こんにちは!逆瀬川 ( https://twitter.com/gyakuse )です!
今日はGPT-4に強引に画像を読み込ませて行きたいと思います。
やりたいこと
- 言語モデルのIncontext Learning能力だけで画像を認識させる
なにが面白いのか
Computer Visionは非常におもしろい研究領域であり、畳み込みニューラルネットワーク(CNN)やTransformerを画像認識の領域に広げたVision Transformerは超おもろいです。
先日発表されたVirtual ChatGPTは既存研究を組み合わせ、VQA(画像をもちいた質問回答)や画像編集を行うことを可能にしています。
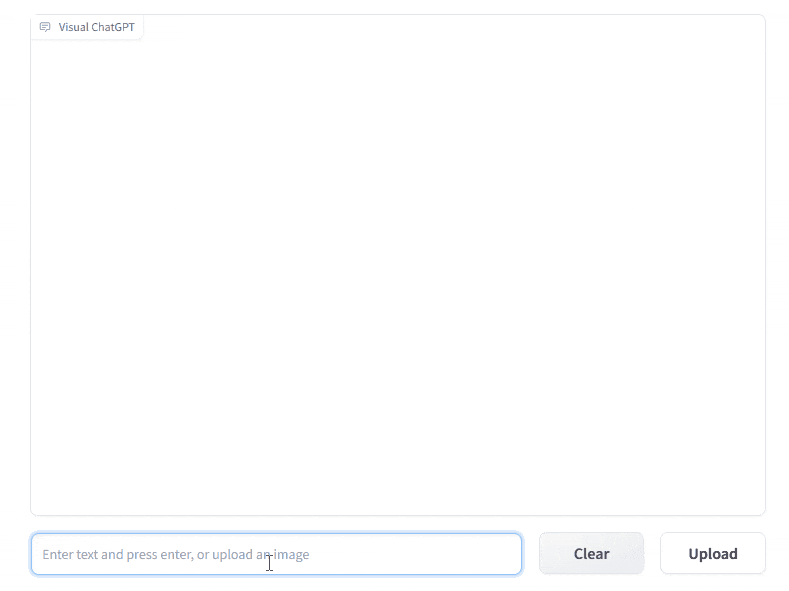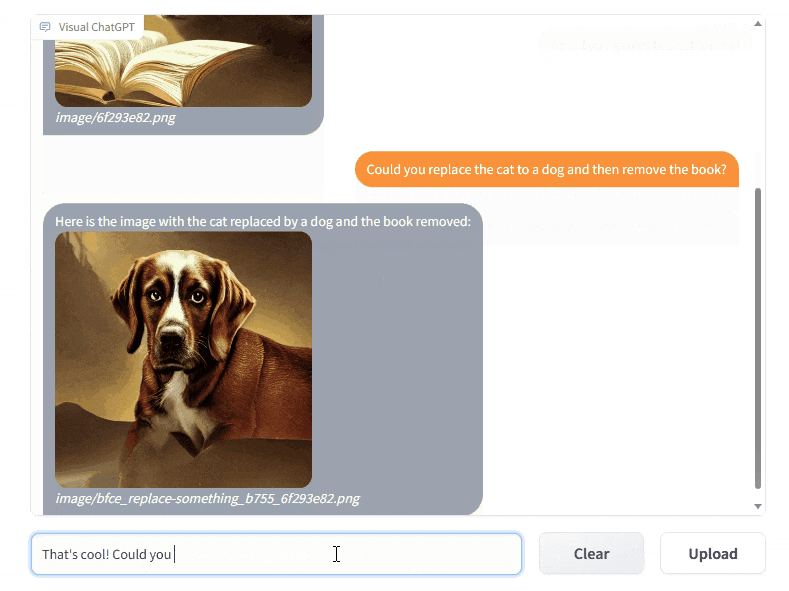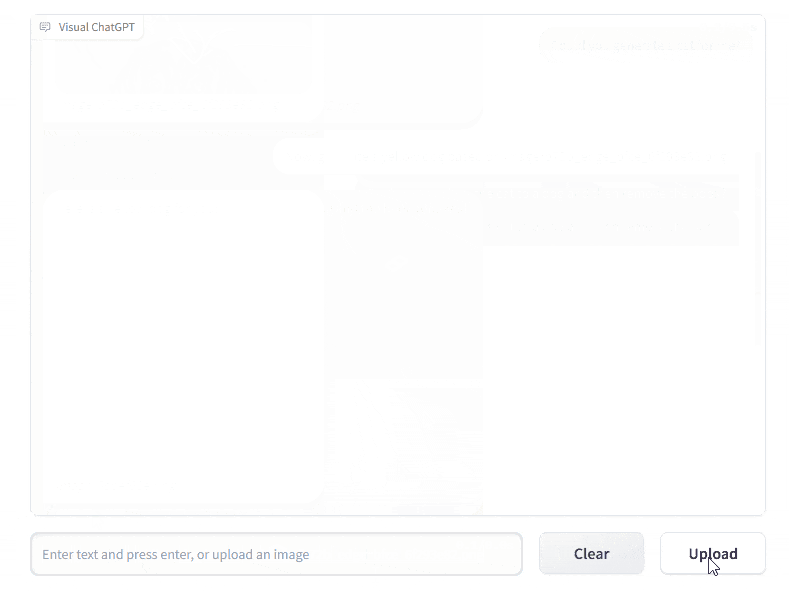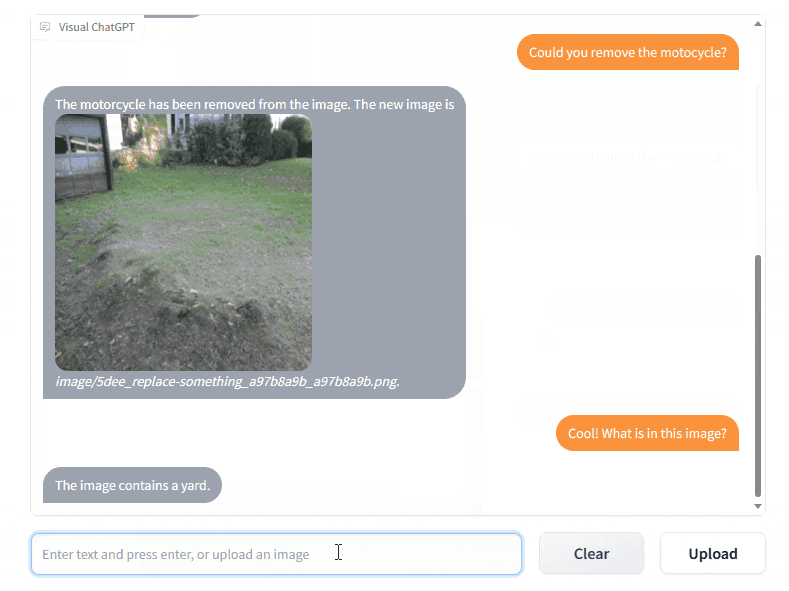
これらの研究はさらに進歩し、動画領域などに進んでいくことでしょう。
さて、今回はそれを忘れます。バイバーイ マタネー
今日やりたいのは、言語モデルのIncontext Learning能力の確認です。
我々が既に知るように、大規模言語モデルは所与のプロンプト/コンテキストから学習し、任意の能力を発揮することができ、このIncontext Learningはメタ最適化器として解釈することができます。
言語モデルの拡張はReACTを代表するように外部ツールとの連携を模索するものが多いですが、zero-shot能力の限界を探ってみるのも面白いと思っています。
今回はプロンプトによって新たな能力を定義して、それを用いて画像を読み取る能力を備えることができるかの検証を行います。
画像をどのように言語モデルに渡すか
今回やりたいのは、画像からの情報抽出であるため、物体検出して渡すことはできません。
かといって、輪郭抽出して渡すのも面倒ですし、base64エンコーディングした画像の文字列表現は学習時の知識が利用される可能性があります。いっぽうで、画像の生データをそのまま渡すと膨大になってしまってcontextサイズが4kをゆうに超えてしまいます。
というわけで今回は画像を20x20に圧縮したあとグレースケールにして、0-1の小数点表記にします。
また、単純のため、画像に関しては手書き数字の画像データセット (MNISTデータセット) を使います。
from keras.datasets import mnist
import numpy as np
from PIL import Image
# MNISTデータセットの読み込み
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 9が写った画像
