まえがき
前回に引き続き、Prompt flowを触ってみました。
今回は以下の便利機能についてまとめます。外部ツールの組み込みでは、ベクトル類似検索を一から実装してみました。
- マネージドオンラインエンドポイント
- Variant
- 評価
- 外部ツールの組み込み
「こんな機能もあるよ!」など、他にも便利機能ありましたらご連絡いただければ幸いです。評価についてはもっと深掘りしたいです。
また、以降の章では基本的に前回作成したものを使用します。
前回は簡易的に、「ユーザの入力からFunction calling用の関数定義のJSONを出力する」というタスクをPrompt flowにて実装しました。

外部ツールの組み込み(ベクトル類似検索の実装)については、以下のようなタスクを扱います。

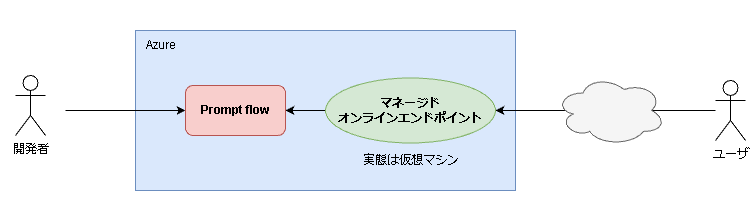
①マネージドオンラインエンドポイント
作成したフローを外部から呼び出せるようにするための機能です。
イメージ
- Azureポータルで見えているprompt flowは開発者用
- マネージドオンラインエンドポイントを作成することで、外部からユーザが利用可能に
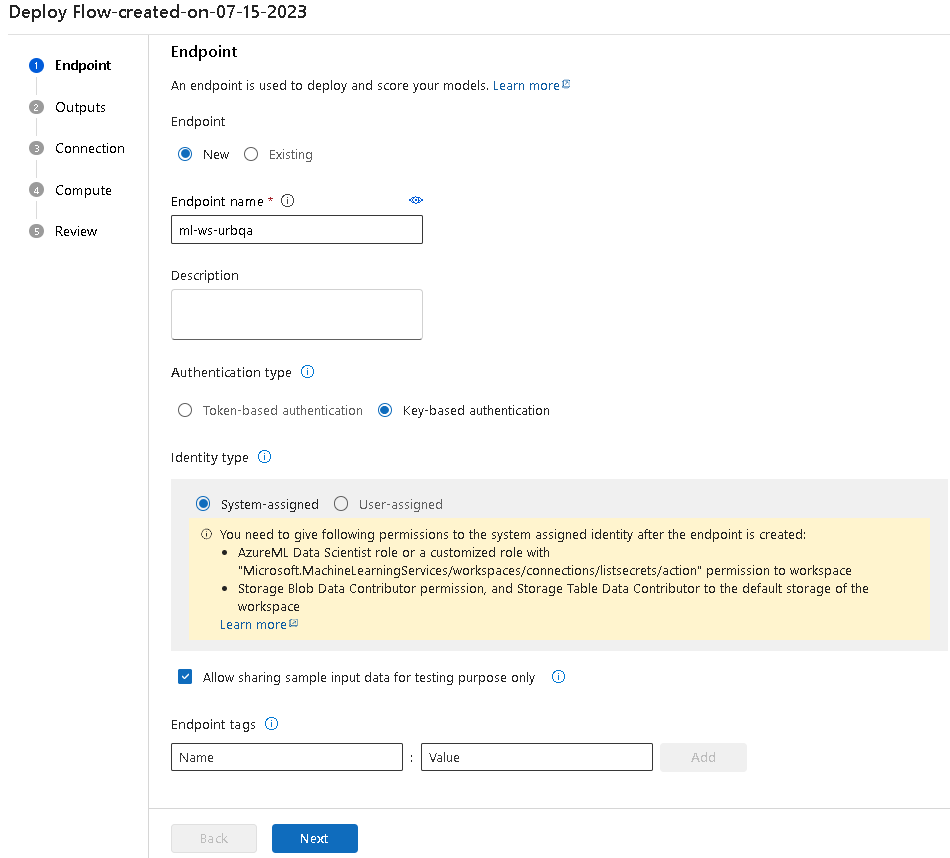
デプロイ
画面右上にあるDeployをクリックします。

