こんにちは!逆瀬川 ( @gyakuse ) です!
今日は最近作った議事録文字起こしアプリに話者分離機能をくっつけたものを作っていきたいと思います。
ChatGPT APIの使い方、Whisper APIの使い方、Hugging Face Spacesへのデプロイ方法等を知りたい場合は以下の記事をぜひ!
できたもの

- openai_keyにOpenAIのAPIキーを入れる
- メイン音声ファイルに会話音声 (wav, 25MB以内) を入れる
- 話者 (1) 参考音声ファイルに話者 (1) の参考音声 (wav) を入れる
- 話者 (1) の名前を入れる
- 話者 (2) 参考音声ファイルに話者 (1) の参考音声 (wav) を入れる
- 話者 (2) の名前を入れる
上記を行って送信ボタンを押すと処理が開始されます。なお、参考音声は10秒程度で大丈夫です。実装全体は以下で確認できます。
話者分離 (Speaker Diarization) とは
WhisperやWhisper APIの出力には発話者が誰であるかという情報が欠落しています。
議事録音声の文字起こしアプリケーションにおいては、誰が喋ったかということを自動的に推定してくれると嬉しさがアップします。
どのように話者を特定するか
話者分離手法としては、各発話に対してベクトルで表現される話者埋め込みを作成して、k-meansなどでクラスタリングします (グループ化)。ここからわかるように、何人で喋っているかという情報があると、より安定した処理を行うことができるようになります。この操作によって得られる情報は以下のようになります。
- 00:00 - 00:20 話者A
- 00:21 - 00:35 話者B
- 00:36 - 00:40 話者A
誰が喋っているかを特定する
たとえば山田さんと田中さんが会話している議事録において、文字起こしでしてほしいのは話者Aと山田さんを結びつけ、話者Bを田中さんに結びつける操作です。これをするのは単純で、参考音声を別撮りして、話者埋め込みを作り、先程作ったクラスターの近傍かどうかを判定してあげれば良いです。10秒程度あればうまくいきそうな気がします。文字起こしと組み合わせると以下のような出力になるでしょう。
- 00:00 - 00:20 山田「こんにちは〜、今日は話者ダイアライゼーションについて話していこうと思います」
- 00:21 - 00:35 田中「面白いですね。話者ダイアライゼーションはたいへんな作業です」
- 00:36 - 00:40 山田「はい……」
実装の流れ
以下に実装の流れを示します。
- 音源を作る
- Whisper APIで文字起こしにする
- speechbrain/spkrec-ecapa-voxcelebを使って埋め込みを作りクラスタリングする
- 参考音声を使ってそれぞれのクラスターに話者をアサインする
実装
音源を作る
https://gist.github.com/nyosegawa/6a9082d0eb208253227b45b515976db1
こちらのgistの会話をもとに録音します。また、参考音声を2人分録音しました。すべてwavにて保存します。トニモノ ( @toni_nimono ) さんに協力していただきました。ありがとうございます。
Whisper APIで文字起こしにする
作成したファイルをWhisper APIにかけます。
transcript = openai.Audio.transcribe("whisper-1", open(meeting_file_path, "rb"), response_format="verbose_json")
Whisper APIのレスポンスのsegmentsには各発話の発話開始秒・終了秒等が格納されています。
各発話をembeddingsにする
こちらのmodelを使って話者埋め込みを作ります。ここの実装はvumichienさんのWhisper speaker Dializationを参考にしました。
この処理によってそれぞれの発話は192次元の埋め込みベクトルになります。
def segment_embedding(
file_name: str,
duration: float,
segment,
embedding_model: PretrainedSpeakerEmbedding
) -> np.ndarray:
"""
音声ファイルから指定されたセグメントの埋め込みを計算します。
Parameters
----------
file_name: str
音声ファイルのパス
duration: float
音声ファイルの継続時間
segment: whisperのtranscribeのsegment
embedding_model: PretrainedSpeakerEmbedding
埋め込みモデル
Returns
-------
np.ndarray
計算された埋め込みベクトル
"""
audio = Audio()
start = segment["start"]
end = min(duration, segment["end"])
clip = Segment(start, end)
waveform, sample_rate = audio.crop(file_name, clip)
return embedding_model(waveform[None])
def generate_speaker_embeddings(
meeting_file_path: str,
transcript
) -> np.ndarray:
"""
音声ファイルから話者の埋め込みを計算します。
Parameters
----------
meeting_file_path: str
音声ファイルのパス
transcript: Whisper API の transcribe メソッドの出力結果
Returns
-------
np.ndarray
計算された話者の埋め込み群
"""
