こんにちは!逆瀬川 (@gyakuse)です!
さいきん以下の記事を書きました。
上記記事ではOpenAIが新しく提供したFunction callingを使って請求書から請求額や請求先情報等を自動的に抽出するという仕組みを解説しています。
ちなみに、functionsの定義書くのだるくてChatGPTに書かせていました。つまり、functionsをChat APIを使って自動で作れば、任意の種別の資料にすぐさま適用できるというわけです。今日はこちらの仕組みの紹介と、AppendixとしてGoogle Bardで情報抽出する、というのをやってみます。
処理の流れ
ユーザーがやることが画像やPDFをアップロードするだけだと未来っぽいです。書類種別も考えさせてしまいましょう。
- 画像やPDFをアップロードする
- OCRで文字列を座標とともに抽出する
- 上記座標付きテキストをChat APIに投げて書類種別 (「請求書」「納品書」「免許証」等) を自動で判別する
- 書類種別に応じたFunction callingのFunctionをChat APIで自動生成する
- 座標付きテキストとFunctionをもとにFunction callingして情報抽出する
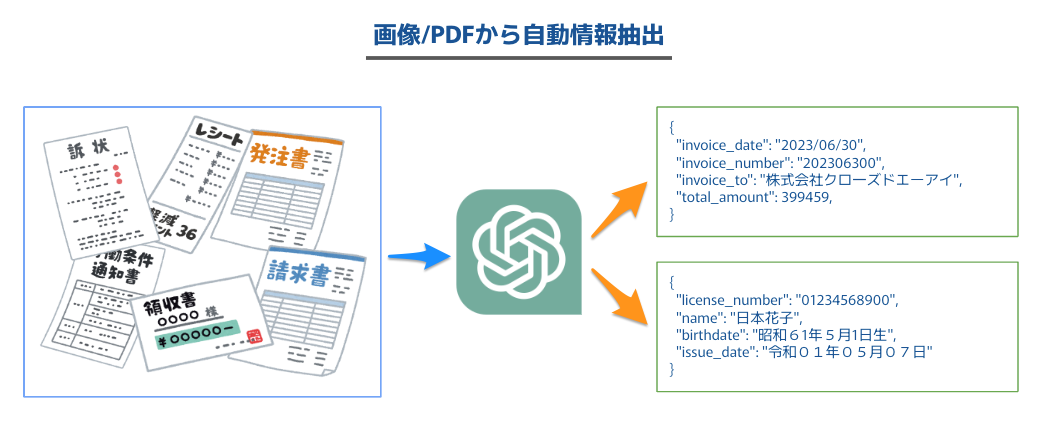
自動化の結果
実装を見る前に、結果だけ先に見てみましょう。わりといい感じなのが伝わるのではないでしょうか。これらは書類種別名を与えず、画像から推定し、抽出要素を自動決定しています。
- 免許証
- https://www.npa.go.jp/policies/application/license_renewal/index.html
-
{ "license_number": "01234568900", "name": "日本花子", "birthdate": "昭和61年5月1日生", "address": "東京都千代田区霞が関2-1一2", "license_type": "優良", "issue_date": "令和01年05月07日", "expiration_date": "2024年(令利06年06月01日まで有効" }
- レシート
- https://tamba-s.com/?attachment_id=229
- 以下では住所と電話番号は一部伏せ字とした
- 日本酒の数量以外は合っている
-
{ 'receipt_date': '2019年10月1日', 'store_name': 'EtC..MArt', 'address': '兵庫県丹波市母坪***-*', 'phone_number': '****-**-****', 'receipt_items': [ { 'item_name': 'パン', 'item_count': 1, 'item_unit_price': 500, 'item_price': 500 }, { 'item_name': '牛肉', 'item_count': 1, 'item_unit_price': 4500, 'item_price': 4500 }, { 'item_name': '日本酒', 'item_count': 2, 'item_unit_price': 2500, 'item_price': 5000 }, { 'item_name': 'フライパン', 'item_count': 1, 'item_unit_price': 2000, 'item_price': 2000 } ], 'total_amount': 9500 }
うまく行かない場合の選択肢
基本的にはOCRのmodelの問題が主であるため、別のmodelの利用やmodelのfine-tuning、あるいは有償のAPIを利用することで改善されます。レイアウト分析のない簡単なOCR modelで良いというのが今回の嬉しいポイントです。
