本記事では、参加中のkaggleコンペ~Home Credit Default Risk~についての2ndミーティング(2018/06/01)の内容を記しています。本記事は、僕らのKaggle奮闘記~Home Credit Default Risk編~#1の続きとなります。
今回Kaggleにチームで参加するということで(二人ですが笑)、データ分析力だけでなくチームでのプロジェクトマネジメント力もトレインできるのではないかと考えました。そこで本記事では、データ分析をどのように行ったかだけではなく、チームプロジェクトを行う上でどのようなことに留意したかについても書き留めようと思います。
参加コンペ
Home Credit Default Risk
既存の様々なデータから顧客の借金返済能力を予測するモデルの作成
ミーティングトピックの設定
① この一週間の進捗確認
② そこから出てきた不明点や改善点の抽出
③ 次やること決める
進捗確認
タスク前の進捗
- 下準備
- チーム内環境の統一
- Kaggle参加コンペからのデータダウンロード
- pandasを利用してデータフレームに入れる
- データの変数を知る(HomeCredit_columns_description.csv)
- データ加工
-
データを視覚化してイメージを掴む
- 変数同士のヒストグラムなど
- 欠損値の確認
- discussion boardでもチェック
- 視覚化された情報を元にpredict用のデータフレームを作成
-
データを視覚化してイメージを掴む
- Discussion boardから参考になりそうなものをピックアップして理解する
- Predict
- スコア計算手法のチェック
- モデル作成(SVM, NNなど関数として全部作る)
- Implement
- パラメータチューニング
- モデル選択(ベストスコアを持ってるものを抽出)
- PDCAを回す
- 出力をボードに提出しスコアのチェック
- Kernelで他チーム情報のチェック
- スコアの解釈
- 4.に戻る
今回までにやるべきタスク
・データの変数の確認
・最低5つ視覚化して特徴付けを行っておく(図式化必須)
タスクの共有
@sakigakeman
データの変数の確認
さーてデータの変数を確認するかーと思いとりあえずKaggleコンペのホーム画面に行きます。すると下図のような感じで説明書きがされており、これを見るとどうやら一番下のHomeCredit_columns_description.csvが変数について色々述べている模様。
そしてHomeCredit_columns_description.csvを開いてみると、たしかにそれぞれのデータフレームの変数に対する説明がDescriptionカラムでされています。しかし全て英語で書かれておりなんとなくイメージが掴みにくいので、とりあえずメインテーブルになるであろうapplication_trainの変数であるDescriptionをざっと和訳することにしました。

こう訳してみようとすると、専門知識とまでは行かないまでも日常で使うような一般常識以外にも見識を深めておくことがデータ解析においても必要のようです。

さすがに全部やるのは面倒だし不毛かもなと思ったので、ある程度訳してだいたいイメージが掴めてきた(ような気がした)ところで一旦やめにしました。
そしてこの和訳作業と同時並行でそれぞれの変数がどのような種類の値を持っているのかを確認していたのですが、その確認中に出てきた不明点などを以下に箇条書きにしておきます。
・従属変数同士に大きな相関がある場合、どちらか弾くべきなのか?
- 例えば、携帯電話を持ってる人を示すカラムとe-mailアドレスを持っている人を示すカラムが別々の従属変数として入っていた場合(携帯電話を持っていればほとんどがe-mailアドレスを持っている)
・人間的解釈では絶対関係ないだろ!みたいなデータでも目的変数に相関の絶対値がかなり高くでている場合はどうするのか?
・データが文字列で分類されているとき、どうやって学習器に入れるのがいいのか?
