> bool:
# モデルにYes, Noで分類させる
options = ["Yes", "No"]
# 分類用のプロンプト
select_prompt = guidance("""
あなたはユーザの入力に基づいて判定を行うassistantです。
ユーザの入力が単純な肯定を表している場合は「Yes」と判定する。
それ以外の場合は「No」と判定する。
example:
{
ユーザの入力: 実行して
判定: Yes
}
assitant:
{
ユーザの入力: {{user_input}}
判定: {{select 'isExec' options=options}}
}
""", llm=text_llm)
# 分類実行
select = select_prompt(
user_input=user_input,
options=options
)
if select["isExec"] == "Yes":
return True
else:
return False
# スキルの定義を参照する関数
def get_skill_by_name(skills, name):
for skill in skills:
if skill["name"] == name:
return skill
return None
# SearchFileスキル
class SearchFile:
skill_name = "SearchFile"
@sk_function(
name=get_skill_by_name(skills, skill_name)["name"],
description=get_skill_by_name(skills, skill_name)["description"],
input_description="前のスキルの実行結果。またはfirst_goal。",
)
@sk_function_context_parameter(
name="query",
description="検索クエリ",
)
def searchfile(self, context:SKContext) -> str:
# ファイル検索処理記述
print(f"前のスキルの実行結果:{context['input']}")
result = f"「{context['query']}」の社内ファイル検索結果"
return result
# SearchWebスキル
class SearchWeb:
skill_name = "SearchWeb"
@sk_function(
name=get_skill_by_name(skills, skill_name)["name"],
description=get_skill_by_name(skills, skill_name)["description"],
input_description="前のスキルの実行結果。またはfirst_goal。",
)
@sk_function_context_parameter(
name="query",
description="検索クエリ",
)
def searchweb(self, context:SKContext) -> str:
# Web検索処理記述
print(f"前のスキルの実行結果:{context['input']}")
result = f"「{context['query']}」のWeb検索結果"
return result
# SearchDBスキル
class SearchDB:
skill_name = "SearchDB"
@sk_function(
name=get_skill_by_name(skills, skill_name)["name"],
description=get_skill_by_name(skills, skill_name)["description"],
input_description="前のスキルの実行結果。またはfirst_goal。",
)
@sk_function_context_parameter(
name="sql",
description="SQL文",
)
def searchdb(self, context:SKContext) -> str:
# DB検索処理記述
print(f"前のスキルの実行結果:{context['input']}")
result = f"「{context['sql']}」のDB検索結果"
return result
# Answerスキル
class Answer:
skill_name = "Answer"
@sk_function(
name=get_skill_by_name(skills, skill_name)["name"],
description=get_skill_by_name(skills, skill_name)["description"],
input_description="前のスキルの実行結果。またはfirst_goal。",
)
@sk_function_context_parameter(
name="first_goal",
description="ユーザの最終的な目的。最初にユーザが入力した内容。",
)
def answer(self, context:SKContext) -> str:
# 回答生成処理 (実際の処理は省略していますが、私が使用している環境ではここにguidanceを使用しています。)
# 自由にPythonを記述できるのは嬉しいですよね。
return f"「{context['input']}」 を基に回答します。"
