⓪サンプルコード
自分のアプリに組み込む時にはどんな感じになるか知りたかったため、ローカルでWebサーバを立て、Add your data (On your data?) をAPI経由で利用してみました。
システムプロンプト、過去の文脈などのモデルへの入力に関して、なにをどこに書くべきかあまり分かっていません。要調査です。
Webサーバのソースコード
import os
import time
import openai
import json
import requests
from flask import Flask, Response, request, jsonify
from dotenv import load_dotenv
load_dotenv()
app = Flask(__name__)
# 環境変数を読み込む
AZURE_SEARCH_SERVICE_URL=os.getenv("AZURE_SEARCH_SERVICE_URL")
AZURE_SEARCH_KEY=os.getenv("AZURE_SEARCH_KEY")
AZURE_SEARCH_INDEX=os.getenv("AZURE_SEARCH_INDEX")
AZURE_OPENAI_BASE= os.getenv("AZURE_OPENAI_BASE")
AZURE_OPENAI_MODEL=os.getenv("AZURE_OPENAI_MODEL")
AZURE_OPENAI_KEY=os.getenv("AZURE_OPENAI_KEY")
# パラメータ
TEMPERATURE = 0
MAX_TOKENS = 500
TOP_P = 0.95
STOP = None
STREAM = True
# システムメッセージを定義
SYSTEM_MESSAGES = "あなたは日本語のAIアシスタントです。知っている情報のみを使用できます。"
# リクエストボディとヘッダーを生成
def genrete_body_headers(user_input:str):
body = {
"temperature": TEMPERATURE,
"max_tokens": MAX_TOKENS,
"top_p": TOP_P,
"stop": STOP,
"stream": STREAM,
"dataSources": [
{
"type": "AzureCognitiveSearch",
"parameters": {
"endpoint": AZURE_SEARCH_SERVICE_URL,
"key": AZURE_SEARCH_KEY,
"indexName": AZURE_SEARCH_INDEX,
}
}
],
"messages": [
# {
# "role": "user",
# "content": "あなたは検索結果しか使えません。また、語尾は必ず「だよ♪」です。"
# },
# {
# "role": "assistant",
# "content": "承知だよ♪。"
# },
{
"role": "user",
"content": "日本語で回答して。\n" + user_input
}
]
}
headers = {
"Content-Type": "application/json",
"api-key": AZURE_OPENAI_KEY,
"chatgpt_url": f"{AZURE_OPENAI_BASE}openai/deployments/{AZURE_OPENAI_MODEL}/chat/completions?api-version=2023-03-15-preview",
"chatgpt_key": AZURE_OPENAI_KEY,
}
return body, headers
def search_request_not_stream(body, headers, endpoint):
response = requests.post(endpoint, headers=headers, json=body)
data = {
'status': response.status_code,
'content': response.content.decode('utf-8')
}
content = json.loads(data['content'])
print(content['choices'][0]['messages'][0])
return Response(json.dumps(data).replace("\n", "\\n"), status=data['status'])
def search_request(body, headers, endpoint):
response = {
"id": "",
"model": "",
"created": 0,
"object": "",
"choices": [{
"messages": []
}]
}
try:
res = requests.post(endpoint, json=body, headers=headers, stream=True)
deltaText = ""
# chunk_sizeバイトずつ読み込む
for line in res.iter_lines(chunk_size=10):
# ストリーム感を味わうために少しスリーブ
time.sleep(0.01)
if line:
# data:のプレフィックスを削除 & 文字列にデコードし、JSONに変換
lineJson = json.loads(line.lstrip(b'data:').decode('utf-8'))
# ロールを抽出 (tool or assistant)
role = lineJson["choices"][0]["messages"][0]["delta"].get("role")
# tool: 検索結果
if role == "tool":
response["choices"][0]["messages"].append(lineJson["choices"][0]["messages"][0]["delta"])