- Monday, Tuesday, Wednesday...といった要素を持つデータに対して
さらにここで少し二人で話し合い(どうしてかは忘れたのですが)、とりあえず全てのテーブルを下の図のkey連結表を元に結合させて一つの大きなテーブルを作ってみることになりました。

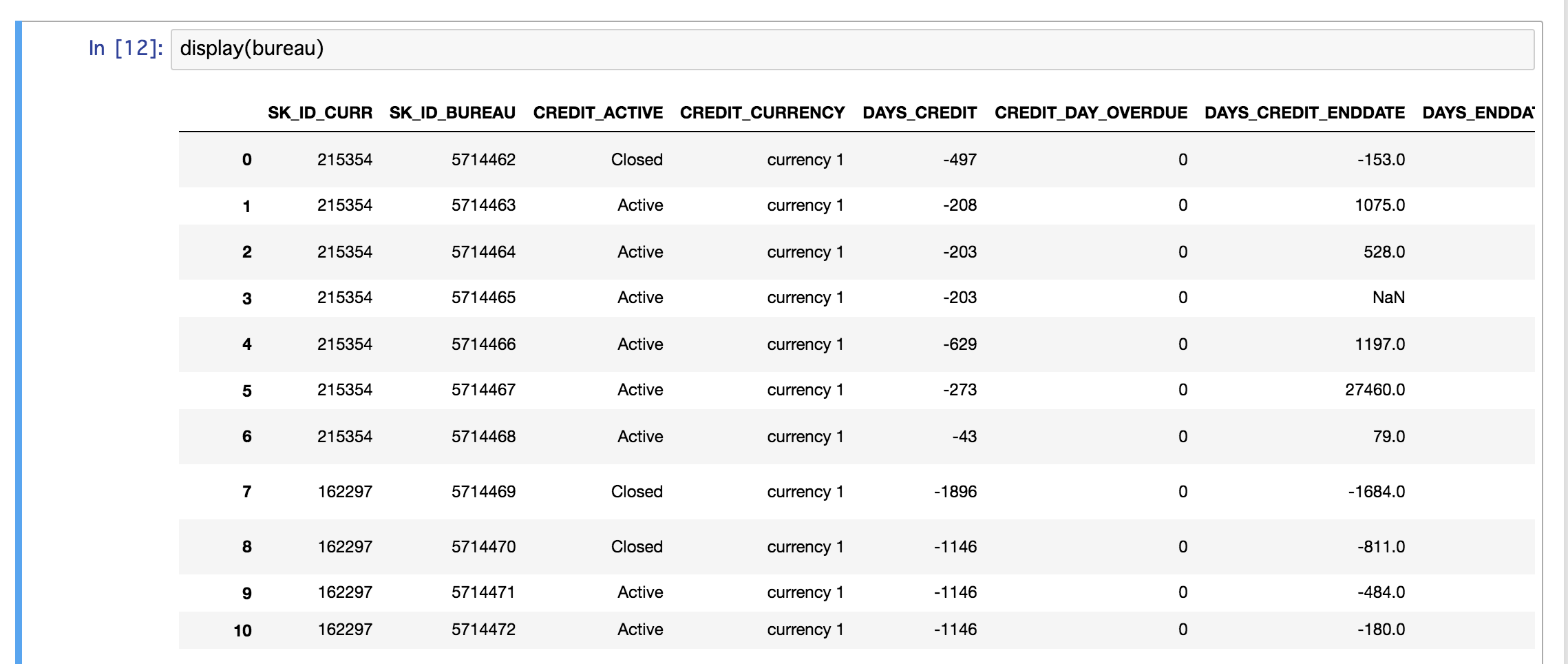
しかし、ここでまた新たな不明点が出てきます。上図によると、例えばapplication_trainとbureau.csvを連結しようとしたときにSK_ID_CURRというのが結合キーになっているようです。しかし、bureau.csvのいくつかを表示させて見ると、下図のように一つのSK_ID_CURRに対して異なるデータが付与されていることが分かります。つまり、application_trainではユニークとなっている変数SK_ID_CURRが、bureau.csvではユニークではないということです。
・このような場合、データフレームのジョインはouter_joinで行うのがいいのか?