# SemanticKernelのプランナーを実行する関数
async def exec_skplanner(plan_base:str) -> str:
print("\n!!! Semantic Kernel !!!\n")
# スキルの読み込み
skills_dir = "tmp" # ※本来であればskのスキルはフォルダで管理します。
kernel.import_skill(SearchFile(), skill_name="SearchFileSkill")
kernel.import_skill(SearchWeb(), skill_name="SearchWebSkill")
kernel.import_skill(SearchDB(), skill_name="SearchDBSkill")
kernel.import_skill(Answer(), skill_name="AnswerSkill")
# プランナーを作成し、実行計画を生成
print(f"\n### 実行計画のベース ###\n{plan_base}")
planner = BasicPlanner()
plan = await planner.create_plan_async(plan_base, kernel)
# 実行計画を表示
plan_dict = json.loads(plan.generated_plan["input"])
print("\n### 実行計画 ###")
print("サブタスク:")
for task in plan_dict['subtasks']:
print(f" - {task}")
# 実行計画を実行
print("\n### 結果 ###")
plan_result = await planner.execute_plan_async(plan, kernel)
print(plan_result)
async def main():
# ユーザの初回入力を受け取り、実行計画のベースを作成する
first_user_input = input("ゴール: ")
plan_base_str, executed_prompt = generate_plan_base(first_user_input, first_user_input)
while True:
# ユーザに確認を行う
user_input = input(f"\n###\n{plan_base_str}\n###\n\nこれでよろしいでしょうか?: ")
print("-"*40)
# ユーザの入力を分類する
isExec = check_user_input(user_input)
# ユーザの入力が肯定の場合は終了
if isExec:
# Semantic Kernelに実行計画のベースを渡し、処理を行う
response = await exec_skplanner(plan_base_str)
break
else:
# ユーザの入力が否定の場合は、実行計画のベースを再作成する
plan_base_str, executed_prompt = generate_plan_base(first_user_input, user_input, executed_prompt)
import asyncio
asyncio.run(main())
※ ファイル分割などしておらず殴り書きしていて長いですが、コピペで動くと思います。
実行するには以下の2点が必要です
pip install semantic_kernel guidance-
.envファイル
AZURE_OPENAI_ENDPOINT=
AZURE_OPENAI_API_KEY=
AZURE_OPENAI_DEPLOYMENT_NAME=
3. ユーザとの対話部分
実行イメージ
- 実行画面(1/2)
- 青色はユーザ定義のリストを展開している部分です。
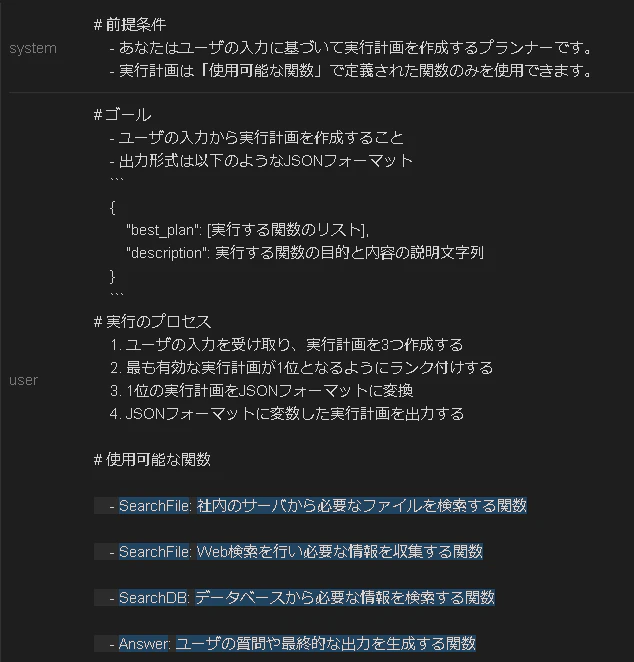
- 実行画面(2/2)
- 緑色はモデルが生成した文字列です。(今回の場合、実行計画のベースです)
- 青色は実行待機中を表しています。

使用するguidanceブロック
ブロックと呼ぶのかは分かりませんが、本記事では{{}}のことをブロックと呼びます。
以下はユーザの入力からJSON形式で実行計画のベースを生成するプロンプトの例です。
guidanceプロンプトの実装例
GUIDANCE_PROMPT = """
{{#system~}}
# 前提条件
- あなたはユーザの入力に基づいて実行計画を作成するプランナーです。
- 実行計画は「使用可能な関数」で定義された関数のみを使用できます。
{{~/system}}
{{#user~}}
# ゴール
- ユーザの入力から実行計画を作成すること
- 出力形式は以下のようなJSONフォーマット
```
{
"best_plan": [実行する関数名のリスト],
"description": "実行する関数名と目的の説明"
}
```
# 実行のプロセス
1. ユーザの入力を受け取り、実行計画を3つ作成する
2. 最も有効な実行計画が1位となるようにランク付けする
3. 1位の実行計画をJSONフォーマットに変換
4. JSONフォーマットに変数した実行計画を出力する
# 使用可能な関数
{{#each skills}}
- {{this.name}}: {{this.description}}
{{/each}}
{{~/user}}
{{#assistant~}}
はい。ユーザの入力に基づいて実行計画を作成し、JSONのみを出力します。