# assistant: ?
elif role == "assistant":
response["choices"][0]["messages"].append({
"role": "assistant",
"content": ""
})
# モデルの回答部分を抽出
else:
deltaText = lineJson["choices"][0]["messages"][0]["delta"]["content"]
if deltaText != "[DONE]":
response["choices"][0]["messages"][1]["content"] += deltaText
# DONE以外の場合、yieldで返す
yield deltaText
except Exception as e:
yield json.dumps({"error": str(e)}).replace("\n", "\\n") + "\n"
@app.route('/chat', methods=['POST'])
def chat():
# リクエストデータを取得
data = request.json
user_input = data["message"]
# ボディとヘッダーを生成
body, headers = genrete_body_headers(user_input)
endpoint = f"{AZURE_OPENAI_BASE}openai/deployments/{AZURE_OPENAI_MODEL}/extensions/chat/completions?api-version=2023-06-01-preview"
if STREAM:
return Response(search_request(body, headers, endpoint), mimetype='text/event-stream')
else:
return search_request_not_stream(body, headers, endpoint)
if __name__ == "__main__":
app.run(debug=True)
# Webサーバをローカルで起動
python app.py
# localhost:5000/chat宛てにcurlでPOSTする
curl -X POST -H "Content-Type:application/json" localhost:5000/chat -d '{"message":"~~って社内で使っていいの?"}'
※.envファイルとPythonパッケージが必要です。
AZURE_SEARCH_SERVICE_URL=
AZURE_SEARCH_KEY=
AZURE_SEARCH_INDEX=
AZURE_OPENAI_BASE=
AZURE_OPENAI_MODEL=
AZURE_OPENAI_KEY=
①前提条件とやること
Add your dataをAPI経由で利用する方法は大きく分けて2つです。
1. Azure OpenAIのCompletions extensionsに直接リクエストを投げる
dataSourceで指定したCognitive Searchに対して検索をかけに行き、取得できたデータを基にユーザに回答します。
curl -i -X POST YOUR_RESOURCE_NAME/openai/deployments/YOUR_DEPLOYMENT_NAME/extensions/chat/completions?api-version=2023-06-01-preview \