- オープンソース
- 有償 API
適応可能そうな領域
次にどんな領域で使えるか事前に考えておきます。
- 各種商取引のデータ化
- レシート
- 見積書、注文書 (申込書)、納品書、検収書、請求書、領収書
- 契約書
- その他書式のデータ化
- 名刺
- ハガキ
- アンケート
- 身分証明書
- 資格証明書
- 報告書
業界単位でChatGPTに考えさせてみた結果:
- 金融・銀行業: 通帳、契約書、領収書、請求書
- 保険業: 保険契約書、請求書、医療記録
- 小売業: レシート、請求書、領収書
- 製造業: 部品リスト、製品マニュアル、安全データシート
- 教育: 試験答案、学生の書類、研究論文
- 出版業: 原稿、印刷物、電子書籍
- 法律業界: 契約書、裁判所の記録、法律文書
- ロジスティクス: 配送伝票、在庫リスト、輸送文書
- 不動産業: 物件チラシ、契約書、不動産評価書
- 医療業界: カルテ、医療記録、薬品説明書
- 産業廃棄物処理業者: 廃棄物管理表、危険物取り扱い指南書
- レストラン業: メニュー、注文伝票
- 旅行業: パスポート、チケット、予約確認書
- 公共交通: チケット、時刻表、運賃表
- 建設業: 青図、見積もり書、工程表
- 警察/法執行: 警察報告書、罰金通知、証拠書類
- 農業: 作物レポート、気候データ、土壌テスト結果
- エネルギー産業: サービス契約、メーター読み取り、保守記録
- 自動車業: パーツリスト、サービスマニュアル、保証書
- 広告業: クリエイティブデザイン、広告契約、媒体データ
- IT業界: ソフトウェア仕様書、バグ報告、ユーザーマニュアル
- 人事: 履歴書、面接結果、従業員ファイル
- 証券業界: 報告書、市場調査、財務諸表
- アート業界: アート作品の説明、展覧会カタログ、著作権証明書
- 慈善業界: 寄付記録、ボランティア登録、寄付者情報
- 環境保全業界: 環境影響評価、保全報告書、野生生物調査
実装
それでは実装していきます。
今回実装したものは以下のGoogle Colaboratoryで利用可能です。
書類の種別の自動判定
OCRで得たテキスト情報からジャンルを推定します。
Function callingを使って処理しています。あんまり精度はよくないので、プロンプトを改善する必要がありそうです。Function callingを使わず独自の分類器を作ったほうがよさそうです。
def estimate_genre(ocr_text: str, openai_key: str) -> str:
"""
OCRで得たテキスト情報から書類ジャンルを推定する
Parameters
----------
ocr_text: str
OCRで抽出したテキスト情報
openai_key: str
OpenAI API Key
Returns
-------
genre: str
書類ジャンル
"""
functions = [
{
"name": "genre_estimate",
"description": "これはある書面の画像をOCRにかけたものから、書類のジャンルを推定するための処理です。OCRで抽出されたテキストは以下の形式に従います: (x座標, y座標): {OCRで抽出されたテキスト}",
"parameters": {
"type": "object",
"properties": {
"genre_name": {
"type": "string",
"description": "ジャンル名 (例: 請求書, 領収書, 運転免許証, はがき, レポート, etc...)"