また、実行計画の作成には使用可能な関数を使用します。
{{~/assistant}}
{{#geneach 'chat' stop=False}}
{{#user~}}
ユーザの入力: {{set 'this.user_input' (await 'user_input')}}
必ずJSONだけを出力して
{{~/user}}
{{#assistant~}}
{{gen "this.plan" n=1 temperature=0 max_tokens=256}}
{{~/assistant}}
{{/geneach}}
"""
今回の実装では主に以下のブロックを使用しています。
-
{{each 変数名}}→ スキル=使用可能な関数の展開- Pythonのリストループで展開し、プロンプトに埋め込めます
- guidanceとskで使用するスキルの情報をリストとして定義しています。
-
{{geneach 変数名}}→ ループ処理の実現- このブロックで囲った部分は、繰り返し実行されます。
- stop=Falseとすると永遠に推論を繰り返します。
- 実行計画の修正に使います。
-
{{set 変数名 (await 変数名)}}→ 非同期処理の実現(実行完了を待機)- プロンプトの外部から変数名が挿入されるまで、以降のプロンプトを実行せずに待機状態になります。
-
{{geneach}}と合わせると、会話形式を実現可能です。
-
{{system}}, {{user}}, {{assistant}}- チャット用のプロンプトを記述する際に使用するブロック達です。
処理(プロンプト)の流れ
プロンプトの流れは単純ですが、ループ処理の実現方法が少し特殊です。
- システムメッセージを与えて、
- 出力例を示して、
- 会話用のループを実行する
ループ処理には、{{geneach}}を使用します。
{{set await()}}を合わせて使用することで、ユーザの追加入力を待つことができます。
ユーザの追加入力が発生した場合、以降のプロンプトが処理されます。
以下のソースコードを実行するとイメージが湧くかと思います。
実装例
import os
import guidance
from dotenv import load_dotenv
load_dotenv()
# guidanceの初期化
guidance_llm = guidance.llms.OpenAI(
model="gpt-3.5-turbo",
api_type = "azure",
token=os.getenv("AZURE_OPENAI_API_KEY"),
endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
deployment_id=os.getenv("AZURE_OPENAI_DEPLOYMENT_NAME"),
api_version="2023-03-15-preview"
)
# guidance/Semantic Kernelで使用する関数(スキル)の定義
skills = [
{"name": "SearchFile", "description": "社内のサーバから必要なファイルを検索する関数"},
{"name": "SearchWeb", "description": "Web検索を行い必要な情報を収集する関数"},
{"name": "SearchDB", "description": "データベースから必要な情報を検索する関数"},
{"name": "Answer", "description": "ユーザの質問や最終的な出力を生成する関数"}
]
GUIDANCE_PROMPT = """
{{#system~}}
# 前提条件
- あなたはユーザの入力に基づいて実行計画を作成するプランナーです。
- 実行計画は「使用可能な関数」で定義された関数のみを使用できます。
{{~/system}}
{{#user~}}
# ゴール
- ユーザの入力から実行計画を作成すること
- 出力形式は以下のようなJSONフォーマット
```
{
"best_plan": [実行する関数名のリスト],
"description": "実行する関数名と目的の説明"
}
```
# 実行のプロセス
1. ユーザの入力を受け取り、実行計画を3つ作成する
2. 最も有効な実行計画が1位となるようにランク付けする
3. 1位の実行計画をJSONフォーマットに変換
4. JSONフォーマットに変数した実行計画を出力する
# 使用可能な関数
{{#each skills}}
- {{this.name}}: {{this.description}}
{{/each}}
{{~/user}}
{{#assistant~}}
はい。ユーザの入力に基づいて実行計画を作成し、JSONのみを出力します。
また、実行計画の作成には使用可能な関数を使用します。
{{~/assistant}}
{{#geneach 'chat' stop=False}}
{{#user~}}
ユーザの入力: {{set 'this.user_input' (await 'user_input')}}
必ずJSONだけを出力して
{{~/user}}
{{#assistant~}}
{{gen "this.plan" n=1 temperature=0 max_tokens=256}}
{{~/assistant}}
{{/geneach}}
"""
prompt = guidance(GUIDANCE_PROMPT, llm=guidance_llm)
first_user_input = "AWS WAFってなに?"
