導入
5/9にMetaからすごそうなモデルが発表されましたね、しかもOSS![]()
ということは、自分のPCでも動かせるのでは?ということで触ってみました。
進化・スピードが早すぎて、情報のキャッチアップ&咀嚼が圧倒的に間に合いません、、![]()
みなさんどうされていますか?こんなときこそAIの出番ですかね。
とか思いつつ寿命(睡眠時間)を削りつつ勉強しています。
ImageBindについて
Metaのメタバースへの本気度がうかがえるようなモデルですよね。

参考: https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai/
以下、GPT翻訳。
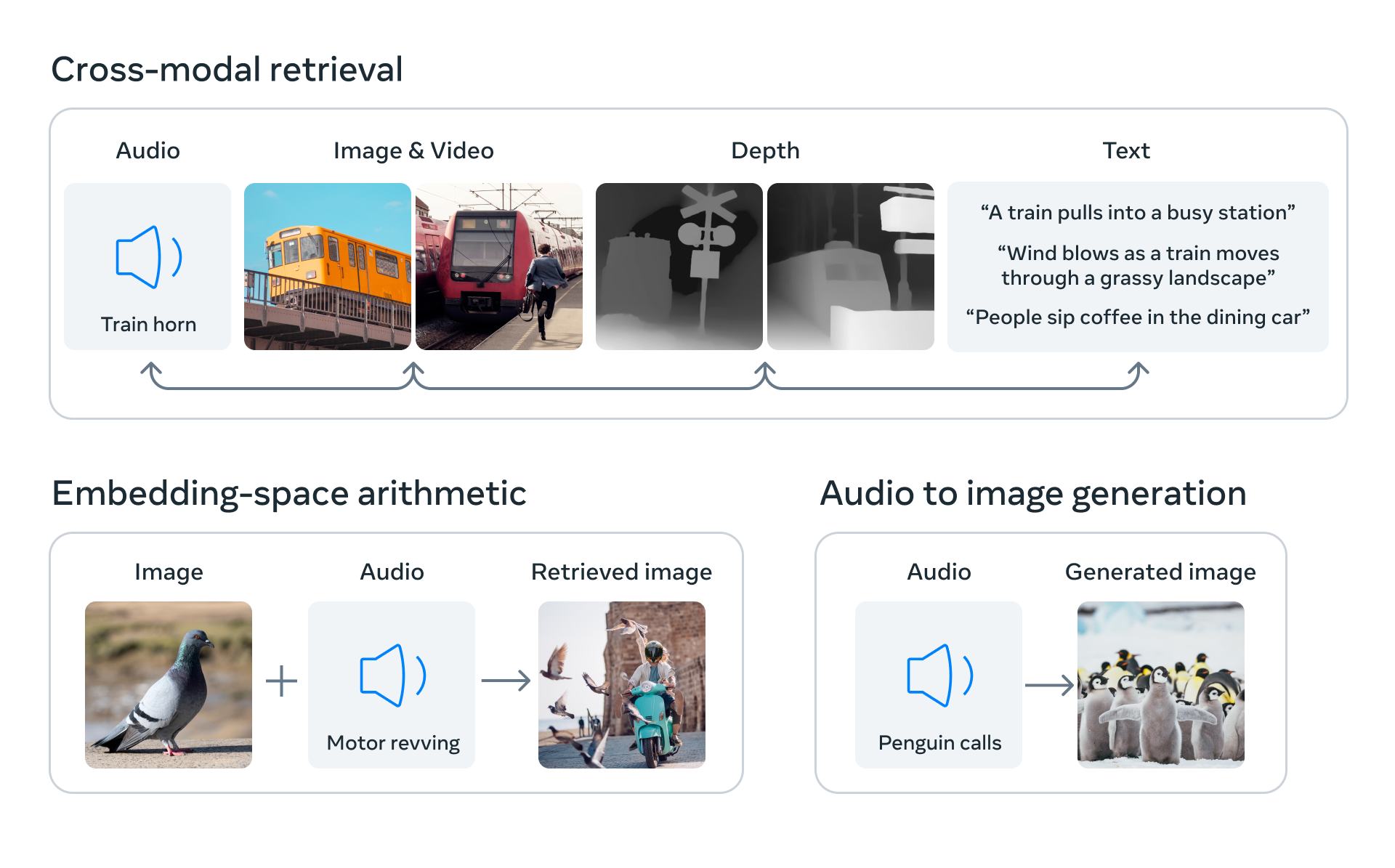
ImageBindは、人間が複数の感覚を使って情報を取り込む能力に近づくためのアプローチです。このモデルは、明示的な監督(生データの整理やラベリングの必要性)なしに、テキスト、画像/動画、音声だけでなく、深度情報、赤外線熱画像、動きや位置を計算するIMUといったセンサーの情報を統合的に学習します。モデルは、写真の中のオブジェクトとそれらの音、3Dの形状、温かさや冷たさ、そして動きとのつながりを持つ総合的な理解を機械に提供します。
ImageBindは異なるモダリティ(画像、テキスト、音声、深度情報、赤外線熱画像、IMU)の特徴表現を共通の空間に埋め込みます。
らしいです。「データの種類に関わらず、同じ空間上でベクトルとして表現できますよ。だからデータの種類が違っていても、比較したり類似性を見出せたりますよ」みたいなイメージでしょうか。
環境構築
- git cloneでソースコードをローカルに落とします
- 仮想環境を作って、jupyter notebookを起動します。
git clone https://github.com/facebookresearch/ImageBind.git && cd ImageBind
py -m venv pyenv-imagebind && .\pyenv-imagebind\Scripts\activate && pip install jupyter && jupyter notebook
- README.mdに従ってpip installするとエラーが起きました。pytorchの周りのバージョン起因ですね。
- github上では以下のようなrequirements.txtが用意されています。
- しかし、PyTorch関連はこちらからお使いの環境に合わせたものをinstallした方が良さそうです。
--extra-index-url https://download.pytorch.org/whl/cu113
torch==1.13
torchvision==0.14.0
torchaudio==0.13.0
pytorchvideo @ git+https://github.com/facebookresearch/pytorchvideo.git@28fe037d212663c6a24f373b94cc5d478c8c1a1d
timm==0.6.7
ftfy
regex
einops
fvcore