認証方式とマネージドIDの種類を選択します。
ここでは、キー認証・システム割り当てを選択しています。
認証の参考ページ、マネージドIDの参考ページ
出力を選択します。今回はフローの最終的な出力を選択します。

Azure OpenAIとの接続情報を選択します。

仮想マシンのサイズとインスタンス数を選択します。

確認画面で詳細を確認した後、Deployをクリックします。

Endpointsをクリックすることで、詳細を確認できます。

テスト実行
Testタブに移動します。

Testをクリックすると、RBACのエラーが発生します。先ほど作成したマネージドIDになにもロールを割り当てていないためです。


Azureポータルからロールを割り当てます。Azure Machine Learningのページを開き、
アクセス制御→ロールの割り当ての追加と進みます。

AzureML データ科学者を選択し、次へをクリックします。

マネージドIDを選択し、メンバーを選択するをクリックします。

マネージドIDの欄でAzure Machine Learning workspaceを選択します。

レビューと割り当てをクリックし、ロール割り当てを行います。
再度テストを実行すると以下のような結果となりました。
「入力:Slackで任意のメッセージを送りたい」に対して期待通りのJSONが得られました。

少し入力を変えて試してみました。「入力:ユーザの入力を基にWeb検索をしたい」として結果を見てみます。イイ感じですね。

APIとして呼び出す
以下のようなリクエストを投げることで、外部からPrompt flowで作成したフローを実行できます。
これで好きにプログラムに組みこむことができる状態になりました。/scoreにPOSTするみたいですね。
また、リクエストボディには先ほど作成したフローのインプットに該当するuser_inputが必要となります。(フローのinputsの設定によって変わります。)
curl -X 'POST' \
'https://ws-test-bxvte.japaneast.inference.ml.azure.com/score' \
-H 'accept: application/json' \
-H 'Authorization: Bearer <キー>' \
-H 'Content-Type: application/json' \
-d '{
"user_input": "I want to send a message in Slack."
}'
②Variant
複数のプロンプトを並列に実行し、結果の比較や評価を行うことができます。「プロンプトエンジニアリングの強い味方」といった感じでしょうか。
LLMの特性上、プロンプトを一行変えたり、内容は全く同じでも文章の構造が少し変わったりするだけでガラッと出力が変わってしまいます。(微調整が本当にしんどいです。)
そんな時に複数のプロンプトを並列に試して評価を行えるのは嬉しいですよね。
プロンプトの複製
Show variantsをクリックします。

現在はvariant_0でこちらがデフォルトになっていることを確認できます。Cloneをクリックしてvariantを追加します。クリックすると、2variantsになったことが確認できます。

また、画面右側のフローの図をみるとプロンプトが複数になっています。(2枚重なっています。)
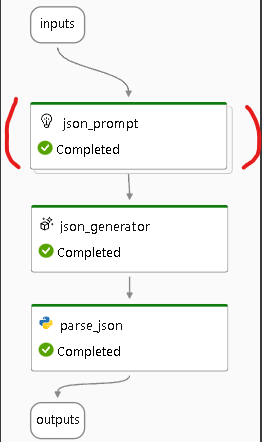
プロンプトの編集
追加したvariant_1に該当するプロンプトを編集します。画面左側からvariant_1に該当するプロンプトを探し、Diff modeを有効化した上で編集します
今回は、デフォルトプロンプトから以下3点を変更してみました。
- システムメッセージを単純化
- one-shot部分を削除
- 出力条件を削除
variant_0は、前回イイ感じにFunction calling用のJSONを出力してくれるようにカスタマイズしています。
そのため、結果としては以下の表のようになることが期待されます。
| variant_0 | variant_1 |
|---|---|
| 期待通りのJSONを出力 | 要件を満たしていないJSONを出力 |

Runボタンをクリックして実行してみます。

variantが複数ある場合、以下のような画面が出てきます。
全てのvariantsを実行するか、デフォルトのvariantのみ実行するか聞かれています。今回は全てのvariantsを実行してほしいので何も変更せずSubmitをクリックします。