}
},
"required": ["genre_name"]
}
}
]
result = process_with_gpt(ocr_text, functions, openai_key)
return result['genre_name']
Functionの自動生成
Function callingに使うためのFunctionを生成します。
ジャンル名推定で拾った情報とサンプルのFunctionsをもとに生成しています。
Chat APIのレスポンスにmarkdownの構文が混じったりするのでそれを削除する処理も入れています。
def get_functions_from_gpt(genre: str, openai_key: str) -> List[Dict[str, Union[str, int]]]:
"""
指定した書類ジャンルのFunction calling用Functionsを作成する
Parameters
----------
genre: str
書類ジャンル
openai_key: str
OpenAI API Key
Returns
-------
functions: List[Dict[str, Union[str, int]]]
Function calling用Functions
"""
function_prompt = '''情報抽出システムがあります。
規定のフォーマットを参考に、これを「xxxx」に対応したものに書き換え、その結果のみ出力してください。
## 規定のフォーマット
```
functions = [
{
"name": "invoice_information_extraction",
"description": "これは請求書のpdfをOCRにかけたものから情報を抽出するための処理です。OCRで抽出されたテキストは以下の形式に従います: (x座標, y座標): {OCRで抽出されたテキスト} また、請求書は以下の配置ルールがあります。(1) 銀行名、支店名、口座種類、口座番号は座標的に近い位置にある (2) 住所、請求元会社名、名前、電話番号、メールアドレスは座標的に近い位置にある (3) 請求元会社名は請求先とは異なり、無い場合がある (4) 郵便番号、住所は座標的に近い位置にある (5) 請求先は「御中」や「様」などの左に書かれる\n座標を考慮しつつ情報を抽出してください。",
"parameters": {
"type": "object",
"properties": {
"invoice_date": {
"type": "string",
"description": "請求日"
},
"invoice_number": {
"type": "string",
"description": "請求番号"
},
"invoice_to": {
"type": "string",
"description": "請求先 (御中とか様は除外する)"
},
"billing_amount": {
"type": "number",
"description": "請求する金額"
},
"invoice_items": {
"type": "array",
"description": "請求品目",
"items": {
"type": "object",
"properties": {
"item_name": {
"type": "string",
"description": "請求品目名"
},
"item_count": {
"type": "number",
"description": "品目数量"
},
"item_unit_name": {
"type": "string",
"description": "品目単位名"
},
"item_unit_price": {
"type": "number",
"description": "品目単価"
},
"item_price": {
"type": "number",
"description": "品目金額"
}
}
}
},
"bank_name": {
"type": "string",
"description": "銀行名"