decord==0.6.0
マルチモーダルを試してみる
①READMEのソースコードを試す
※ Audio backend起因のエラーで音声は試せてません
- READMEのソースコードだけ見るとめちゃくちゃシンプルです。
- ①データ種別に応じてinputを作成
- テキスト:
ModalityType.TEXT - 画像:
ModalityType.VISION - 音声:
ModalityType.AUDIO
- テキスト:
- ②Embeddingsを生成
- データ種別が異なっていても同じ空間にベクトルして表現できます
- githubの例では犬・車・鳥に対して、テキスト・画像・音声が用意されていました。
- そのため、「犬ベクトル・車ベクトル・鳥ベクトル」が各データ種別に対して生成されます。
- ③生成したベクトルを使って類似度計算
- A → テキストから得た「犬ベクトル・車ベクトル・鳥ベクトル」
- B → 画像から得た「犬ベクトル・車ベクトル・鳥ベクトル」
- AとBを比較。(ベクトルが似ていると内積大→値が大きい=似ていると判断)
テキストの犬ベクトルと画像の犬ベクトルは、同じ犬を表すベクトル→つまり、似ている。
細かいことは置いておいて、直感的に以下のような結果になれば良さそうですよね![]()
| テキスト\画像 | 犬ベクトル | 車ベクトル | 鳥ベクトル |
|---|---|---|---|
| 犬ベクトル | 似てる(値大) | 違う | 違う |
| 車ベクトル | 違う | 似てる(値大) | 違う |
| 鳥ベクトル | 違う | 違う | 似てる(値大) |
見てみましょう。
(モデルは4.4GBくらいでした。ローカルの8GBGPUで動きました。)
import data
import torch
from models import imagebind_model
from models.imagebind_model import ModalityType
### モデルのロード ###
device = "cuda:0" if torch.cuda.is_available() else "cpu"
model = imagebind_model.imagebind_huge(pretrained=True)
model.eval()
model.to(device)
### モデルにinputする各データを「犬・車・鳥」の順で定義 ###
text_list=["A dog.", "A car", "A bird"] # テキスト
image_paths=[".assets/dog_image.jpg", ".assets/car_image.jpg", ".assets/bird_image.jpg"] # 画像
# audio_paths=[".assets/dog_audio.wav", ".assets/car_audio.wav", ".assets/bird_audio.wav"] # 音声
### ①各データをデータ種別に合わせて変換 ###
inputs = {
ModalityType.TEXT: data.load_and_transform_text(text_list, device),