各variantの結果を確認します。以下のような結果となりました。
予想通りvariant_0はイイ感じのJSONを、variant_1はダメダメなJSONを出力しています。
{
"description": "Slackに任意のメッセージを送信する",
"name": "send_slack_message",
"parameters": {
"properties": {
"channel": {
"description": "送信するチャンネル名",
"type": "string"
},
"message": {
"description": "送信するメッセージの内容",
"type": "string"
}
},
"required": [
"message",
"channel"
],
"type": "object"
}
}
{
"text": "Slackに任意のメッセージを送りたい。"
}
今回は既に動作確認済みのプロンプトを用いていますが、実際には様々なプロンプトを微調整しながら開発することになるかと思います。そういった場合にvariantが活躍しますね。
また、今回は簡易的にoutputを見て各variantの結果を確認しましたが、Keyが足りていないJSONはエラーにするといったフローを組み込んだりすれば、そもそもエラーになるのでチェックしやすくなるなと思いました。
工夫次第でvariantの使い方の幅が広がりそうですよね。
③評価
実行
作成したフローを定量的に評価できます。また、variantごとに評価を実行することが可能です。
今回は以下のようなフローに対して評価を行っていきます。variantは先ほど作成したものを使用します。

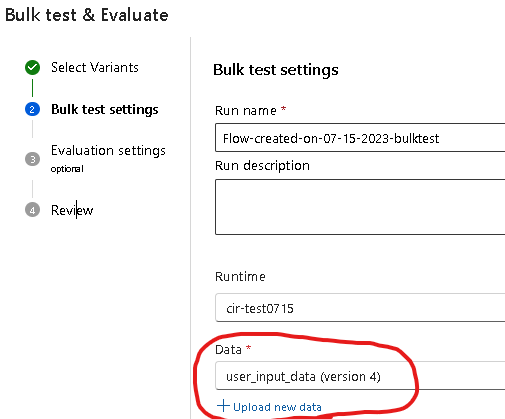
画面右上のBulk testをクリックします。

全てのvariantを評価したいので、デフォルトのまま変更せずにNextをクリックします。

次にテストの設定を行います。私の環境ではデータアップロード済みのため実際の表示と異なる可能性があります。Upload new dataをクリックし、テストに使用するデータのアップロード画面に移動します。
アップロードする前にデータを作成します。今回はjsonl形式でデータを定義しました。
データの中身は以下の通りです。
| ID | user_input | GroundTruth |
|---|---|---|
| データID | ユーザの入力 | 期待する答え |
{"ID": 1, "user_input": "Slackで任意のメッセージを送りたい", "GroundTruth": "{\"description\": \"Slackに任意のメッセージを送信する\",\"name\": \"send_slack_message\",\"parameters\": {\"properties\": {\"channel\": {\"description\": \"送信するチャンネル名\",\"type\": \"string\"},\"message\": {\"description\": \"送信するメッセージの内容\",\"type\": \"string\"}},\"required\": [\"message\",\"channel\"],\"type\": \"object\"}}"}
{"ID": 2, "user_input": "明日の天気を知りたい", "GroundTruth": "{\"description\": \"明日の天気を知る\",\"name\": \"get_weather\",\"parameters\": {\"properties\": {\"city\": {\"description\": \"天気を知りたい都市名\",\"type\": \"string\"}},\"required\": [\"city\"],\"type\": \"object\"}}"}
{"ID": 3, "user_input": "ある企業の現在の株価を知りたい", "GroundTruth": "{\"description\": \"企業の株価を知る\",\"name\": \"get_stock_price\",\"parameters\": {\"properties\": {\"company\": {\"description\": \"株価を知りたい企業名\",\"type\": \"string\"}},\"required\": [\"company\"],\"type\": \"object\"}}"}
上記のデータを定義したファイルをアップロードします。

データのアップロード後、データの先頭から数十件表示されます。(今回は3件のみですが)

評価方法を設定します。様々な評価方法がありますが、今回はQnA GPT Similarity Evaluationを選択しました。今回のユースケースにおいて適切な評価方法ではないと思います、、(要調査)
評価に使用する値を設定します。先ほどアップロードしたデータの中から適切な値をquestion, ground_truth, answerにマッピングしています。
| question | ground_truth | answer |
|---|---|---|
| フローへの入力 | 期待する答え | フローの出力 |