-H "Content-Type: application/json" \
-H "api-key: YOUR_API_KEY" \
-H "chatgpt_url: YOUR_RESOURCE_URL" \
-H "chatgpt_key: YOUR_API_KEY" \
-d \
'
{
"dataSources": [
{
"type": "AzureCognitiveSearch",
"parameters": {
"endpoint": "'YOUR_AZURE_COGNITIVE_SEARCH_ENDPOINT'",
"key": "'YOUR_AZURE_COGNITIVE_SEARCH_KEY'",
"indexName": "'YOUR_AZURE_COGNITIVE_SEARCH_INDEX_NAME'"
}
}
],
"messages": [
{
"role": "user",
"content": "What are the differences between Azure Machine Learning and Azure Cognitive Services?"
}
]
}
'
2. AppService上のWebアプリにリクエストを投げる
こちらは間接的に1を呼び出すイメージです。
Azure OpenAI Studioのプレイグラウンドからポチポチすると、Webアプリがデプロイされます。
このWebアプリには、/conversationというAPIエンドポイントが立っている状態となっているため、そのAPIエンドポイントを叩きに行く構成となります。
今回は「1. Cognitive Searchに直接リクエストを投げる」を取り扱います。
理由は、他のシステムに組み込む際、API経由で利用することになると思われるためです。
Webアプリでも/conersationでAPIエンドポイントが立っていますが、それを利用するためだけにWebアプリを立てるのは現実的ではないと思っています。
②リソース作成
以下の記事で詳細な手順をまとめてくださっています。本記事では詳細な作成方法については記載致しません。
Azure OpenAIの参照先となるCognitive Searchの準備
少し異なる点は「 Deploy to 」ボタンをクリックせず、データソースを追加するまでの作業でとどめておくことです。前述した通り、WebアプリをデプロイせずにAPI経由で利用したいためです。
以下は本記事におけるリソース作成の手順です。
- Azureポータル
- ストレージアカウント作成 → コンテナ追加
- Cognitive Searchを作成
- Azure OpenAI Studio
- プレイグラウンドからAdd a data sourceをクリック
- Blobストレージ・コンテナを選択
- Cognitive Searchを選択
- 作成されるインデックスの名前を入力
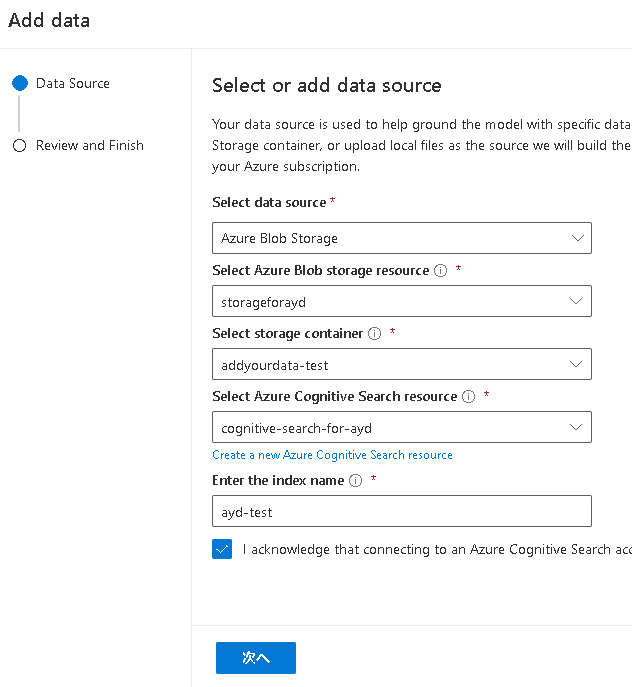
上記手順を実施すると、データソースが追加されていることをプレイグラウンド上から確認できます。
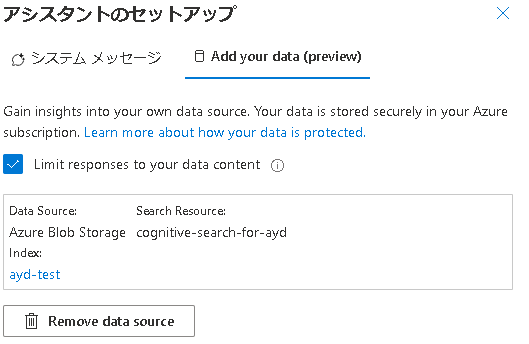
作成されたCognitive Searchのインデックスを確認
プレイグラウンドからインデックス名をクリックするとCognitive Searchの画面に飛ぶことができます。
Cognitive Searchの画面から以下2点を確認していきます。