},
"branch_name": {
"type": "string",
"description": "支店名"
},
"account_type": {
"type": "string",
"enum": ["普通", "定期", "当座"],
"description": "口座種類"
},
"account_number": {
"type": "string",
"description": "口座番号"
},
"zipcode": {
"type": "string",
"description": "郵便番号"
},
"address": {
"type": "string",
"description": "住所"
},
"company_name": {
"type": "string",
"description": "請求元会社名"
},
"name": {
"type": "string",
"description": "名前"
},
"phone_number": {
"type": "string",
"description": "電話番号"
},
"email_address": {
"type": "string",
"description": "メールアドレス"
},
"remarks": {
"type": "string",
"description": "備考"
}
},
"required": ["invoice_date"]
}
}
]
```'''.replace('xxxx', genre)
function_messages = [{"role": "user", "content": function_prompt}]
openai.api_key = openai_key
function_response = openai.ChatCompletion.create(
model="gpt-4-0613",
messages=function_messages,
temperature=0,
max_tokens=1024,
)
function_text = function_response['choices'][0]['message']['content']
match = re.search(r'functions = (\[.*\])', function_text, re.DOTALL)
if match:
extracted_json_string = match.group(1)
else:
raise ValueError("No valid JSON object found")
# json形式の文字列をPythonのリストに変換
functions = json.loads(extracted_json_string.replace("\n", ""))
return functions
OCRでのテキスト抽出
PDFまたは画像に対してPaddleOCRでテキスト抽出処理をかけます。
座標情報付きのテキストとして出力させています。
def extract_text_with_ocr(file_path: str, ocr: PaddleOCR) -> str:
"""
指定したファイルからOCRを使用してテキストを抽出する関数
Parameters
----------
file_path: str
テキストを抽出するファイルのパス
Returns
-------
ocr_text: str
OCRで抽出したテキスト情報
"""
# ファイル拡張子を取得します
extension = os.path.splitext(file_path)[1]
results = []
if extension.lower() in ['.pdf']:
images = convert_from_path(file_path)
for i, image in enumerate(images, start=1):
print(f"Processing page {i}")
image_path = f'{i}.png'
image.save(image_path, 'PNG')