ModalityType.VISION: data.load_and_transform_vision_data(image_paths, device),
# ModalityType.AUDIO: data.load_and_transform_audio_data(audio_paths, device),
}
### ②モデルにinputする ###
with torch.no_grad():
# 「犬ベクトル・車ベクトル・鳥ベクトル」の獲得
embeddings = model(inputs)
### ③類似度を計算する ###
print(
"Text x Vision: ",
torch.softmax(embeddings[ModalityType.TEXT] @ embeddings[ModalityType.VISION].T, dim=-1),
)
### Output ###
Vision x Text:
tensor([[9.9994e-01, 1.5806e-05, 4.3154e-05],
[4.9035e-03, 9.6986e-01, 2.5235e-02],
[2.1362e-05, 1.2545e-05, 9.9997e-01]], device='cuda:0')
以下、モデルから出力された結果です。(値は手動で適当に丸めています、、)
具体的には、テキストから得たベクトル群と画像から得たベクトル群の比較結果ですね。
| テキスト\画像 | 犬ベクトル | 車ベクトル | 鳥ベクトル |
|---|---|---|---|
| 犬ベクトル | 0.99 | 0.000015 | 0.000043 |
| 車ベクトル | 0.00049 | 0.97 | 0.02 |
| 鳥ベクトル | 0.000021 | 0.000012 | 0.99 |
おお、すごい。予想通りの結果すぎる。
githubの基データを見ると分かりますが、犬はめちゃくちゃ犬で、車はめちゃくちゃ車です。(笑)
ここまでの所要時間10分くらいでした![]()
すごい時代になりましたね。
②違うデータで試してみる
- 犬が犬すぎたので、少し別の画像で試してみます
- 以下の違い、(クラウドを触っている)人間なら誰でも分かりますよね。
- そうです、「上:AWS」「下:Azure」です。
- 流石にこれは厳しいでしょう、という意地悪で試してみました

- しかもテキストを複雑に。
- 流石にこれは厳しいでしょう、という意地悪で試してみました
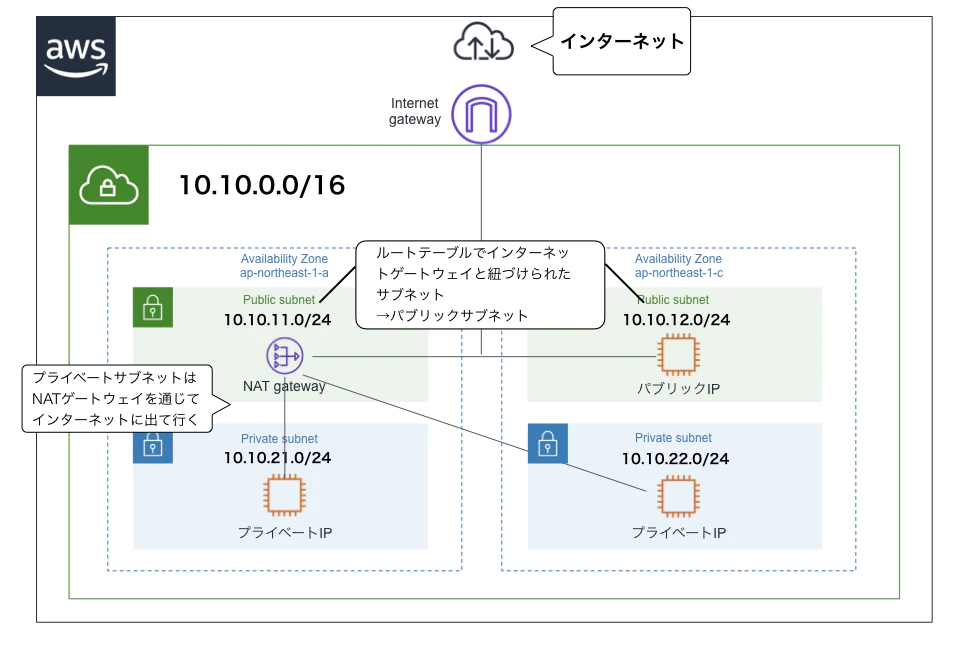
参考: https://qiita.com/g_ayushi/items/0e0f34d19813b8fdc2b8
上記画像のペアになるテキストとして、「可用性を考慮し、複数のAZにリソースを配置したよ」といった内容を与えます。
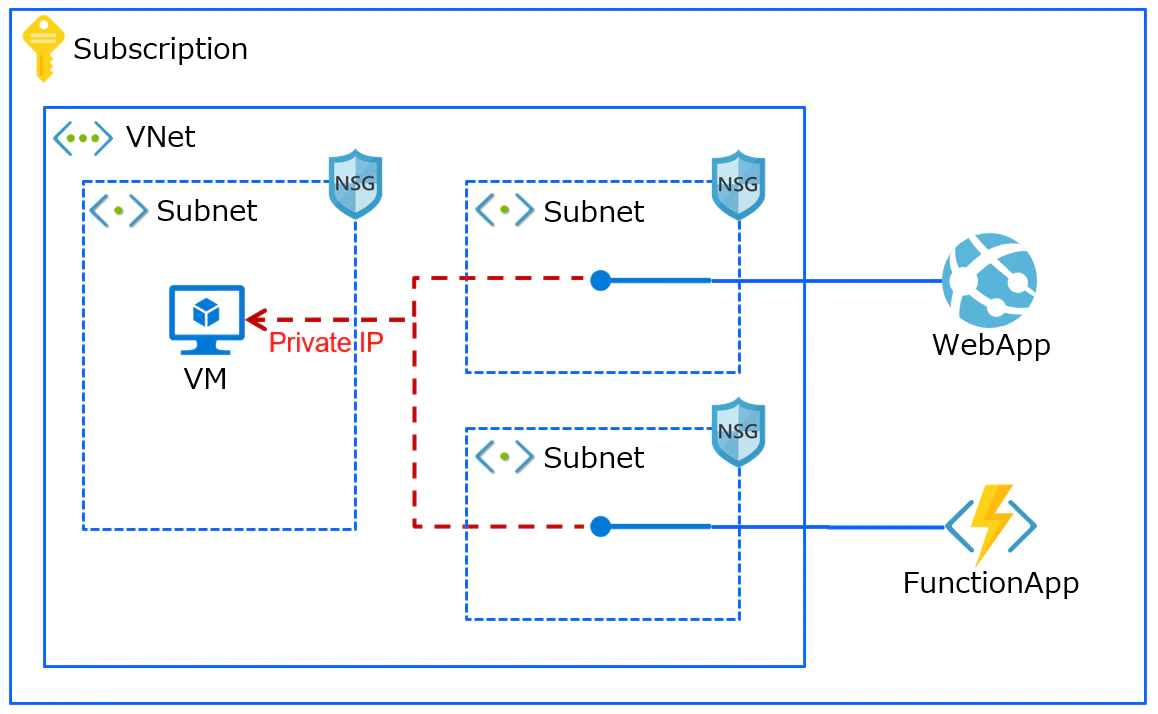
参考: https://qiita.com/VA_nakatsu/items/d9ed92188b249384e981
上記画像のペアになるテキストとして、「Webアプリは仮想マシンとの接続性を持つよ」といった内容を与えます。