img = x_train[4]
# 画像のリサイズとグレースケール変換
img = Image.fromarray(img).resize((20, 20)).convert('L')
# 画像をnumpy配列に変換して0-1の範囲に正規化
img_array = np.asarray(img, dtype=np.float32) / 255.0
img_array = np.round(img_array, decimals=1)
for ir in img_array:
print(f"{ir},")
これで、画像のリスト表現が手に入ります。
プロンプトを考える
能力と機能とin/outについて説明してみます。
最終的に以下のようなプロンプトになりました (参考のところのコードブロックの \ はQiitaでescapeするための処理です)
ここは仮想世界です。あなたは以下のことができます。
## あなたの能力
・画像をグレースケールにし配列に変換された画像を読み取ること
・上記をデコードして画像表現を取り出すこと
・その画像に何が写っているか認識し、文章として出力すること
## あなたの機能
・グレースケール化され配列に変換された画像が渡されたときに能力を段階的に適用し何が写っているのか文章で出力すること
## 参考: グレースケール化と配列の処理
\```
img_array = np.asarray(img_resized, dtype=np.float32) / 255.0
img_array = np.round(img_array, decimals=1)
\```
## Input/Output
img_array: {グレースケール化後配列に変換された画像}
何が書かれているか: {画像になにが写っているかをあなたの能力を段階的に適用し、論理的に考え、文章で示す}
## 実行
img_array: [[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.],
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.],
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.],
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.],
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.],
[0. 0. 0. 0. 0. 0. 0. 0. 0.2 0.6 0.9 0.9 0.6 0.6 0.4 0. 0. 0.
