
こんにちは!逆瀬川 ( https://twitter.com/gyakuse ) です。
今日は英語論文をサクッと翻訳する方法を共有します。
素晴らしい事前学習済みモデルの恩恵で素人でも1時間程度で実装できてしまいます。
なお、実装めちゃ汚いのですが、そのあたりはご容赦ください。
論文以外の文字埋め込みのないpdfを翻訳したい場合はこちらを参考にしてください:
論文全体の自動要約についてはこちら:
概要
翻訳モデル、レイアウト検知ライブラリとpdfを操作するライブラリを用いて外国語で書かれたpdfファイルを翻訳します。
翻訳にはフリーのニューラル機械翻訳モデルFuguMTを使用します。
この手法の嬉しさ
- DeepLおよびDeepL APIではpdf翻訳がサポートされていますが、行の切り替わりで別の文章と認識されることが多く、途中までの文章で翻訳されるため精度が落ちてしまいます
- この手法では段落単位で文章が一つにまとめられるため、より正確な翻訳が機能します。
- また、DeepL Proアカウントでは1ヶ月に翻訳できる文書ファイル数が5つに限定されています。
Google Colab
使い方
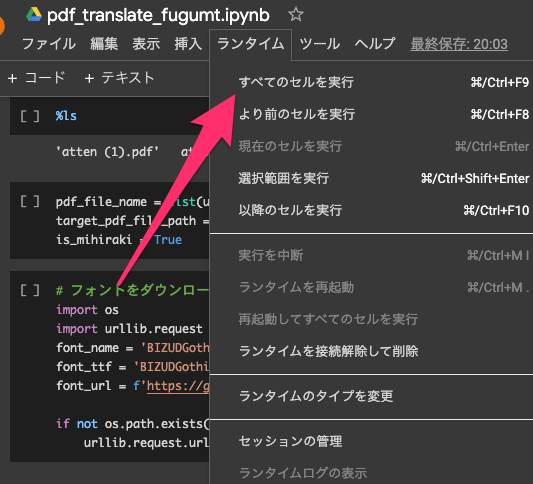
- 上記colabを開き、ランタイム > すべてのセルを実行 をクリックします
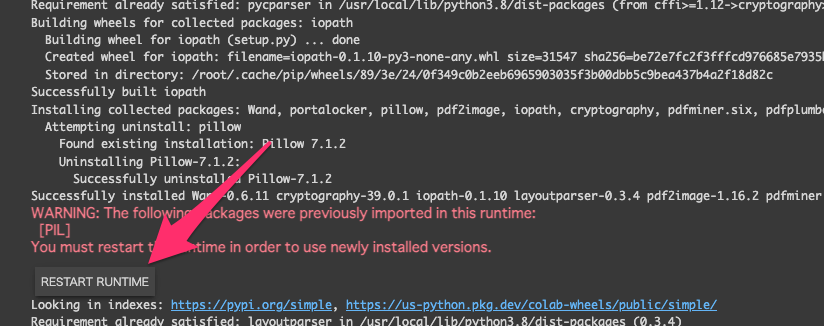
- pip install をしている部分で、PILのインストール時に以下のようなRUNTIME ERRORが出るのでクリックしてランタイムを再起動します(バージョン違いのため)
- 再度「すべてのセルを実行」をクリックします
- Restart runtimeとか出てきますが今度は無視でいいです
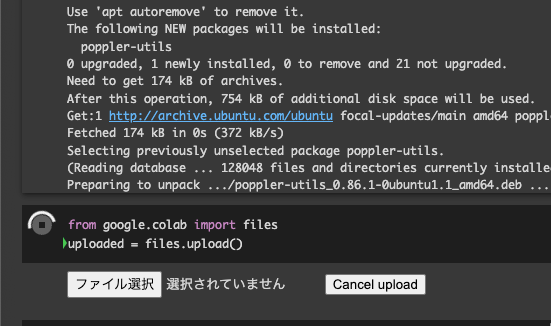
- pip install が終わったら、ファイルをアップロードするUIが出てくるので、ファイルをアップロードします
- 処理を待ちます
- 処理が終わったらtranslated_{file_name}.pdfで保存されます
- 2ページ表示にするといい感じに幸福を味わえます
使用しているライブラリ等について
- layoutparser: レイアウトをパースするためにDetectron2のwrapperとして使っています。このライブラリではpdfを画像として渡して内部で
mask_rcnn_X_101_32x8d_FPN_3xという事前学習モデルを呼び出しています - reportlab: pdfの文章読み込み用に使用しています
- pypdf: pdfの文章書き込み用に使用しています
- FuguMT: huggingfaceのtransformersを使ってFuguMTを呼び出しています
処理の流れ
翻訳の処理の流れは以下のようになります。
- pdfをlayoutparserでレイアウト分けする
- レイアウトで検出された部分ごとに以下の処理を行う
- レイアウトに対応するpypdfで抽出された文章をピックする
- 文章をFuguMTで翻訳する
- レイアウトの対象部分を白い長方形で覆う
- その上に文章を詰め込み、reportlabで書き込む
このようにシンプルな処理で英語のpdfだけではなくどんな言語の資料でも、文字埋め込みがあれば翻訳することができます。
実装
pdfをパラグラフ単位で取得する
レイアウトモデルで検出させます。レイアウトはdraw_box関数でどのように検出されたかを確認することができます。
そのままだと画像やセクション名なども含まれてしまうので、type=='Text'とすることでテキスト(パラグラフ)のみを抽出することができます(薄いオレンジで囲まれた部分)。

pdf_layout = model.detect(pdf_image)
paragraph_blocks = lp.Layout([b for b in pdf_layout if b.type=='Text'])
なお、添字のように、検出されたパラグラフは人間の認識する順序と同一になっていません。
特定のブロックに含まれた文章を取得する
layoutparserで取得できたパラグラフブロックの中に入っている文章を抽出します。
layoutparserで文章を扱うにはOCRをしなければなりませんが(たぶん)、コストが高いので、pypdfで文章を取ってきて、layoutparserが検出した領域内に含まれているかを判定してあげます。
また、layoutparserの検出が甘いことも考えられるので、許容誤差も設定します。
inner_text_blocks = list(filter(lambda x: is_inside(paragraph_block, x), text_blocks))
# 特定のtext_blockがparagraph_blockに含まれているかチェック
def is_inside(paragraph_block, text_block):