executed_prompt = prompt(
skills=skills,
user_input=first_user_input
)
print(executed_prompt["chat"][-2]["plan"])
実行時の出力の一部
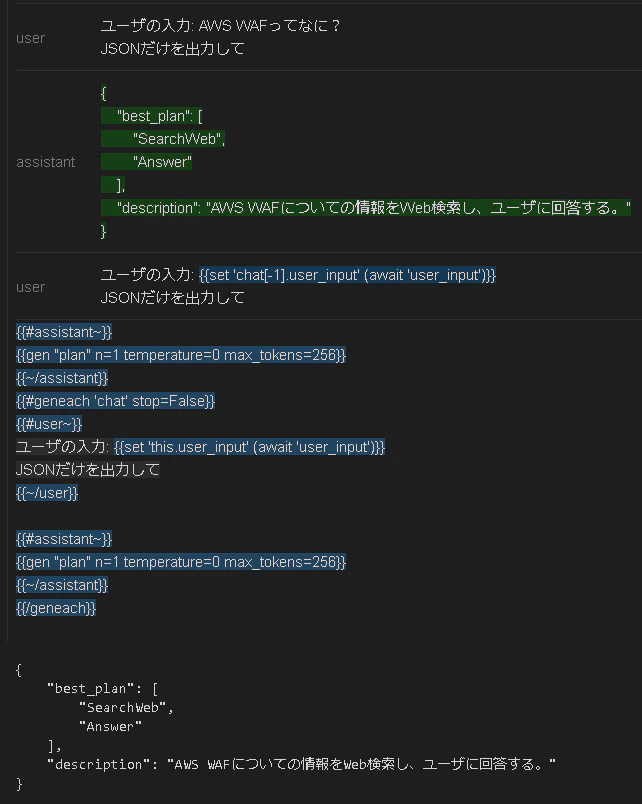
青色部分は待機中であることを表しています。
awaitで指定しているuser_inputが与えられるまで待機しています。
user_inputを与えてやると前の文脈も踏まえてプロンプトが実行されます。
先ほどの実行計画のベースではWeb検索をしようとしていました。
Webではなく、社内情報を検索してほしい場合、「Webではなく、社内情報を検索したい」という入力をしてあげます。
plan_fix = "Web検索ではなく、社内情報を検索してほしい"
executed_prompt = executed_prompt(
skills=skills,
user_input=plan_fix
)
print(executed_prompt["chat"][-2]["plan"])
すると以下のような出力を得られます。しっかりと SearchWeb → SearchFile の修正がされています。
前の文脈を考慮してくれるので、雑な指示でも修正ができていますね。
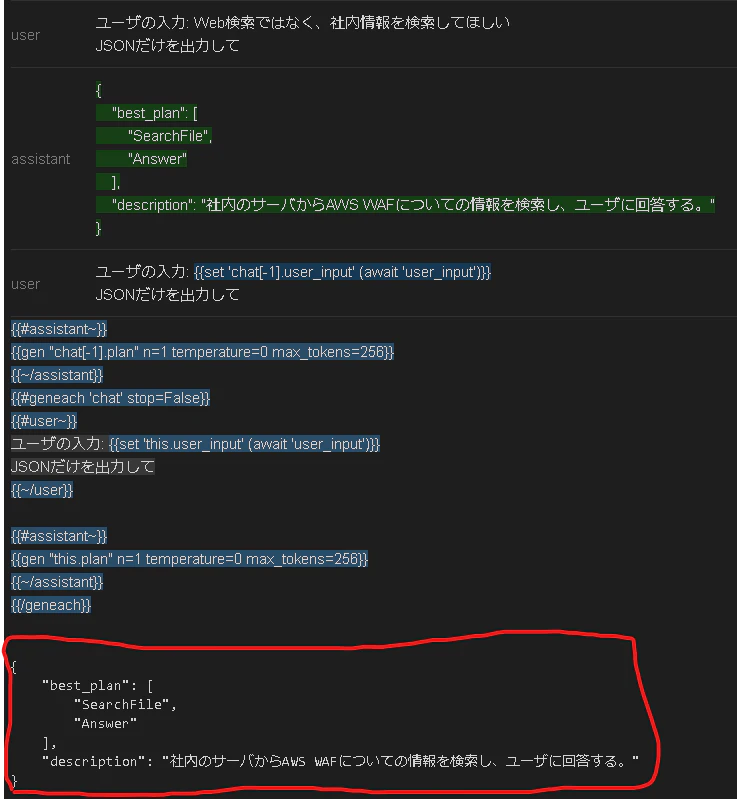
ちなみに、組み合わせや実行順序の指定などにも対応できます。
「全ての検索機能を使ってね。最初はWeb検索でお願い」という修正指示を入力してみます。
plan_fix = "あらゆる検索機能を使って。最初にWeb検索して"
executed_prompt = executed_prompt(
skills=skills,
user_input=plan_fix
)
print(executed_prompt["chat"][-2]["plan"])
以下のような出力となりました。いいですね。

※「それでも足りない場合は..」といった出力がありますが、skにはそのような機能はない(?)ため、実装するとなると力業で頑張るしかなさそうです。
4. 実行計画ベースの修正を終了と判定する
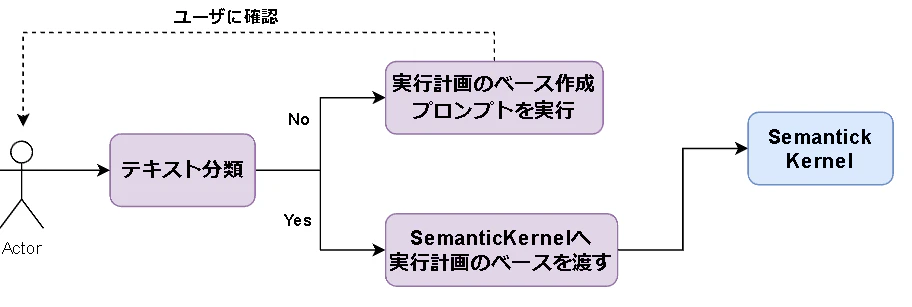
概要図
ユーザの入力が「 実行を促しているかどうか 」を判定するテキスト分類を行うことで処理を分岐させています。
詳細
実行計画のベースの修正はできるようになりましたが、終了条件がないためいつまで修正を続ければいいのかエージェントにはわかりません。