result = ocr.ocr(image_path)
results.append(result)
elif extension.lower() in ['.jpg', '.jpeg', '.png']:
print(f"Processing image {file_path}")
result = ocr.ocr(file_path)
results.append(result)
else:
print(f"Unsupported file type {extension}")
ocr_text = ""
for r in results[0][0]:
ocr_text += f"({r[0][0][0]}, {r[0][0][1]}): {r[1][0]}\n"
return ocr_text
出力の参考: 免許証
(34.0, 34.0): 氏名
(109.0, 32.0): 日本花子
(444.0, 33.0): 昭和61年
(542.0, 32.0): 5月
(595.0, 31.0): 1日生
(36.0, 97.0): 住所
(87.0, 95.0): 東京都千代田区霞が関2-1一2
(36.0, 129.0): 玄付
(103.0, 126.0): 令和01年05月07日
(330.0, 126.0): 12345
(34.0, 154.0): 2024年(令利06年06月01日まで有効
(438.0, 176.0): 画
(36.0, 198.0): 免許の
(101.0, 195.0): 眼鏡等
(36.0, 220.0): 条件等
(222.0, 231.0): 見本
(39.0, 250.0): 優良
(76.0, 298.0): 第
(121.0, 296.0): 01234568900
(373.0, 297.0): 号
(32.0, 335.0): 小N平成15年04月01:
(50.0, 362.0): -「
(60.0, 358.0): 成17年06月01日
(462.0, 364.0): 00000
(44.0, 382.0): 糧成29年0801
(461.0, 381.0): 公宝季員会
pdfminer.sixによるテキスト抽出
PDFでフォント埋め込みの場合はこちらを使うべきでしょう。
埋め込まれたフォントに基づき、extract_text_with_ocrと同様の出力を行います。
def extract_text_with_pdfminer(file_path: str) -> str:
"""
指定したPDFファイルからpdfminerを使用してテキストを抽出する関数
Parameters
----------
file_path: str
テキストを抽出するPDFファイルのパス
Returns
-------
ocr_text: str
pdfminerで抽出したテキスト情報
"""
ocr_text = ""
with open(file_path, 'rb') as file:
parser = PDFParser(file)
doc = PDFDocument(parser)
rsrcmgr = PDFResourceManager()
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
interpreter = PDFPageInterpreter(rsrcmgr, device)
for page in PDFPage.create_pages(doc):
interpreter.process_page(page)
layout = device.get_result()
for element in layout:
if isinstance(element, LTTextBox) or isinstance(element, LTTextLine):
for text_line in element:
if isinstance(text_line, LTTextLine):
x, y, _, _ = text_line.bbox
x = round(x, 1) # x座標を小数点第1位までに丸める
y = round(y, 1) # y座標を小数点第1位までに丸める