上記設定を行った後、評価を実行します。
評価結果の確認
Bulk testの実行後、結果を確認します。
Jobsへ移動し、該当のExperimentをクリックします。
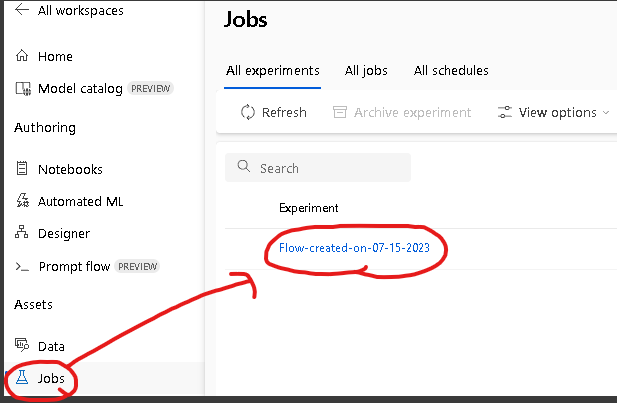
Bulk testのRunに該当するものをクリックします。

Bulk testが各variantごとに評価が実行されていることがわかります。使用トークン数なども表示されていますね。
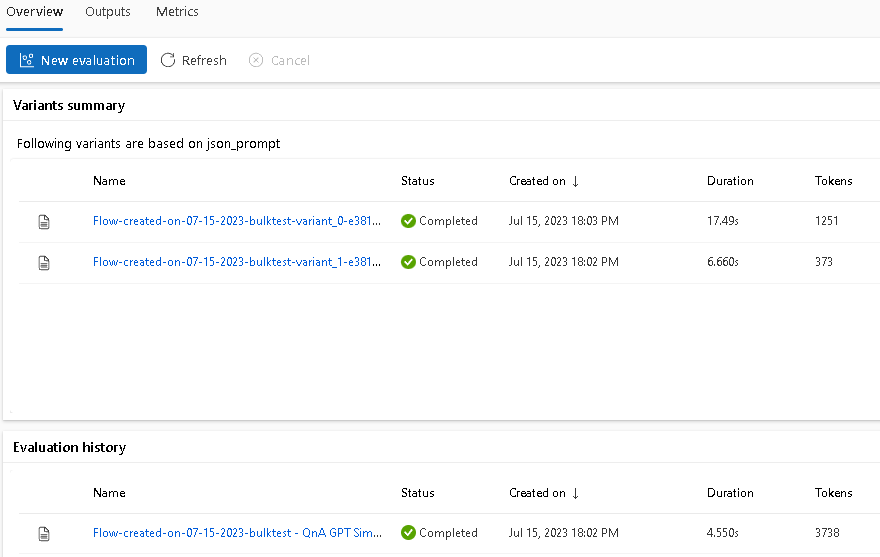
Evaluation historyのNameをクリックし、結果の詳細を確認してみます。