以上がタスクの内容と、そこから出てきた不明点となります。最低5つ視覚化して特徴付けを行っておくものについてはやっていないのですが、それ以外のことをやっていたことにより無罪放免となりました。
@oginom
データを視覚化してイメージを掴む
まず、application_trainがメインテーブルなのでそれのみに着目し、それぞれのカラムを要素の種類ごとに三種類に分類しました。それぞれの要素の種類とそのカラムの数は以下のようになっています。
bool型(0または1):33カラム
label型(順序のない値、文字列):16カラム
number型(数値):73カラム
そして今回はbool型(0, 1の二値を要素として持つ)を取り上げ、それぞれの変数と目的変数との相関を視覚化しました。下の図は、それぞれの変数において値1を持つデータの割合を示しています。出力値が1.0に近いものはほとんどのデータがそのカラムにおいて要素値1を持ち、逆に0に近いものはほとんどのデータがそのカラムにおいて要素値0を持つことを示します。

この図を見ると、bool型カラムにおいては多くのカラムで値に偏りがあることが伺えます。このように偏りがあるカラムは全体としては情報量が少ないように思われるのですが、逆にほとんどが要素値1を持っている中要素値0を持っているデータは特異点として何か役に立つかもしれません。
現段階では、この表からさらにミクロの部分にスケールダウンして解釈することはしませんでした。
また、下図はそれぞれのカラムの要素値(0, 1)と目的変数の値(0, 1)の関係について示しています。青の棒グラフはそのカラムで要素値1を持つ全データの目的変数の平均、オレンジの棒グラフはそのカラムで要素値0を持つ全データの目的変数の平均を示しています。
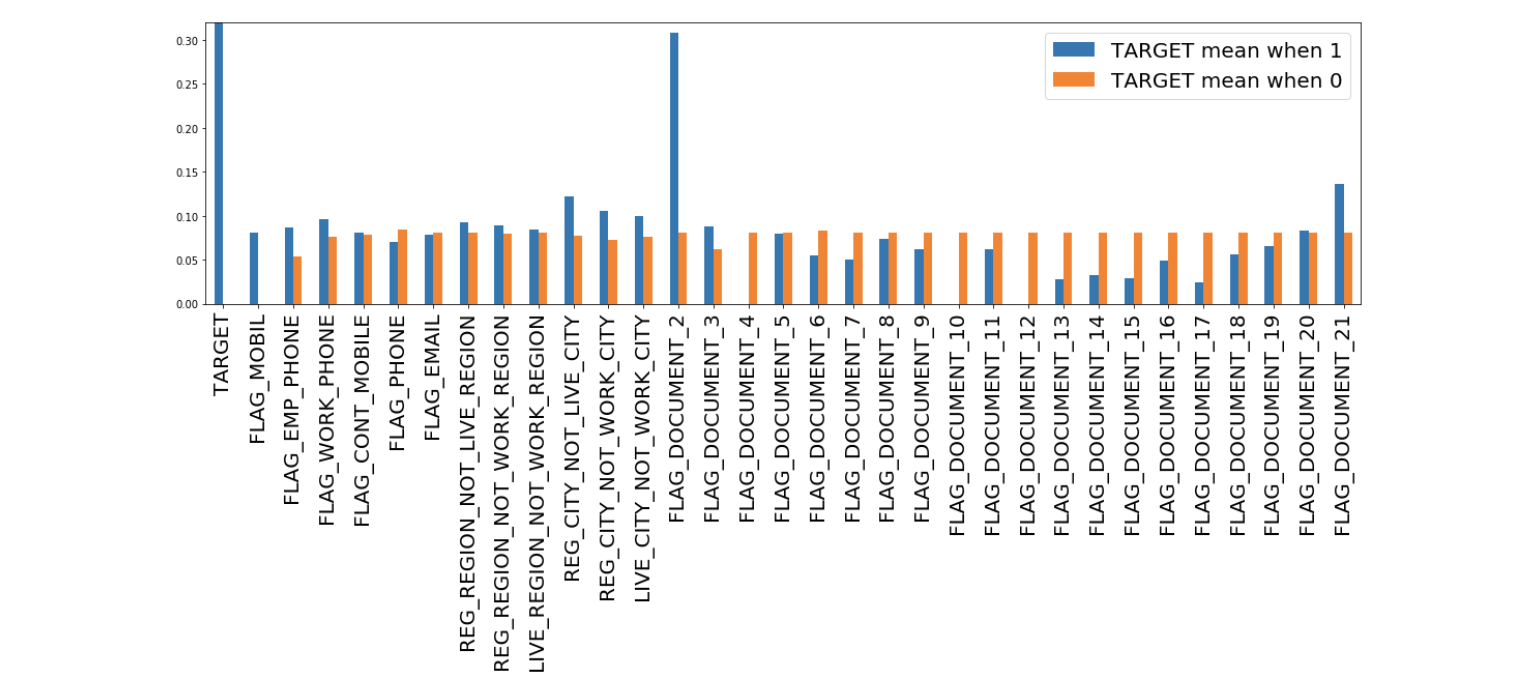
この図から、従属変数FLAG_MOBILとFLAG_DOCUMENT_2, 10, 17は目的変数であるTARGETに対し他変数と比べ大きな影響を与えていると解釈できます。
不明点としては、以下が挙げられました。
・欠損値を持つデータの割合が比較的多いので、そのようなデータへの対応をどうするか?