そこで以下のような仕組みで終了条件を作成してあげます。
- テキスト分類用のプロンプトを用意
- ユーザの入力を受け付ける
- 実行を促すような入力が得られた場合は
Yes、それ以外の場合はNoを返す
テキスト分類タスクとして終了判定の処理を実装しています。実際のプロンプトを見たほうが理解が楽だと思います。{{select}}を使用することで、「Yes, No」のどちらかを出力しなさいといった指示が可能です。
実装例: 終了判定用のテキスト分類処理
import os
import guidance
from dotenv import load_dotenv
load_dotenv()
text_llm = guidance.llms.OpenAI(
model="text-davinci-003",
api_type = "azure",
token=os.getenv("AZURE_OPENAI_API_KEY"),
endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
deployment_id="text-davinci-003",
api_version="2022-12-01"
)
select_prompt = guidance("""
あなたはユーザの入力に基づいて判定を行うassistantです。
ユーザの入力が単純な肯定を表している場合は「Yes」と判定する。
それ以外の場合は「No」と判定する。
example:
{
ユーザの入力: 実行して
判定: Yes
}
assitant:
{
ユーザの入力: {{user_input}}
判定: {{select 'isExec' options=options}}
}
""", llm=text_llm)
options = ["Yes", "No"]
user_input = "おk"
executed_prompt = select_prompt(
user_input=user_input,
options=options
)
print(select["isExec"])
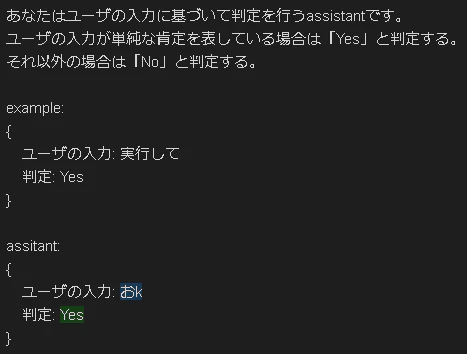
「おk」という入力に対して「Yes」という判定がされています。期待通りの動作です。
ユーザの入力にある程度幅を持たせることができるのは嬉しいですよね。
想定されるユーザの入力を用いて判定処理のテストをしてみました。テスト数は少ないですが、期待通りの動作をしていることを確認できます。
tests = ["AWS WAFってなに?", "Web検索してほしい", "OK", "実行して"]
reuslts = []