text = f"({x}, {y}): {text_line.get_text()}"
ocr_text += text
return ocr_text
Function calling
Function callingのwrapper関数です。
def process_with_gpt(ocr_text: str, functions: List[Dict[str, Union[str, int]]], openai_key: str) -> Dict[str, Union[str, int]]:
"""
OCRで取得したテキストをGPT-3を使用して処理する関数
Parameters
----------
ocr_text: str
OCRで取得したテキスト情報
functions: List[Dict[str, Union[str, int]]]
Function calling用Function
openai_key: str
OpenAI API Key
Returns
-------
result: Dict[str, Union[str, int]]
GPT-3.5で処理した結果
"""
messages = [{"role": "user", "content": ocr_text}]
openai.api_key = openai_key
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-0613",
messages=messages,
functions=functions,
temperature=0,
max_tokens=1024,
function_call={"name": functions[0]['name']}
)
result = response["choices"][0]["message"]["function_call"]["arguments"]
return json.loads(result)
PDF&フォント埋め込み確認関数
def check_pdf_and_font(filepath: str) -> bool:
"""
指定したファイルがPDFかつフォント埋め込みかチェックする関数
Parameters
----------
file_path: str
テキストを抽出するPDFファイルのパス
Returns
-------
bool
pdfかつフォント埋め込みの場合True, それ以外の場合False
"""
if os.path.exists(filepath) and filepath.endswith('.pdf'):
try:
reader = PdfFileReader(filepath)
with open(filepath, 'rb') as f:
parser = PDFParser(f)
doc = PDFDocument(parser)
fonts = set()
for obj in doc.get_objects():
if isinstance(obj, (PDFType1Font, PDFTrueTypeFont)):
fonts.add(obj)
if fonts:
return True
except:
pass
return False
使用例
ジャンルを手動で入力する場合にも対応するようにしています。
# OCRの初期化
ocr = PaddleOCR(lang='japan')
# OCRによるテキスト抽出
ocr_text = extract_text_with_ocr(file_path, ocr)
# ジャンル推定
if genre == "":
genre = estimate_genre(ocr_text, openai_key)
# Function生成
functions = get_functions_from_gpt(genre, openai_key)
# 結果
result = process_with_gpt(ocr_text, functions, openai_key)
print(genre)
print(functions)
print(ocr_text)