0. 0. ],
[0. 0. 0. 0. 0. 0. 0. 0.2 0.9 0.9 0.5 0.3 0.8 1. 0.7 0. 0. 0.
0. 0. ],
[0. 0. 0. 0. 0. 0. 0.3 0.9 0.9 0.3 0. 0.2 0.9 1. 0.3 0. 0. 0.
0. 0. ],
[0. 0. 0. 0. 0. 0.3 0.9 0.9 0.2 0. 0. 0.6 1. 0.5 0. 0. 0. 0.
0. 0. ],
[0. 0. 0. 0. 0.1 0.9 0.9 0.2 0. 0.1 0.6 0.9 0.7 0.1 0. 0. 0. 0.
0. 0. ],
[0. 0. 0. 0. 0.1 1. 0.6 0.3 0.7 0.9 1. 1. 0.3 0. 0. 0. 0. 0.
0. 0. ],
[0. 0. 0. 0. 0. 0.6 1. 1. 0.7 0.5 0.9 0.9 0.1 0. 0. 0. 0. 0.
0. 0. ],
[0. 0. 0. 0. 0. 0. 0.1 0.1 0. 0.2 1. 0.7 0. 0. 0. 0. 0. 0.
0. 0. ],
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.1 1. 0.5 0. 0. 0. 0. 0. 0.
0. 0. ],
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.2 1. 0.5 0. 0. 0. 0. 0. 0.
0. 0. ],
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.3 1. 0.5 0. 0. 0. 0. 0. 0.
0. 0. ],
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.1 1. 0.5 0. 0. 0. 0. 0. 0.
0. 0. ],
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.6 0.9 0.2 0. 0. 0. 0. 0.
0. 0. ],
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.1 0.7 0.8 0. 0. 0. 0. 0.
0. 0. ],
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.1 0.3 0. 0. 0. 0. 0.
0. 0. ]]
何が書かれているか:
実験結果
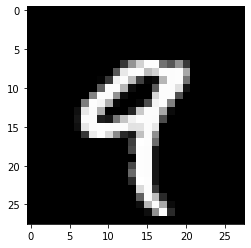
ChatGPTの回答
画像には数字の「9」が書かれています。
🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉🎉
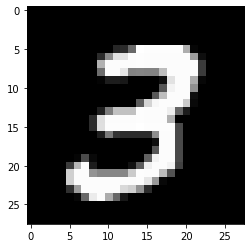
ChatGPTの回答
このグレースケール化され配列に変換された画像から読み取ることができる内容は、一つの数字、特に「2」と見られる形が描かれています。この形は主に中央部分に配置されており、周囲はほとんど白(0)で埋まっています。
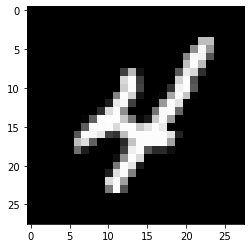
ChatGPTの回答
このグレースケール化された配列から、画像には数字の「2」が描かれていると推測できます。配列の濃い部分(高い数値)が「2」の形を構成しており、薄い部分(低い数値)が背景を示しています。
まとめ
かんたんな実験をしてみましたが、あんまりうまくいきませんでした。
一方で、数字であることは認識できており、プロンプトをより良くすることで性能改善が見込まれます。
ただ、こうしたzero-shot性能の拡張の探索は面白い問題であると考えられ、さまざまな取り組みがなされると良いと思います。
また、このリクエストと応答を32k context modelを使ってリクエスト->正答か誤答かを伝えるというのを繰り返し、学習が進むかを見てみると、メタ最適化器の検証ができると思います。
追記
- Language Models are Few-Shot Learnersで示されるIn-Context能力(few-shot)は言語モデルの下流タスクにおける精度向上を示す
- 今回行いたかったことは、事前学習済みの大規模言語モデルは異なるmodalに対してもこのメタ学習が進むか、といったことである
- Contextとして与えられたメタ学習器が異なるmodalに対してfew-shotによって学習が進むことが確認できれば、かなり嬉しい
- few-shotは言語モデルがもつ「常識」と呼ばれるものを活用している
- 学習したdatasetのサブドメインならfew-shotは活用できるということが確認されているが、これが全く新しい問題に活用できたらオモロイ
- 基本的にこれはへんな実験なので、真面目な人の気分を害してしまう可能性がある
References