for user_input in tests:
select = select_prompt(
user_input=user_input,
options=options
)
reuslts.append(select)
print(reuslts)
### 出力 ###
['No', 'No', 'Yes', 'Yes']
「余談」
guidanceでは、{{}}で指定した箇所を出力させることができます。これにより、無駄なテキストが出力されなかったり、出力形式を限定できたり色々メリットがあると思います。
5. Semantic Kernelで実行計画を作成・実行
こちらについては、あまり詳細には触れません。以前の記事でまとめているため、詳細が気になる方はそちらをご確認いただければと思います。本記事ではポイントと実装例のソースコードを記載しておきます。
重要ポイント①: skへ渡す情報の整形
一番最初のユーザの入力と最終的な実行計画のベースをskへの入力に使用する
- 実行計画の修正を繰り返すループを行う仕組みを実装していますが、最終的に達成したいことは一番最初のユーザの入力を満たすことです。
- 今回の例では、「 AWS WAFってなに? 」でした
- そのため、以下のようにskへの入力を整形しています。
- JSON形式かどうかチェックしています。詳細はその他をご参照ください
import re
import json
# JSONフォーマットのチェック・変換を行う関数
def format_json(current_plan:str)->dict:
try:
plan_dict = json.loads(current_plan)
except:
# {任意の文字列}を抽出する。DOTALLで改行も含めて検索
pattern = r"{.*}"
plan_json = re.search(pattern, current_plan, re.DOTALL).group()
plan_dict = json.loads(plan_json)
return plan_dict
# 実行計画のベースを辞書型に変換
plan_base = format_json(executed_prompt["chat"][-2]["plan"])
# Semantic kernelに渡す情報
plan_base = f"ユーザの入力:{first_user_input}\n使用したい関数:{plan_base['best_plan']}\n実行計画ベース:{plan_base['description']}"
print(plan_base)
### 出力 ###
"""
ユーザの入力:AWS WAFってなに?