Prompt flowの画面に遷移します。評価のフローはPrompt flowで実装されているみたいですね。(解読すれば勉強になりそう)
今回選択した評価方法では、「フローへの入力から得られた出力がGroundTruthとどのくらい類似しているか?」というタスクをGPTに解かせているみたいです。Few-shotされているデータを見ると今回のケースではあまりうまく動作しなさそうですが、一旦無視して進めましょう。
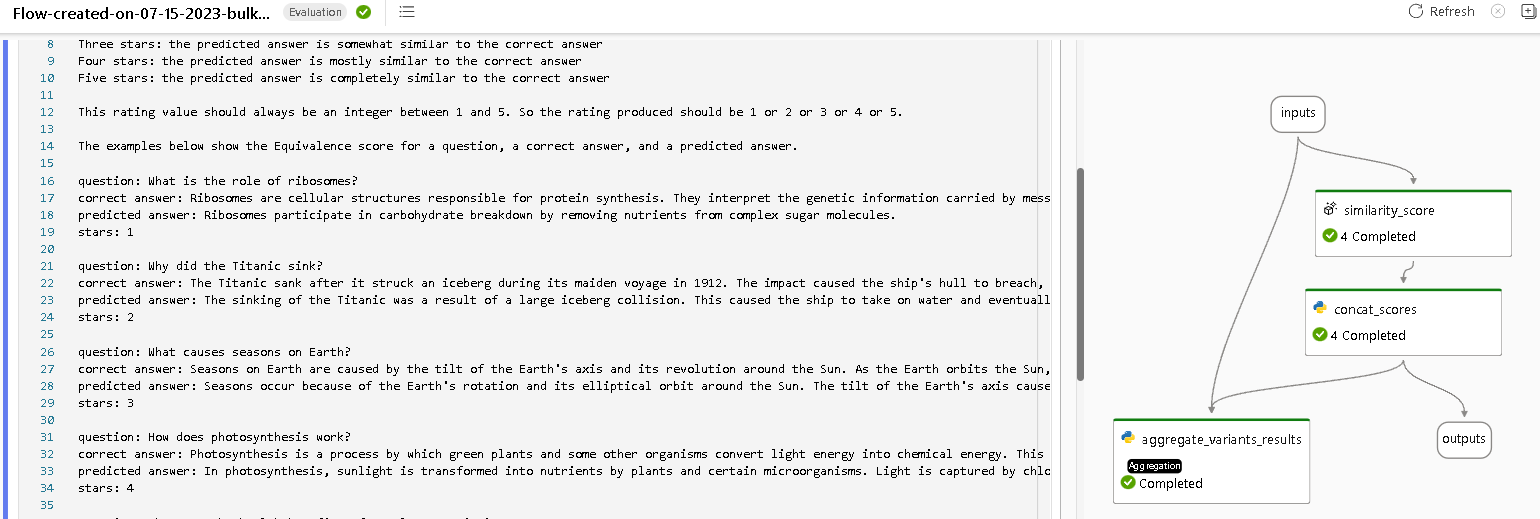
では、評価結果を確認してみます。少しわかりにくいですが、画面上部のView outputsボタンをクリックしてフローのoutputを表示します。

Metircsタブに移動すると、2つのメトリックがあります。

どんな指標なのかはPrompt flowのコンポーネント群の詳細を見ることで確認できました。
上段は、「 各データに対して5段階で類似度を計算し、平均を算出した結果 」が表示されています。
下段は、「 全データの内、類似度が3を超えているデータの割合 」が表示されています。
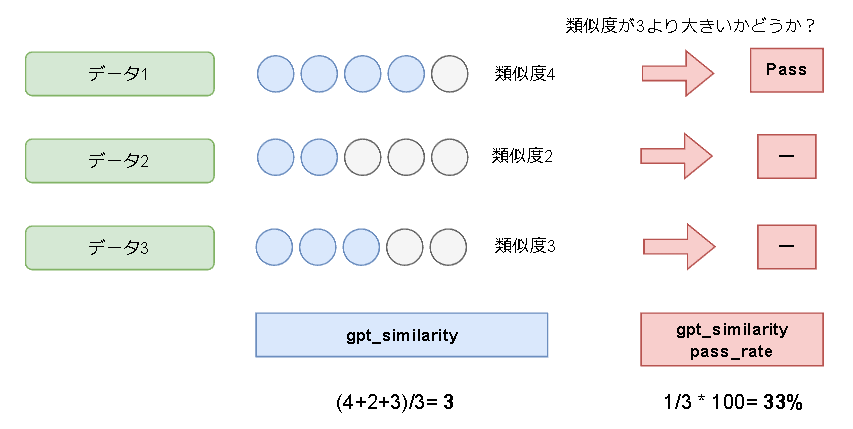
今回の結果をまとめると以下のようになっています。
- 類似度平均はvariant_0の方が高い。
- pass_rateはvariant_0とvariant_1共に33%
評価に使っているプロンプトがあまり今回のケースには適していないので数値は全く参考になりませんが、評価の実行→結果の確認の流れを体験できました。
④外部ツールの組み込み
Prompt flowは外部API連携やCongnitive Searchとのデータ連携などを行えます。
画面上の操作で言うと、More toolsをクリックすることで連携可能なツール群を確認可能です。