segments = transcript['segments']
embedding_model = PretrainedSpeakerEmbedding("speechbrain/spkrec-ecapa-voxceleb", device='cpu')
embeddings = np.zeros(shape=(len(segments), 192))
with contextlib.closing(wave.open(meeting_file_path, 'r')) as f:
frames = f.getnframes()
rate = f.getframerate()
duration = frames / float(rate)
for i, segment in enumerate(segments):
embeddings[i] = segment_embedding(meeting_file_path, duration, segment, embedding_model)
embeddings = np.nan_to_num(embeddings)
return embeddings
発話の埋め込みベクトル群をクラスタリングする
階層的クラスタリング手法 (AgglomerativeClustering) を用いてベクトル群をクラスタリング (グループ分け) します。話者数を2と設定しているので、2つのグループができます。最後の format_speaker_output_by_segment 関数にクラスターと文字起こしを渡すことで、話者IDを振った文字起こしを表示できます。
import numpy as np
from sklearn.cluster import AgglomerativeClustering
from typing import List, Tuple
def clustering_embeddings(speaker_count: int, embeddings: np.ndarray) -> AgglomerativeClustering:
"""
埋め込みデータをクラスタリングして、クラスタリングオブジェクトを返します。
Parameters
----------
embeddings: np.ndarray
分散表現(埋め込み)のリスト。
Returns
-------
AgglomerativeClustering
クラスタリングオブジェクト。
"""
clustering = AgglomerativeClustering(speaker_count).fit(embeddings)
return clustering
def format_speaker_output_by_segment(clustering: AgglomerativeClustering, transcript: dict) -> str:
"""
クラスタリングの結果をもとに、各発話者ごとにセグメントを整形して出力します
Parameters
----------
clustering: AgglomerativeClustering
クラスタリングオブジェクト。
transcript: dict
Whisper API の transcribe メソッドの出力結果
Returns
-------
str
発話者ごとに整形されたセグメントの文字列
"""
labeled_segments = []
for label, segment in zip(clustering.labels_, transcript["segments"]):
labeled_segments.append((label, segment["start"], segment["text"]))
output = ""
for speaker, _, text in labeled_segments:
output += f"話者{speaker + 1}: 「{text}」\n"
return output
この format_speaker_output_by_segment 処理によって得られた出力が以下となります。
話者1: 「ねえ、目玉焼きには醤油が一番だと思わない?」
話者1: 「いや、僕はソース派だよ。目玉焼きにソースが合うと思う。」
話者1: 「醤油の方がシンプルで美味しいと思うんだけどな。ソースはちょっと味が濃すぎる気がする。」
話者2: 「でも、ソースの甘さと酸味が卵の旨味を引き立てると思うんだよね。それにソースはバリエーションが豊富だし。」
話者1: 「そうかもしれないけど、醤油は日本の伝統的な調味料だし、目玉焼きには合うと思うよ。それに塩分が少なめでヘルシーだし。」
話者2: 「確かに醤油もいいかもしれないけど、ソースの風味が好きなんだよね。どっちも一長一短があると思うけど、僕はやっぱりソースが好きかな。」
話者1: 「まあ、それぞれの好みだよね。どっちにしても、美味しい目玉焼きができればそれが一番だよ。」
話者2: 「そうだね。美味しい目玉焼きのために焼き方にもこだわりたいよね。焼き加減って大事だと思うんだ。」
話者1: 「確かに。卵の黄身がトロトロの状態が好きなんだけれど、どうやって焼くといいんだろう?」
話者2: 「僕はフライパンに油をひいて卵を割り入れたら、蓋をして蒸し焼きにするんだ。そうすると黄身がトロトロになるよ。」
話者1: 「ああ、なるほど。それは美味しそうだね。僕も次回は試してみるよ。それに醤油でもソースでも、トロトロの黄身には合うと思うしね。」
話者2: 「うん、そうだね。トロトロの黄身にはどちらの調味料も合うと思うよ。結局は自分の好みで楽しむのが一番だよね。」
話者1: 「そうだね。いろいろな調味料や焼き方を試して自分好みの目玉焼きを見つけるのも楽しいかもしれないね。」
話者2: 「本当にそうだね。これからもっと美味しい目玉焼きを作るために、いろんなレシピや調味料を試してみよう。」
2番目の発話のみ誤って分類されていますが、おおむね期待通りの結果となっています。