使用したい関数:['SearchFile', 'Answer']
実行計画ベース:AWS WAFについての情報を社内のサーバから検索し、回答を生成する
"""
重要ポイント②: guidance側で使用したスキル情報との整合性
再掲になりますが、今回はスキル情報をguidanceとskで連携するような構成となっています。
先ほど、guidance側では辞書型でスキルのメタデータを定義しました。
このメタデータに含まれる関数名(name)と説明(description)を何らかの方法で抽出する必要があります。今回は簡易的なpython関数として実装しています。
# guidance/Semantic Kernelで使用する関数(スキル)の定義
skills = [
{"name": "SearchFile", "description": "社内のサーバから必要なファイルを検索する関数"},
{"name": "SearchWeb", "description": "Web検索を行い必要な情報を収集する関数"},
{"name": "SearchDB", "description": "データベースから必要な情報を検索する関数"},
{"name": "Answer", "description": "ユーザの質問や最終的な出力を生成する関数"}
]
# スキルの定義を参照する関数
def get_skill_by_name(skills, name):
for skill in skills:
if skill["name"] == name:
return skill
return None
# SearchFileスキル
class SearchFile:
@sk_function(
### <ここでskillsの辞書からデータ取得> ###
name=get_skill_by_name(skills, "SearchFile")["name"],
description=get_skill_by_name(skills, "SearchFile")["description"],
### </ここでskillsの辞書からデータ取得> ###
input_description="前のスキルの実行結果。またはfirst_goal。",
)
...
実装例
Semantic Kernelの実装例
import json
import semantic_kernel as sk
from semantic_kernel.connectors.ai.open_ai import AzureChatCompletion
from semantic_kernel.skill_definition import sk_function, sk_function_context_parameter
from semantic_kernel import SKContext
from semantic_kernel.planning.basic_planner import BasicPlanner
# Semantic Kernel初期化
kernel = sk.Kernel()
deployment, api_key, endpoint = sk.azure_openai_settings_from_dot_env()
kernel.add_chat_service("gpt", AzureChatCompletion(deployment, endpoint, api_key))
# guidance/Semantic Kernelで使用する関数(スキル)の定義
skills = [
{"name": "SearchFile", "description": "社内のサーバから必要なファイルを検索する関数"},
{"name": "SearchWeb", "description": "Web検索を行い必要な情報を収集する関数"},
{"name": "SearchDB", "description": "データベースから必要な情報を検索する関数"},
{"name": "Answer", "description": "ユーザの質問や最終的な出力を生成する関数"}
]
# スキルの定義を参照する関数
def get_skill_by_name(skills, name):
for skill in skills:
if skill["name"] == name:
return skill
return None
# SearchFileスキル
class SearchFile:
skill_name = "SearchFile"
@sk_function(
name=get_skill_by_name(skills, skill_name)["name"],
description=get_skill_by_name(skills, skill_name)["description"],
input_description="前のスキルの実行結果。またはfirst_goal。",
)
@sk_function_context_parameter(
name="query",
description="検索クエリ",
)
def searchfile(self, context:SKContext) -> str:
# ファイル検索処理記述
print(f"前のスキルの実行結果:{context['input']}")
result = f"「{context['query']}」の社内ファイル検索結果"
return result
# SearchWebスキル
class SearchWeb:
skill_name = "SearchWeb"
@sk_function(
name=get_skill_by_name(skills, skill_name)["name"],
description=get_skill_by_name(skills, skill_name)["description"],
input_description="前のスキルの実行結果。またはfirst_goal。",
)
@sk_function_context_parameter(
name="query",
description="検索クエリ",
)
def searchweb(self, context:SKContext) -> str:
# Web検索処理記述
print(f"前のスキルの実行結果:{context['input']}")
result = f"「{context['query']}」のWeb検索結果"
return result