今回扱うタスク
今回はCognitive Searchと連携させ、Retrieval Augmented Generation(情報検索×生成タスク)を実装してみます。Congnitive SearchとAzure OpenAIを用いてベクトル類似検索を行い、検索結果を基にユーザの質問に回答する仕組みを作ります。
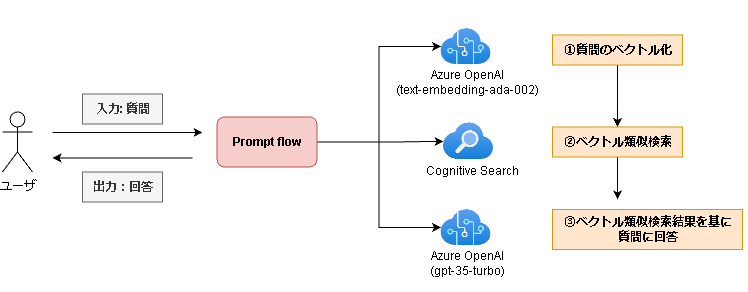
Prompt flowで上記の処理を実装すると以下のようなフローになります。
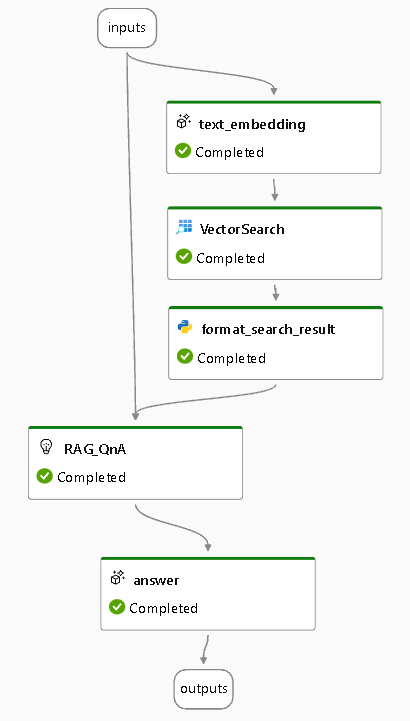
必要なものは以下の通りです。(作成済みのものとして話が進みます)
- Azure OpenAI
- text-embedding-ada-002
- gpt-35-turbo
- Cognitive Search
- ベクトルを含むインデックス
Azure OpenAIのリソースを作成し、モデルをデプロイした結果

Cognitive Searchのインデックスフィールド

サンプルが用意されている
今回扱うタスクについてですが、サンプルのPrompt flowが用意されています。(勉強目的なので今回はサンプルは使用しません。)
サンプルの確認方法を紹介します。
Createをクリックします。

すると画面下部にCreatefrom galleryという欄があります。ここにサンプル集があります。
また、Evaluationタブに移動すると評価用のPrompt flowも確認できます。(実装の勉強になりそうなので後で覗く)

以降では、サンプルを使わずに一から実装していきます。
Prompt flowと外部リソースの接続
Prompt flow内で外部リソースを扱うためにはConnection設定が必要です。Azure OpenAI/Cognitive Searchと繋いでおきます。
Flow一覧の画面から、Connectionsタブに移動し、Createをクリックします。
Azure OpenAIとの接続
APIキーとエンドポイントが必要です。

Cognitive Searchとの接続
APIキーとエンドポイントが必要です。

接続設定後、Connectionsタブを確認すると以下のように2リソースとの接続情報が確認できます。
ベクトル類似検索
まずはベクトル類似検索を行うために必要なコンポーネントを用意します。
コンポーネントと呼ぶのが正しいか分かりませんが、必要なものをPrompt flow上に作成しておきます。
必要なものは以下の通りです。
-
LLM
- ユーザの入力をベクトルに変換する用
-
Vector DB Lookup
- Cognitive Searchインデックス検索用
新規にStandard flowを作成した後、LLMをクリックします。

すると、画面左側のコンポーネントの定義一覧にLLMが追加されます。

こちらを編集していきます。
ペンマークをクリックして名前を変更、Apiをembeddingに変更、inputをフローの入力に変更します。
(他のコンポーネントだとinputが選択式でしたが、今回手入力する必要がありました![]() )
)

変更後、画面右側のフローが可視化されている領域を確認してみます。inputs(=ユーザの入力)が先ほど追加したLLMとつながっているのでよさそうです。

(hello_promptとecho_my_promptは必要ないので削除します。ゴミ箱マークで削除可能です。)
続いて、More toolsをクリックし、Vector DB Lookupを追加します。

追加されたコンポーネントの定義を編集します。(名前の変更は任意です)
以下、変更したパラメータです。Cognitive Searchの設定に合わせる形で各パラメータを設定していくイメージです。
| パラメータ名 | 概要 | 値 |
|---|---|---|
| connection | Cognitive Searchとの接続情報 | cognitive-search-test |
| index_name | Cognitive Searchのインデックス名 | index-for-myllmapp-v2 |
| text_field | 文字列に該当するフィールド | content |
| vector_filed | ベクトルに該当するフィールド | contentVector |
| vector | 検索に用いるベクトル | ${text_embedding.output} |