paragraph_width = paragraph_block.block.x_2 - paragraph_block.block.x_1
paragraph_height = paragraph_block.block.y_2 - paragraph_block.block.y_1
if paragraph_width > 300:
allowable_error_pixel = 10
return (text_block.block.x_1 >= paragraph_block.block.x_1 - allowable_error_pixel and text_block.block.y_1 >= paragraph_block.block.y_1 and
text_block.block.x_2 <= paragraph_block.block.x_2 + allowable_error_pixel and text_block.block.y_2 <= paragraph_block.block.y_2 + allowable_error_pixel)
else:
allowable_error_pixel = 3
return (text_block.block.x_1 >= paragraph_block.block.x_1 - allowable_error_pixel and text_block.block.y_1 >= paragraph_block.block.y_1 and
text_block.block.x_2 <= paragraph_block.block.x_2 + allowable_error_pixel and text_block.block.y_2 <= paragraph_block.block.y_2 + allowable_error_pixel)
文章を埋め込む
layoutparserのParagraphを使って文章を埋め込みます。改行もいい感じにやってくれるのですが、フォントサイズはうまく自動化できなかったために、calc_fontsize という関数で処理しています。
frame = Frame(paragraph_x, height - paragraph_y, paragraph_width, paragraph_height,
showBoundary=0, leftPadding=0, rightPadding=0, topPadding=0, bottomPadding=0)
# テキスト実態の追加
fontsize = calc_fontsize(paragraph_width, paragraph_height, translated_text)
style = ParagraphStyle(name='Normal', fontName=font_name, fontSize=fontsize, leading=fontsize)
paragraph = Paragraph(translated_text, style)
story = [paragraph]
story_inframe = KeepInFrame(paragraph_width * 1.5, paragraph_height * 1.5, story)
frame.addFromList([story_inframe], text_canvas)
既知のバグや課題
- フォント系
- フォントサイズがデカすぎたり小さすぎたりする (
calc_fontsizeをまともなものにする) - フォントサイズがでかすぎて入らなかったりする
- フォントサイズがデカすぎたり小さすぎたりする (
- 領域系
- 元のテキストの上に白く塗っただけなので、コピペしづらい (英語のフォント情報を事前に削除する)
- 領域判定がわりと泥臭い、白く塗りつぶしすぎてしまったり、足りなかったり
- 打ち漏らしがある (章タイトルとか余計な翻訳しないようにlayoutparserでtext判定されたやつだけを対象にしているのでtext判定されなかったやつは翻訳されない)
- 引用やリンクが元の英文の場所を参照している
後記
このように、資料翻訳を行うことは事前学習済みモデルのおかげで簡単にできるようになっています (上記は1時間程度で実装できました。なお、記事作成に2時間かかって俺は泣いてます)。
綺麗に実装したりフォントサイズを安定させたり数式を解析しようとすると (latex image to mathmlのような処理を入れる)、実装コストが高くなります。
ただ、こういう雑実装でも今後の実装のためになると思うので、公開しました。
ところで
- 論文をいちいちcolabを動かして翻訳するのはつらいです
- https://readable.jp/ であれば、月額980円で無限に翻訳することができます (筆者もこれを作ったあとこのサービスに気づき、今では月に200本程度翻訳処理かけています。控えめに言って神です)
参考
- layoutparser
- ReportLab