# SearchDBスキル
class SearchDB:
skill_name = "SearchDB"
@sk_function(
name=get_skill_by_name(skills, skill_name)["name"],
description=get_skill_by_name(skills, skill_name)["description"],
input_description="前のスキルの実行結果。またはfirst_goal。",
)
@sk_function_context_parameter(
name="sql",
description="SQL文",
)
def searchdb(self, context:SKContext) -> str:
# DB検索処理記述
print(f"前のスキルの実行結果:{context['input']}")
result = f"「{context['sql']}」のDB検索結果"
return result
# Answerスキル
class Answer:
skill_name = "Answer"
@sk_function(
name=get_skill_by_name(skills, skill_name)["name"],
description=get_skill_by_name(skills, skill_name)["description"],
input_description="前のスキルの実行結果。またはfirst_goal。",
)
@sk_function_context_parameter(
name="first_goal",
description="ユーザの最終的な目的。最初にユーザが入力した内容。",
)
def answer(self, context:SKContext) -> str:
# 回答生成処理 (実際の処理は省略していますが、私が使用している環境ではここにguidanceを使用しています。)
# 自由にPythonを記述できるのは嬉しいですよね。
return f"「{context['input']}」 を基に回答します。"
# スキルの読み込み
skills_dir = "tmp" # ※本来であればskのスキルはフォルダで管理します。
kernel.import_skill(SearchFile(), skill_name="SearchFileSkill")
kernel.import_skill(SearchWeb(), skill_name="SearchWebSkill")
kernel.import_skill(SearchDB(), skill_name="SearchDBSkill")
kernel.import_skill(Answer(), skill_name="AnswerSkill")
# プランナーを作成し、実行計画を生成
plan_base_str = """
ユーザの入力:AWSってなに?
使用する関数:['SearchDB', 'Answer']
実行計画ベース:データベースから情報を検索し、回答を生成します。
"""
print(f"### 実行計画のベース ###\n{plan_base_str}")
planner = BasicPlanner()
plan = await planner.create_plan_async(plan_base_str, kernel)
# 実行計画を表示
plan_dict = json.loads(plan.generated_plan["input"])
print("\n### 実行計画 ###")
print("サブタスク:")
for task in plan_dict['subtasks']:
print(f" - {task}")
# 実行計画を実行
print("\n### 結果 ###")
plan_result = await planner.execute_plan_async(plan, kernel)
print(plan_result)
本記事で訴求したいポイントは、guidanceによるユーザとの対話に基づいた実行計画のベースが固まっていることです。これにより、skでの実行計画作成の精度が向上すると考えています。
(現状、定量的なものを示せるわけではありませんが、、)
私の過去の記事にもありますが、semantickernelのプランナーで使用されているデフォルトのプロンプトではあまりうまく実行計画を作成できませんでした。そのため、自作のプロンプトを使用したりと工夫を施していました。
今回の方式を使用するとデフォルトのプロンプトでも精度良く実行計画を作成してくれます。
その他 (JSON形式へのフォーマットについて)
guidanceで実行計画のベースを作成する際、たまに以下のような出力をしてくることがあります。
JSONだけを出力してくれないパターンです。今回のプロンプトでは、{}のネストがない想定のため、{}で囲われた文字列を抽出し、JSON形式にすればOKです。

JSON形式だと{"name": {"a": "aaa", "b": "bbb"}}といった形式もありえますが、うまいこと処理すれば変換はできそうですよね。今回はプロンプト側でそのような形式がほとんど生成されないようにしているため、単純に{}を検索しています。
def format_json(current_plan:str)->dict:
try:
plan_dict = json.loads(current_plan)
except:
# {任意の文字列}を抽出する。DOTALLで改行も含めて検索
pattern = r"{.*}"
plan_json = re.search(pattern, current_plan, re.DOTALL).group()
plan_dict = json.loads(plan_json)
return plan_dict
まとめ
ユーザの自然言語による入力を起点に、様々な動的処理を行えるのは夢が広がりますよね。今後、色々試しながら改良して行きたいと思います。
次は、ユーザの入力に基づいて作成された実行計画をベースに、「こういった関数がこういう順序で実行されますよ」といったUIを動的に作成する仕組みを実装してみたいと思っています。
また、エージェントに装備されている機能が一目でわかるUIも作りたいですね。
他にも、「どのような機能をもったエージェントなのか?」といったことをエージェント自身に説明させる機能を実装してみたいです。(1日24時間って短いですよね![]() )
)