print(result)
# PDFかつフォント埋め込みの場合
is_pdf_with_embedded_fonts = check_pdf_and_font(file_path)
if is_pdf_with_embedded_fonts:
miner_text = extract_text_with_pdfminer(file_path)
result2 = process_with_gpt(miner_text, functions, openai_key)
print(miner_text)
print(result2)
サマリー
今回は書類からの情報抽出を自動化してみました。個人情報保護等の理由で気軽にOpenAI APIを使えないケースも多々ありそうですが、ちょっとした遊びや社内文書のデータ化処理に使うにはめちゃ気軽にできて便利です。
今回はFunctionsを生成することに焦点を当てましたが、これはあくまで試しに使うためのものなので、ジャンル名を指定したり、Functionsや周辺のプロンプトを自分で定義することでより精度を上げることができます。
ぜひみなさんも気軽に情報抽出してみましょう。
Appendix: Google Bard でやってみる
最近、Google の Bard に画像認識システムが登場しました。画像は内部的にはGoogle Lensで処理されており、Deplot/Matchaの成果も反映されているようでグラフや表を正しく理解してくれます。
Google Bard の画像認識システムを使う
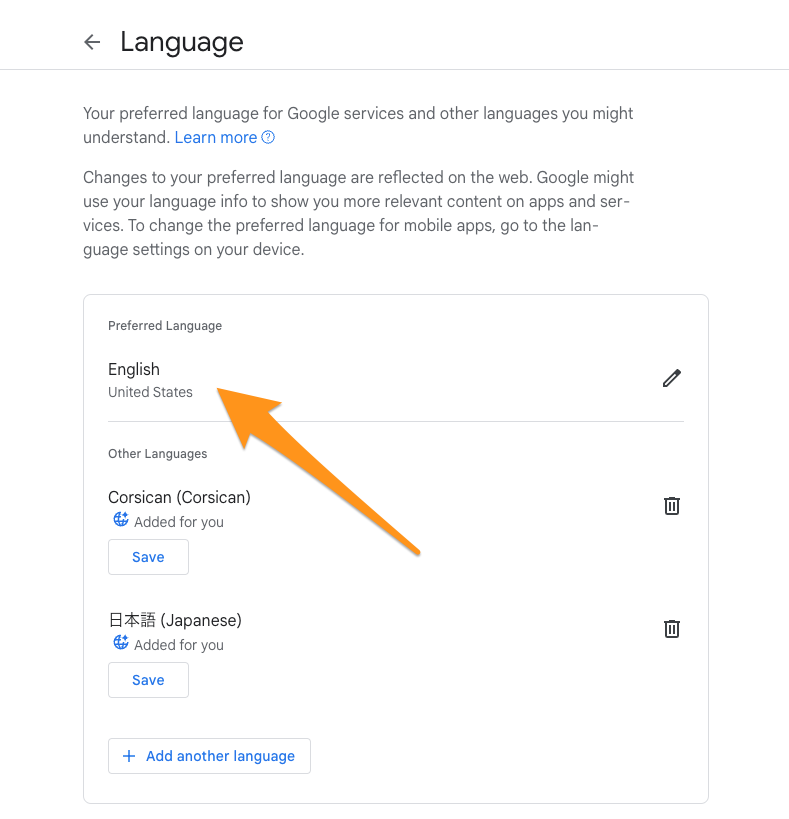
現在は英語しかサポートしていないので、Googleの言語設定を変更します。以下ページから言語をEnglishに変更してください。
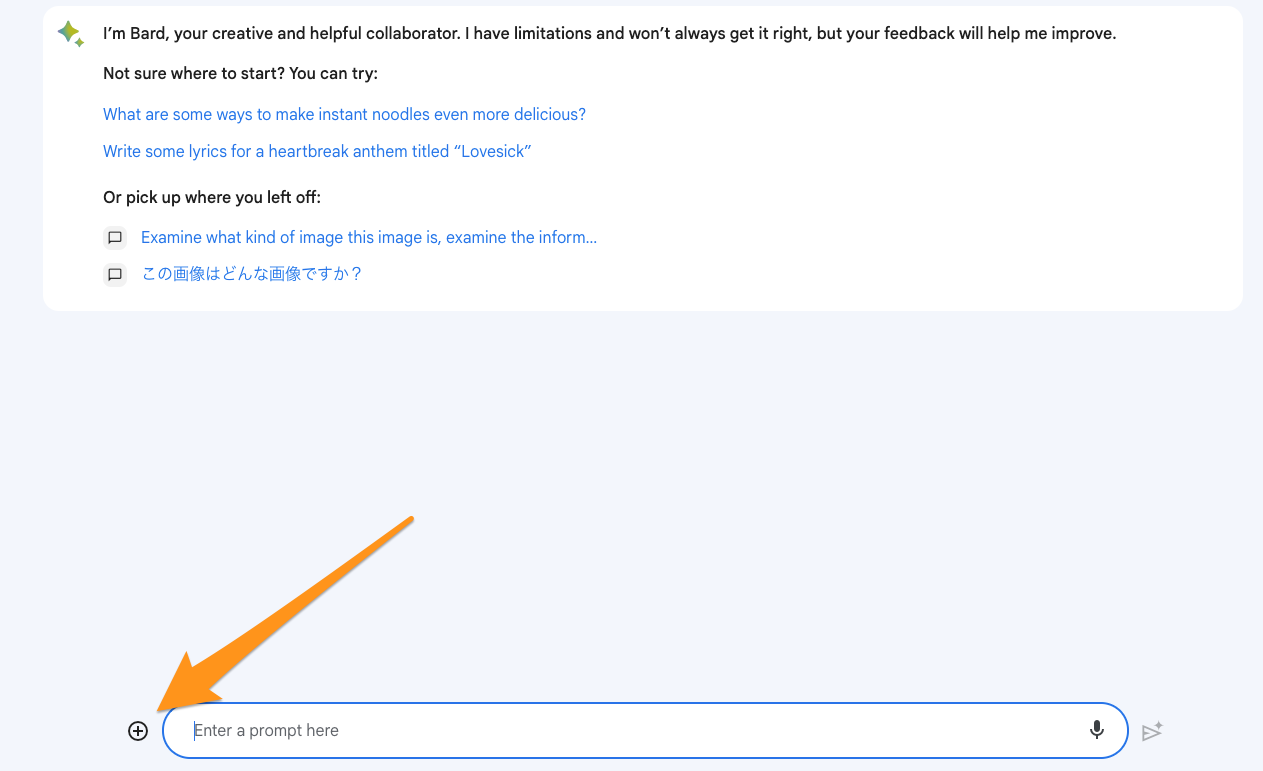
ファイルをアップロードする
入力欄左側の + ボタンを押し、画像を選択します。PDFの場合はキャプチャを撮るなどして画像形式にしてから貼り付けてください。
プロンプト
Bard で画像検索を行う際のプロンプトにおいて、日本語を使うと以下のように回答されてしまいます。
現時点では、一部の言語にのみ対応できるようトレーニングされており、そちらについてはまだお手伝いできません。現在サポートされている言語のリストは、Bardヘルプセンターをご覧ください。
「日本語で回答してください」という内容を英語で書けば、通ります。
今回は以下のプロンプトをまず英語に翻訳します。
情報抽出をお願いします。具体的には以下の作業をしてください。
- この画像がどういう書類か推測する
- その書類に必要な情報を検討する
- この書類情報をリスト形式で日本語で表示する
翻訳後:
Please perform the following information extraction tasks:
- Predict what type of document this image represents
- Consider the information required for this document
- Display the information of this document in a list format in Japanese
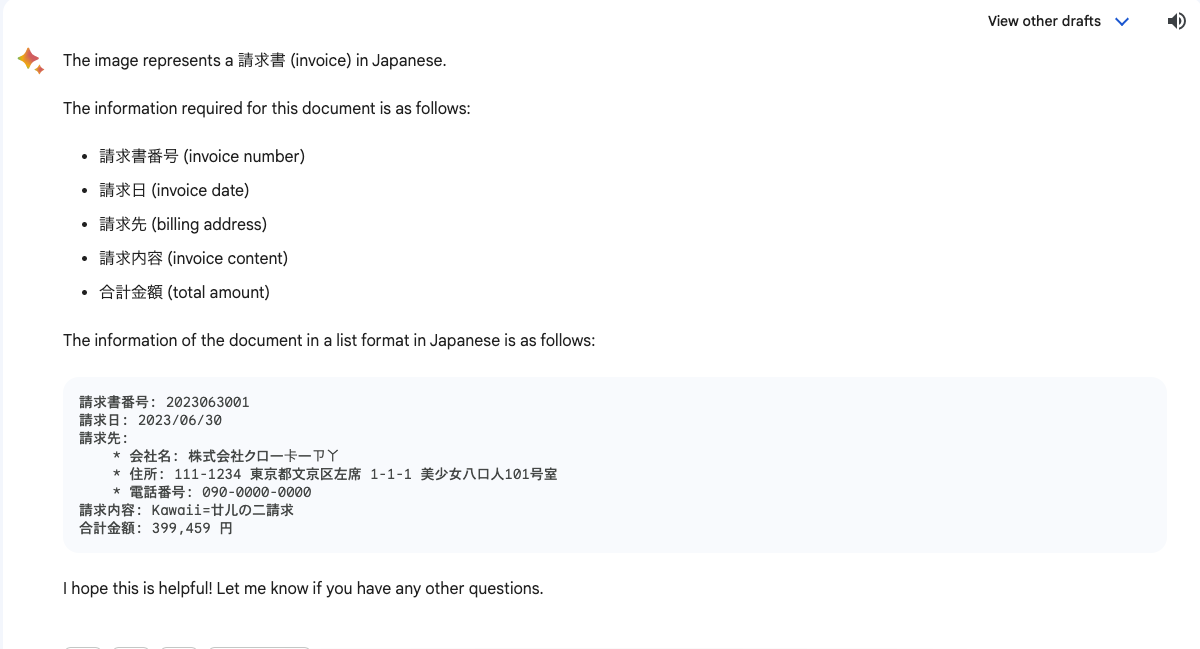
試してみる
以下のように画像とプロンプトをセットにしてリクエストします。

回答全体を日本語でお願いしなかったので、基本的には英語ですが、以下のように情報抽出が行われました🎉
今回はFunction calling用のプロンプトや各種関数をこちらで用意しましたが、任意のモダリティに対応した言語モデルであれば、思考ループによってのみ解決する仕組みもできそうです (いま現在でも、ReACTのようなAgentの行動戦略決定システムを使えば実現可能だと思いますが)。
ユーザーが「ここのフォルダにある請求書を情報抽出していい感じにExcelにまとめておいて〜」って言ったら勝手にすべてやってくれるような、汎用的なAIアシスタントも近いうちに登場するかもしれません。