タスクにより出てきた不明点への対応
Q. 従属変数同士に大きな相関がある場合、どちらか弾くべきなのか?
仮A.
重回帰分析等ではこのような従属変数を弾くことによって精度を高めたりした経験がありますが、基本的には無相関化によってこれに対応します。この処理は、主成分分析と同等のものです。
参考:ニューラルネットワークの学習の工夫
Q. 人間的解釈では絶対関係ないだろ!みたいなデータでも目的変数に相関の絶対値がかなり高くでている場合はどうするのか?
仮A.
データ数が十分な場合はきっと何か関連はあるはず(気づいてないだけor他の従属変数に影響を与えてる等)なので、とりあえずそのままにすることとします。
Q. データが文字列で分類されているとき、どうやって学習器に入れるのがいいのか?
仮A.
二値ラベルのときは0,1で入れ、多値ラベルの時(例えばsingle, marrige, divorce)はまずsingleカラムを新たに作りsingleなら1, singleでないなら0とし、次に同様にしてmarrigeカラムを作りmarrigeならば1, でないなら0という作業をラベルの種類分行うことで対応します。
このようなある要素のみが1でその他の要素が0であるような表現方法を、one-hot表現と言います。
Q. 与えられたテーブルをkeyを参考に結合して大きなテーブルを作る際outer_joinするべき?
仮A.
とりあえずそのまま何もしなくて良いことになりました(笑)
Q. 欠損値の対応はどうするか?
仮A.
一つのカラムに対し欠損値を持つデータの割合が30%強と少し割合としては高いことがわかったので、一旦discussion boardを参考にしてから欠損のあるデータは使わないようにするなどの対応を決定することにしました。
今後やること
文字列をone-hot表現に直す
discussion board読む
提出用データの説明変数に欠損があるかチェック
欠損値の扱いを考える
とりあえず適当にモデル作ってどれぐらいのパフォーマンス出たかチェックする(1人最低1モデル)
メモ
プログラム共有方法 - Google Driveに.ipynbでアップロード
フローの更新と現時点までの進捗
- 下準備
- チーム内環境の統一
- Kaggle参加コンペからのデータダウンロード
- pandasを利用してデータフレームに入れる
- データの変数を知る(HomeCredit_columns_description.csvの和訳)
- データ加工
-
データを視覚化してイメージを軽く掴む
- 変数同士のヒストグラムなど
- メインテーブルの文字列をone-hot表現に直す
- トレインデータ/テストデータにおける欠損値の確認
- discussion boardでもチェック
- 欠損値への対応の決定
- redict用のデータフレームを作成
-
データを視覚化してイメージを軽く掴む
- Discussion boardから参考になりそうなものをピックアップして理解する
- Predict
- とりあえず適当なモデルでの出力でパフォーマンスがどれくらいか把握する
- スコア計算手法のチェック
- モデル作成(SVM, NNなど関数として全部作る)
- Implement
- パラメータチューニング
- モデル選択(ベストスコアを持ってるものを抽出)
- PDCAを回す
- 出力をボードに提出しスコアのチェック
- Kernelで他チーム情報のチェック
- スコアの解釈
- 2.に戻る
次回までのタスク
・和訳をざっくりでいいので終わらせる(sakigakeman)
・メインテーブルの文字列をone-hot表現に直す(sakigakeman)
・欠損値の扱いについて案を持ってくる(oginom)
・discussion board読む(1人1個担当分)
・とりあえずモデル作ってどれぐらいのパフォーマンス出たか(1人最低1モデル)
3rdミーティングは2018/06/10です。