パラメータvectorにtext_embeddingの出力を指定しているため、フローの図を見ると以下のようになっています。(一度実行したためCompletedとなっていますが、ステータス表示は無視で大丈夫です。)
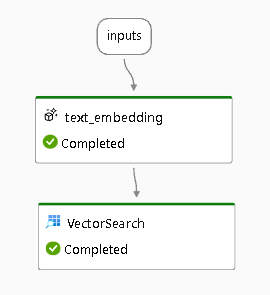
Outputsがフローに繋がっていないため、Outputsを編集してつなぎます。
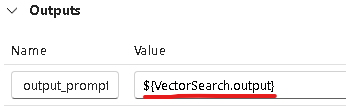
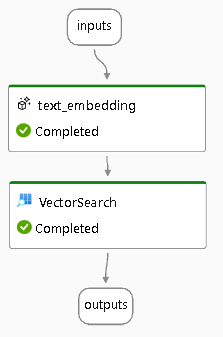
OutpusにVectorSearchの出力を指定したため、フローを見ると以下のようになっています。

ここまでで一度テスト実行します。Runtimeが設定されていることを確認し、Runをクリックします。

無事に実行が終わると、画面右側のフローに実行ステータスが追加されます。
今回はテスト用に以下のような画像を用いて、Cognitive Searchでインデックス化するために必要な情報を作成・保持しています。具体的には、以下の情報が含まれます。
- content: 画像から抽出した文字列
- contentVector: 文字列をベクトル化したもの

Prompt flowへの入力を「責任あるAIってなに?」として実行し、最終的な出力を確認すると以下のようになっていました。
score, text, vectorが含まれているみたいですね。ファイル名に該当する値はありません。
検索という意味ではよさそうですが、プロンプトには情報のソース(ファイル名)を埋め込みたいですよね、、。ファイル名も出力できるようにしてほしいところです。
{
"output": [
{
"score": 0.91211456,
"text": "責任ある AlMicrosoft は、人を第一に考える原則に基づいて、AI の発展に取り組んでいます...。",
"vector": [0.004075101, -0.0278097223, ...]
},
{
@search_scoreが2番目に高いやつ
},
{
@search_scoreが3番目に高いやつ
}
]
}
ベクトル類似検索の結果を整形
ベクトル類似検索の結果を基にプロンプトを作成するためのコンポーネントを追加します。
必要なコンポーネントは以下の通りです。
-
Python
- ベクトル類似検索の結果から必要なデータを抽出
- 各データを文字列として結合
-
Prompt
- 検索結果を受け取る ( = Pythonの出力を受け取る)
- 検索結果を基に回答させるためのプロンプトを記述
PythonとPromptをクリックしてコンポーネントを追加します。

Pythonコンポーネントを編集していきます。
名前を変更、Codeを変更、Validate and parse inputをクリック、inputsのValueを変更します。
配置するソースコード
from promptflow import tool
from embeddingstore.core.contracts import SearchResultEntity
@tool
def format_search_result(search_result: list[dict], source_field:str) -> str:
result_str = ""
for result in search_result:
filename, content = _extract_doc_info(result, source_field)
result_str += f"filename:\n{filename}\n\ncontent:\n{content}\n\n###\n\n"
return result_str
def _extract_doc_info(doc:dict, source_field:str):
entity = SearchResultEntity.from_dict(doc)
filename = entity.original_entity[source_field] # ファイル名に該当するフィールドの値を抽出
content = doc["text"]
return filename, content

先ほども触れましたが、Prompt flowからベクトル検索した結果の中にファイル名に該当する値が含まれていません。
RAGでは情報のソースを含めつつ回答させることになると思いますので、ファイル名を取得してくるための小細工をしています。(_extract_doc_info())
私の環境で作成しているインデックスではファイル名に該当するフィールド名はfilenameなので、それを引数で渡すようにしてみました。
OutputsをこのPython関数の出力に変更します。