- ①どのようなインデックスが作成されているか? → 「 検索エクスプローラー 」から確認
- ②どのようなインデックス設計となっているか? → 「 フィールド 」を確認
まず、「①どのようなインデックスが作成されているか」についてです。
今回は総務省が公表しているクラウドセキュリティのガイドライン(一部)をBlobストレージに置いています。
そのため、ガイドラインの情報をいい感じに5分割したものがインデックスとして作成されています。
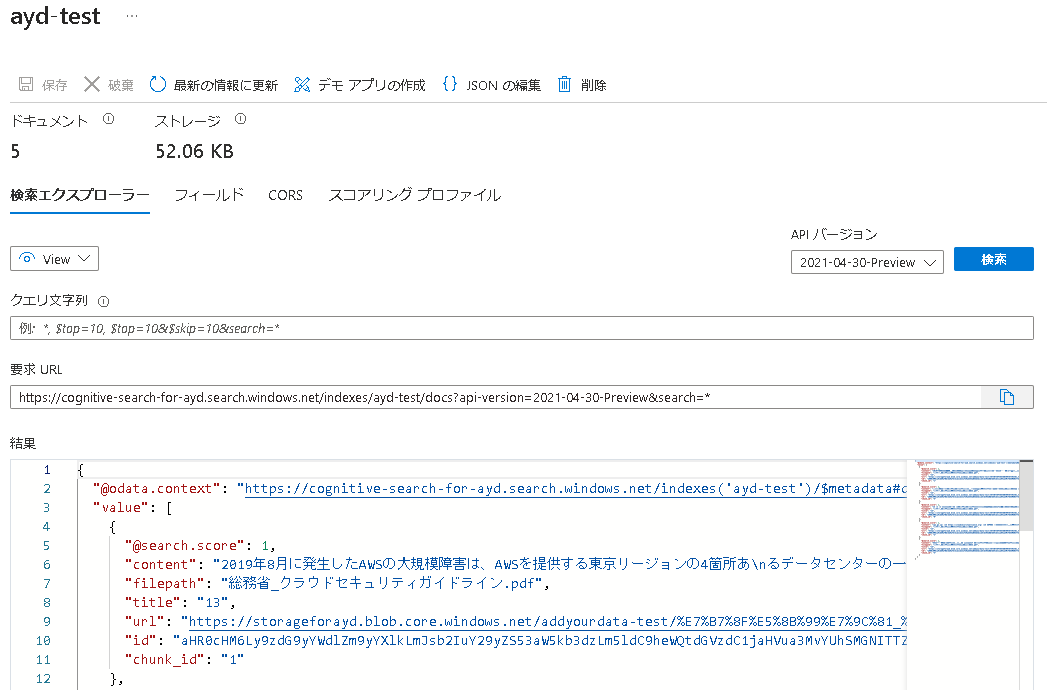
続いて、「②どのようなインデックス設計となっているか」についてです。
検索エクスプローラーの横にあるフィールドをクリックし、インデックス設計を見てみます。
ファイルの内容とタイトルで検索可能なようです。
(タイトルが何を基に作成されているのか不明なため要調査です。)
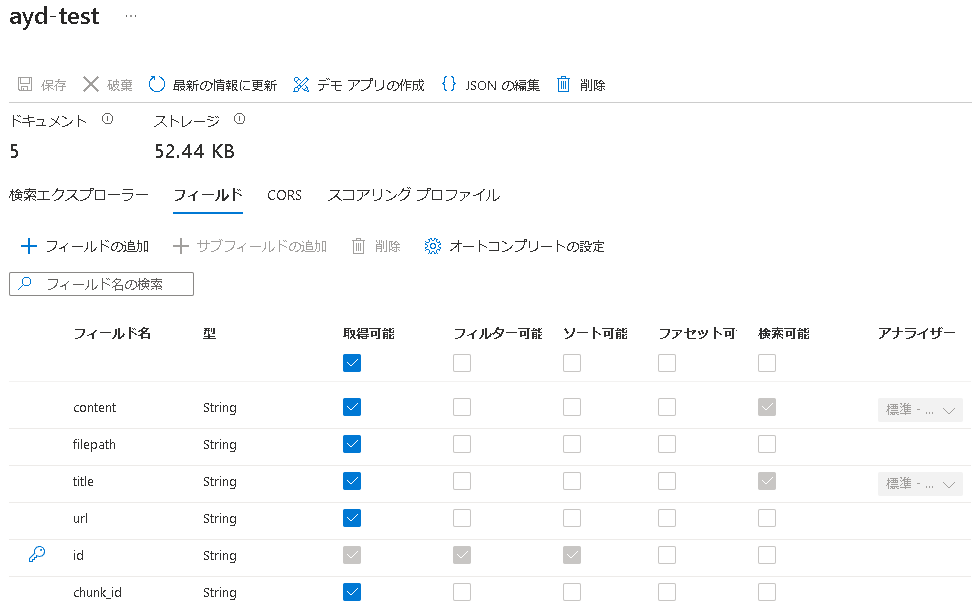
| フィールド名 | 値 | オプション |
|---|---|---|
| content | 分割後の文字列 | 取得/検索 |
| filepath | ファイル名 | 取得 |
| title | ?? (13となっていました) | 取得/検索 |
| url | BlobストレージのURL | 取得 |
| id | 一意のドキュメントID | 取得/フィルター/ソート |
| chunk_id | 分割の識別子 | 取得 |
③API経由でAdd your dataを利用する
今回のメイントピックです。公式ドキュメントは以下から参照できます。
実現したいこと
先ほど確認したインデックスをAzure OpenAIに参照させた上で、こちらの質問に答えてもらいます。
社内データ検索、ナレッジ検索などがユースケースに該当します。
curlでPOSTしてみる
Completions extensionsという拡張機能?のようなものが追加されているのでcurlでPOSTしてみます。
curl -i -X POST YOUR_RESOURCE_NAME/openai/deployments/YOUR_DEPLOYMENT_NAME/extensions/chat/completions?api-version=2023-06-01-preview \
-H "Content-Type: application/json" \
-H "api-key: YOUR_API_KEY" \
-H "chatgpt_url: YOUR_RESOURCE_URL" \
-H "chatgpt_key: YOUR_API_KEY" \
-d \
'
{
"dataSources": [
{
"type": "AzureCognitiveSearch",
"parameters": {
"endpoint": "'YOUR_AZURE_COGNITIVE_SEARCH_ENDPOINT'",
"key": "'YOUR_AZURE_COGNITIVE_SEARCH_KEY'",
"indexName": "'YOUR_AZURE_COGNITIVE_SEARCH_INDEX_NAME'"
}
}
],
"messages": [
{
"role": "user",
"content": "What are the differences between Azure Machine Learning and Azure Cognitive Services?"