ちなみにt-SNEで2次元に次元削減してプロットしてみると以下のようになります。
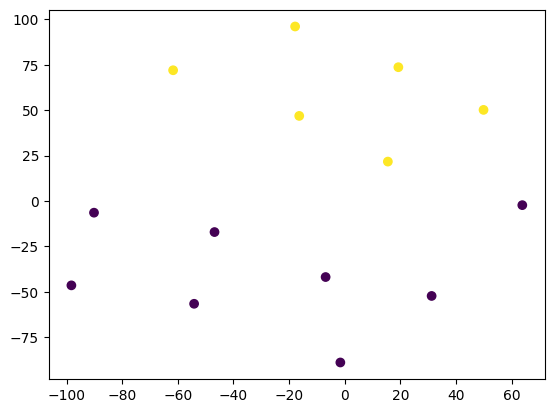
話者名をアサインする
参考音声についても先程と同様に話者埋め込みを作り、各発話に対してどちらの話者埋め込みに近いかをcosine類似度を取ってあげることで判定します。
from scipy.spatial.distance import cosine
def closest_reference_speaker(embedding: np.ndarray, references: List[Tuple[str, np.ndarray]]) -> str:
"""
与えられた埋め込みに最も近い参照話者を返します。
Parameters
----------
embedding: np.ndarray
話者の埋め込み
references: List[Tuple[str, np.ndarray]]
参照話者の名前と埋め込みのリスト
Returns
-------
str
最も近い参照話者の名前
"""
min_distance = float('inf')
closest_speaker = None
for name, reference_embedding in references:
distance = cosine(embedding, reference_embedding)
if distance < min_distance:
min_distance = distance
closest_speaker = name
return closest_speaker
def format_speaker_output_by_segment2(embeddings: np.ndarray, transcript: dict, reference_embeddings: List[Tuple[str, np.ndarray]]) -> str:
"""
各発話者の埋め込みに基づいて、セグメントを整形して出力します。
Parameters
----------
embeddings: np.ndarray
話者の埋め込みのリスト
transcript: dict
Whisper API の transcribe メソッドの出力結果
reference_embeddings: List[Tuple[str, np.ndarray]]
参照話者の名前と埋め込みのリスト
Returns
-------
str
発話者ごとに整形されたセグメントの文字列。
"""
labeled_segments = []
for embedding, segment in zip(embeddings, transcript["segments"]):
speaker_name = closest_reference_speaker(embedding, reference_embeddings)
labeled_segments.append((speaker_name, segment["start"], segment["text"]))
output = ""
for speaker, _, text in labeled_segments:
output += f"{speaker}: 「{text}」\n"
return output
この format_speaker_output_by_segment2 処理によって得られた出力が以下となります。
さかせがわ: 「ねえ、目玉焼きには醤油が一番だと思わない?」
とにえもん: 「いや、僕はソース派だよ。目玉焼きにソースが合うと思う。」
さかせがわ: 「醤油の方がシンプルで美味しいと思うんだけどな。ソースはちょっと味が濃すぎる気がする。」
とにえもん: 「でも、ソースの甘さと酸味が卵の旨味を引き立てると思うんだよね。それにソースはバリエーションが豊富だし。」
さかせがわ: 「そうかもしれないけど、醤油は日本の伝統的な調味料だし、目玉焼きには合うと思うよ。それに塩分が少なめでヘルシーだし。」
とにえもん: 「確かに醤油もいいかもしれないけど、ソースの風味が好きなんだよね。どっちも一長一短があると思うけど、僕はやっぱりソースが好きかな。」
さかせがわ: 「まあ、それぞれの好みだよね。どっちにしても、美味しい目玉焼きができればそれが一番だよ。」
とにえもん: 「そうだね。美味しい目玉焼きのために焼き方にもこだわりたいよね。焼き加減って大事だと思うんだ。」
さかせがわ: 「確かに。卵の黄身がトロトロの状態が好きなんだけれど、どうやって焼くといいんだろう?」
とにえもん: 「僕はフライパンに油をひいて卵を割り入れたら、蓋をして蒸し焼きにするんだ。そうすると黄身がトロトロになるよ。」
さかせがわ: 「ああ、なるほど。それは美味しそうだね。僕も次回は試してみるよ。それに醤油でもソースでも、トロトロの黄身には合うと思うしね。」
とにえもん: 「うん、そうだね。トロトロの黄身にはどちらの調味料も合うと思うよ。結局は自分の好みで楽しむのが一番だよね。」
さかせがわ: 「そうだね。いろいろな調味料や焼き方を試して自分好みの目玉焼きを見つけるのも楽しいかもしれないね。」
とにえもん: 「本当にそうだね。これからもっと美味しい目玉焼きを作るために、いろんなレシピや調味料を試してみよう。」
それぞれの発話埋め込みに対してcosine類似度を取るこのやり方をすると、かなり精度が高くなることがわかります。
おわりに
今回は議事録文字起こしに話者を自動アサインする方法をまとめました。商用製品ではこれに近いことをもっと真面目に実装していると思います。たとえば独自の話者埋め込みモデルを作ったり、話者数が増えたり不明である場合や、会議参加者が参考音声埋め込み1,000人のうちいずれかという場合を考えると、非常に難しい問題になります。
とはいえ話者数がわかっている&全員分の参考音声があると結構いい感じなので、ぜひみなさんも話者ダイアライゼーションしていきましょう。