ここまででテスト実行してみます。ステータスは全てCompletedなのでよさそうです。

最終的な出力も確認してみます。画面上部にあるView outputsをクリックします。(もっとわかりやすいボタンや表示にしてほしいところ、、。)

今回確認するのは、output_promptです。filenameとcontentが含まれているのでよさそうですね。
余談ですが、この画面からログや実行時間など様々な情報を確認可能です。

プロンプトを作成
Python関数にて、ベクトル検索の結果を整形できました。整形後の文字列をプロンプトに埋め込んでいきます。
現在の状態を確認しておくと、以下のようなフローになっているかと思います。プロンプトが浮いています。

浮いているコンポーネントを関連づけます。具体的には、以下のような設定を入れ込みます。
-
入力 : 2つ
- inputs ( =ユーザの最初の入力)
- format_search_resultの出力 ( =ベクトル検索結果の整形後文字列)
-
出力: 1つ
- outputsに向ける
上記の設定を終えるとフローは以下のようになります。(今更ですが、フローの可視化めちゃくちゃいいですよね。設計図代わり。)

まず、入力部分の設定です。Promptコンポーネントの定義を編集します。今回はテストなので適当なプロンプトを用います。
名前を変更、Promptを編集、Validate and parse inputボタンをクリック、InputsのValueを編集します。

プロンプト
system:
- あなたは検索結果を基にユーザの質問に回答するアシスタントです
- ユーザの質問に適切に回答するために、ステップバイステップで慎重に考えることができます
user:
[検索結果]
{{search_result}}
[質問]
{{user_input}}
具体例を用いてわかりやすく説明して。回答の参考にしたファイルの名前を必ず表示すること。
今回は後の処理でchatタイプのモデル(gpt-35-turbo)を使用します。その場合、Promptは以下のような書式にする必要があります。
system:
システムメッセージ
assistant:
AIメッセージ
user:
ユーザメッセージ
次に出力の設定を編集します。

Runをクリックしてテスト実行し、ステータスに問題がないことを確認します。
LLMを追加し、回答を生成
「入力のベクトル化→情報検索→プロンプト作成」まで完了しました。あとは推論実行するだけです。
LLMをクリックします。

コンポーネントの定義を編集します。
- 名前を変更
- Apiをchatに変更
- temperatureを0に設定
- max_tokensを400に設定
- Promptを変更
- Validate and parse inputをクリック
- InputsのValueを変更

フローの出力として、このコンポーネントの出力を指定します。

実行と結果の確認
Runをクリックして実行し、結果を確認してみます。
下記jsonのoutputを見るとイイ感じの回答をしてます。ファイル名もちゃんと出力してくれていますね。
またsystem_metricsからトークン数なども確認できるみたいです。
{
"system_metrics": {
"completion_tokens": 267,
"duration": 6.867124,
"prompt_tokens": 1906,
"total_tokens": 2173
},
"output": "「責任あるAI」とは、AIの開発や運用において、人間の利益や安全性を最優先に考慮し、慎重に設計されたAIのことを指します。具体的には、AIが生成するコンテンツが正しくない、または有害なものにならないように、適切なフィルターやガイダンスを提供することが含まれます。\n\n例えば、Microsoftは、Azure OpenAIで使用できる生成モデルについて、責任あるAI使用に関する原則を取り入れ、顧客をサポートするコンテンツフィルターを構築するなど、慎重な設計と熟考した軽減策を講じています。この情報は、ファイル名が「責任あるAI.png」のファイルから得られました。"
}
まとめ・所感
Prompt flowの便利機能とベクトル類似検索の実装方法を紹介しました。
評価や外部ツールの組み込みはめちゃくちゃ使えそうですね。使いこなせるようになりたい。
個人的に開発しているLLMアプリケーションのコア部分をPrompt flowに移行してみたいです。(経験値上がりそう。)
また、評価がPrompt flowで実装されているのが興味深かったです。実装した人に使用感や実際便利なのかどうかインタビューしたいですね。笑
以下のような質問がきそうだなあと思ってました。
偉い人:
「評価をGPTベースでやるとなると、その評価するプロンプトは評価しなくていいの?」
Prompt flowには多くのサンプルが用意されていました。(chat形式、ベクトル検索、評価など)
サンプルをcloneしてきて中身を確認できるので、実装例から多くのことを学べそうです。色々試そう。