}
]
}
'
上記の例を見てわかる通り、ヘッダーにchatgpt_url, chatgpt_keyを設定しないといけません。
(最初ここになにを指定するかわからなかったですが、以下のような指定でいけます。)
-
chatgpt_url
- 少しわからずらいですが、以下のような文字列となります。
- {AzureOpenAIリソースのエンドポイント} + /openai/deployments/{モデルデプロイ名} + /chat/completions?api-version=2023-03-15-preview
-
chatgpt_key
- Azure OpenAIのAPIキーです
# Python風に書くと以下のようなイメージです。
"chatgpt_url": f"{AZURE_OPENAI_BASE}openai/deployments/{AZURE_OPENAI_MODEL}/chat/completions?api-version=2023-03-15-preview",
"chatgpt_key": AZURE_OPENAI_KEY,
ドキュメントに記載のレスポンス例は以下のようになっていますが、実際には以下のレスポンスの後に、検索結果を基にした回答の文字列が返ってきます。(ストリーム有効化している場合)
ドキュメント記載のレスポンス例
{
"id": "12345678-1a2b-3c4e5f-a123-12345678abcd",
"model": "",
"created": 1684304924,
"object": "chat.completion",
"choices": [
{
"index": 0,
"messages": [
{
"role": "tool",
"content": "{\"citations\": [{\"content\": \"\\nCognitive Services are cloud-based artificial intelligence (AI) services...\", \"id\": null, \"title\": \"What is Cognitive Services\", \"filepath\": null, \"url\": null, \"metadata\": {\"chunking\": \"orignal document size=250. Scores=0.4314117431640625 and 1.72564697265625.Org Highlight count=4.\"}, \"chunk_id\": \"0\"}], \"intent\": \"[\\\"Learn about Azure Cognitive Services.\\\"]\"}",
"end_turn": false
},
{
"role": "assistant",
"content": " \nAzure Cognitive Services are cloud-based artificial intelligence (AI) services that help developers build cognitive intelligence into applications without having direct AI or data science skills or knowledge. [doc1]. Azure Machine Learning is a cloud service for accelerating and managing the machine learning project lifecycle. [doc1].",
"end_turn": true
}
]
}
]
}
検索結果を基にしたモデルの回答
...
# 1文字目
{
"id": "3a196ba6-14ce-4ae2-9365-e9ff75d5360a",
"model": "gpt-35-turbo",
"created": 1687443930,
"object": "chat.completion.chunk",
"choices": [
{
"index": 0,
"messages": [
{
"delta": {
"content": "I"
},
"index": 1,
"end_turn": false
}
],
"finish_reason": null
}
]
}
# 2文字目
{
"id": "3a196ba6-14ce-4ae2-9365-e9ff75d5360a",
"model": "gpt-35-turbo",
"created": 1687443930,
"object": "chat.completion.chunk",
"choices": [
{
"index": 0,
"messages": [
{
"delta": {
"content": "'m"
},
"index": 1,
"end_turn": false
}
],
"finish_reason": null
}
]
}
...
OpenAIのAPIを叩きに行っているので仕様は同じ、choices["messages"]["delta"]["content"]にストリームされた文字列が入っていることが分かります。
自分のアプリケーションに組み込む際はこれをうまいこと抽出していく形になるかと思います。
④課題・疑問
1.Add your data有効化時の情報のみが対象
今回、プレイグラウンドからBlobストレージをデータソースとして選択し、Add your dataを有効化しました。
Azure OpenAIが参照できる情報は、有効化を行ったタイミングでBlobストレージに格納されているファイル群が対象となっています。
そのため、ファイルをアップロードして参照できる情報を増やす、といったことはできません。別途実装が必要そうです。
- ①Cognitive SearchのインデクサーでBlobストレージのファイルを定期的にインデックス化
- ②Add your dataのデータソース選択時に、①で作成されたインデックスを指定
といった形になるのでしょうか?(Cognitive Search辺り弱いので要調査です。)
2.日本語の回答精度が悪い
ファイルの内容を英語として解析してしまう設定となっているため、日本語の精度が悪いです。
1,2については以下の記事がとても参考になるかと思います。
3.裏で動いているプロンプトがわからない?
指定したデータソースの情報を使って回答してもらうためにCompletions extentionsというAPIを叩きにいきます。
しかし、裏側でどのようなプロンプトが動いているのかわかりません。詳細な制御をしたいとなった場合、以下のようになるのでしょうか?
- システムメッセージを付与しつつリクエストを投げる
- ユーザメッセージに指示を追加する
ただ、上記のようなことを試してみましたが、期待通りの動作を実装できませんでした、、
私が把握しきれておらず別のパラメータとして設定する箇所があるのか、プロンプトチューニングが甘いのか、、要調査です。
4.元ファイルのURLを出してくれない時がある?
社内データ検索として使用する場合、回答に使用したファイルをダウンロードしたいケースがあるかと思います。プレイグラウンドからWebアプリとしてデプロイし何か入力を送ると、参照した文章は提示してくれますが、元ファイルのURLを提示してくれません。
Completions extentions APIの中身を見るとファイルURLがあるため、それを取得・表示すれば良さそうです。
Webアプリの方でもファイルURLを必ず表示させる方法はあるのでしょうか?
参考
API経由でAdd your dataを利用する方法についての情報がまとまっています。