text_list=[
# 可用性を考慮し、複数のAZにリソースを配置したよ (AWSの構成をぼかして表現)
"We have considered availability and placed subnets and servers in multiple availability zones.",
# Webアプリは仮想マシンとの接続性を持つよ (Azureの構成をぼかして表現)
"A web application can connect to virtual machines deployed in subnets."
]
image_paths=[
".assets/AWS.jpg",
".assets/Azure.jpg"
]
with torch.no_grad():
embeddings = model(inputs)
print(
"Text x Vision: ",
torch.softmax(embeddings[ModalityType.TEXT] @ embeddings[ModalityType.VISION].T, dim=-1),
)
### OutPut ###
Text x Vision:
tensor([[5.7317e-03, 9.9427e-01],
[4.3503e-04, 9.9956e-01]], device='cuda:0')
どちらのテキストもAzureの構成図に反応するという結果になりましたね![]()
| テキスト\画像 | AWSベクトル | Azureベクトル |
|---|---|---|
| AWSベクトル | 0.0057 | 0.994 |
| Azureベクトル | 0.0004 | 0.999 |
「~~で○○な構成」という文を基に、構成図を画像として出力できたらすごいなあと思っていましたが、今後に期待ですね。
③違うデータで試してみる (Text変更)
ちょっと文章を変えて試してみました。理由は以下の通りです。
(モデル&ソースコードを理解してないので的外れかもです。)
- 文章が長いと無理なのかも?
- 曖昧な表現はくみ取れないのかも?
シンプルに「AWSですよ。Azureですよ。」としてみました。
(先にこれやれよって話ですよね、性格の悪さが出ました![]() )
)
text_list=[
"AWS Architecuture.",
"Azure Architecuture."
]
image_paths=[
".assets/AWS.jpg",
".assets/Azure.jpg"
]
以下結果です。すごいですね
(なんでこうなるのかまだ理解できていないので、詳しい方いれば教えてください、、)
| テキスト\画像 | AWSベクトル | Azureベクトル |
|---|---|---|
| AWSベクトル | 0.99 | 0.0045 |
| Azureベクトル | 0.085 | 0.91 |
まとめ
マルチモーダルによってめちゃくちゃ色々なアプリ・サービス登場しそうですね。動向追っていきます。
今後は「色々なデータで試してみる、デコードしてみる」ってことをしていくので、ある程度進んだら記事にまとめます。